Boid'ы, птички и Unity3D
10 мин
Туториал

Вторая часть: Оптимизируем Boid'ов на Unity
Задумывались ли вы когда-нибудь о то, почему птицы летая большими стаями никогда не сталкиваются и не коллапсируют в огромный галдящий перьевой ком? Хм, если подумать, это было бы круто. В любом случае, однажды в 1986 нашёлся человек по имени Крейг Рейнольдс, который решил создать простую модель поведения птиц в стаях и назвал её Boids. В модели у каждого боида есть три базовых правила: Separation, Alignment и Cohesion. Первое заключается в избегании столкновения с соседями, второе заставляет лететь примерно в ту же сторону что и соседи, а третье говорит не летать в одиночку и держаться группы. Эти простые правила позволяют создать правдоподобные стаи птиц, рыб и другой живности, чем и пользуются в кино и игровой индустрии.
В статье я расскажу как можно реализовать эту модель на практике. Для разработки я использую Unity и C#, но большинство вещей верны для других движков и языков. В этом туториале я не разжёвываю основы работы с Unity, подразумевается, что вы знаете эффект комбинации Ctrl+Shift+N на сцене, умеете работать с инспектором, дублировать и двигать объекты. Если нет, то советую начать с этой статьи. Или можете просто посмотреть на картинки.
 Мультиязычные сайты — это хорошо, но довольно муторно. И если для
Мультиязычные сайты — это хорошо, но довольно муторно. И если для 
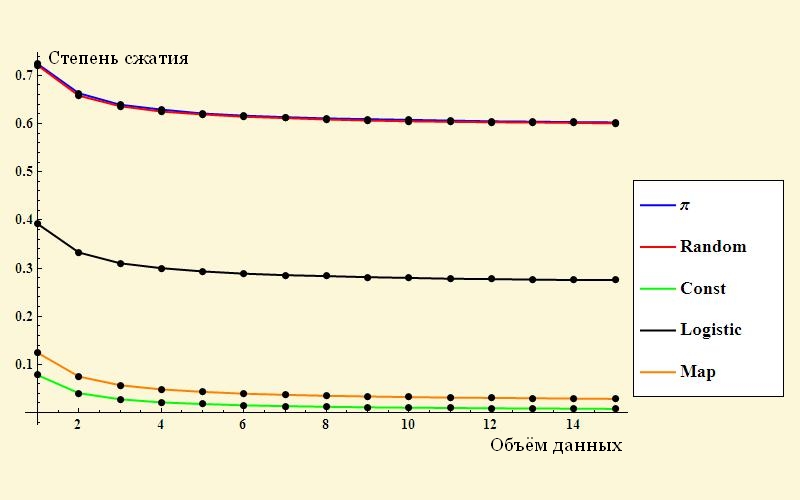
 В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке.
В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке.