Прочитал сегодня на хабре перевод статьи Распределение символов в паролях. Захотелось провести свой небольшой анализ. Интерес для меня представляют длины паролей, первые символы паролей и используемые в паролях биграммы (пар смежных символов). А также в статье будет рассмотрен алгоритм улучшенного полного перебора паролей.
Скачал архив с паролями отсюда: http://thepiratebay.org/torrent/6443601
Использовал для анализа только 1 файл: Sony_Pictures_International_BEAUTY_USERS.txt
Количество паролей: 20 921
Картинки в статье кликабельны.
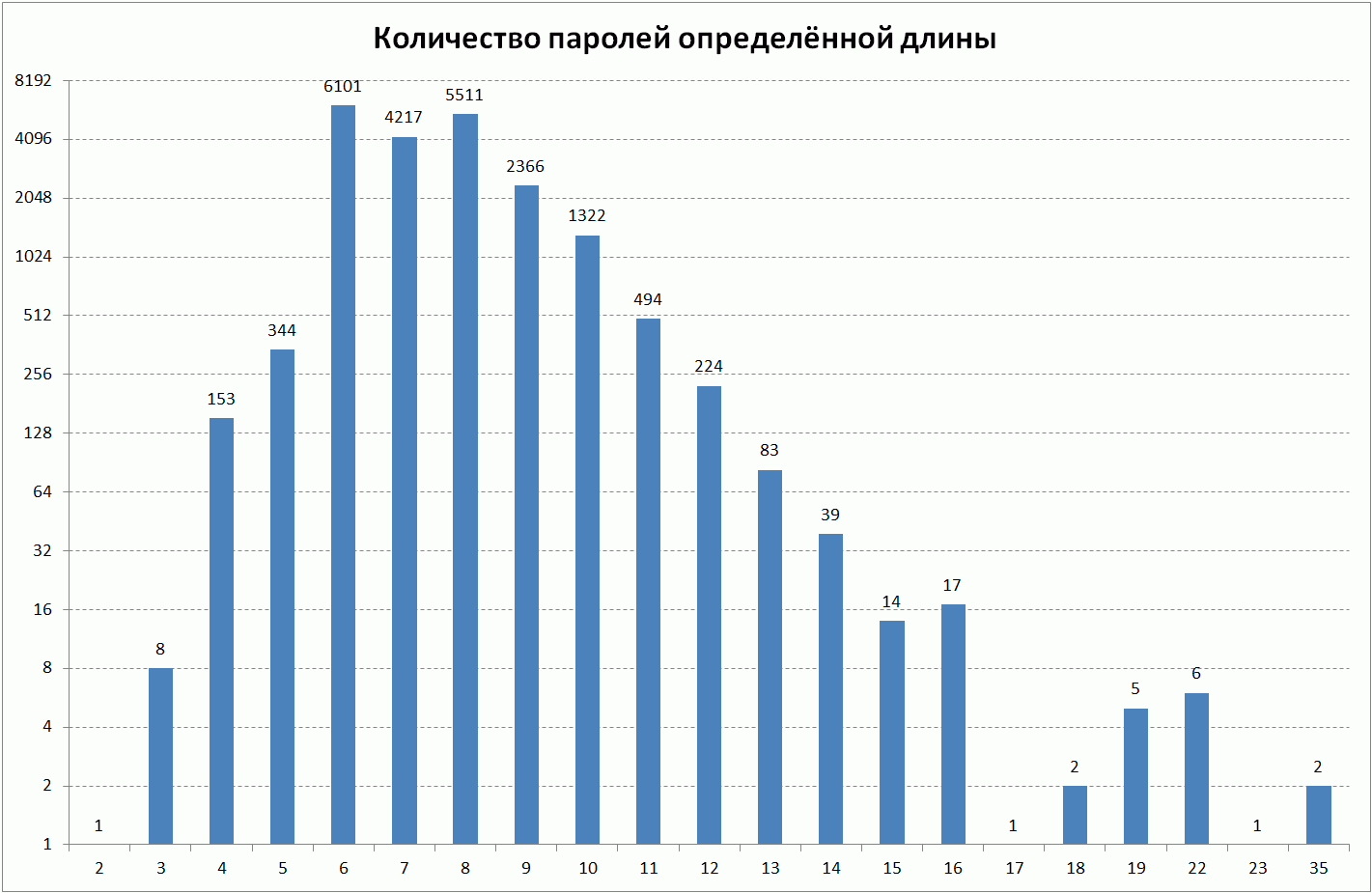
Видно, что пароли пользователей имеют различные длины. Удивляет, что у пользователей встречаются пароли короче 6-ти символов. Странно, что система регистрации вообще позволяет использовать такие пароли. Количество паролей такой длины составляет менее 2,5% от всех общего числа паролей. Имеется 2 пароля длиной 35 — очень похоже, что они получены какой-нибудь программой для генерации паролей.
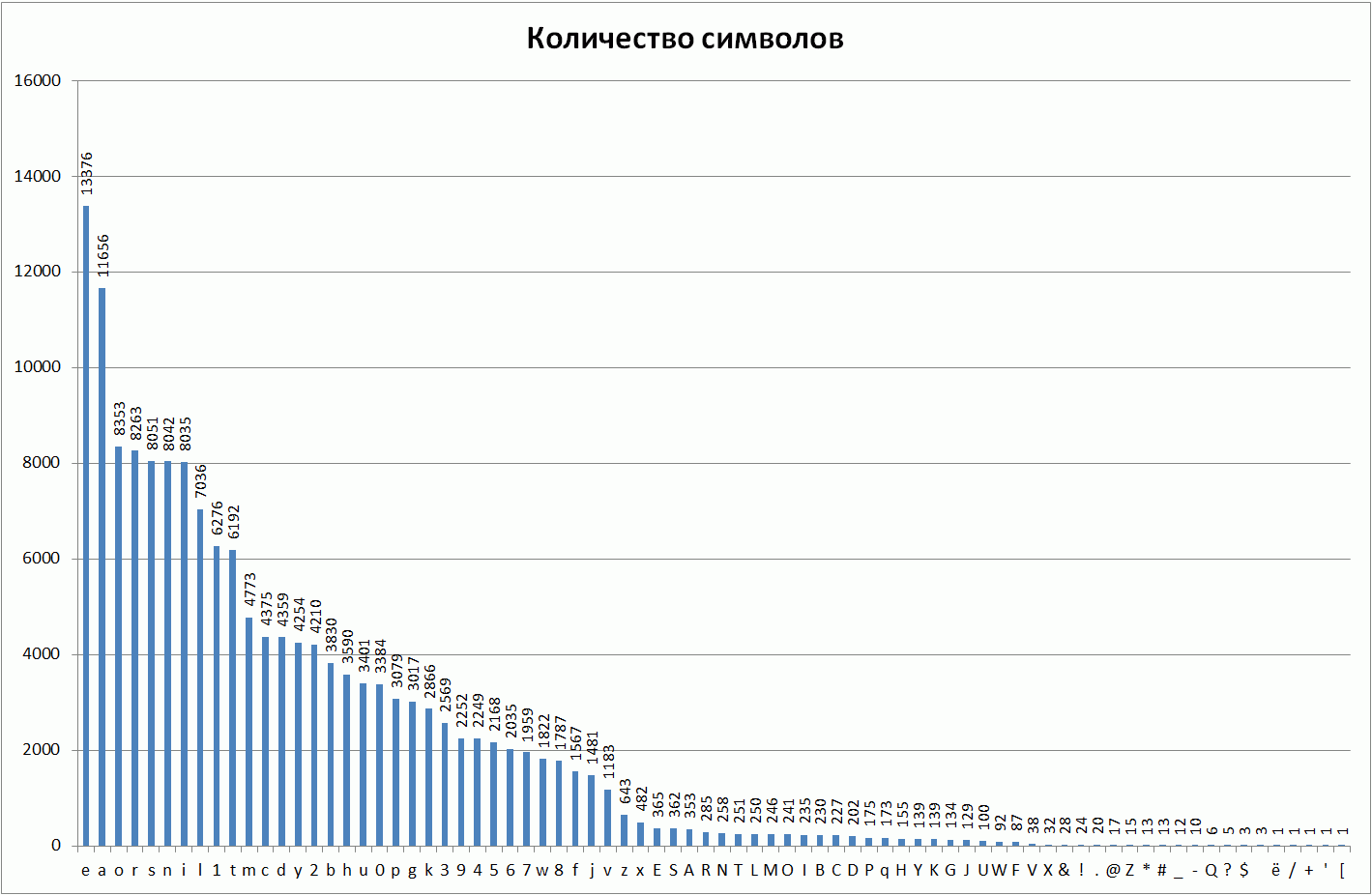
Как и ожидалось, гласные по популярности на первом месте, за ними идут согласные с цифрами. Символы в верхнем регистре используются на порядок реже. Число символов в верхнем регистре составляют менее 2,8% от числа всех символов.
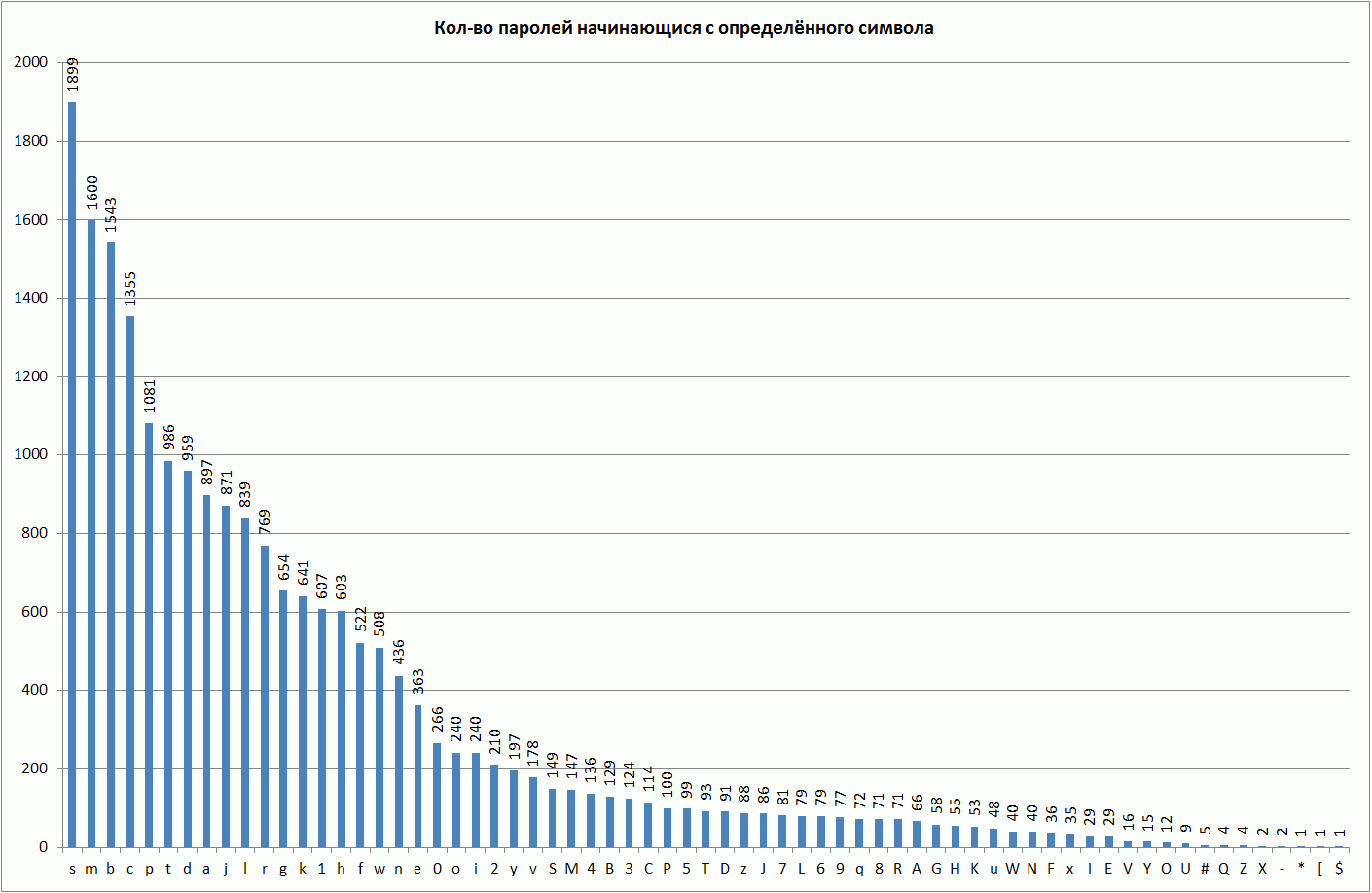
Чаще всего пароли начинаются с символов s,m,b,c. Следующими по популярности являются символы p,t,d,a,j,l,r. Менее популярна группа символов g,k,1,h,f,w,n,e. Все остальные символы менее популярны в данном смысле.
