Привет, Хабр! В этой статье разберём, что такое метрики отношения. Узнаем, почему критерий Стьюдента не работает. Попробуем применить бутстреп к зависимым данным. Изучим дельта-метод — способ оценки А/Б тестов с метрикой отношения.
Привет, Хабр! В этой статье разберём, что такое метрики отношения. Узнаем, почему критерий Стьюдента не работает. Попробуем применить бутстреп к зависимым данным. Изучим дельта-метод — способ оценки А/Б тестов с метрикой отношения.

По сравнению с развитыми странами, уровень внедрения ИИ в промышленности в России остается невысоким. Если технологию и используют, то в основном на предприятиях тяжелой промышленности. За рубежом искусственный интеллект активно разворачивают и в более “легких” отраслях. В статье — наиболее типовые сценарии и кейсы применения технологии в FMCG и фарме международными отраслевыми лидерами.
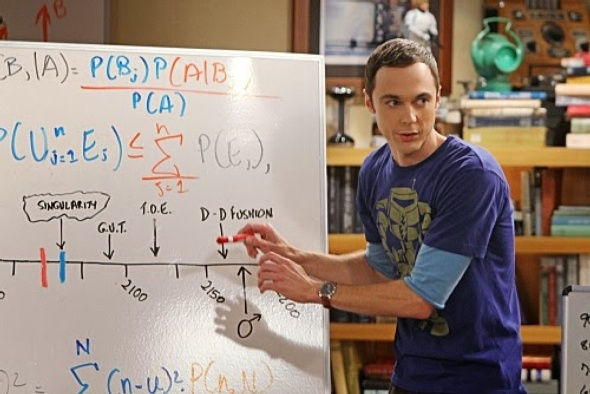
Теорема (формула) Байеса позволяет выяснить вероятность события при условии, что произошло связанное с ним другое событие.
Теорема позволяет рассчитать вероятность события, если причину и следствие поменять местами. Например, мы знаем распространенность симптома среди больных и здоровых. Значит, мы можем вычислить вероятность заболевания от наличия симптома.

Откройте для себя новый аспект в улучшении пользовательского опыта: связь между просмотром карточек товаров и покупками. В статье я исследую, как количество просмотренных карточек влияет на действия пользователей.
Узнайте, как анализ данных позволяет оптимизировать ваш продукт и стимулировать пользователей к совершению покупок. Раскройте потенциал вашего продукта, упрощая путь к целевому действию.

Всем привет! В предыдущих двух статьях мы подробно рассмотрели технические и методологические аспекты A/B-тестирования в Ozon. А сейчас время перейти к не менее интересным темам. Так как наша команда занимается не только A/B-тестами, но и в целом развитием методов принятия решений с помощью causal inference, стоит уделить внимание многоруким бандитам.
В этой статье мы рассмотрим методологию и границы применимости классических многоруких и контекстуальных бандитов, а также реализуем контекстного бандита, в основе которого будут сэмплирование Томпсона и нейронная сеть. Ну и, конечно, мы постараемся ответить на главный вопрос: могут ли многорукие бандиты заменить A/B-тесты?

