На хабрахабре уже неоднократно обсуждались технологии работы с памятью используемые в различных гипервизорах. Эти технологии зачастую принято объединять под общим названием — Memory Overcommitment.
Цели которые обычно стремятся достигнуть применяя memory overcommitment две:
Когда запущенно множество виртуальных машин, некоторые из них могут содержать идентичные страницы памяти. Page sharing позволяет удерживать такие страницы в физической памяти гипервизора только в одном экземпляре. В итоге если страница памяти используется, к примеру, двумя виртуальными машинами (в них исполняется похожий код) они обе работают только с одной страницей памяти. Иными словами происходт дедубликация страниц. Используется метод вычисление хеша каждой используемой страницы и их сравние в таблице хешей. Если происходит совпадение, дополнителнительно запускается процесс побитового сравнения. Такая общая страница работает только на чтение. Если одной из машин необходимо изменить содержимое страницы, инициируется создание приватной копии и происходит подмена этой страницы. Только после ремапинга разрешается запись. По этому, то незначительное падение производительности которое обычно приписывают TPS (чуть менее 1%), заключается именно в процедуре воспроизведение такой подмены на запись. TPS включен и работает по-умолчанию со страницами гостевой памяти в 4KB. Для страниц размером в 2MB он выключен.
Включается когда значение свободной памяти хоста снижается преодолевая рубеж в 4%. Позволяет вытеснить уже выделенные, но не используемые страницы памяти. В лучшем случае это страницы которые операционная система обычно помечает в свой “free” лист (ОС, грубо говоря, заносит страницы гостевой физической памяти в два перечня — “allocate” и “free”). От псевдо-устройства vmmemctl, которое является драйвером в комплекте VMware Tools, в ОС поступает запрос на выделение требуемого объема памяти, после его получения, страницы этого объема сообщаются гипервизору как свободные.
Технология заключается в компрессии страниц памяти. Активируется вместе с свапированием виртуальным машин (не путать со свапом ОС) когда значение свободной памяти хоста преодолевает рубеж в 2%.
Метод заключается в создании специальной области памяти для каждой виртуальной машины — compression cache, которая предназначена содержать сжатые страницы памяти. Эта область изначально пуста и растет по мере ее накопления. Когда принимается решение о свапировании страницы памяти, сначала происходит ее анализ на уровень сжатия. Если уровень более 50%, происходит сжатие страницы и помещение ее в compression cache.
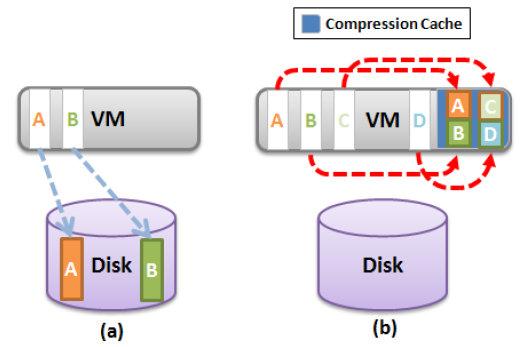
Таким образом, страница не попадает сразу в свап (рисунок a), а продолжает находится физической памяти хоста, но в сжатом виде (рисунок b). Таким образом высвобождается как минимум в два раза больше памяти ценой доступа к ней.
Если эта страница понадобилась, проводится декомпрессия ее из кеша и становится доступна вновь в гостевой памяти. Это значительно сокращает время извлечения страницы, по сравнению со свапом.
Объем compression cache имеет размер по-умолчанию равный 10% от сконфигурированной памяти виртуальной машины. Когда кеш заполняется, страницы к которым не было обращения долгое время, извлекаются через декомпрессию и выпадают в свап. Из compression cache страницы никогда не перемещаются в свап в сжатом виде.
Когда же необходимо высвободить даже ту область памяти которая используется под compression cache (в случае чрезвычайной нехватки памяти), тогда все сжатые страницы извлекаются и выпадают в свап, а область становится свободной.
Важно так же отметь, что объем памяти используемый под compression cache причисляется к гостевой памяти виртуальной машины. То есть этот объем не аллоцируется отдельно так, как память для оверхеда. Поэтому важно соблюдать оптимальное значение максимального размера compression cache. При слишком скромном размере, много сжатых страниц памяти будут выпадать в свап, значительно нивелируя преимущества memory compression. При слишком большом значении — в кеше будет находится слишком много страниц которые могут вообще долгое время быть не востребованными, а раздутый кеш будет попросту тратить объем гостевой памяти. Поведение технологии регулируется расширенными параметрами, наименование которых начинается с Mem.MemZip. Например, размер кеша в первую очередь регулируется параметром Mem.MemZipMaxPc.
В случае когда применяя TPS, ballooning и memory compression гипервизору не удается превысить рубеж свободной памяти хоста в 2%, ESXi активно использует свапинг виртуальных машин (страницы начинают выпадать в .swap файл, создаваемый на дисковом хранилище при запуске виртуальной машины).