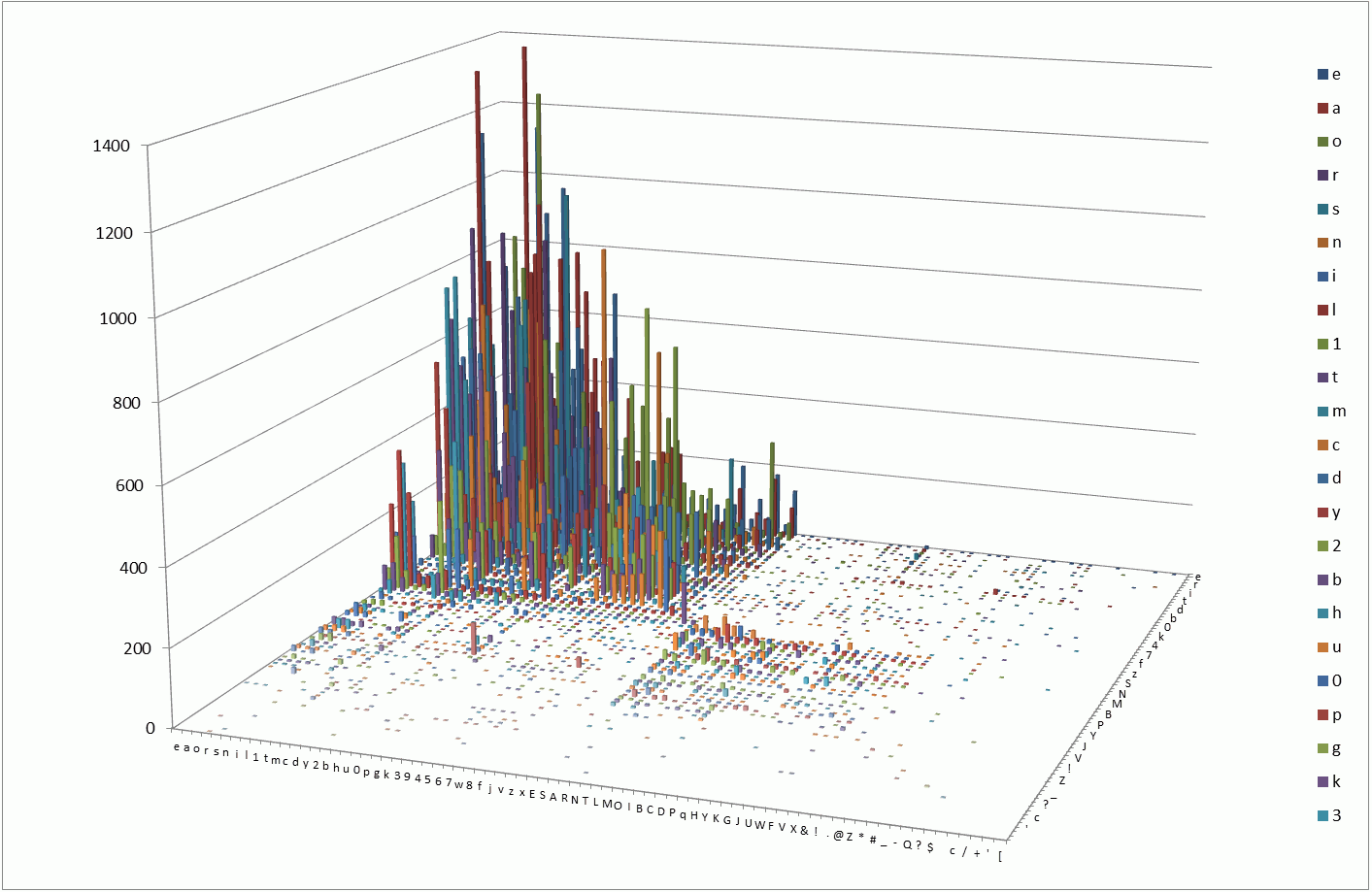
Как видно из диаграммы, распределение биграмм весьма не случайное. Пять самых встречающихся биграмм в порядке уменьшения популярности:
ar(1367), le(1315), on(1239), ie(1136), es(1134).
Теперь рассмотрим алгоритм линеаризации перебора комбинаций слов из двух символов. Символы принадлежат счётному алгоритму (не обязательно конечному).

Что делать, если у необходимо организовать перебор слов из трёх символов счётного алфавита? Придумывать формулы для обхода трёхмерного куба не хочется. Можно организовать обход квадрата, а один из символов интерпретировать как номер в последовательности обхода двухсимвольных слов. Таким образом можно организовать обход слов любой заданной длины.
Отдельное внимание следует уделить обходу слов разной длины. Необходимо дополнительно линеаризовать обход «длины слова» и самого слова. Таким образом будут перебираться слова всех длин, символы которых принадлежат счётному множеству.
По сути теперь перед нами стоит задача перебора слов всех длин и с бесконечным алфавитом. Алфавит на самом деле конечный, но в общем случае задачу так решать проще.
