
Как могут помнить те из вас, кто читает хаб «Программирование», зимой 2014 JetBrains объявила подписку на private preview C++ IDE. В результате немалое количество подписчиков ей уже пользуются, в начале осени мы планируем выпустить общедоступную early preview, а мы до сих пор олучаем письма от друзей на тему «мы не успели подписаться, как вскочить в этот поезд сейчас?».
А сейчас есть отличная возможность вписаться в похожую историю без опозданий: JetBrains открывает подписку на early preview новой IDE для разработчиков, которые пишут на SQL. И для админов баз данных, — им тоже бывает нужно что-то поудобнее, чем pgAdmin. Для админов новая IDE пригодится там, где им надо поработать с данными в таблицах. Назначать права, делать бэкапы и выполнять прочие чисто админские задачи IDE пока не умеет, хотя мы подумываем ее этому научить.
Короче: тут — подписываться, а под катом — подробности.
А сейчас есть отличная возможность вписаться в похожую историю без опозданий: JetBrains открывает подписку на early preview новой IDE для разработчиков, которые пишут на SQL. И для админов баз данных, — им тоже бывает нужно что-то поудобнее, чем pgAdmin. Для админов новая IDE пригодится там, где им надо поработать с данными в таблицах. Назначать права, делать бэкапы и выполнять прочие чисто админские задачи IDE пока не умеет, хотя мы подумываем ее этому научить.
Короче: тут — подписываться, а под катом — подробности.
 Добрый день, статья написана в качестве некоего продолжения
Добрый день, статья написана в качестве некоего продолжения  В обязанности администратора баз данных входит много разных задач, которые, в основном, направлены на поддержку работоспособности и целостности базы данных. И если целостность данных можно проверить через команду CHECKDB, то с поиском невалидных объектов в схеме не все так гладко.
В обязанности администратора баз данных входит много разных задач, которые, в основном, направлены на поддержку работоспособности и целостности базы данных. И если целостность данных можно проверить через команду CHECKDB, то с поиском невалидных объектов в схеме не все так гладко. Иногда в своих проектах мне хотелось прикрутить некоторую географическую базу, с помощью которой я бы разделял пользователей ресурса по их месту пребывания. Но постоянная занятость делами насущными никак не давала реализовать идею с базой регионов и мало-мальски удобным интерфейсом для ее визуализации.
Иногда в своих проектах мне хотелось прикрутить некоторую географическую базу, с помощью которой я бы разделял пользователей ресурса по их месту пребывания. Но постоянная занятость делами насущными никак не давала реализовать идею с базой регионов и мало-мальски удобным интерфейсом для ее визуализации.









 В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.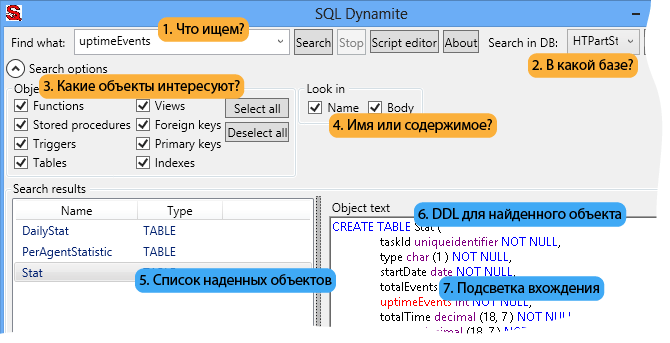
 В предыдущем посте была
В предыдущем посте была 