
Доклад «Стабильность интернет-сайта: how to» — очередной в серии расшифровок с Форума Технологий Mail.Ru 2011. Подробности о том, как работает система расшифровки докладов — см. в статье «Изнанка» Форума технологий Mail.Ru: Хай-тек в event-management. Там же, а также на сайте Форума (http://techforum.mail.ru) — ссылки на расшифровки других докладов.
(Скачать видеоверсию для мобильных устройств — iOS/Android H.264 480×368, размер 170 Mb, видеобитрейт 500 кбит/с, аудио — 64 кбит/с )
(Скачать видеоверсию большего разрешения H.264 624×480, размер 610 Mb, видеобитрейт 1500 кбит/с, аудио — 128 кбит)
(Скачать слайды презентации, 5.5Mb)
Наверное, для вас не секрет, что каждый раз, когда у какого-нибудь крупного сайта возникают проблемы с работой, перебои, это вызывает огромное количество обсуждений. Я постараюсь рассказать вам, как сделать так, чтобы ваш сайт не падал, или падал хотя бы реже. Что мы делаем для этого в Mail.Ru, какие методики мы используем.
Стабильность — это важно
Стабильность для интернет-сайта — она в принципе важна? На эту тему есть много мнений — кто-то считает, что это важно, кто-то считает, что среди прочих — это не самый важный фактор. Мы считаем это очень важным, и на то у нас есть три основные причины.

Как вы знаете, большинство сервисов в интернете бесплатны. И как только ваш сайт не работает, тормозит, испытывает какие-то проблемы, ваш пользователь уходит к конкуренту.
Вторая причина в том, что порог переключения между сервисами в интернете довольно низкий. Вам не нужно никуда ехать, тут нет высокой стоимости переключения, как в случае с сотовыми операторами, и всегда можно переключиться на другой сайт, когда не работает тот сервис, которым вы привыкли пользоваться. И, более того, есть огромное количество вспомогательных фич, которые помогут такому обиженному пользователю переехать с одного сайта на другой, поэтому стабильность — это важно.
Третья причина — не «про интернет». Мы должны все понимать, что человек устроен таким образом, что отрицательные эмоции всегда сильнее, чем положительные, и одна авария на вашем сайте, как правило, перекрывает огромное количество времени стабильной работы, качественность сервиса и т.д.
По этим трем причинам мы считаем, что сайт должен работать стабильно, но в среднем, в интернете уровень стабильности не на очень высоком уровне. По нашей внутренней статистике средний сайт российского интернета имеет Uptime, т.е. «время работы», — 98.6%. Цифра вроде не ужасная, но если присмотреться внимательнее — это пять суток в год, когда средний интернет-сайт не работает. Это довольно большое количество времени, и это говорит нам о том, что проблема существует, и проблема довольно серьезная. Конечно, крупные интернет-сайты работают чуть получше. На крупный интернет-сайт приходится порядка четырех часов «неработы» в год. Но, тем не менее, это всё большие числа, особенно если вспомнить про пять суток.

Причины аварий
На основе статистики Mail.ru мы классифицировали причины, по которым происходят аварии у нас и на других сайтах в российском интернете. Если говорить о количественном распределении, я имею в виду количество аварий, по причине которых не работает тот или иной функционал сайта, сайт лежит и т.д., половина аварий сайтов в интернете приходится на неправильный релиз софта, на релиз софта с багами, с кривыми конфигами. Соответственно, в половине случаев, опять хочу обратить внимание — количественно, виноваты разработчики, системные администраторы, которые недостестировали, плохо зарелизили и т.д. Еще 25% случаев приходится на программные аварии, к которым я отношу также и нагрузку на сайт, 16% случаев — это сетевые аварии, 8% — это аварии серверов, компьютеров, на которых работают сайты.

Если посмотреть качественное распределение — оно будет совершенно другое. Как мы видим, самые страшные аварии — это аварии на сети и аварии в датацентрах. От них очень тяжело уберечься. Они, как правило, полностью выключают весь ресурс или даже крупный хостинг, много ресурсов не работает одновременно. Они занимают по 30%. Следующие — аварии при релизе нового программного обеспечения. Далее следуют программные аварии и, в самом конце, аварии оборудования, они составляют небольшой процент.
Мониторинг
Для того чтобы говорить о том, как сделать свой сайт стабильным, нам нужно сначала обсудить, как мы узнаем, что с нашим сайтом что-то не так. Я уверен, что все айтишники, находящиеся в этой аудитории, не будут спорить со мной о том, что мониторинг нужен. Кто-нибудь будет? Я так же уверен, что в этой аудитории находятся люди, у которых мониторинга нет. Позвольте мне коротко назвать 10 причин иметь мониторинг. Я знаю, что вы согласны с тем, что вам нужен мониторинг, но давайте все-таки пройдемся по этому списку.