Теперь составим следующие линейные списки:
— Длины паролей
— Первые символы паролей
— Вторые символы биграмм
Составим перечень длин паролей по их популярности:
6, 8, 7, 9, 10, 11, 12, 13, 14, 16,15
Составим перечень первых символов в паролях по их популярности:
s,m,b,c,p,t,d,a,j,l,r,g,k,1,h,f,w,n,e,0,o,i,2,y,v,S,M,4,B,3,C,P,5,T,D,z,…
Составим списки вторых символов из биграмм по популярности для заданных первых букв биграмм:
e: s,l,n,e,y,t,1,b,r,c,w,2,v,x,f,3,4,a,7,5,k,6,9,j,h,u,d,m,8,z,p,o,…
a: r,t,s,l,m,c,d,b,i,y,g,p,k,u,h,v,w,x,2,f,0,j,4,9,3,7,1,6,n,z,e,o,…
o: n,o,r,l,m,u,s,g,v,k,b,d,c,1,2,x,i,w,p,t,0,3,6,j,z,5,9,7,e,y,a,8,…
r: a,i,o,l,d,t,1,r,k,n,e,g,b,c,4,5,7,8,s,v,3,6,u,9,w,y,h,j,2,p,m,z,…
…
Теперь можно организовать линейный перебор паролей, начиная с самых популярных вариантов. И возможно решить обратную задачу. Из конкретного пароля вывести его номер в перебираемой последовательности. Это, правда, немного трудновато из-за того что список букв алфавита выбирается на основе предыдущей буквы.
Если тема окажется интересной сообществу, постараюсь получить номер пароля в последовательности паролей в одной из своих следующих статей.
Скачал архив с паролями отсюда: http://thepiratebay.org/torrent/6443601
Использовал для анализа только 1 файл: Sony_Pictures_International_BEAUTY_USERS.txt
Количество паролей: 20 921
Картинки в статье кликабельны.
Какие длины паролей самые популярные?
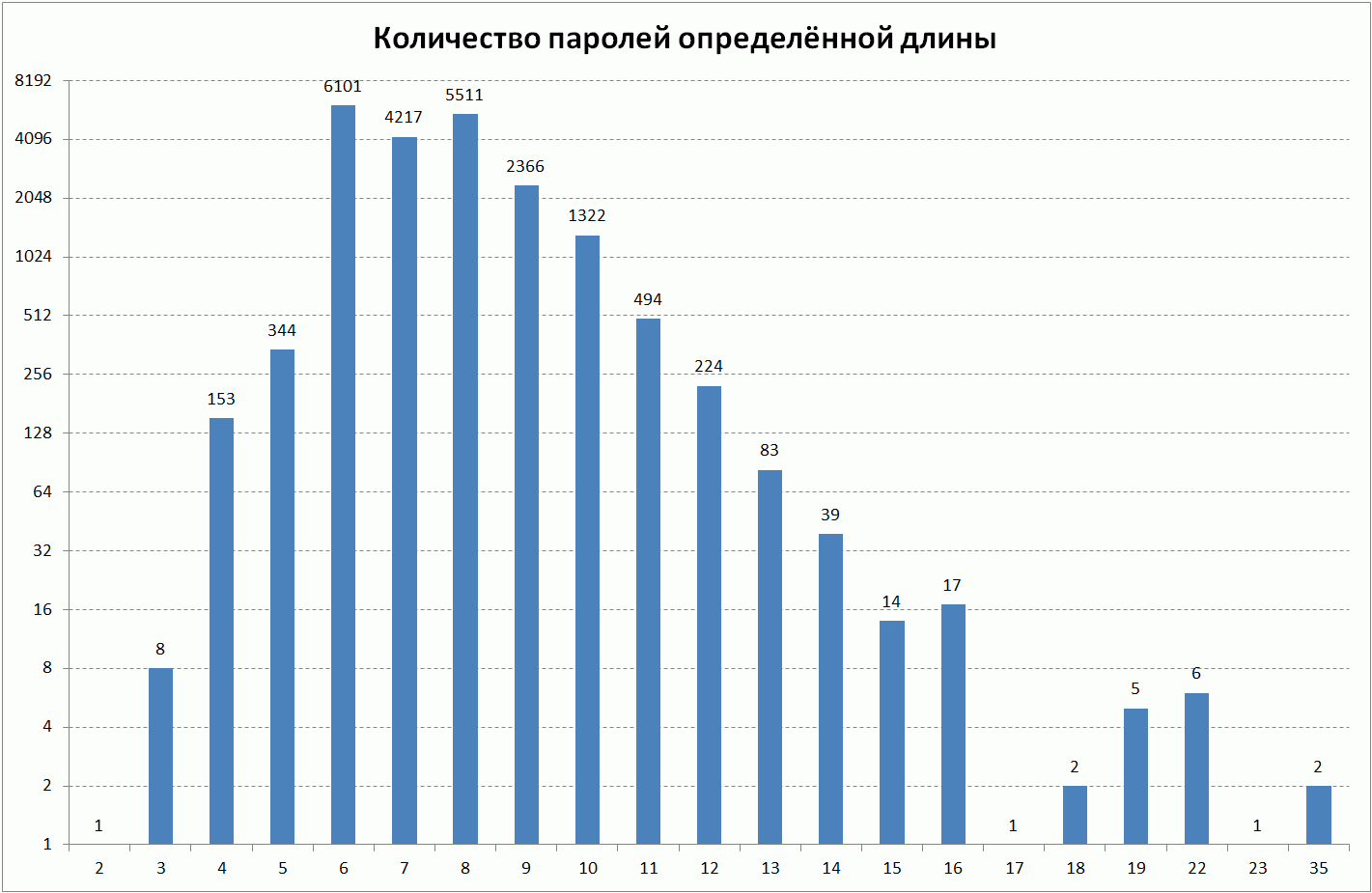
Видно, что пароли пользователей имеют различные длины. Удивляет, что у пользователей встречаются пароли короче 6-ти символов. Странно, что система регистрации вообще позволяет использовать такие пароли. Количество паролей такой длины составляет менее 2,5% от всех общего числа паролей. Имеется 2 пароля длиной 35 — очень похоже, что они получены какой-нибудь программой для генерации паролей.
Какие символы преобладают в паролях?

Как и ожидалось, гласные по популярности на первом месте, за ними идут согласные с цифрами. Символы в верхнем регистре используются на порядок реже. Число символов в верхнем регистре составляют менее 2,8% от числа всех символов.
С каких символов чаще всего начинаются пароли?
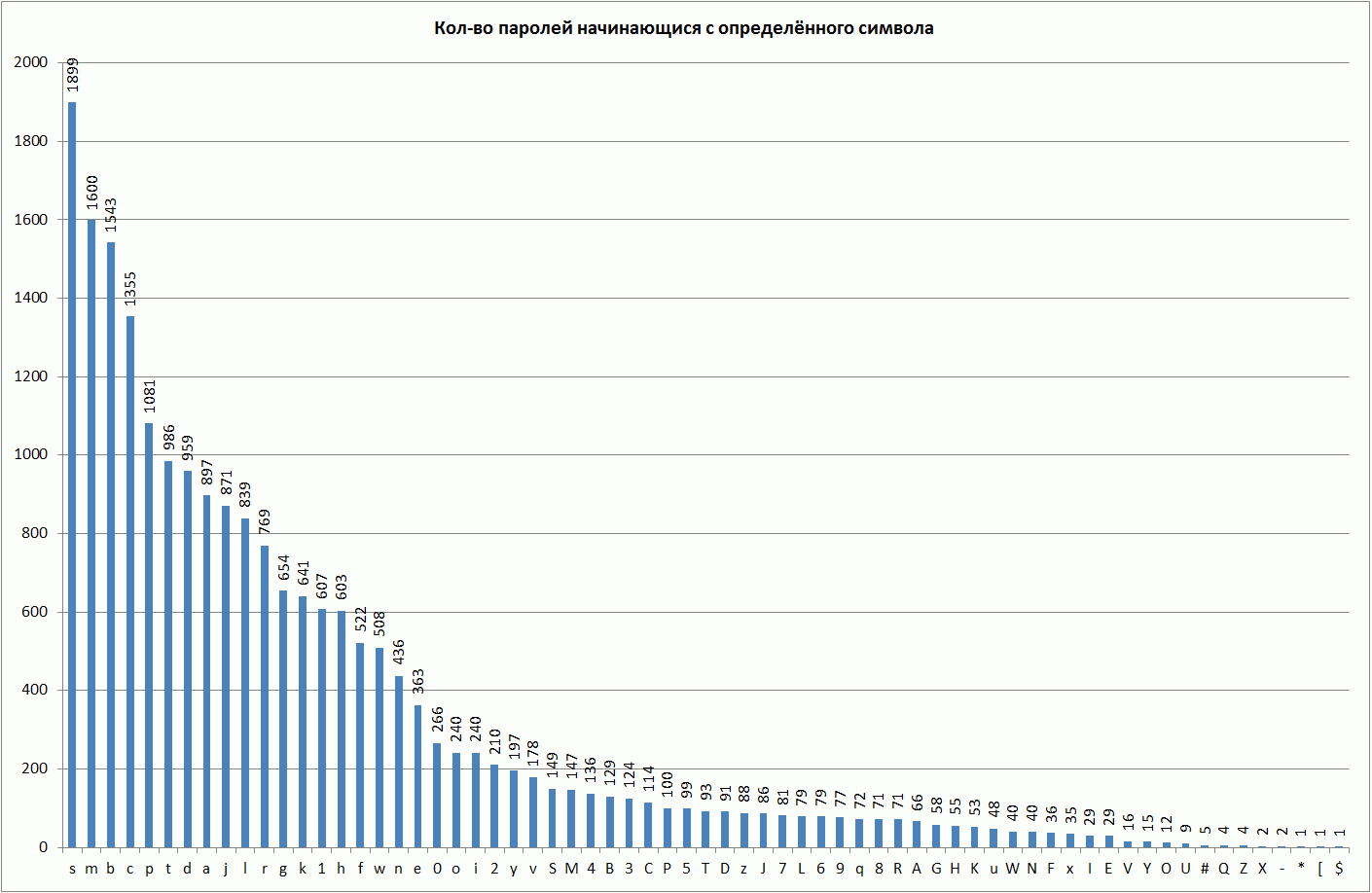
Чаще всего пароли начинаются с символов s,m,b,c. Следующими по популярности являются символы p,t,d,a,j,l,r. Менее популярна группа символов g,k,1,h,f,w,n,e. Все остальные символы менее популярны в данном смысле.
Какие биграммы (пары соседних символов) в паролях встречаются чаще других?
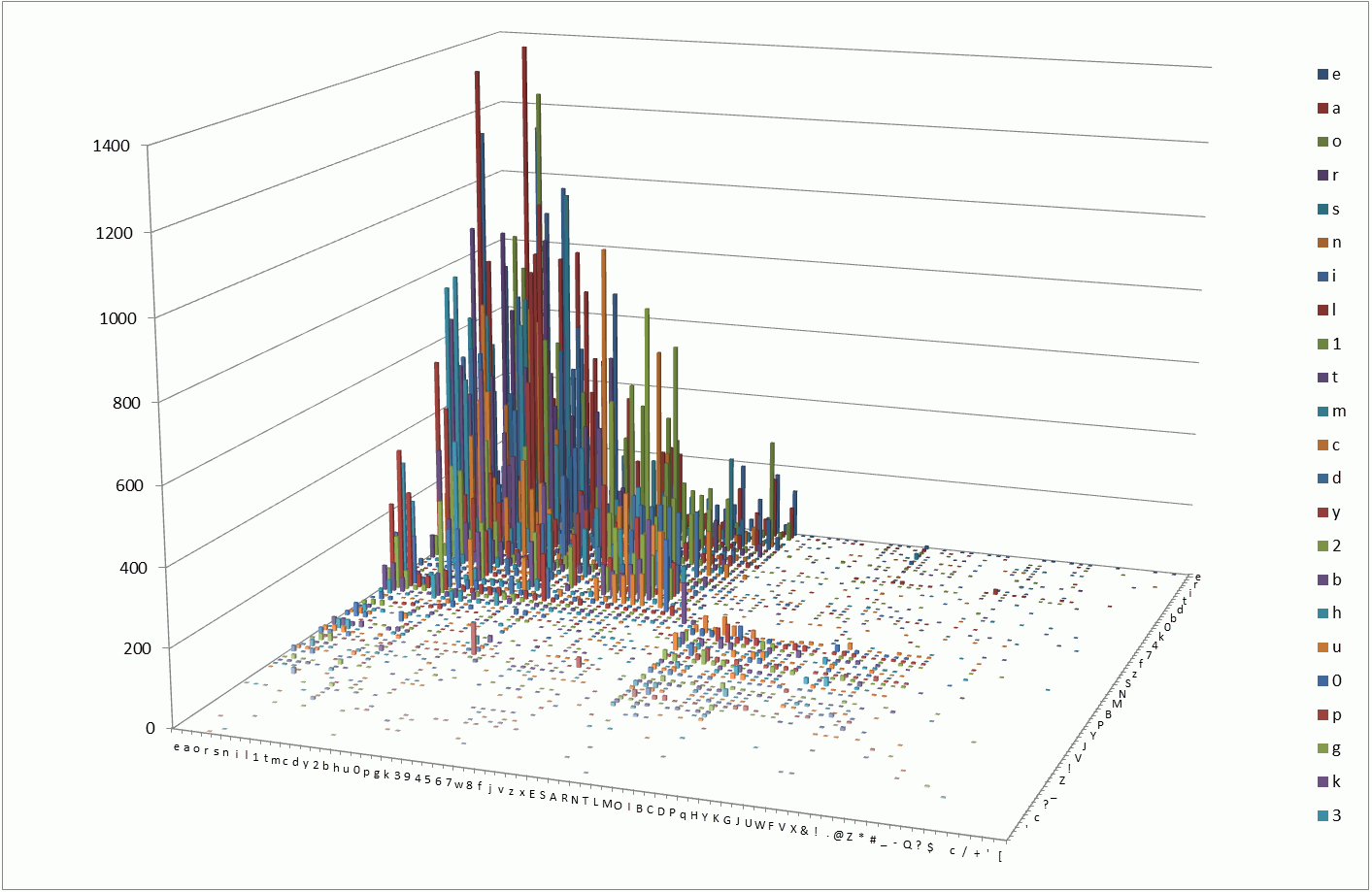
Как видно из диаграммы, распределение биграмм весьма не случайное. Пять самых встречающихся биграмм в порядке уменьшения популярности:
ar(1367), le(1315), on(1239), ie(1136), es(1134).
