Эта статья по логике должна была появиться первой, перед статьей про Transparent Page Sharing, так как это база, с которой должно начинаться погружение в управление ресурсами памяти в vSphere 4.1.
В моем англоязычном блоге, когда я только начинал изучать эту тему, я разбил ее на две части — мне самому было так легче воспринимать совершенно новую для меня информацию. Но так как публика на хабре серьезная и бывалая, то я решил объединить материал в одну статью.
Начнем мы с самого основного элемента, который называется Memory Page. Ему дается следующее определение — непрерывный блок данных фиксированного размера, используемый для распределения памяти. Как правило размер страницы может быть 4 Кбайта (Small Page) или 2 Мбайта (Large Page). Каждому приложению ОС выделяет 2 Гбайта виртуальной памяти, которая принадлежит только этому приложению. Чтобы ОС могла знать какой странице физической памяти (Physical Address — PA) соответствует определенная страница виртуальной памяти (Virtual Address — VA) ОС ведет учет всех страниц памяти с помощью Page Table. Именно там хранятся все соответствия между VA и PA.
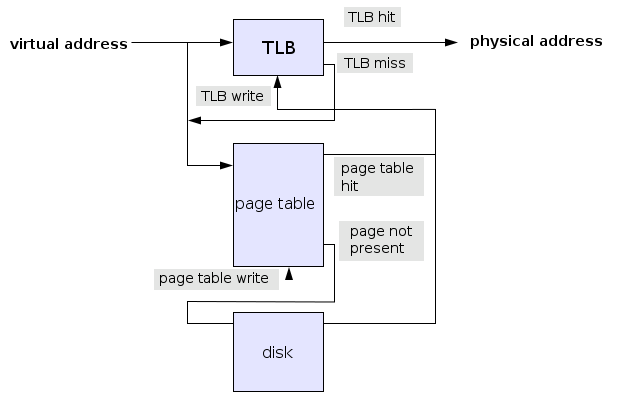
Далее нам нужен какой либо инструмент, который сможет по запросу приложения к памяти находить в Page Table нужную пару VA — PA. Такой инструмент называется Memory Management Unit (MMU). Процесс поиска пары VA-PA не всегда может быть быстрым, если учесть, что в 2 Гбайтном виртуальном адресном пространстве может быть до 524 288 страниц размером 4 Кбайта. Для ускорения подобного рода поиска MMU активно использует Translation Lookaside Buffer (TLB), в котором хранятся недавно используемые пары VA-PA. Каждый раз, когда приложение выполняет запрос к памяти MMU сначала проверяет TLB на наличие там пары VA-PA. Если она там есть — здорово, PA отдается процессору — это называется TLB hit. Если же в TLB ничего не найдено (TLB miss), тогда MMU приходится «шерстить» всю Page Table и как только искомая пара найдена, поместить ее в TLB и дать приложению знать, что можно отправлять запрос еще раз.
Если же нужная страница находится в свопе, то сначала страницу отправляют из свопа обратно в память, потом пару VA-PA пишут в TLB и только потом происходит доступ приложения к памяти. Визуально это выглядит вот так
TLB существенно ограничена в размерах. В Nehalem процессорах TLB первого уровня содержит 64 записи 4 кбайтных страниц или 32 записи 2 Мбайтных страниц, TLB второго уровня умеет работать только с маленькими страницами и содержит 512 записей. Исходя из этого можно предположить, что использование больших страниц будет приводить к существенно меньшему количеству TLB miss — (64x4=256)+(512x4=2048)=2304 Кбайта против 32x2=64 Мбайт.
Не могу удержаться от выкладки из Википедии стоимости TLB miss, где рассматривается некая усредненная TLB.
Size: 8 — 4,096 entries
Hit time: 0.5 — 1 clock cycle
Miss penalty: 10 — 100 clock cycles
Miss rate: 0.01 — 1%
Если TLB hit исполняется за один CPU цикл, TLB miss отнимает 30 циклов, и если средняя частота TLB miss составляет 1%, то среднее количество циклов на один запрос памяти составляет 1.30.
Все эти рассуждения и вычисления справедливы для ситуаций когда наша ОС работает на физическом сервере. Но в случае когда ОС работает на виртуальной машине у нас появляется еще один уровень трансляции памяти. Когда приложение в виртуальной машине делает запрос к памяти, оно использует виртуальный адрес (VA), который должен быть транслирован в физический адрес виртуальной машины (PA), который в свою очередь должен быть транслирован в физический адрес памяти ESXi хоста (HA). То есть нам нужны уже две Page Table: одна для VA-PA пар, другая для PA-HA трансляций
Если постараться это отобразить графически, то мы получаем приблизительно такую картинку.

Мне не хочется лезть в глубокие исторические дебри технологий виртуализации памяти на заре появления ESX, поэтому мы рассмотрим последние две — Software Memory Virtualization и Hardware Assisted Memory Virtualization. Тут мне надо ввести в наше повествование еще один элемент Virtual Machine Monitor (VMM). VMM задействован в исполнении всех команд, которые отдает виртуальная машина процессору и памяти. Для каждой виртуальный машины существует отдельный VMM процесс.
Теперь, когда мы освежили основы, можно перейти и к некоторым деталям.
Software Memory Virtualization
Итак, как видно из названия, у нас тут наблюдается программная реализация виртуализации памяти. При этом VMM создает Shadow Page Table, в которую копируются следующие трансляции:
1. VA — PA, эти пары адресов напрямую копируются из Page Table виртуальной машины, за содержание которой отвечает гостевая ОС.
2. PA — HA, за эти пары адресов отвечает сама VMM
То есть, это эдакая суммарная таблица двойной трансляции. Каждый раз, когда приложение в виртуальной машине обращается к памяти (VA), MMU должна заглянуть в Shadow Page Table и найти соответствующую пару VA — HA, чтобы физический процессор мог работать с реальным физическим адресом памяти хоста (HA). При этом достигается изоляция MMU от виртуальной машины, с тем чтобы одна виртуальная машина не получила доступ к памяти другой виртуальной машины.
Согласно документации VMware такой тип трансляции адресов очень сравним по скорости с трансляцией адресов на обычном физическом сервере.
Спрашивается, к чему тогда городить огород и выдумывать новые технологии? Оказывается есть к чему — не все типы запросы к памяти от виртуальной машины могут быть выполнены с такой же скоростью как на физическом сервере. Например, каждый раз, когда происходить изменение в Page Table в ОС виртуальной машины (то есть изменяется VA — PA пара), VMM должна перехватить этот запрос и обновить соответствующую секцию Shadow Page Table (то есть результирующую пару VA — HA). Еще одним хорошим примером является ситуация, когда приложение делает самый первый запрос к определенному участку памяти. Поскольку VMM до сих пор не слышала про этот VA ничего, то есть надо создать новую запись в Shadow Page Table, таким образом опять привнося задержку в обращении к памяти. Ну и наконец, хоть это и не критично, можно отметить, что сама Shadow Page Table тоже потребляет память. Эта технология применима к vSphere, работающей на процессорах, которые были выпущены до появления на рынке семейств Nehalem/Barcelona.
Hardware Assisted Memory Virtualization
На данный момент, на рынке есть две основные технологии виртуализации MMU. Первая была представлена компанией Intel в семействе процессоров Nehalem и называется этот новый функционал — Extended Page Tables (EPT). Вторая была представлена компанией AMD в процессорах семейства Barcelona под названием Rapid Virtualization Indexing (RVI). В принципе, обе технологии выполняют один и тот же функционал, и различаются только в очень глубоко технических деталях, изучением которых я пренебрег в силу малозначительности их для моей работы.
Так вот, основное преимущество обеих технологий это то, что теперь новая MMU может одновременно запускать два процесса поиска адресов в Page Tables. Первый процесс ищет пару VA — PA в Page Table вашей виртуальной машины, другой процесс ищет PA — HA пару в Page Table, которой управляет VMM. Вторая Page Table и называется Extended (иногда Nested) Page Table. Как только обе пары найдены, MMU записывает результирующую пару VA — PA в TLB. Так как обе таблицы теперь доступны MMU необходимости содержания Shadow Page Table теперь нет. Другой важный момент это то, что теперь когда обе таблицы отделены друг от друга виртуальная машина может спокойно сама управляться со своей Page Table без контроля со стороны VMM.
Ну и еще одно существенное отличие архитектуры Nehalem это то, что в TLB теперь введено новое поле Virtual Processor ID. В более старых процессорах, этого поля не было, и когда процессор переключался с контекста одной виртуальной машины на контекст другой виртуальной машины все содержимое TLB удалялось по соображениям безопасности. Теперь же, с помощью VPID этого можно избежать и соответственно опять же уменьшить количество случаем TLB miss.
Единственная отмечаемая проблема такого решения это более высокая стоимость TLB miss по одной простой причине — каждый раз когда MMU не обнаруживает в TLB нужную пару адресов MMU приходится опять совершать поиск по двум таблицам. Именно поэтому, когда vSphere обнаруживает, что работает на Nehalem процессоре, она в обязательном порядке использует большие страницы. На следующей неделе я постараюсь закончить отключение поддержки больших страниц на всех наших ESXi хостах и выложить результаты производительности — в моей первой статье я уже упоминал о результатах отключения Large Pages на одном из продакшн серверов.
По ряду причин, от лени и попытки сделать материал более доступным до моего невежества, я опустил достаточно много различных нюансов и деталей. Например, такие как различные типы TLB и процессоров, дополнительная уровень трансляции памяти из Linear Address в Virtual Address, различия в работе с памятью в разных ОС, и т.д. Критика к качеству материала, техническим неточностям, каверзные вопросы, ну и вообще любой живой интерес только приветствуются, ибо помогут всем нам заполнить наши же пробелы в знаниях.
Основными источниками моего вдохновения и информации были Википедия и вот этот документ, за что мне хотелось бы сказать огромное спасибо их авторам.
В моем англоязычном блоге, когда я только начинал изучать эту тему, я разбил ее на две части — мне самому было так легче воспринимать совершенно новую для меня информацию. Но так как публика на хабре серьезная и бывалая, то я решил объединить материал в одну статью.
Начнем мы с самого основного элемента, который называется Memory Page. Ему дается следующее определение — непрерывный блок данных фиксированного размера, используемый для распределения памяти. Как правило размер страницы может быть 4 Кбайта (Small Page) или 2 Мбайта (Large Page). Каждому приложению ОС выделяет 2 Гбайта виртуальной памяти, которая принадлежит только этому приложению. Чтобы ОС могла знать какой странице физической памяти (Physical Address — PA) соответствует определенная страница виртуальной памяти (Virtual Address — VA) ОС ведет учет всех страниц памяти с помощью Page Table. Именно там хранятся все соответствия между VA и PA.
Далее нам нужен какой либо инструмент, который сможет по запросу приложения к памяти находить в Page Table нужную пару VA — PA. Такой инструмент называется Memory Management Unit (MMU). Процесс поиска пары VA-PA не всегда может быть быстрым, если учесть, что в 2 Гбайтном виртуальном адресном пространстве может быть до 524 288 страниц размером 4 Кбайта. Для ускорения подобного рода поиска MMU активно использует Translation Lookaside Buffer (TLB), в котором хранятся недавно используемые пары VA-PA. Каждый раз, когда приложение выполняет запрос к памяти MMU сначала проверяет TLB на наличие там пары VA-PA. Если она там есть — здорово, PA отдается процессору — это называется TLB hit. Если же в TLB ничего не найдено (TLB miss), тогда MMU приходится «шерстить» всю Page Table и как только искомая пара найдена, поместить ее в TLB и дать приложению знать, что можно отправлять запрос еще раз.
Если же нужная страница находится в свопе, то сначала страницу отправляют из свопа обратно в память, потом пару VA-PA пишут в TLB и только потом происходит доступ приложения к памяти. Визуально это выглядит вот так

TLB существенно ограничена в размерах. В Nehalem процессорах TLB первого уровня содержит 64 записи 4 кбайтных страниц или 32 записи 2 Мбайтных страниц, TLB второго уровня умеет работать только с маленькими страницами и содержит 512 записей. Исходя из этого можно предположить, что использование больших страниц будет приводить к существенно меньшему количеству TLB miss — (64x4=256)+(512x4=2048)=2304 Кбайта против 32x2=64 Мбайт.
Не могу удержаться от выкладки из Википедии стоимости TLB miss, где рассматривается некая усредненная TLB.
Size: 8 — 4,096 entries
Hit time: 0.5 — 1 clock cycle
Miss penalty: 10 — 100 clock cycles
Miss rate: 0.01 — 1%
Если TLB hit исполняется за один CPU цикл, TLB miss отнимает 30 циклов, и если средняя частота TLB miss составляет 1%, то среднее количество циклов на один запрос памяти составляет 1.30.
Все эти рассуждения и вычисления справедливы для ситуаций когда наша ОС работает на физическом сервере. Но в случае когда ОС работает на виртуальной машине у нас появляется еще один уровень трансляции памяти. Когда приложение в виртуальной машине делает запрос к памяти, оно использует виртуальный адрес (VA), который должен быть транслирован в физический адрес виртуальной машины (PA), который в свою очередь должен быть транслирован в физический адрес памяти ESXi хоста (HA). То есть нам нужны уже две Page Table: одна для VA-PA пар, другая для PA-HA трансляций
Если постараться это отобразить графически, то мы получаем приблизительно такую картинку.

Мне не хочется лезть в глубокие исторические дебри технологий виртуализации памяти на заре появления ESX, поэтому мы рассмотрим последние две — Software Memory Virtualization и Hardware Assisted Memory Virtualization. Тут мне надо ввести в наше повествование еще один элемент Virtual Machine Monitor (VMM). VMM задействован в исполнении всех команд, которые отдает виртуальная машина процессору и памяти. Для каждой виртуальный машины существует отдельный VMM процесс.
Теперь, когда мы освежили основы, можно перейти и к некоторым деталям.
Software Memory Virtualization
Итак, как видно из названия, у нас тут наблюдается программная реализация виртуализации памяти. При этом VMM создает Shadow Page Table, в которую копируются следующие трансляции:
1. VA — PA, эти пары адресов напрямую копируются из Page Table виртуальной машины, за содержание которой отвечает гостевая ОС.
2. PA — HA, за эти пары адресов отвечает сама VMM
То есть, это эдакая суммарная таблица двойной трансляции. Каждый раз, когда приложение в виртуальной машине обращается к памяти (VA), MMU должна заглянуть в Shadow Page Table и найти соответствующую пару VA — HA, чтобы физический процессор мог работать с реальным физическим адресом памяти хоста (HA). При этом достигается изоляция MMU от виртуальной машины, с тем чтобы одна виртуальная машина не получила доступ к памяти другой виртуальной машины.
Согласно документации VMware такой тип трансляции адресов очень сравним по скорости с трансляцией адресов на обычном физическом сервере.
Спрашивается, к чему тогда городить огород и выдумывать новые технологии? Оказывается есть к чему — не все типы запросы к памяти от виртуальной машины могут быть выполнены с такой же скоростью как на физическом сервере. Например, каждый раз, когда происходить изменение в Page Table в ОС виртуальной машины (то есть изменяется VA — PA пара), VMM должна перехватить этот запрос и обновить соответствующую секцию Shadow Page Table (то есть результирующую пару VA — HA). Еще одним хорошим примером является ситуация, когда приложение делает самый первый запрос к определенному участку памяти. Поскольку VMM до сих пор не слышала про этот VA ничего, то есть надо создать новую запись в Shadow Page Table, таким образом опять привнося задержку в обращении к памяти. Ну и наконец, хоть это и не критично, можно отметить, что сама Shadow Page Table тоже потребляет память. Эта технология применима к vSphere, работающей на процессорах, которые были выпущены до появления на рынке семейств Nehalem/Barcelona.
Hardware Assisted Memory Virtualization
На данный момент, на рынке есть две основные технологии виртуализации MMU. Первая была представлена компанией Intel в семействе процессоров Nehalem и называется этот новый функционал — Extended Page Tables (EPT). Вторая была представлена компанией AMD в процессорах семейства Barcelona под названием Rapid Virtualization Indexing (RVI). В принципе, обе технологии выполняют один и тот же функционал, и различаются только в очень глубоко технических деталях, изучением которых я пренебрег в силу малозначительности их для моей работы.
Так вот, основное преимущество обеих технологий это то, что теперь новая MMU может одновременно запускать два процесса поиска адресов в Page Tables. Первый процесс ищет пару VA — PA в Page Table вашей виртуальной машины, другой процесс ищет PA — HA пару в Page Table, которой управляет VMM. Вторая Page Table и называется Extended (иногда Nested) Page Table. Как только обе пары найдены, MMU записывает результирующую пару VA — PA в TLB. Так как обе таблицы теперь доступны MMU необходимости содержания Shadow Page Table теперь нет. Другой важный момент это то, что теперь когда обе таблицы отделены друг от друга виртуальная машина может спокойно сама управляться со своей Page Table без контроля со стороны VMM.
Ну и еще одно существенное отличие архитектуры Nehalem это то, что в TLB теперь введено новое поле Virtual Processor ID. В более старых процессорах, этого поля не было, и когда процессор переключался с контекста одной виртуальной машины на контекст другой виртуальной машины все содержимое TLB удалялось по соображениям безопасности. Теперь же, с помощью VPID этого можно избежать и соответственно опять же уменьшить количество случаем TLB miss.
Единственная отмечаемая проблема такого решения это более высокая стоимость TLB miss по одной простой причине — каждый раз когда MMU не обнаруживает в TLB нужную пару адресов MMU приходится опять совершать поиск по двум таблицам. Именно поэтому, когда vSphere обнаруживает, что работает на Nehalem процессоре, она в обязательном порядке использует большие страницы. На следующей неделе я постараюсь закончить отключение поддержки больших страниц на всех наших ESXi хостах и выложить результаты производительности — в моей первой статье я уже упоминал о результатах отключения Large Pages на одном из продакшн серверов.
По ряду причин, от лени и попытки сделать материал более доступным до моего невежества, я опустил достаточно много различных нюансов и деталей. Например, такие как различные типы TLB и процессоров, дополнительная уровень трансляции памяти из Linear Address в Virtual Address, различия в работе с памятью в разных ОС, и т.д. Критика к качеству материала, техническим неточностям, каверзные вопросы, ну и вообще любой живой интерес только приветствуются, ибо помогут всем нам заполнить наши же пробелы в знаниях.
Основными источниками моего вдохновения и информации были Википедия и вот этот документ, за что мне хотелось бы сказать огромное спасибо их авторам.