Первая причина звучит очень просто: вы отличный программист, еще лучший системный администратор, но ваш сайт все равно упадет. Что бы вы ни делали, это случится — завтра, через год — это не важно. Это произойдет в любом случае, с этим невозможно бороться, это обязательно будет, поэтому всегда помните об этом. Мониторинг нам нужен не только для того, чтобы узнать, что наш сайт упал. Он нам нужен для того, чтобы как можно скорее принять какие-то меры, чтобы сайт вновь заработал. Когда сайт не работает малое количество времени — это одна проблема для юзера, когда сайт не работает в течение 5 дней — это проблема уже другого порядка.
Вы не должны узнавать о проблемах вашего сайта от ваших пользователей, потому что то время, которое затрачивается на то, чтобы ваш пользователь вам написал, ваша техподдержка сказала вам о проблеме — оно слишком велико. За это время большое количество юзеров уходит к вашим конкурентам. Рынок устроен таким образом, что большинство сервис-провайдеров, как интернет-сервис-провайдеров, так и провайдеров услуг датацентров, не будут нести ответственность, соразмерную со стоимостью вашего бизнеса, поэтому ответственность за ваш Uptime и за то время, когда ваш сайт не работает, лежит целиком на вас, а не на вашем сервис-провайдере.
Как вы знаете, когда сайт не работает, пользователи начинают обсуждать: «он не работает временно» или «вообще закрылся» или «что-то произошло». Это обсуждение наносит большой урон вашей репутации. Более того, мы заметили интересный эффект, что даже те пользователи, которые не были затронуты аварией напрямую, т.е. они не заходили на сайт в то время, когда он не работал, участвуя в этих обсуждениях, они становятся как бы сопричастными. Они считают, что с ними тоже что-то случилось и это очередная проблема, по которой нам нужно иметь мониторинг, и нам нужно знать, когда наш сайт не работает.

Все наши сайты обновляются, мы постоянно дорабатываем новый функционал, мы запускаем новые «фичи», мы делаем новые функции на нашем сайте, и это приводит к тому, что у нас существует сложный большой длительный процесс разработки. Мониторинг — это та вещь, которая позволяет нам узнать о том, что в нем существуют системные проблемы. Только благодаря мониторингу вы можете узнать, какая команда ваших разработчиков или конкретный разработчик постоянно создают проблемы в стабильности сайта. Только благодаря мониторингу мы можем узнать, на какой модуль нашего программного комплекса нам нужно обратить дополнительное внимание.
Следующая проблема — это то, что интернет большой, и вы можете прекрасно работать с вашим сайтом, он может отлично открываться, у вас могут работать все функции, однако вы будете единственным человеком, у которого он работает. Соответственно, мониторинг должен быть сделан таким образом, чтобы он позволял вам увидеть проблемы не только из вашей технической инфраструктуры, но и снаружи. Вот если говорить о Mail.Ru — он мониторится примерно из 100 точек по всему земному шару, таким образом, мы узнаем о проблемах не только у нас, но и о проблемах у провайдеров, о проблемах у провайдеров наших провайдеров. Честно говоря, конечному пользователю все равно, где не работает Mail.Ru, словосочетание «провайдер провайдера» ему вообще ничего не говорит. Ему понятно, что не работает Mail.Ru. Поэтому мы наблюдаем за нашей сетевой инфраструктурой, мы наблюдаем за сетевой инфраструктурой тех операторов, которые предоставляют нам услуги с помощью нашего же мониторинга.
Опять же, хороший мониторинг сэкономит вам время, потому что он не только предупредит вас о том, что у вас есть проблемы, он еще и скажет, что именно в данный момент не работает, и это сэкономит вам время на понимание и последующее решение.
Вы должны знать о проблеме в любое время. Только в России есть девять часовых поясов, а по всему миру у вас могут быть пользователи в тех местах, где, допустим, уже день, в то время когда у нас — ночь.
Ну и последний аргумент. Как правило, стоимость разработки сайта довольно высока. Стоимость создания мониторинга по сравнению со стоимостью разработки сайта практически никакая. Под созданием я имею в виду настройку, потому что решений в открытом доступе, которые можно скачать и поставить бесплатно, огромное количество.
Вот вам 10 причин, по которым все люди находящиеся в этом зале, у которых есть свои сайты, и которые их почему-то еще не мониторят, должны вернуться с Форума технологий и настроить себе мониторинг.

Что мониторим в Mail.Ru
На самом деле в Mail.Ru порядка 140 различных типов мониторинга, я не буду перечислять их все, суммарно мы мониторим порядка 150 000 объектов на наших серверах. У нас есть мониторинг работы сервиса. Например, это может быть ответ сервиса по HTTP. У нас есть функциональный мониторинг сервисов, мы всегда проверяем доходят ли до нас письма, скачиваются ли они по POP3, может ли пользователь добавить другого пользователя в друзья и т.д. Мы обязательно мониторим сетевую доступность. Мы проверяем, видны ли мы по всему миру. Мы мониторим заполняемость наших хранилищ данных, потому что большая часть программного обеспечения написана таким образом, что если диски переполняются, то дальше эти данные просто портятся, и мы будем вынуждены восстанавливаться из бэкапа. Мы мониторим также скорость работы сайта, потому что существуют пороговые значения, при которых уже не важно, что ваш сайт открывается, условно говоря, за полчаса. Для пользователя это будет значить, что ваш сайт просто не работает. Мы мониторим все статистические выбросы. Мы собираем огромное количество статистики по Mail.Ru, например, мы знаем, сколько у нас в день отправляется писем, мы знаем, сколько у нас в день отправляется сообщений, сколько у нас дружб в социальных сетях. Мы стараемся наблюдать за этими количественными метриками, и в случае если какая-нибудь из них начинает быстро расти или меняться, или появляется какой-то "выброс", у нас это подсвечивается в мониторинге, есть возможность потом проанализировать, почему это случилось, что с этим можно сделать и т.д. И это лишь несколько из имеющихся типов мониторингов.
Но остался еще один самый важный. Если у вас нет мониторинга — это очень плохо. Но когда у вас есть мониторинг, но он не работает — это ужасно, потому что у вас складывается ложное впечатление о том, что ваш сайт на самом деле сейчас работает. Поэтому самый главный и самый первый мониторинг в Mail.Ru — это мониторинг того, что мониторинг работает.

Резервирование и балансировка
А теперь давайте поговорим о том, что же нам все-таки сделать, чтобы наш сайт не падал, как мы в Mail.Ru подходим к этим вопросам. Начнем мы, естественно, с резервирования и балансировки.
У нас есть универсальная таблица, которую мы применяем к нашим сервисам. Она довольно общая, но, по крайней мере, примеряя ее к тому или иному нашему сервису, мы можем понять, насколько он защищен, насколько он соответствует тому, что мы хотим получить.
Мы считаем, что для любых серверов обработки данных, которые не являются хранилищами, нам достаточно резервирования N+1. N+1 в данном примере не означает, что на 100 серверов у нас один запасной, это означает, что мы сами определяем N. Например, в случае frontend-ов у нас один запасной сервер на каждые 10 web-серверов. Важно то, что в этом случае у нас всегда есть какое-то количество серверов, которое мы можем, если что, пустить в бой. Для хранилищ данных мы всегда имеем две онлайн-копии нашего хранилища, потому что жесткие диски это такая штука, что им нельзя доверять. И мы в любой момент можем переключиться с одного хранилища на другое. Плюс, что часто забывается, мы всегда имеем оффлайн-копию наших данных. Проблема вся в том, что бывают сбои не только оборудования, но и программного обеспечения, и в этом случае два массива с битыми данными мне просто не нужны, мне нужна именно оффлайн-копия, на которую мы сможем откатиться, если нам это понадобится.
Запас, принятый по сетевой инфраструктуре в Mail.Ru — 35%. Этого достаточно для того, чтобы пережить «пики», которые связаны с какими-то событиями. Этого достаточно, чтобы пережить тот наплыв посещаемости, который мы испытываем, когда не работают наши конкуренты. В общем, 35% по сетевой инфраструктуре среднему сайту хватает, чтобы пережить все те катаклизмы, которые с ним могут случиться.
Отдельно хочется упомянуть о том, что каждый раз, когда я говорю о резервировании, каждый раз, когда я говорю о резерве, я не имею ввиду сервера, лежащие у вас где-то на складе, в офисе, или еще где-то. Потому что в тот момент, когда авария случится, вам потребуется какое-то количество времени на то, чтобы резерв ввести в бой. Поэтому весь резерв, которым вы обладаете, должен быть введен в бой автоматически. А в идеальном случае, как это сделано у нас, он должен всегда работать. Т.е. идеальный резерв — это избыточность ваших рабочих серверов. Резервные сервера должны точно так же обрабатывать какую-то часть нагрузки в обычное время, для того чтобы копия программного обеспечения для них была всегда актуальна, чтобы их файл-конфигурации были всегда актуальны и т.д.
Итак, всего пару слов о том, как мы подходим к созданию отказоустойчивых систем балансировки. Я опишу это на примере HTTP-сервиса. На самом деле вы можете использовать эту концепцию в почти любом сервисе. Для того, чтобы создать такой балансировщик, нам потребуется самый простой роутер с поддержкой протокола RIP, потребуется средство общения с этим роутером, я предлагаю опенсорсное решение Quagga, но вы можете использовать что-то другое.
Нам нужен собственно балансировщик и энкапсулятор траффика IPVS, он очень известен, огромное количество системных администраторов умеют с ними работать. И последнее, что нам понадобится — это утилита для проверки живости серверов keepalived. Она хороша тем, что вы можете ее настроить полностью под свои нужды. Итак, как же это работает на примере одного датацентра? В дальнейшем я покажу также, как это работает в случае нескольких датацентров.
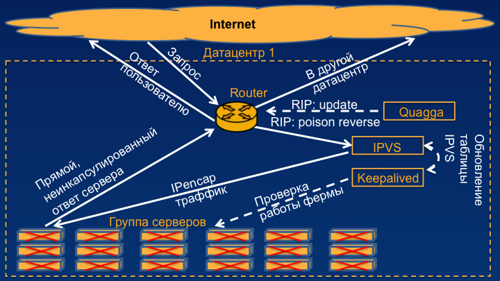
Вот у нас есть группа наших серверов. Допустим — это frontend-ы. Они отвечают по HTTP на запросы пользователей. У нас есть тот самый Keepalived, который я описывал, который опрашивает их и, в случае если они работают, он обновляет таблицу вот этих реальных серверов в IPVS. В случае, если количество реально рабочих серверов в IPVS выше порогового значения, которое мы определили достаточным для нашего сервиса, IPVS поднимает на балансировщике виртуальный IP-адрес вашего сервиса. В случае Mail.Ru, вы можете посмотреть, это четыре IP-адреса, четыре различных группы балансировщиков. Тот самый демон, который общается с роутером, начинает сообщать ему, что маршрут до Mail.Ru пролегает через этот самый балансировщик. Дальше, когда к нам приходит пользовательский запрос, роутер на основе своей таблицы маршрутизации обращается к балансировщику, балансировщик энкапсулирует этот трафик в IP-in-IP (это добавляет нам всего лишь 20 байт на каждый пакет) и отправляет его на реальный сервер. А реальный сервер отправляет его уже напрямую, без энкапсуляции на роутер, роутер — напрямую пользователю.
Эта схема позволяет Вам обработать порядка 600 000 пакетов в секунду, что неплохо даже для железа популярных вендоров.

Плюс этого решения, по сравнению с железом, купленным у вендора, в том, что оно полностью вам подконтрольно, вы полностью понимаете, что там в данный момент происходит, вы можете дописывать, доделывать, переделывать все так, как вам нужно. В случае, если у нас не работает несколько серверов, это тут же заметит keepalived, и он выключит эти сервера в таблице реальных серверов нашего балансировщика. В случае если у нас сломалась вся ферма, т.е. количество живых серверов, которые на данный момент у нас работают, оказалось меньше порогового значения, которое мы выставляем, это замечает тот же самый keepalived, он сообщает это IPVS, и он убирает виртуальный IP-address с нашего балансировщика. В результате демон, который отвечает за общение с роутером, просто убивает маршрут к этому балансировщику, и пользовательский пакет просто уходит в другой датацентр, где у нас стоит рабочая ферма серверов и рабочий балансировщик.
На примере нескольких датацентров это звучит чуть сложнее, но смысл примерно такой же. К нам приходят пользовательские запросы. В случае, если RIP-метрики одинаковые, они равномерно распределяются между нашими балансировщиками, дальше попадают на реальные сервера, дальше уходят на роутер и обратно к пользователю. В случае, если у нас случается какая-то авария, это замечает наш мониторинг, наш keepalived, мы убиваем маршрут на этом роутере, и все пользовательские запросы уходят на роутер в соседнем датацентре, и соответственно, на балансировщик в соседнем датацентре.

Как известно, любая реклама описывает только преимущества, и моя презентация — не исключение. Есть четыре вещи, которые нам нужно сделать, для того чтобы это на самом деле заработало. Нам нужно поправить таймеры RIP-апдейта в Quagga, их нужно уменьшить до одной секунды, просто для того чтобы пользователь не ждал долго, пока обновится наша таблица маршрутизации.
Второе, нам нужно еще раз поправить Quagga таким образом, чтобы ваша RIP-метрика, которую может выставить ваш системный администратор, не уходила в poison реверс-пакет. Административно выставить метрику вы можете захотеть в случае, если у вас несколько балансировщиков для вашей системы, и вам нужно провести какие-то работы на одном из них. Как я уже говорил, IPVS энкапсулирует пакеты, добавляя 20 байт к каждому пакету IP-заголовка. Мы вынуждены будем запатчить Keepalived таким образом, чтобы он слал не только максимально похожие на пользовательские запросы, нам нужно, чтобы они еще были размером в 1500 байт, чтобы в случае, если у нас где-то в сети пакетик не пролезает по MTU — мы это сразу обнаружили.
Ну и последнее: для того чтобы достичь той производительности, которую я вам обещал, а именно в 600 000 пакетов в секунду, нам нужно будет на нашем сервере выключить irqbalance, и вручную разбросать процессы по ядрам. Cобственно говоря, разбрасывать придется процесс keepalived и очереди прерывания вашей сетевой карты. Будет здорово, если ваша сетевая карта будет поддерживать MSI-X, и у вас будет больше одной очереди. Вот так мы балансируем в Mail.Ru.

А теперь давайте поговорим немного о других вещах. Для того чтобы сделать проект стабильным, надежным и все время работающим. нам нужно сделать его модульным. Это позволит нам ломаться не сразу целиком, а по частям. Вы прекрасно понимаете, что какой бы ни был у вас сайт, ваши пользователи работают только с некоторыми функциями на нем. Какие-то части вашего сайта более популярны, какие-то менее. Соответственно, если ваш программный продукт модулен, то вы никогда не сломаетесь целиком. Вы сломаетесь каким-то куском, и это затронет меньшее количество ваших любимых пользователей. Вторая вещь — кэшируйте «негативные» ответы. Если какая-то из частей вашей системы почему-то перестала вам отвечать, не надо продолжать отправлять туда все запросы от ваших пользователей. Необходимо спроектировать систему таким образом, чтобы после того, как авария случилась, туда попадал каждый десятый, двадцатый, тысячный пакет, в зависимости от вашей нагрузки. Соответственно, как только ваш сервис начал отвечать правильно, вы разблокируете его автоматически, и работа восстанавливается.
Очень хорошая идея, которую мало кто реализует — работайте с вашими модулями асинхронно. Это можно делать как с помощью clientside — с помощью AJAX, так и на серверной стороне, это вам позволит, в случае если у вас проблемы с нагрузкой, за то время, пока вы будете ждать тормозящего модуля, собрать все остальные необходимые данные. Как только в вашей системе появляется больше одного сервера, очень хорошей идеей будет разделить нагрузку по типам. А именно — иметь специфицированный сервер для вашей базы данных, для вашего frontend-a, для вашей почтовой службы и т.д. Это вам позволяет опять же ломаться не целиком.

Релиз-менеджмент и тестирование
Давайте немного поговорим о релиз-менеджменте и тестировании. Я понимаю, что мы по времени не успеем покрыть весь релиз-менеджмент, тем более что на эту тему можно устроить целую конференцию. Но есть, тем не менее, ряд топиков, которые для Mail.Ru кажутся самыми важными и самыми главными.
Во-первых, половина проблем со стабильностью проекта связаны с релизом нового кода. И это говорит нам о том, что релиз-менеджмент в проекте должен быть. Под релиз-менеджментом я понимаю то, что вы, ваш менеджер, команда, которая занимается разработкой проекта, должны понимать, «а что мы сегодня запускаем», «что вошло в этот релиз», «кто за него отвечает», «какую нагрузку этот релиз добавит нам в продакшн»? Процесс релиза должен быть максимально автоматизирован, потому что… у нас в Mail.Ru даже есть одна простая поговорка — «чем более автоматизирован процесс, тем меньше сюрпризов в продакшене». Начиная с момента, когда чтобы запустить что-то на продакшен-серверах, вы начинаете что-то копировать, исправлять какие-то конфигурационные файлы вручную — ждите, пройдет совсем немного времени до того момента, когда вы ошибетесь. В случае, если у вас процесс релиза автоматический, во-первых, это гарантирует вам то, что вы выкатываете на продакшен именно то, что только что протестировали. Во-вторых, это минимизирует количество ошибок в конфигурационных файлах, недонесенные до продакшена библиотеки и т.д. То есть затраты на автоматизацию релиза невелики, а польза от этого, я считаю, очень большая.
Конечно же, все люди ошибаются, и мы не всегда можем предусмотреть, какую нагрузку мы принесем на наш сервис, запуская тот или иной новый функционал. Мы в Mail.Ru для этого применяем сплит-тестирование. Сплит-тестирование — это когда вы запускаете новую финчу только для некоторых пользователей. Во-первых — это дико нравится самим пользователям, потому что появляется группа избранных, которая видит всё самое новое, самое интересное, самые интересные баги. Во-вторых, это позволяет нам на этой группе посмотреть, а не ошиблись ли мы с нагрузкой, не сделали ли мы что-либо такое, что при запуске на всей системе приведет нас к аварии.
И последняя вещь, о которой я хочу чуть-чуть рассказать — каждый раз нужно релизить всё. Допустим, в вашей команде несколько разработчиков, и кто-то из них сделал свою задачу быстро, кто-то из них делал задачу долго. Так вот, даже если ваш продукт, который делал один разработчик, не готов к релизу — релизьте то, что есть. Даже если эти модули никто не вызывает, даже если они никому не нужны — все равно релизьте их в день релиза. Это позволяет вам избежать черного дня системного администратора, когда релизится огромнейший кусок кода, и если где-то что-то сломалось, разобраться уже невозможно. Поэтому, релизя свой продукт каждый раз по чуть-чуть, делая этот процесс постоянным, вы добиваетесь того, что у вас никогда не будет одного большого мегарелиза, после которого понадобится еще пять дней, чтобы все откатить.

Конечно, важно не только все релизить, важно также и прогнозировать нагрузку. У вас должны быть графики вашей нагрузки. Вы должны знать, как быстро вы работаете. В вашей команде разработки должен быть человек, в обязанности которого входит смотреть на эти графики, и предупреждать каждый раз — «ребята, кажется, мы приближаемся к критическим значениям». Мы должны иметь пороговые значения для всех времен ответов наших сервисов, потому что нам нужно знать, когда закричать о проблеме.
Существуют специфические проекты. Например, такие как сервис виртуальных открыток. В дни праздников, например, в Новый Год, в День Святого Валентина, нагрузка на таких сервисах возрастает в 20 раз. Соответственно, если вы помните об этом, то вы будете готовы к такому росту нагрузки.
Очень часто команда сформирована таким образом, что программисты разрабатывают новый функционал, а за стабильность вашего сайта отвечают администраторы — это плохая организация, это должна быть единая команда, люди должны понимать, что они запускают и как это отразится в продакшене. Не должно быть ситуаций, когда одни люди программируют и знают, что они собираются запустить, а другие люди отвечают за стабильность сайта, и для них каждый запуск — это сюрприз. Мы в Mail.Ru стараемся иметь оценочную метрику нагрузки, которую вызовет наш релиз, мы стараемся предсказать, что вот этот функционал потребует от нас столько-то дополнительных серверов. Вам тоже рекомендую это делать. Где-то, наверное, с
раза и вы научитесь угадывать нагрузку. Это очень сильно помогает вам прогнозировать вашу нагрузку, и своевременно увеличивать те мощности, которые вам необходимы.

Аварии
Теперь давайте поговорим о планировании аварий. Я не имею в виду диверсионную деятельность, я имею ввиду, что мы будем делать, когда у нас все, наконец-то, сломалось. А как мы помним, это неизбежно. Так вот, потратьте на это время до того. как у вас произошла авария, и вы сэкономите много часов того времени, которое будет вами потрачено на восстановление стабильности вашего сайта. Любой член команды должен знать — если что-то сломалось, то какова его функция, что он делает, как вводится резерв, как раскатываются бэкапы. Выкатка бэкапа должна быть полностью автоматизирована. Что я имею в виду под автоматизацией? К сожалению, когда у нас ломается оборудование, оно нас заранее не всегда предупреждает. Иногда это происходит ночью, иногда какие-то люди бывают в отпуске. Соответственно, чтобы у вас не возникло ситуации, когда ваш системный администратор где-то далеко, а ваши данные уже сломались, сделайте так, чтобы у вас бэкап выкатывался автоматически, по вашей просьбе, естественно. Предусмотрите заглушки и «лайт-версии» вашего сайта. Если уж поломка неизбежна, давайте сделаем так, чтобы пользователю было чуть менее плохо. Давайте покажем ему нормальное сообщение о том, что у нас проводятся какие-то ремонтные работы, вместо нашего любимого «internal server error 500».
Я, честно говоря, не могу сказать лучше о следующей теме моей презентации, чем вот эти два товарища, давайте их послушаем: (ролик из фильма) «Контрразведчик должен знать всегда, как никто другой, что верить в наше время нельзя никому, даже самому себе. А вот мне можно.»

Верить нельзя никому
Так вот, все те люди, которые занимаются разработкой сайтов, которые отвечают за их стабильность, они в каком-то смысле контрразведчики, потому что верить нельзя никому. В рамках этой презентации мне, конечно, можно. Регулярно проверяйте те самые планы, о которых мы с вами говорили на предыдущем слайде, «восстановления после сбоя». Разработка современного интернет-сайта происходит зачастую стохастически, очень быстро, огромным количеством изменений. И уже через полгода ваш отличный план о том, как мы быстро все починим, будет в лучшем случае полностью неработоспособен, а в худшем — принесет еще больший урон. Поэтому проверять нужно постоянно, лично. Нужно в тестовых целях запускать резервные сервера, нужно в тестовых целях использовать бэкапы и смотреть, что после этого происходит.

Отдельная тема — бэкапы. Опять же, никто не спорит, что бэкапы должны быть, но почему-то, когда что-то случается, их никогда нет. Если в этой аудитории есть люди, у которых есть в обязанностях создавать бэкапы, если в этой аудитории есть люди, у которых есть доступ на сервера, где хранятся бэкапы — после конференции зайдите, проверьте, они там есть, нет? Потому что периодически что-то ломается, что-то меняется, что-то происходит, в результате чего выясняется что, в худшем случае, бэкапа просто нет. Бывают случаи, когда наш проект настолько вырос, что мы выяснили, что восстановиться из бэкапа у нас занимает несколько месяцев. И такое я тоже видел. Соответственно, бэкапы должны не только быть, они должны быть годными к восстановлению, об этом всегда нужно помнить и это всегда нужно периодически проверять.
Когда авария случилась, у нас план сработал, мы все починили, все сказали «мы молодцы». В 10% случаев ваш сайт все еще не работает. Где-то что-то забылось, где-то что-то отвалилось, что-то не заметили. Нужно самому, лично проверить, после того как авария устранена — что она устранена для всех пользователей, и она устранена на самом деле.
Чтобы минимизировать количество аварий, по результатам каждой из них должно быть проведено совещание, и должно быть обсуждено, что в этой аварии было хорошо, что было плохо, какие планы сработали, какие нет, ожидали ли мы ее, какие еще аварии этого же типа возможны. Для примера приведу одну простую ситуацию — все аварии, которые происходят в крупных интернет-проектах, довольно однотипны.
Я думаю, многие из вас помнят летнюю аварию, когда Яндекс пролежал несколько часов, потому что они разлили по своей сети BGP-сессии, которые не должны были туда попасть. Самое смешное, что мы в Mail.Ru за полгода до этого сделали то же самое чуть с меньшими последствиями. Поэтому, я считаю, что на таких конференциях мы должны максимально обмениваться опытом друг с другом, потому что это позволяет исключать подобные ошибки, вплоть до полного повторения той аварии, которая была у нас. Они происходят в любых крупных проектах, да и в мелких тоже. Соответственно, обменивайтесь знаниями, используйте то, что я вам сегодня рассказал, и давайте перейдем к вопросам.