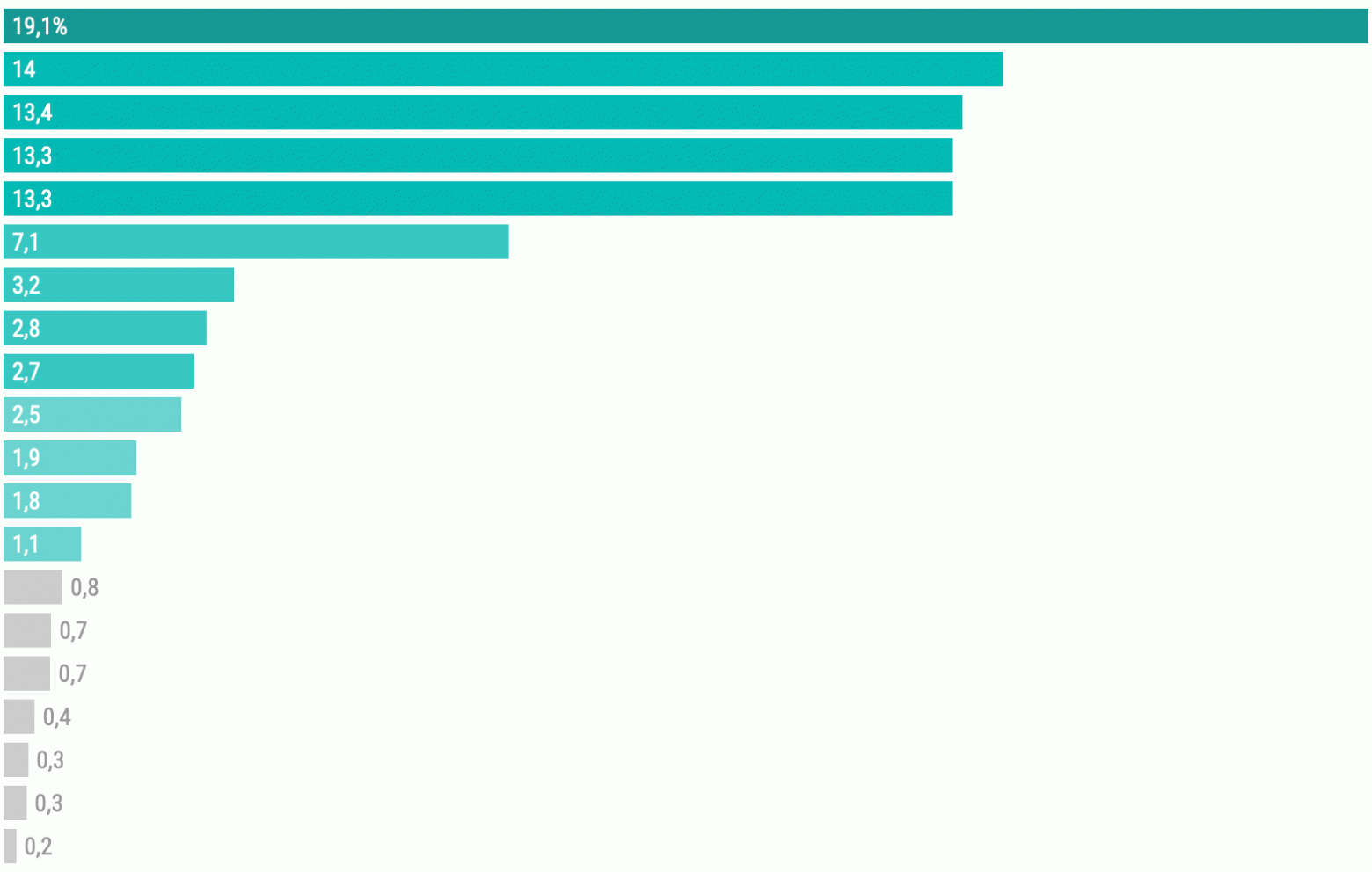
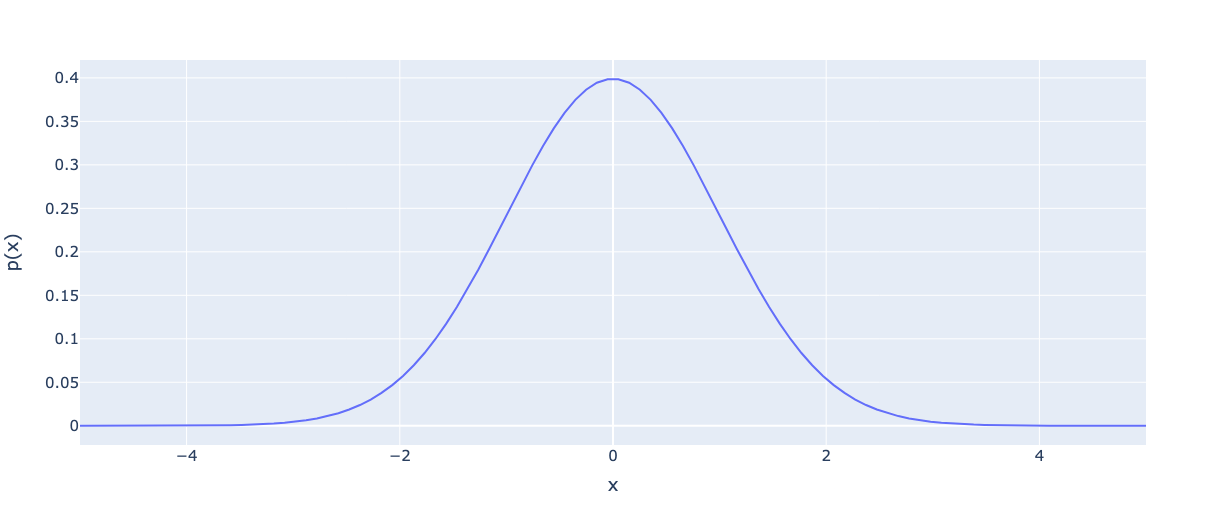
Диаграммы помогают визуализировать как простые, так и самые сложные наборы данных. При этом диаграмм — множество видов, у каждого есть свои достоинства и недостатки. О наиболее эффектных и эффективных, реализуемых с Python, мы решили рассказать в сегодняшней подборке. Если вам интересна эта тема – просим под кат. А если у вас есть собственные предпочтения среди графиков (или вы используете что-то ещё), то пишите в комментариях, обсудим. Что же – поехали!

