Распознавание гильоширных элементов на примере паспорта РФ
7 мин
Recovery Mode
Гильош – это специальная технология защиты банкнот, документов, ценных бумаг и других видов полиграфической продукции (билетов, акцизных марок, сертификатов и многих других документов государственного масштаба).
Защита документов обеспечивается путем нанесения на бланки сложных композиций различных гильоширных элементов. Гильоширный элемент представляет собой замысловатый рисунок из множества многократно пересекающихся тончайших кружевных линий (рисунок 1). Обычно такие элементы представлены разного рода защитными сетками, розеттами, бордюрами, виньетками и уголками. Гильош может быть как симметричным, так и асимметричным по своему дизайну.
Согласно существующим нормативам, гильоширные элементы должны занимать не менее 70% площади ценных бумаг.
Причем из этой площади большая часть должна содержать многоцветные гильоширные композиции.

Защита документов обеспечивается путем нанесения на бланки сложных композиций различных гильоширных элементов. Гильоширный элемент представляет собой замысловатый рисунок из множества многократно пересекающихся тончайших кружевных линий (рисунок 1). Обычно такие элементы представлены разного рода защитными сетками, розеттами, бордюрами, виньетками и уголками. Гильош может быть как симметричным, так и асимметричным по своему дизайну.
Согласно существующим нормативам, гильоширные элементы должны занимать не менее 70% площади ценных бумаг.
Причем из этой площади большая часть должна содержать многоцветные гильоширные композиции.






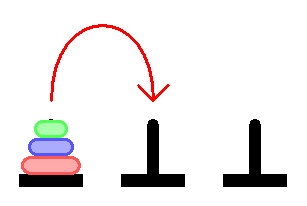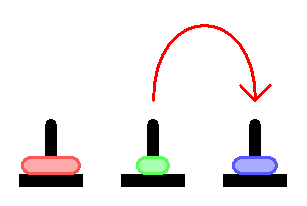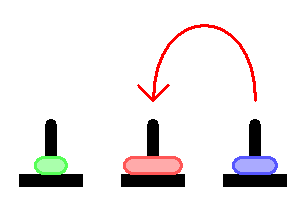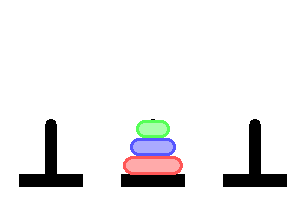 Пообщавшись с некоторыми знакомыми программистами, внезапно обнаружил, что не все знают про Ханойскую башню, а среди тех кто знает — мало кто понимает как решается эта задача.
Пообщавшись с некоторыми знакомыми программистами, внезапно обнаружил, что не все знают про Ханойскую башню, а среди тех кто знает — мало кто понимает как решается эта задача.