Вопросы
Вот вы говорили о мониторинге — очень хорошая штука, конечно же, мы тоже ее используем. Но у нас есть проблема с кейсами, которые очень сложно писать, поддерживать. Расскажите в двух словах, как вы это делаете?
Это где-то минут на 15, давайте я подойду к вам чуть попозже.
Здравствуйте. Илья, компания Мамба. Меня интересует вопрос: как вы мониторите статистические выбросы по времени ответа?
У нас есть календарь с государственными праздниками, и мы знаем распределение той или иной пользовательской нагрузки по неделям. В соответствии с этим календарем мы понимаем, какая нагрузка должна быть в этот день и мы понимаем, в пределах ее мы находимся или нет. Также у нас есть статистика по тому, как мы себя ведем в среднем в этот день недели, в среднем в этот месяц и т.д. Мы апроксимируем довольно большие объемы данных и получаем такие средние значения, которые позволяют нам довольно адекватно чувствовать себя в плане статистических выбросов.
Сергей, компания РусБИТех, у меня два вопроса. Первый: каким образом вы мониторите мониторинги, и второй — насколько у вас оффлайн-бэкапы отстают от онлайн данных?
Что касается мониторинга мониторингов — это очень просто. У нас есть событие, которое должно появиться, которое должен заметить наш мониторинг в определенное время. Если его не случилось, значит, мы в беде. Что касается оффлайн-бэкапов — зависит от сервиса, от нескольких часов до суток, не больше суток.
Мишин Павел. Насколько комфортно разработчику устранять эти аварии? Он как-то защищен или он виноват, он исправит и как-то будет наказан за это?
Тут у нас немного другой подход. У нас продакшен-сервера полностью защищены от разработчика. Там есть специальные люди, которые называются системные администраторы. Вот они и защищают продакшен от разработчика. Соответственно, в устранении аварии в основном принимает участие системный администратор, потому что он принял релиз у разработчика, он принял предыдущий стабильный рабочий релиз у разработчика, соответственно, в его компетенции находится — «мы чиним то, что произошло, откатываемся на предыдущий релиз», он отвечает за стабильность работы сервиса. То есть в плане разработчика — жизнь отличная, сделал багу и все хорошо.
Максим, «РИА Новости». Вы справедливо отметили, что надо защищать базы данных не только от того, что сломается железо, но и от того, что баги какие-то могут повредить сами данные. И в этом случае вы используете оффлайн-хранилище. А как вы страхуетесь от того, что вот эти вот битые данные попадут в оффлайн-бэкап?
Оффлайн-бэкап имеет некую историю. Если данные разбились, мы это замечаем и откатываемся на тот момент, где еще не было этого «коррапшена».
Валерий. Вопрос по поводу откатов. Значит если у вас там все плохо — вы говорите, что принимают участие в починке в основном администраторы и их основное действие — откатиться на предыдущую версию. Зачастую изменения в новом релизе связаны с изменениями схемы данных, порою — какими-то кардинальными изменениями. Как с этим бороться? Вот схема уже перекачана на новую версию..
Я понял. Это на самом деле то, почему разработчику тяжело разрабатывать высоконагруженный большой продукт. Каждый раз, когда ты это делаешь, и системный администратор принимает твой релиз, он обязательно задаст вопрос — «слушай, а вот если что-то пойдет не так, как мы это вернем обратно?». И все наши релизы должны предусматривать беспроблемный и автоматический возврат в предыдущую стабильную конфигурацию. Даже в случае если у нас изменилась схема данных, у нас должна остаться репликация с предыдущей схемой данных, какая-то из живых баз с предыдущей схемой данных или у нас должно быть некое промежуточное решение, которое поддерживает в актуальном состоянии и старую, и новую базу данных.
Вопрос второй — как часто у вас в основных проектах делаются релизы и кто принимает решение — «вот, сейчас делаем релиз»? Кто этот процесс инициирует?
У нас релиз запланирован по дню недели. Условно говоря — «сегодня четверг — мы релизим». Релизится то, что мы сделали к четвергу. Решение о том, что мы действительно релизим этот модуль принимает заказчик, как правило — это менеджер проекта. Схема выглядит так: менеджер проекта заказывает какую-то разработку, команда разработчиков ее реализует, дальше — тестирование и менеджер говорит «да, это то, что я хотел», после этого выступают те люди, которые защищают продакшен от разработчиков. Они принимают этот релиз в техническом смысле. Они спрашивают у разработчика «а что мы с этим делаем, когда это сломается», «как мне откатываться», «ты вообще сам уверен, что это надо раскатывать?» и т.д.
Сергей, РусБИТех. Вы упомянули о том, что вы используете сплит-тестирование. Т.е. некоторых пользователей вы петлей запускаете на новые версии программного продукта. Каким образом вы определяете кто эти пользователи? По их желанию или как-то по оригинальному принципу? Как вы распределяете тестовый трафик?
Есть три подхода на разных наших продуктах, в зависимости от свойств самого сервиса. В тех продуктах, где мы не можем автоматически управлять пользователями, например, наше клиентское программное обеспечение, у нас есть специальные группы пользователей, которые с удовольствием тестируют все наши новые баги. Те продукты, где мы можем сами выделить какую-то группу пользователей и сделать их тестовыми — мы это делаем сами. Те продукты, которые требуют стабильного региона — мы используем сплит- тестирование по региональному признаку. Например, если говорить о нашем мессенджере, у нас есть специальная группа пользователей, которая его тестирует. Если говорить о нашей почте — мы сами выбираем счастливцев, которые видят все новые фичи. Если говорить о нашем поиске, то у нас есть регионы, на которых мы тестируемся, чтобы видеть, что происходит с нашей долей в том или ином регионе.