Статистический анализ играет важную роль в научных исследованиях, коммерческих деятельностях и в других областях. Однако, его результаты могут быть неточными, если не учитывать имеющиеся степени свободы. Степени свободы – это концепция, которая широко используется в статистике, и она позволяет более точно определить, насколько можно доверять полученным результатам.
В данной статье мы рассмотрим понятие степеней свободы, их роль в статистических расчетах, а также примеры их использования. Мы узнаем, как степени свободы помогают улучшить точность статистических выводов и в каких случаях их использование особенно важно.

Привет, Хабр. Меня зовут Максим Еремин, отвечаю за развитие PaaS-сервисов в beeline cloud. Этой статьей мы запускаем цикл публикаций, в которых вместе с коллегами будем комментировать и рассказывать о ситуации на рынке BI. Сегодня поговорим о data-driven культуре и импортозамещении. А если возникнут вопросы — буду рад обсудить их в комментариях.
Громкие заголовки, возвещающие о «кончине» business intelligence (BI), встречаются на тематических площадках уже лет десять. Но сегмент и не думает отходить на второй план, напротив — растет и развивается. Аналитики из Precedence Research говорят, что к 2032 году мировой рынок BI достигнет планки в $55 млрд. Их коллеги из Fortune Business Insights дают еще более оптимистичные оценки — та же сумма, но к 2030-му.
Технология глубоко проникла в стеки крупного, малого и среднего бизнеса. Ту или иную BI-систему имеет 80% компаний со штатом более 5 тыс. сотрудников. В фирмах поменьше показатель составляет 26%, но постепенно увеличивается.
Если взглянуть на российский рынок разработки и интеграции BI-решений, то он тоже достаточно зрелый. Два года назад его объем составлял 35 млрд рублей. Сегодня эксперты прогнозируют ускорение темпов роста в полтора-два раза. Развитие рынка стимулируют несколько факторов — рост объемов данных, развитие систем ИИ и необходимость импортозамещения.
Категориальные данные имеет огромное значение в DataScience. Как справедливо заметили авторы в [1], мы живем в мире категорий: информация может быть сформирована в категориальном виде в самых различных областях - от диагноза болезни до результатов социологического опроса.
Частным случаем анализа категориальных данных является анализ таблиц сопряженности (contingency tables), в которые сводятся значения двух или более категориальных переменных.
Однако, прежде чем написать про статистический анализ таблиц сопряженности, остановимся на вопросах их визуализации. Казалось бы, об этом уже написано немало - есть статьи про графические возможности python, есть огромное количество информации и примеров с программным кодом. Однако, как всегда имеются нюансы - в процессе исследования возникают вопросы как с выбором средств визуализации, так и с настройкой инструментов python. В общем, есть о чем поговорить...
В данном обзоре мы рассмотрим следующие способы визуализации таблиц сопряженности.
Теперь к истокам задачи: часто, чтобы математическая модель была применима в реальном секторе, необходимо использовать очень много ограничений и большое количество переменных. Задачи, возникающие в бизнесе в реальных условиях, требуют использования моделей с большим количеством ограничений и большим количеством переменных. Временами задача в лоб может и не решиться, поэтому были придуманы различные трюки. Один из них - метод « генерации столбцов» (Column generation).

