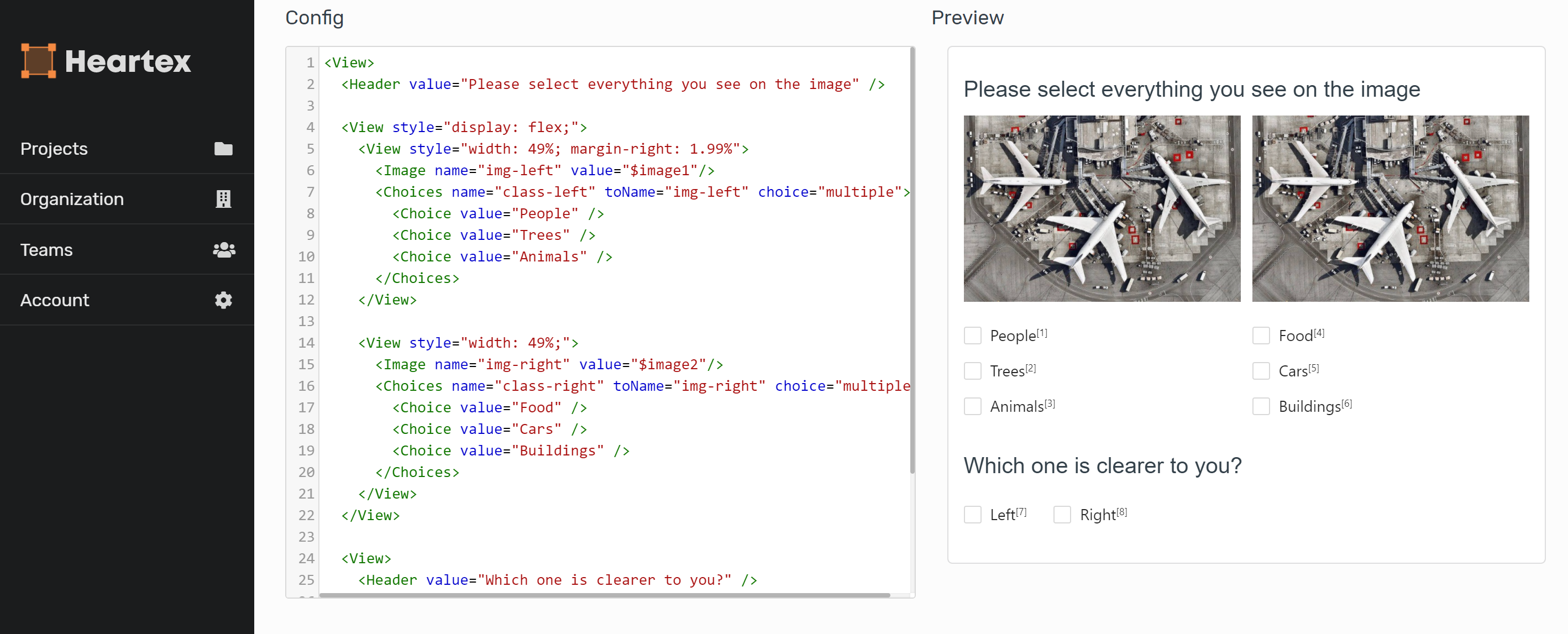
Несмотря на масштабный переход к цифровым технологиям, часть наиболее сложных данных по-прежнему хранится в виде текста в статьях или официальных документах. В условиях изобилия публично доступной информации возникают трудности с управлением неструктурированными сырыми данными и их преобразования в понятный для машин вид. С текстом это сделать сложнее, чем с изображениями и видео. Возьмём для примера простое предложение: «They nailed it!». Люди бы поняли его как выражение одобрения, подбадривания или признания заслуг, однако традиционная модель обработки естественного языка (Natural Language Processing, NLP), скорее всего, воспримет только поверхностное понимание слова, упустив смысл. А именно, она бы ассоциировала слово «nail» с забиванием гвоздей молотком. Точные аннотации текста помогают моделям лучше понимать передаваемые им данные, что приводит к безошибочной интерпретации текста.