Откройте секрет, регионы — это какие регионы? Центральный регион России или...
Зависит от того, что мы тестируем. Разные. Мы можем тонко нарезать нашу аудиторию, мы тестируемся как на одном городе, так и на целом регионе, в зависимости от того, что мы сейчас хотим запустить и проверить.
Иван Панченко. Мониторите ли вы ошибки в Java скрипте, которые возникают в браузере пользователей? А также падение этих пользователей? Это первый вопрос. А второй вопрос: вы говорили, что нехорошо показывать500-ю ошибку. Что вместо нее показывать, все решают по-разному. Корректно ли, по вашему мнению, показывать вместо страницы с контентом — страницу, на которой написано что «в этом блоге постов еще не было»?
С последнего начну. Что показывать на пустой странице? Мы, как правило, пытаемся сказать пользователю о том, что у нас произошла проблема и требуется время, чтобы ее починить — это в случае, если невозможно сделать какую-нибудь лайт-версию нашего продукта. Тем не менее, если мы можем обрезать функционал — мы просто даем ограниченный доступ к функционалу. Что касается ошибок Java-скрипта — да, мониторим, да, есть графики, по ним даже меряются статистические выбросы. На самом деле, что касается клиента — мы меряем довольно много. Каждый раз, когда ты заходишь на mail.ru, твой браузер с Java-скриптом отправляет нам, были ли ошибки, сколько загружалась страница и еще кучу информации о том, как вел себя наш сайт в вашем браузере.
Владимир. Вопрос про мониторинг. Используете ли вы opensource решения мониторинга либо вы используете самописный. Например, Яндекс очень долго использовал opensource решение и на текущий момент продолжает использовать, но уже пишет свой мониторинг.
Мы используем свой собственный мониторинг. 13 лет в ИТ-индустрии — это стаж. В тот момент, когда нам это понадобилось, мы не нашли ничего приемлемого, поэтому мы написали и с тех пор поддерживаем свой собственный мониторинг. У mail.ru очень много сущностей, которые нужно мониторить, причем мониторить их нужно быстро. Поэтому используем свой собственный продукт.
Можно вопросик, которого не было в принципе в докладе. По поводу информационной безопасности. Как вы обеспечиваете все свои части системы для того, чтобы предотвратить хакерскую атаку или что-либо еще, применяете ли какие-то системы мониторинга, методики?
Информационная безопасность бывает двух типов. Если говорить о DoS-атаках и о каких-либо вообще атаках на отказ от обслуживания, у нас подход очень простой. Наших мощностей должно быть больше, чем у людей, которые нас атакуют и пока у нас это получается. Не хочу хвастаться, но лет, наверное, 10 у нас не было проблем. Не в том смысле, что нас никто не атакует, а в том смысле, что мы просто выдерживаем и фильтруем тот трафик, который к нам приходит в случае DoS. Что касается безопасности в плане хакеров, в плане каких-то уязвимостей — да, конечно, у нас есть свои мониторинги, свои ловушки, мы постоянно следим за этим, очень внимательно относимся к тому, кто пытается сделать что-то нехорошее в наших сетях, на наших серверах.
Евгений. К вопросу о стабильности — используете ли вы какое-то специализированное железо для отражения DoS-атак?
Нет.
То есть, все за счет мощностей?
Не за счет мощностей — за счет мозгов.
Второй вопрос: заинтересована ли Mail.Ru Group в новой технологической площадке для привлечения новых центров обработки данных?
Да, однозначно. Мы с удовольствием рассматриваем предложения от новых дата-центров и предложения о строительстве новых дата-центров. Мы строим свои дата-центры и это очень интересно.
Андрей. Меня интересует вопрос, как происходит, если в случае падения, проблема не может быть решена автоматически, кто принимает участие в ее восстановлении? Например, ситуация: если проблема была в программном коде, и она всплыла1-го января ночью или когда группа программистов, которая разрабатывала этот код, летит в самолете в Тайланд.
За продакшен несут ответственность системные администраторы, на плечах которых держится все Mail.Ru. Они полностью способны устранить любые проблемы в нашем программном комплексе, и более того, они находятся на работе 24 часа в сутки. За Mail.Ru люди присматривают круглосуточно. Существуют дежурные смены и т.д. Эти люди, если под бой курантов что-то где-то отвалилось, примут решение о починке этой проблемы или об откате программного обеспечения на предыдущую стабильную версию. Но, честно скажу, мы перестаем запускать новый функционал где-то за неделю до Нового Года, чтобы на случай, если тот самый самолет в 12 часов где-то там зависнет, у нас была минимальная необходимость что-то менять в продакшене. То же касается пятниц, дней перед праздниками и т.д. Это вcё о стабильности.
Данный текст является стенограммой доклада Габриеляна Владимира на Форуме технологий Mail.Ru 2011, проходившем 16 ноября в центре Инфопространство. Подробности о технологии создания текстов докладов по видеозаписям см. здесь: «Изнанка» Форума технологий Mail.Ru: Хай-тек в event-management. Видеоверсии прочих докладов (включая версии для мобильных устройств) доступны на сайте Форума – techforum.mail.ru. Текстовые варианты докладов будут публиковаться здесь и на сайте Форума каждую неделю или немного пореже в похожем формате. Пожалуйста, сообщайте в «личку» об опечатках в тексте.