Кол-центры перейдут на отечественные продукты до 2025 года, указала Юлия Черноуцян, генеральный директор компании-разработчика ПО для кол-центров MightyCall. В разговоре с информационной службой Хабра Юлия дала несколько прогнозов относительно будущего отечественного рынка кол-центров и немного рассказала, как он развивался после ухода западных вендоров в 2022 году.








Руководящие документы по организации первичной медико-социальной помощи населению предписывают проводить сравнительный анализ численности населения по территориальным участкам (норматив численности населения на терапевтическом участке - 1700 взрослых, на педиатрическом участке - 800 детей, на акушерско-гинекологическом участке - 3300 женщин в возрасте 15 лет и старше и т.д.) .
Оценку численности населения по субъектам РФ Росстат публикует ежегодно на 1 января текущего года. Для крупных городов территории обслуживания населения медицинскими организациями часто не совпадают с адресно административным делением и распределение населения по зонам ответственности медицинской организации становится скорее творчеством нежели технологической процедурой. Вопрос как декомпозировать данные из бюллетеня Росстата до медицинского участка для меня остается нерешенным.
Мы пойдем другим путем. Данные о населении мы можем получить из медицинской информационной системы (МИС). База МИС обогащается на регулярной основе данными страховых компаний о застрахованных лицах по программе обязательного медицинского страхования (ОМС).
Для работы нам понадобится обезличенная выгрузка из МИС, содержащая данные по пациентам: пол, дату рождения, адрес регистрации, адрес фактического места жительства, данные медицинской организации и номера участка по терапевтическому или педиатрическому профилю. Я загрузил ее в pandas.dataframe.

Пару недель назад редакция Хабра порадовала нас поддержкой маркдауна в новом редакторе. А заодно рассказала о том, насколько он стал популярен:

80 процентов, да лаадно? Впрочем, это совсем несложно проверить. Давеча я скрапил Хабр для одного интересного расследования и кроме всего прочего заметил в заветном jsonе такое поле:
И оказалось, что с новым редактором все далеко не так просто.
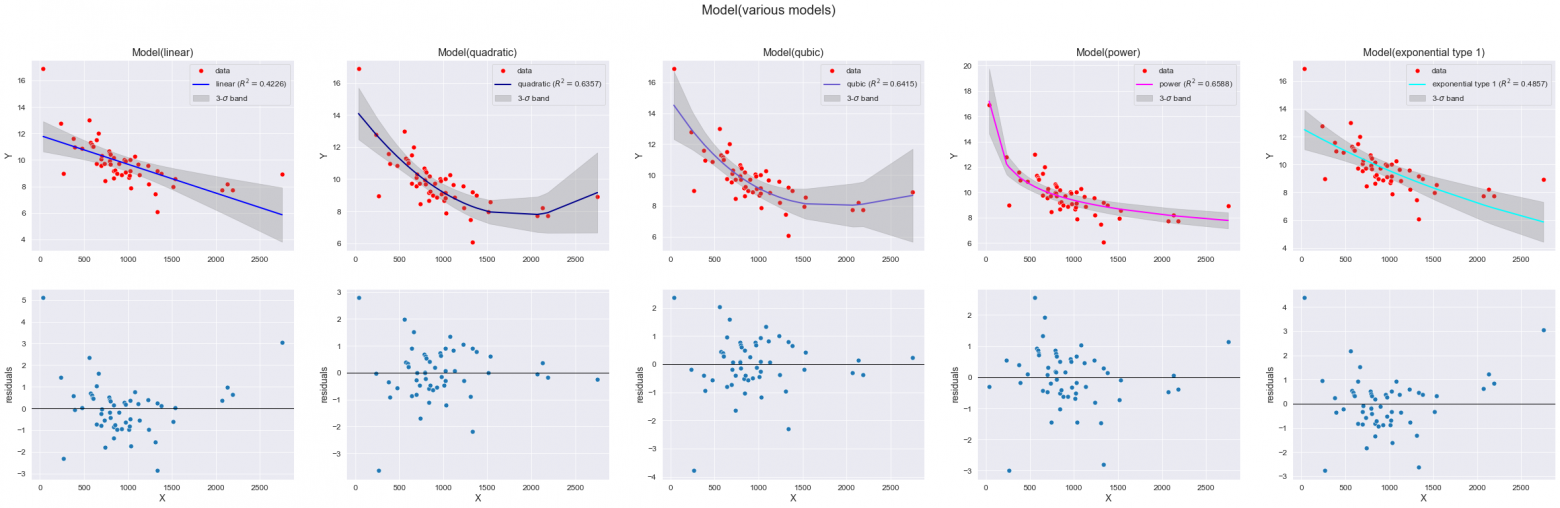
В предыдущих обзорах (https://habr.com/ru/articles/690414/, https://habr.com/ru/articles/695556/) мы рассматривали линейную регрессию. Пришло время переходить к нелинейным моделями. Однако, прежде чем рассматривать полноценный нелинейный регрессионный анализ, остановимся на аппроксимации зависимостей.
Про аппроксимацию написано так много, что, кажется, и добавить уже нечего. Однако, кое-что добавить попытаемся.
При выполнении анализа данных может возникнуть потребность оперативно построить аналитическую зависимость. Подчеркиваю - речь не идет о полноценном регрессионном анализе со всеми его этапами, проверкой гипотез и т.д., а только лишь о подборе уравнения и оценке ошибки аппроксимации. Например, мы хотим оценить характер зависимости между какими-либо показателями в датасете и принять решение о целесообразности более глубокого исследования. Подобный инструмент предоставляет нам тот же Excel - все мы помним, как добавить линию тренда на точечном графике:

Всем привет! Меня зовут Рома Смирнов. Я работаю продуктовым аналитиком в Lamoda Tech. Не так давно я столкнулся с необычным взглядом на то, как следует интерпретировать результаты A/B-эксперимента. Он заключается в том, что наблюдаемый аплифт — разницу средних, полученную на основе выборок, — необходимо сравнивать не только с критическим z- или t-значением, но еще и с MDE, минимальным эффектом, который мы ожидаем зафиксировать. Утверждается, что тест следует принимать только в том случае, если наблюдаемый аплифт лежит правее значения MDE.
Кажется, что на занятиях по статистике такому обычно не учат. Я обратился к традиционному источнику информации — Всемирной паутине (web, internet) — и нашел на эту тему хорошую статью болгарского гигачада A/B-тестирования Георгия Георгиева. В ней он приводит несколько аргументов, демонстрирующих несостоятельность описанного выше подхода.
В своей статье я буду использовать аргументы Георгия Георгиева, разбавленные моими мыслями и примерами на эту тему.

Привет! В рамках своей работы в beeline tech мы часто взаимодействуем с геоданными. Для решения проблем, связанных с хранением, обработкой и анализом большого объема распределенных пространственных данных, мы используем Apache Sedona (бывший Geospark). Мы — Денис Афанасьев, аналитик больших данных, и Женя Рыбалкин, инженер больших данных, под катом расскажем, почему выбрали именно этот инструмент и что он умеет. А чтобы показать, зачем вообще работать с геоданными, давайте возьмем пример расчета посещаемости хоккейных матчей в Москве, как-никак плей-офф в разгаре.
Давайте по порядку. Почти любой доступный смартфон, умные часы, фитнес-браслеты, оборудование для IoT — всё это может получать и передавать данные о собственном местоположении. Кроме потребительского железа серьезную эволюцию прошёл и интернет вещей в целом, причем как классический IoT для умного дома и других полезностей, так и индустриальный IIoT, заточенный под мониторинг сложных технологических систем, сельское хозяйство, мониторинг окружающей среды и многое другое.
Следствием такого развития, как в количественном, так и в качественном плане, стал ощутимый рост того объёма данных, который все эти устройства генерируют. Ну и что нам с ними делать? Давайте разберемся на примере геоданных!
Зачем вообще кому-то нужны геоданные?