Алгоритм линеаризации перебора слов разной длины, символы которых принадлежат счётному алфавиту.
Теперь рассмотрим алгоритм линеаризации перебора комбинаций слов из двух символов. Символы принадлежат счётному алгоритму (не обязательно конечному).
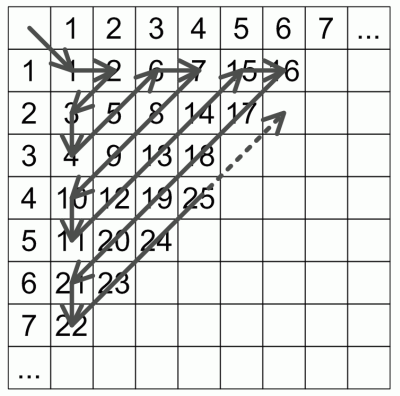
Что делать, если у необходимо организовать перебор слов из трёх символов счётного алфавита? Придумывать формулы для обхода трёхмерного куба не хочется. Можно организовать обход квадрата, а один из символов интерпретировать как номер в последовательности обхода двухсимвольных слов. Таким образом можно организовать обход слов любой заданной длины.
Отдельное внимание следует уделить обходу слов разной длины. Необходимо дополнительно линеаризовать обход «длины слова» и самого слова. Таким образом будут перебираться слова всех длин, символы которых принадлежат счётному множеству.
По сути теперь перед нами стоит задача перебора слов всех длин и с бесконечным алфавитом. Алфавит на самом деле конечный, но в общем случае задачу так решать проще.
Для чего может потребоваться вся это информация?
Теперь составим следующие линейные списки:
— Длины паролей
— Первые символы паролей
— Вторые символы биграмм
Составим перечень длин паролей по их популярности:
6, 8, 7, 9, 10, 11, 12, 13, 14, 16,15
Составим перечень первых символов в паролях по их популярности:
s,m,b,c,p,t,d,a,j,l,r,g,k,1,h,f,w,n,e,0,o,i,2,y,v,S,M,4,B,3,C,P,5,T,D,z,…
Составим списки вторых символов из биграмм по популярности для заданных первых букв биграмм:
e: s,l,n,e,y,t,1,b,r,c,w,2,v,x,f,3,4,a,7,5,k,6,9,j,h,u,d,m,8,z,p,o,…
a: r,t,s,l,m,c,d,b,i,y,g,p,k,u,h,v,w,x,2,f,0,j,4,9,3,7,1,6,n,z,e,o,…
o: n,o,r,l,m,u,s,g,v,k,b,d,c,1,2,x,i,w,p,t,0,3,6,j,z,5,9,7,e,y,a,8,…
r: a,i,o,l,d,t,1,r,k,n,e,g,b,c,4,5,7,8,s,v,3,6,u,9,w,y,h,j,2,p,m,z,…
…
Теперь можно организовать линейный перебор паролей, начиная с самых популярных вариантов. И возможно решить обратную задачу. Из конкретного пароля вывести его номер в перебираемой последовательности. Это, правда, немного трудновато из-за того что список букв алфавита выбирается на основе предыдущей буквы.
Если тема окажется интересной сообществу, постараюсь получить номер пароля в последовательности паролей в одной из своих следующих статей.








