В последнее время интерес к облачным архитектурам растет с каждым днем, так как это один из наиболее эффективных способов масштабировать приложение, не прикладывая больших усилий, а самым узким местом любого высоконагруженного проекта является хранилище данных, в частности реляционная БД. Для борьбы с недостатками традиционных БД в основном используется 2 подхода:
1) Кэширование результатов выполнения запросов
2) NoSQL решения
Сегодня я хочу познакомить вас с таким типом хранилища данных, который объединяет достоинства обоих подходов и при этом имеет ряд преимуществ перед упомянутыми выше решениями: In-memory-data-grid (IMDG).
Этот подход очень быстро получил широкое признание среди экспертов в области проектирования облачных платформ, а также любых систем, имеющих потребность в практичеки неограниченном масштабировании системы хранения данных. Многие известные компании выпустили на рынок системы такого типа:
Так как я собираюсь рассказывать о решениях для Java, то узлами кластера IMDG будут JVM, но данная статья будет интересна и тем, кто не имеет отношения к Java, потому что во-первых, некоторые из популярных решений имеют поддержку нескольких языков, а во-вторых, даже IMDG на Java может быть использован для быстрого доступа к данным через REST API.
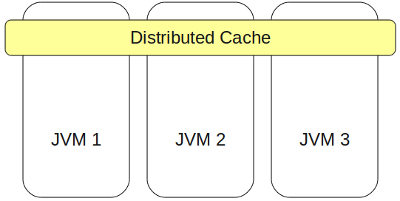
Это кластерное key-value хранилище, которое предназначено для высоконагруженных проектов, имеющих большие объемы данных и повышенные требования к масштабируемости, скорости и надежности.
Основными частями IMDG являются кэши (в GemFire это называется регионами).
Кэш в IMDG — это распределенный ассоциативный массив (т.е. кэш реализует джавский интерфейс Map), обеспечивающий быстрый конкурентный доступ к данным с любого узла кластера.
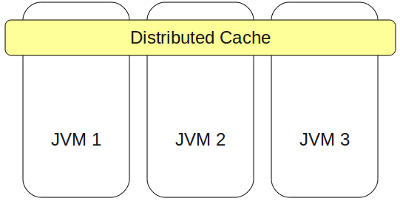
Кэш также позволяет производить обработку этих данных распределенно, т.е. модификация любых данных может быть произведена с любого узла кластера, при этом не обязательно доставать данные из кэша, изменять их, а потом класть обратно.
Практически во всех IMDG кэши поддерживают транзакции.
Данные в кэшах хранятся в сериализованном виде (т.е. в виде массива байтов).
Все данные находятся в оперативной памяти кластера, за счет чего существенно сокращается время доступа.
Т.к. все данные сериализованы, то время получения какого-либо объекта из кэша = (время перемещения объекта на конкретный узел кластера) + (время на десериализацию).
В случае, если запрашиваемый объект находится на том же узле, на котором выполнен запрос, то (время получения) = (время на десериализацию). И здесь мы видим, что доступ к данным мог бы быть вообще бесплатным, если бы объект не надо было десериализовать, для чего в концепцию IMDG было введено понятие near-cache.
Near-cache — это локальный кэш объектов для быстрого доступа, все объекты в нем хранятся готовыми к использованию. Если near-cache для данного кэша сконфигурирован, то объекты туда попадают автоматически при первом get-запросе этих объектов.
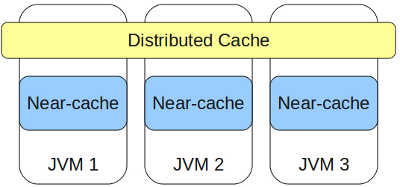
Т.к. near-cache может со временем разрастись до больших размеров, в результате чего может кончиться память, то предусмотрены следующие возможности для ограничения роста количества закэшированных объектов:
При желании (а также недостатке памяти) данные могут храниться в файле, либо в БД.
