Код этого поста, как и сам пост, выложен на
github.
До недавнего времени регулярные выражения казались мне какой-то магией. Я никак не мог понять, как можно определить, соответствует ли строка заданному регулярному выражению. А теперь я это понял! Ниже представлена реализация простого движка регулярных выражений менее чем в 200 строках кода.
Часть 1: Парсинг
Спецификация
Реализация регулярных выражений полностью — довольно сложная задача; хуже того, она мало чему вас научит. Реализуемой нами версии достаточно для того, чтобы изучить тему, не скатываясь в рутину. Наш язык регулярных выражений будет поддерживать следующее:
. — соответствие любому символу| — соответствие abc или cde+ — соответствие одному или более предыдущего паттерна* — соответствие 0 или более предыдущего паттерна( и ) — для группировки
Хотя набор опций невелик, с его помощью можно создать интересные regex-ы, например,
m (t|n| ) | b позволяющий найти субтитры к Star Wars без субтитров к Star Trek, или
(..)* для нахождения множества всех строк чётной длины.
План атаки
Мы будем анализировать регулярные выражения в три этапа:
- Парсинг (синтаксический анализ) регулярного выражения в синтаксическое дерево
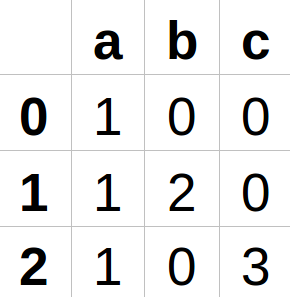
- Преобразование синтаксического дерева в конечный автомат
- Анализ конечного автомата для нашей строки
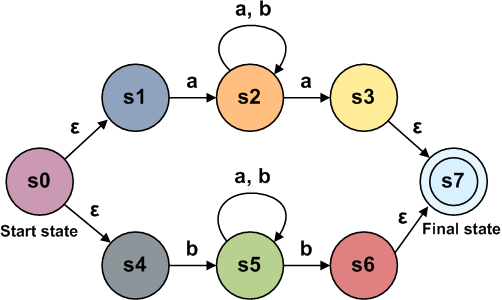
Для анализа регулярных выражений (подробнее об этом ниже) мы будем использовать конечный автомат под названием
NFA. На высоком уровне NFA будет представлять наш regex. При получении входных данных мы будем перемещаться в NFA от состояния к состоянию. Если мы придём в точку, из которой невозможно совершить допустимого перехода, то регулярное выражение не соответствует строке.






 Итак, эта статья посвящается тем, кто любит решать нестандартные задачи на не предназначенных для этого инструментах. Здесь я опишу основные проблемы, с которыми столкнулся во время создания аналога игры Gravity defied с использованием потокового текстового редактора (sed).
Итак, эта статья посвящается тем, кто любит решать нестандартные задачи на не предназначенных для этого инструментах. Здесь я опишу основные проблемы, с которыми столкнулся во время создания аналога игры Gravity defied с использованием потокового текстового редактора (sed). 

 Плюнь тому в глаза, кто скажет, что можно обнять необъятное!
Плюнь тому в глаза, кто скажет, что можно обнять необъятное! 
