 Фото: Duke University
Фото: Duke UniversityИсследователи показали работу новой системы на ИИ, которая генерирует изображение «с повышением частоты дискретизации» в 64 раза по сравнению с оригиналом с низким разрешением. В разработке использовали алгоритм исследования скрытого пространства. Система показала, что воспроизведенное изображение может кардинально отличаться от оригинала.
Синтия Рудин, профессор компьютерных наук в Университете Дьюка в Дареме, Северная Каролина, прокомментировала разработку: «Мы доказали, что вы не можете распознать лица по размытым изображениям, потому что здесь слишком много возможностей. Таким образом, масштабирование и улучшение, превышающие определенный пороговый уровень, не могут существовать».
Модуль Python PULSE, который разработала команда, тем не менее, может применяться если не в целях распознавания лиц, то в астрономии, медицине или в художественной сфере. В целом, отмечают исследователи, PULSE дает более широкое понимание исходного изображения. Оно не воспроизводит лицо с исходника, но «придумывает» множество похожих.
Рудин привела в пример размытый снимок черной дыры. В сочетании с инструментом визуализации на ИИ, которые генерируют астрономические изображения, PULSE может воспроизводить возможные астрофизические сценарии, которые могли бы привести к получению этой фотографии с низким разрешением.
При традиционном методе распознавания изображение с низким разрешением загружают в систему, а та «угадывают», какие дополнительные пиксели необходимо добавить, чтобы они, в среднем, соответствующим пикселям в изображении с высоким разрешением, на которых обучали алгоритм. В результате этого усреднения текстурированные участки волос и кожи выглядят нечеткими.
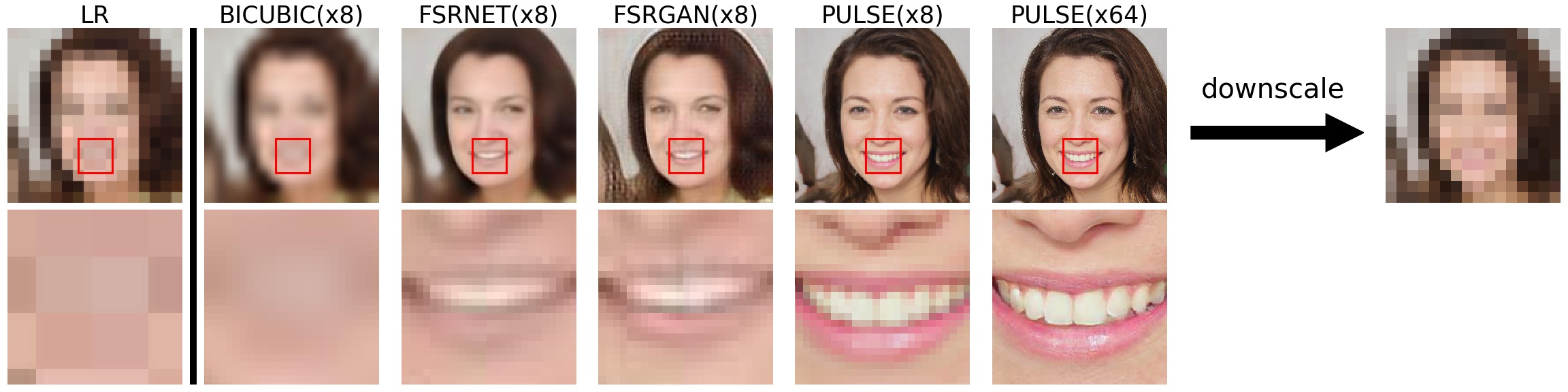
В случае с PULSE, вместо того, чтобы считывать изображение с низким разрешением и медленно добавлять в него новые детали, система просматривает сгенерированные ИИ примеры лиц с высоким разрешением, ища те, которые максимально похожи на входной снимок при уменьшении до того же размера.
На данный момент PULSE оптимизирован именно для работы с портретами, потому что функционирует на алгоритме NVIDIA StyleGAN, который создает фотореалистичные лица.
По мнению Рудин, PULSE можно задействовать также в областях архитектуры и дизайна, если оптимизировать для этого StyleGAN.
«Каждый раз, когда у вас появляется подобный тип генеративного моделирования, вы можете использовать PULSE для организации поиска в этом пространстве», — заключила исследователь.
Код модели выложили на GitHub.
В 2019 году ученые Массачусетского технологического института разработали метод, позволяющий восстанавливать скрытое на видео, используя тени и отражения. Алгоритм анализирует взаимодействие теней и геометрии на видео и делает прогноз «переноса света». Так, если в комнате установлена видеокамера, он поможет реконструировать видеоизображение невидимого угла помещения.
См. также:




