Недавно вышла 11-я версия известного в России и в мире программного продукта по оптическому распознаванию текста ABBYY FineReader. В этой версии анонсировано множество улучшений, а основной упор делается на увеличение производительности и снижение ошибок. Эти улучшения — в сравнении с 10-й версией. Я же не пользовался этой программой со студенческих лет (с начала 2000-х), и наверняка пропустил версий, эдак, шесть. В те годы интернет и мобильные технологии не были развиты так сильно, а времени было много. Поэтому я был готов брать в библиотеке книгу на час, снимать копии, ехать в один конец города к компьютеру, где есть сканер, затем в другой конец, туда, где есть FineReader, а затем домой, доисправлять ошибки распознавания и форматирования в Word-овских файлах. Сегодня же юзер стал ленивее и требовательнее, поэтому хочу рассмотреть работу с программой в ракурсе современных доступных технологий и острой нехватки времени.
Спасибо dimonline и компании ABBYY за промо-ключ и версию FineReader 11 CE (Corporate Edition), благодаря которым удалось провести несколько тестов.
Итак, я взял книгу-путеводитель «Швейцария» и под определенным углом сфотографировал на iPhone несколько разворотов. Один из разворотов:

Итого я снял 14 фотографий, которые достаточно быстро перенес на ноутбук. Конфигурация ноутбука: MacBook Pro 15" / Core i7 2.66 GHz / RAM 8GB / Mac OS X Lion, а сам FineReader запущен на VMware Fusion / Windows 7 x64 (выделено 2 ядра процессора и 2 GB RAM). Запустил FineReader, выбрал функцию «Файл (изображение) в PDF», выбрал файлы, нажал «Открыть» и перешел в другое окно заниматься своими делами. Примерно через 15 минут характерный звук уведомил об окончании процесса и готовый PDF файл с распознанными страницами предстал пред моим взором. Вот, как выглядит одна из страниц в самом файле:

тем не менее, текст выделяется:

и в блокноте выглядит так:
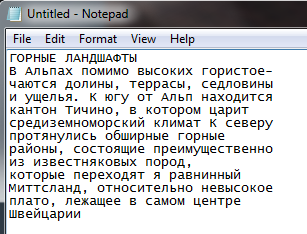
Далее, я зашел в редактирование изображений и устранил трапециевидное искажение путем указания расположения углов прямоугольной страницы. К сожалению, на моих страницах дополнительно присутствуют сферические искажения. В целом, страница и ее картинки стали выглядеть геометрически правильно, но распознавание текста не изменилось. Тогда я сфотографировал страницу со вспышкой, держа телефон строго вертикально над книгой. В итоге имею такую страницу в PDF:

и выделенный текст неплохо читается в блокноте:
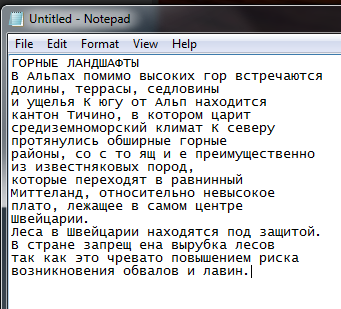
Старинная народная мудрость в действии — лучше качественно снимать, чем потом ретушировать, а точнее — потратить несколько минут на подготовку съемочного места (свет, фон) и оборудования (мегапиксели, фокус), а потом наслаждаться автоматизированным (тут ABBYY постарались) процессом распознавания.
В домашней библиотеке нашелся 500-страничный мануал по некой компьютерной программе (251-страничный PDF-файл), взятый в просторах интернета. Дабыне накликать себе гнев богов копирайта соблюсти условия пользования интеллектуальной собственностью скриншоты не вставляю. Страницы сфотографированы с небольшими сферическими искажениями в области переплета. Много картинок и таблиц. Картинки, в основном, — это скриншоты из собственно описанной программы. Результаты теста таковы:
Время открытия файла: 12 минут.
Время распознавания: 26 минут.
Время экспорта в Word: 2 минуты.
Время сохранения проекта: 11 минут.
Из недочетов можно отметить только один — большинство картинок определены как текстовые блоки. Возможно, потому, что на этих картинках скриншоты, включающие в себя строку заголовка и меню программы. Для этого пришлось зайти на каждую страницу с картинкой и поменять тип и границы блоков.
Время корректировки типов блоков: 35 минут.
Я решил сделать выводы по каждому из анонсированных улучшений.
Оно, действительно, более точное, но многие картинки определились как текст, хотя имеют прямоугольную форму и множество «не-текста». Возможно, программе требуется дополнительная функциональность в виде настройки чувствительности, некий ползунок со шкалой, на одной стороне шкалы надпись «скорее текст», а на другой — «скорее картинка».
Да, действительно, несмотря на то, что программа выполнялась на виртуальной машине со множеством параллельно запущенных программ, процесс шел стабильно, без сбоев. Для верности распознавание 500-страничного документа было осуществлено 3 раза.
Ручное исправление работает, в то время как автоматических изменений замечено не было. Хотя, текст на искаженной странице распознался корректно. А ведь раньше (лет 10 назад) малейшее искажение неизбежно приводило к ошибкам.
Особых проблем в работе с многостраничным документом подмечено не было.
Такие режимы есть, но места на диске и мощности комьютера достаточно для «Наилучшего качества».
Вполне полезные и актуальные функции.
Эта функция полезна для постобработки. Если цель распознавания — просто читать, а не распечатывать, то пользоваться функцией небязательно.
Многие программы с древнейших времен имеют такие окна. Я всегда их закрывал и ставил галочку «Больше не выводить это окно». Но в данном случае решил воспользоваться (возможно, сказался переход на Mac и iPhone) и мне понравилось, с тех пор в FineReader пользовался только этим окном. А лазать по меню стало лень.
Юзабилити вполне в современном тренде и софтом приятно пользоваться. Определенной категории офисных работников она сильно сэкономит время и нервы. Заявленные улучшения действительно работают. Если бы я снова оказался студентом, то просто фотографировал бы отрывки книг на телефон в библиотеке и распознавал дома (для рефератов и диссертаций). Сейчас же подобная функциональность мне требуется не чаще 1-2 раз в год, поэтому для меня будет полезен онлайн-сервис с постраничной оплатой.
Хочу пожелать команде ABBYY продолжать радовать и удивлять потребителя.
* Для правообладателей:
Материалы, упомянутые в данной статье, были распознаны исключительно в целях проверки функциональности и быстродействия ПО. Все результаты распознавания, равно как и цифровые изображения книжных страниц, были впоследствии безвозвратно уничтожены.
P.S. По поводу вопроса от vmb насчет диакритических знаков. По этой ссылке взят скриншот нижеследующего текста на греческом:
Ἐχεκράτης
[57a] αὐτός, ὦ Φαίδων, παρεγένου Σωκράτει ἐκείνῃ τῇ ἡμέρᾳ ᾗ τὸ φάρμακον ἔπιεν ἐν τῷ δεσμωτηρίῳ, ἢ ἄλλου του ἤκουσας;
Φαίδων
αὐτός, ὦ Ἐχέκρατες.
Ἐχεκράτης
τί οὖν δή ἐστιν ἅττα εἶπεν ὁ ἀνὴρ πρὸ τοῦ θανάτου; καὶ πῶς ἐτελεύτα; ἡδέως γὰρ ἂν ἐγὼ ἀκούσαιμι. καὶ γὰρ οὔτε [τῶν πολιτῶν] Φλειασίων οὐδεὶς πάνυ τι ἐπιχωριάζει τὰ νῦν Ἀθήναζε, οὔτε τις ξένος ἀφῖκται χρόνου συχνοῦ [57b] ἐκεῖθεν ὅστις ἂν ἡμῖν σαφές τι ἀγγεῖλαι οἷός τ᾽ ἦν περὶ τούτων, πλήν γε δὴ ὅτι φάρμακον πιὼν ἀποθάνοι· τῶν δὲ ἄλλων οὐδὲν εἶχεν φράζειν.
который при выборе только греческого языка распознался FineReader-ом вот так:
Έχεκράτης
[57β] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τό φάρμακον έπιεν έν τώ δεσμωτηρίω, ή άλλου του ήκουσας;
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εΐπεν ό άνήρ προ του θανάτου; καί πώς έτελεύτα; ήδέως γάρ άν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδείς πάνυ τι επιχωριάζει τά νυν Άθήναζε, οΰτε τις ξένος άφΐκται χρόνου συχνού [57β] έκεΐθεν όστις άν ήμΐν σαφές τι άγγεΐλαι οΐός τ’ ήν περί τούτων, πλήν γε δή ότι φάρμακον πιών άποθάνοι· τών δέ άλλων ούδέν ειχεν φράζειν.
при выборе греческого и английского — так:
Έχεκράτης
[57a] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τό φάρμακον έπιεν έν τώ δεσμωτηρίω, ή άλλου του ήκουσας;
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εΐπεν ό άνήρ προ του θανάτου; καί πώς έτελεύτα; ήδέως γάρ άν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδείς πάνυ τι επιχωριάζει τά νυν Άθήναζε, οΰτε τις ξένος άφΐκται χρόνου συχνού [57b] έκεΐθεν όστις άν ήμΐν σαφές τι άγγεΐλαι οΐός τ’ ήν περί τούτων, πλήν γε δή ότι φάρμακον πιών άποθάνοι· τών δέ άλλων ούδέν ειχεν φράζειν.
а при создании копии греческого языка и добавлении туда всех символов с диакритическими знаками получилось так:
Έχεκράτης
[57ā] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τò φάρμακον επιεν έν τω δεσμωτηρίω, ή άλλου του ήκουσας;
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εĩπεν ό άνήρ πρò τοû θανάτου; καί πώς έτελεύτα; ήδέως γάρ αν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδεìς πάνυ τι επιχωριάζει τά νûν Άθήναζε, οΰτε τις ξένος άφîκται χρόνου συχνού [57ċ>] έκεîθεν öστις αν ήμîν σαφές τι άγγεΐλαι οîός τ’ ήν περί τούτων, πλήν γε δή öτι φάρμακον πιών άποθάνοι- τών δέ άλλων ούδέν εĩχεν φράζειν.
Спасибо dimonline и компании ABBYY за промо-ключ и версию FineReader 11 CE (Corporate Edition), благодаря которым удалось провести несколько тестов.
Тест функциональности
Итак, я взял книгу-путеводитель «Швейцария» и под определенным углом сфотографировал на iPhone несколько разворотов. Один из разворотов:

Итого я снял 14 фотографий, которые достаточно быстро перенес на ноутбук. Конфигурация ноутбука: MacBook Pro 15" / Core i7 2.66 GHz / RAM 8GB / Mac OS X Lion, а сам FineReader запущен на VMware Fusion / Windows 7 x64 (выделено 2 ядра процессора и 2 GB RAM). Запустил FineReader, выбрал функцию «Файл (изображение) в PDF», выбрал файлы, нажал «Открыть» и перешел в другое окно заниматься своими делами. Примерно через 15 минут характерный звук уведомил об окончании процесса и готовый PDF файл с распознанными страницами предстал пред моим взором. Вот, как выглядит одна из страниц в самом файле:

тем не менее, текст выделяется:

и в блокноте выглядит так:

Далее, я зашел в редактирование изображений и устранил трапециевидное искажение путем указания расположения углов прямоугольной страницы. К сожалению, на моих страницах дополнительно присутствуют сферические искажения. В целом, страница и ее картинки стали выглядеть геометрически правильно, но распознавание текста не изменилось. Тогда я сфотографировал страницу со вспышкой, держа телефон строго вертикально над книгой. В итоге имею такую страницу в PDF:

и выделенный текст неплохо читается в блокноте:
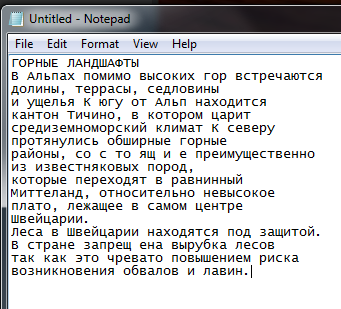
Старинная народная мудрость в действии — лучше качественно снимать, чем потом ретушировать, а точнее — потратить несколько минут на подготовку съемочного места (свет, фон) и оборудования (мегапиксели, фокус), а потом наслаждаться автоматизированным (тут ABBYY постарались) процессом распознавания.
Тест производительности
В домашней библиотеке нашелся 500-страничный мануал по некой компьютерной программе (251-страничный PDF-файл), взятый в просторах интернета. Дабы
Время открытия файла: 12 минут.
Время распознавания: 26 минут.
Время экспорта в Word: 2 минуты.
Время сохранения проекта: 11 минут.
Из недочетов можно отметить только один — большинство картинок определены как текстовые блоки. Возможно, потому, что на этих картинках скриншоты, включающие в себя строку заголовка и меню программы. Для этого пришлось зайти на каждую страницу с картинкой и поменять тип и границы блоков.
Время корректировки типов блоков: 35 минут.
Выводы
Я решил сделать выводы по каждому из анонсированных улучшений.
Более точное определение типов блоков
Оно, действительно, более точное, но многие картинки определились как текст, хотя имеют прямоугольную форму и множество «не-текста». Возможно, программе требуется дополнительная функциональность в виде настройки чувствительности, некий ползунок со шкалой, на одной стороне шкалы надпись «скорее текст», а на другой — «скорее картинка».
Более стабильная работа с большими (более 100 файлов) пакетами документов
Да, действительно, несмотря на то, что программа выполнялась на виртуальной машине со множеством параллельно запущенных программ, процесс шел стабильно, без сбоев. Для верности распознавание 500-страничного документа было осуществлено 3 раза.
Улучшенное автоматическое и ручное исправление искажений сфотографированных документов
Ручное исправление работает, в то время как автоматических изменений замечено не было. Хотя, текст на искаженной странице распознался корректно. А ведь раньше (лет 10 назад) малейшее искажение неизбежно приводило к ошибкам.
Улучшенная работа с многостраничными документами
Особых проблем в работе с многостраничным документом подмечено не было.
Наличие режимов сохранения в PDF: «Наилучшее качество», «Небольшой размер» и «Сбалансированный режим»
Такие режимы есть, но места на диске и мощности комьютера достаточно для «Наилучшего качества».
Сохранение и конвертирование изображений документов и PDF-файлов в формат ODT (OpenOffice.org Writer), DjVu, ePub, fb2
Вполне полезные и актуальные функции.
Редактор стилей
Эта функция полезна для постобработки. Если цель распознавания — просто читать, а не распечатывать, то пользоваться функцией небязательно.
В окно «Новая задача» вынесены функции, которые бывают нужны чаще всего
Многие программы с древнейших времен имеют такие окна. Я всегда их закрывал и ставил галочку «Больше не выводить это окно». Но в данном случае решил воспользоваться (возможно, сказался переход на Mac и iPhone) и мне понравилось, с тех пор в FineReader пользовался только этим окном. А лазать по меню стало лень.
Заключение
Юзабилити вполне в современном тренде и софтом приятно пользоваться. Определенной категории офисных работников она сильно сэкономит время и нервы. Заявленные улучшения действительно работают. Если бы я снова оказался студентом, то просто фотографировал бы отрывки книг на телефон в библиотеке и распознавал дома (для рефератов и диссертаций). Сейчас же подобная функциональность мне требуется не чаще 1-2 раз в год, поэтому для меня будет полезен онлайн-сервис с постраничной оплатой.
Хочу пожелать команде ABBYY продолжать радовать и удивлять потребителя.
* Для правообладателей:
Материалы, упомянутые в данной статье, были распознаны исключительно в целях проверки функциональности и быстродействия ПО. Все результаты распознавания, равно как и цифровые изображения книжных страниц, были впоследствии безвозвратно уничтожены.
P.S. По поводу вопроса от vmb насчет диакритических знаков. По этой ссылке взят скриншот нижеследующего текста на греческом:
Ἐχεκράτης
[57a] αὐτός, ὦ Φαίδων, παρεγένου Σωκράτει ἐκείνῃ τῇ ἡμέρᾳ ᾗ τὸ φάρμακον ἔπιεν ἐν τῷ δεσμωτηρίῳ, ἢ ἄλλου του ἤκουσας;
Φαίδων
αὐτός, ὦ Ἐχέκρατες.
Ἐχεκράτης
τί οὖν δή ἐστιν ἅττα εἶπεν ὁ ἀνὴρ πρὸ τοῦ θανάτου; καὶ πῶς ἐτελεύτα; ἡδέως γὰρ ἂν ἐγὼ ἀκούσαιμι. καὶ γὰρ οὔτε [τῶν πολιτῶν] Φλειασίων οὐδεὶς πάνυ τι ἐπιχωριάζει τὰ νῦν Ἀθήναζε, οὔτε τις ξένος ἀφῖκται χρόνου συχνοῦ [57b] ἐκεῖθεν ὅστις ἂν ἡμῖν σαφές τι ἀγγεῖλαι οἷός τ᾽ ἦν περὶ τούτων, πλήν γε δὴ ὅτι φάρμακον πιὼν ἀποθάνοι· τῶν δὲ ἄλλων οὐδὲν εἶχεν φράζειν.
который при выборе только греческого языка распознался FineReader-ом вот так:
Έχεκράτης
[57β] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τό φάρμακον έπιεν έν τώ δεσμωτηρίω, ή άλλου του ήκουσας;
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εΐπεν ό άνήρ προ του θανάτου; καί πώς έτελεύτα; ήδέως γάρ άν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδείς πάνυ τι επιχωριάζει τά νυν Άθήναζε, οΰτε τις ξένος άφΐκται χρόνου συχνού [57β] έκεΐθεν όστις άν ήμΐν σαφές τι άγγεΐλαι οΐός τ’ ήν περί τούτων, πλήν γε δή ότι φάρμακον πιών άποθάνοι· τών δέ άλλων ούδέν ειχεν φράζειν.
при выборе греческого и английского — так:
Έχεκράτης
[57a] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τό φάρμακον έπιεν έν τώ δεσμωτηρίω, ή άλλου του ήκουσας;
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εΐπεν ό άνήρ προ του θανάτου; καί πώς έτελεύτα; ήδέως γάρ άν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδείς πάνυ τι επιχωριάζει τά νυν Άθήναζε, οΰτε τις ξένος άφΐκται χρόνου συχνού [57b] έκεΐθεν όστις άν ήμΐν σαφές τι άγγεΐλαι οΐός τ’ ήν περί τούτων, πλήν γε δή ότι φάρμακον πιών άποθάνοι· τών δέ άλλων ούδέν ειχεν φράζειν.
а при создании копии греческого языка и добавлении туда всех символов с диакритическими знаками получилось так:
Έχεκράτης
[57ā] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τò φάρμακον επιεν έν τω δεσμωτηρίω, ή άλλου του ήκουσας;
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εĩπεν ό άνήρ πρò τοû θανάτου; καί πώς έτελεύτα; ήδέως γάρ αν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδεìς πάνυ τι επιχωριάζει τά νûν Άθήναζε, οΰτε τις ξένος άφîκται χρόνου συχνού [57ċ>] έκεîθεν öστις αν ήμîν σαφές τι άγγεΐλαι οîός τ’ ήν περί τούτων, πλήν γε δή öτι φάρμακον πιών άποθάνοι- τών δέ άλλων ούδέν εĩχεν φράζειν.