Данные в кластере хранятся в партициях (частях), и эти партиции равномерно распределены по кластеру, а каждая партиция реплицируется на некоторое количество узлов (в зависимости от конфигурации кластера и от требований к надежности хранения данных). Попадание объекта в ту или иную партицию однозначно определяется некоторой хэш-функцией.
Так как при работе под высокой нагрузкой выход отдельного узла кластера (или нескольких узлов сразу, если это были виртуальные машины внутри одного железного сервера) не является чем-то невероятным, то для обеспечения сохранности данных в конфигурации кэша указывается количество узлов, потерю которых кластер должен безболезненно пережить. Этот показатель определяет количество копий каждой партиции.
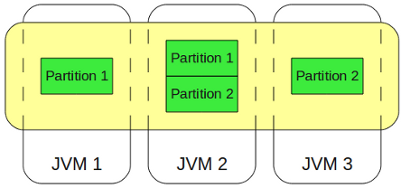
Т.е. если мы укажем, что потеря 2 узлов не должны привести к потере данных, то каждая партиция будет храниться на 3 разных узлах кластера, и при падении 2 узлов данные останутся неповрежденными. Если при этом в кластере осталось более одного узла, то опять будет создано 3 копии всех данных, и кластер будет готов к новым неприятностям.
Состав кластера (количество узлов) может меняться без остановки работы всего кластера, а за корректной работой кластера и консистентностью и доступностью данных следит сам grid без какого-либо вмешательства программиста. Т.е. при возрастающей нагрузке либо объеме данных, вы можете просто поднять еще несколько сконфигурированных узлов, которые автоматически присоединятся к кластеру, а данные внутри самого кластера перебалансируются для равномерного распределения данных по узлам, при этом объем перемещаемых данных будет минимален, чтоб не создавать лишнюю нагрузку на сеть.
При использовании IMDG вы всегда получаете актуальные данные, т.к. при выполнении put отсылается уведомление всем узлам кластера о том, что объекты с такими-то ключами получили новое значение. Каждый узел обновляет свои партиции, содержащие эти ключи, и удаляет старые значения из своего near-cache.
IMDG можно использовать не только как самостоятельное хранилище, но и как узел системы, снимающий нагрузку с трудномасштабируемой реляционной БД.
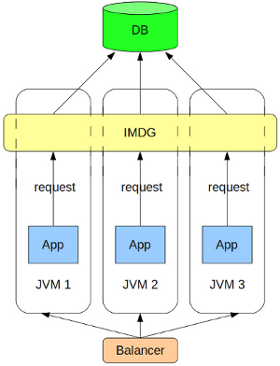
Для чтения и записи из/в БД для каждого кэша в конфигурации указывается Loader, который будет отвечать за чтение/запись объектов в БД.
Возможны несколько вариантов организации доступа к данным:
Варианты записи в БД при изменении соответствующих данных:
В случае использования IMDG как узла, который берет на себя всю нагрузку по чтению/записи/распределенной обработке данных, мы продолжаем иметь в БД актуальные данные, низкую нагрузку на саму базу и, что является очень важным моментом, корпоративные приложения, использующие БД для сбора статистики, составления отчетов и т.д. продолжают работать в прежнем состоянии.
In-memory-data-grid является сравнительно молодой, но хорошо себя зарекомендовавшей технологией, развитие которой ведется многими крупными вендорами. Она объединяет в себе достоинства NoSQL и систем кэширования, устраняет некоторые их существенные недостатки и позволяет поднять производительность системы на новый уровень. Если эта статья показалась вам интересной, то буду рад рассказать в следующий раз про какое-либо конкретное решение из семейства IMDG, а также затронуть вопросы построения и использования индексов, механизмов сериализации и взаимодействия с другими платформами в этих системах.
UPD: следующая статья
1) Кэширование результатов выполнения запросов
- плюсы: высокая скорость доступа к данным
- минусы: требует компромисса между актуальностью данных и скоростью доступа, т.к. данные в кэше могут устареть, а удалять старые данные из кэша с последующим кэшированием новых — это дополнительные задержки и нагрузка на систему
2) NoSQL решения
- плюсы: хорошая горизонтальная масштабируемость, доменная модель данных совпадает с моделью хранения данных
- минусы: низкая скорость получения результатов в случае использования диска, практически невозможно обеспечить работу внутрикорпоративного софта, который ориентирован на работу с конкретной реляционной БД.
Сегодня я хочу познакомить вас с таким типом хранилища данных, который объединяет достоинства обоих подходов и при этом имеет ряд преимуществ перед упомянутыми выше решениями: In-memory-data-grid (IMDG).
Этот подход очень быстро получил широкое признание среди экспертов в области проектирования облачных платформ, а также любых систем, имеющих потребность в практичеки неограниченном масштабировании системы хранения данных. Многие известные компании выпустили на рынок системы такого типа:
- Oracle Coherence — Java/C/.NET
- VMWare Gemfire — Java
- GigaSpaces - Java/C/.NET
- JBoss (RedHat) Infinispan — Java
- Terracota — Java
Так как я собираюсь рассказывать о решениях для Java, то узлами кластера IMDG будут JVM, но данная статья будет интересна и тем, кто не имеет отношения к Java, потому что во-первых, некоторые из популярных решений имеют поддержку нескольких языков, а во-вторых, даже IMDG на Java может быть использован для быстрого доступа к данным через REST API.
Итак, что же представляет из себя in-memory-data-grid?
Это кластерное key-value хранилище, которое предназначено для высоконагруженных проектов, имеющих большие объемы данных и повышенные требования к масштабируемости, скорости и надежности.
Основными частями IMDG являются кэши (в GemFire это называется регионами).
Кэш в IMDG — это распределенный ассоциативный массив (т.е. кэш реализует джавский интерфейс Map), обеспечивающий быстрый конкурентный доступ к данным с любого узла кластера.
Кэш также позволяет производить обработку этих данных распределенно, т.е. модификация любых данных может быть произведена с любого узла кластера, при этом не обязательно доставать данные из кэша, изменять их, а потом класть обратно.
Практически во всех IMDG кэши поддерживают транзакции.
Данные в кэшах хранятся в сериализованном виде (т.е. в виде массива байтов).
1. Скорость
Все данные находятся в оперативной памяти кластера, за счет чего существенно сокращается время доступа.
Т.к. все данные сериализованы, то время получения какого-либо объекта из кэша = (время перемещения объекта на конкретный узел кластера) + (время на десериализацию).
В случае, если запрашиваемый объект находится на том же узле, на котором выполнен запрос, то (время получения) = (время на десериализацию). И здесь мы видим, что доступ к данным мог бы быть вообще бесплатным, если бы объект не надо было десериализовать, для чего в концепцию IMDG было введено понятие near-cache.
Near-cache — это локальный кэш объектов для быстрого доступа, все объекты в нем хранятся готовыми к использованию. Если near-cache для данного кэша сконфигурирован, то объекты туда попадают автоматически при первом get-запросе этих объектов.
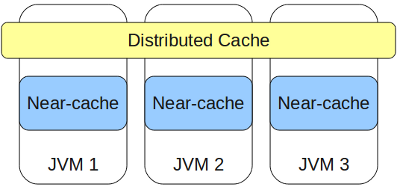
Т.к. near-cache может со временем разрастись до больших размеров, в результате чего может кончиться память, то предусмотрены следующие возможности для ограничения роста количества закэшированных объектов:
- expiration — время жизни объекта в кэше
- eviction — удаление объекта из кэша
- ограничение по количеству хранимых объектов
При желании (а также недостатке памяти) данные могут храниться в файле, либо в БД.
2. Надежность
Данные в кластере хранятся в партициях (частях), и эти партиции равномерно распределены по кластеру, а каждая партиция реплицируется на некоторое количество узлов (в зависимости от конфигурации кластера и от требований к надежности хранения данных). Попадание объекта в ту или иную партицию однозначно определяется некоторой хэш-функцией.
Так как при работе под высокой нагрузкой выход отдельного узла кластера (или нескольких узлов сразу, если это были виртуальные машины внутри одного железного сервера) не является чем-то невероятным, то для обеспечения сохранности данных в конфигурации кэша указывается количество узлов, потерю которых кластер должен безболезненно пережить. Этот показатель определяет количество копий каждой партиции.

Т.е. если мы укажем, что потеря 2 узлов не должны привести к потере данных, то каждая партиция будет храниться на 3 разных узлах кластера, и при падении 2 узлов данные останутся неповрежденными. Если при этом в кластере осталось более одного узла, то опять будет создано 3 копии всех данных, и кластер будет готов к новым неприятностям.
3. Масштабируемость
Состав кластера (количество узлов) может меняться без остановки работы всего кластера, а за корректной работой кластера и консистентностью и доступностью данных следит сам grid без какого-либо вмешательства программиста. Т.е. при возрастающей нагрузке либо объеме данных, вы можете просто поднять еще несколько сконфигурированных узлов, которые автоматически присоединятся к кластеру, а данные внутри самого кластера перебалансируются для равномерного распределения данных по узлам, при этом объем перемещаемых данных будет минимален, чтоб не создавать лишнюю нагрузку на сеть.
4. Актуальность данных
При использовании IMDG вы всегда получаете актуальные данные, т.к. при выполнении put отсылается уведомление всем узлам кластера о том, что объекты с такими-то ключами получили новое значение. Каждый узел обновляет свои партиции, содержащие эти ключи, и удаляет старые значения из своего near-cache.
5. Снижение нагрузки на БД
IMDG можно использовать не только как самостоятельное хранилище, но и как узел системы, снимающий нагрузку с трудномасштабируемой реляционной БД.

Для чтения и записи из/в БД для каждого кэша в конфигурации указывается Loader, который будет отвечать за чтение/запись объектов в БД.
Возможны несколько вариантов организации доступа к данным:
- во время запуска приложения высасывать все необходимые данные из БД в грид (так называемый preloading). Время подъема приложения увеличивается, потребление памяти тоже, но скорость работы растет
- во время работы приложения подтягивать необходимые данные по запросам клиентов (read-through). Выполняется автоматически с помощью объекта Loader для данного кэша. Время подъема приложения небольшое, начальные затраты памяти тоже, но дополнительные временные затраты на обработку запросов, вызывающих read-through
Варианты записи в БД при изменении соответствующих данных:
- при каждой операции put в кэш автоматически производится запись в БД с помощью Loader'a (так называемый write-behind). Подходит только для систем, основная нагрузка на которые вызывается чтением.
- данные, ожидающие записи в БД, накапливаются, а потом производится один запрос на запись в БД. Сигналом к выполнению такого запроса может быть определенное количество данных, ожидающих записи, либо таймаут. Подходит для write-intensive систем, но сложнее в реализации
В случае использования IMDG как узла, который берет на себя всю нагрузку по чтению/записи/распределенной обработке данных, мы продолжаем иметь в БД актуальные данные, низкую нагрузку на саму базу и, что является очень важным моментом, корпоративные приложения, использующие БД для сбора статистики, составления отчетов и т.д. продолжают работать в прежнем состоянии.
Вывод
In-memory-data-grid является сравнительно молодой, но хорошо себя зарекомендовавшей технологией, развитие которой ведется многими крупными вендорами. Она объединяет в себе достоинства NoSQL и систем кэширования, устраняет некоторые их существенные недостатки и позволяет поднять производительность системы на новый уровень. Если эта статья показалась вам интересной, то буду рад рассказать в следующий раз про какое-либо конкретное решение из семейства IMDG, а также затронуть вопросы построения и использования индексов, механизмов сериализации и взаимодействия с другими платформами в этих системах.
UPD: следующая статья







