Известные ParserCombinator'ы и Parboiled предназначены исключительно для разбора формальных языков. Мы же решаем задачу разбора естественного языка и при этом хотим, чтобы с помощью той же грамматики можно было осуществлять синтез фраз на естественном языке, отражающих требуемую нам семантику. Было бы удобно иметь возможность описывать языковые конструкции вместе с правилами абстрагирования/конкретизации.
Например,
Причём хотелось бы иметь следующие системные свойства:
Под катом — описание подхода, реализованного в библиотеке synapse-typed-expressions. Рассмотрены только числительные, но подход естественным образом распространяется на другие вышеупомянутые формальные языковые конструкции.
Например,
- Преобразование числительных в число («десять» -> 10:Int)
- и обратно (10:Int -> «десять» («десятый», «десяток» ...))
- Преобразование числительных вместе с единицей измерения («десять рублей» <-> NumberWithMeasurement(10, RUB))
- Неполный адрес («ул. Яблочная» <-> Address(street=«Яблочная»))
- Адрес в пределах города («улица Яблочная дом сто двадцать три квартира сорок пять» <-> Address(street=«Яблочная», building=123, flat=45))
- Телефон (256-00-21 («двести пятьдесят шесть ноль ноль двадцать один») <-> NumericalSequence(256,0,0,21))
Причём хотелось бы иметь следующие системные свойства:
- единственность описания правил абстрагирования/конкретизации
- строго типизированное представление семантики на всех уровнях абстракции
- наличие альтернативных форм представления семантики и возможность повлиять на выбор формы представления семантики
- согласование словоформ для получения фразы на чистом русском языке
- возможность формирования вторичных структур на основе исходных правил. В частности, мы бы хотели формировать грамматики разбора, соответствующие правилам.
Под катом — описание подхода, реализованного в библиотеке synapse-typed-expressions. Рассмотрены только числительные, но подход естественным образом распространяется на другие вышеупомянутые формальные языковые конструкции.



 Наткнулся в интернете на очередную игру для программистов.
Наткнулся в интернете на очередную игру для программистов.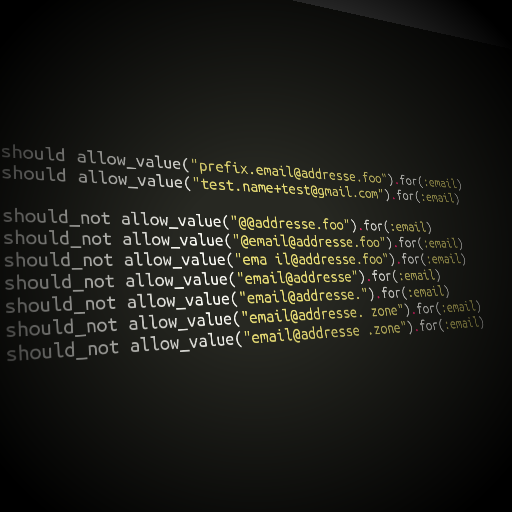


 В расширениях Хрома принято указывать версию скрипта в виде не более чем 4 чисел, разделённых точками, и величиной не более 32767 каждое и не начинающихся с цифры 0. Этого более чем достаточно, если в номер версии включены обычные данные: версия, подверсия, сборка. Если в версию хотим поместить дату в виде 3 чисел, то в наиболее удобной для чтения записи (версия.год.месяц.день) числа года, месяца и дня занимают 3 места из 4. На версию остаётся первое число (как более приоритетное перед датой), а на подверсию и минор ничего не остаётся. Задача: как расположить минорную версию, чтобы уложиться в формат, чтобы дата была читаемой, а версия с минором при сравнении 2 строк занимала правильное место в ряду версий? Кроме того, нужна процедура выделения даты и версии с минором из общей строки.
В расширениях Хрома принято указывать версию скрипта в виде не более чем 4 чисел, разделённых точками, и величиной не более 32767 каждое и не начинающихся с цифры 0. Этого более чем достаточно, если в номер версии включены обычные данные: версия, подверсия, сборка. Если в версию хотим поместить дату в виде 3 чисел, то в наиболее удобной для чтения записи (версия.год.месяц.день) числа года, месяца и дня занимают 3 места из 4. На версию остаётся первое число (как более приоритетное перед датой), а на подверсию и минор ничего не остаётся. Задача: как расположить минорную версию, чтобы уложиться в формат, чтобы дата была читаемой, а версия с минором при сравнении 2 строк занимала правильное место в ряду версий? Кроме того, нужна процедура выделения даты и версии с минором из общей строки.