Как правило, если рассматривать свапинг виртуальных машин сам по себе, он позволяет гарантировано добиться высвобождения определенного значения памяти на определенной время, но обладает такими серьезными недостатками:
Сравнивают падение производительность конфигурации Sharepoint с включенной memory comression и без нее:

По горизонтали постепенно уменьшали количество физической памяти доступной гипервизору. А по вертикали слева можно проследить падение производительности.
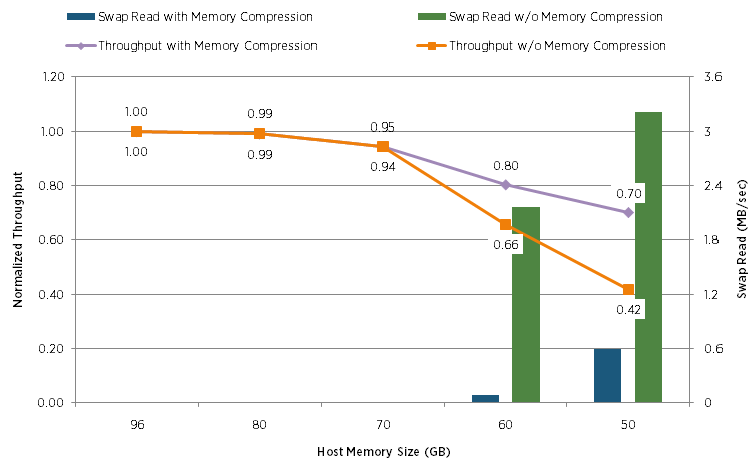
В этом тесте аналогично сравнивали падение производительности нагрузок Swingbench:
А в этом тесте, сравнивают падение производительности с применением Host Cache на SSD дисках и без:
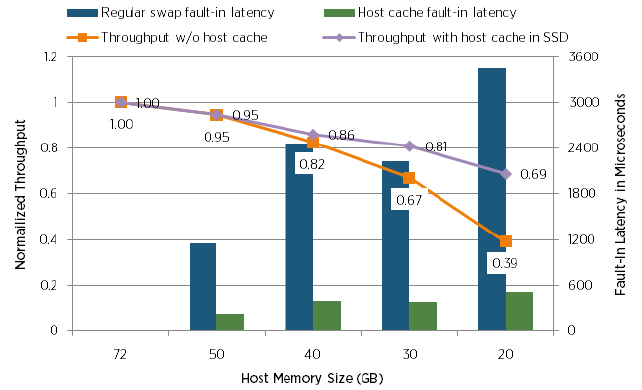
К сожалению, так и осталось и не ясно какой же тип диска использовался в тесте без Host Cache.
Дополнительно на всех графиках выше показаны значение свапирования, что позволяет легко проследить работу и технологий TPS и ballooning, которые так же были включены в этих тестах. Подробные тесты технологий TPS и ballooning смотрите в ссылках ниже.
В этом топике думаю так же следует вспомнить о заявленной в ESXi 5.0 фиче Memory fault isolation. Гипервизор способен обнаружить сбойные регионы памяти и изолировать их. Так, если сбойный регион был обнаружен среди страниц гостевой памяти, виртуальная машина перезапускается. А вот в пурпурный экран ESXi теперь будет падать только когда такой регион занят кодом гипервизора.
По метериалам:
www.petri.co.il/memory-compression-in-vsphere-4-1.htm
www.vmware.com/pdf/Perf_Best_Practices_vSphere5.0.pdf
www.vmware.com/files/pdf/mem_mgmt_perf_vsphere5.pdf
www.vmware.com/support/vsphere5/doc/vsphere-esx-vcenter-server-50-new-features.html
Цели которые обычно стремятся достигнуть применяя memory overcommitment две:
- Повышение утилизации физической памяти хостов преимущественно активными гостевыми страницами памяти на столько на сколько это возможно;
- Повышение общего значение консолидации виртуальных машин.
Transparent page sharing (TPS)
Когда запущенно множество виртуальных машин, некоторые из них могут содержать идентичные страницы памяти. Page sharing позволяет удерживать такие страницы в физической памяти гипервизора только в одном экземпляре. В итоге если страница памяти используется, к примеру, двумя виртуальными машинами (в них исполняется похожий код) они обе работают только с одной страницей памяти. Иными словами происходт дедубликация страниц. Используется метод вычисление хеша каждой используемой страницы и их сравние в таблице хешей. Если происходит совпадение, дополнителнительно запускается процесс побитового сравнения. Такая общая страница работает только на чтение. Если одной из машин необходимо изменить содержимое страницы, инициируется создание приватной копии и происходит подмена этой страницы. Только после ремапинга разрешается запись. По этому, то незначительное падение производительности которое обычно приписывают TPS (чуть менее 1%), заключается именно в процедуре воспроизведение такой подмены на запись. TPS включен и работает по-умолчанию со страницами гостевой памяти в 4KB. Для страниц размером в 2MB он выключен.
Ballooning
Включается когда значение свободной памяти хоста снижается преодолевая рубеж в 4%. Позволяет вытеснить уже выделенные, но не используемые страницы памяти. В лучшем случае это страницы которые операционная система обычно помечает в свой “free” лист (ОС, грубо говоря, заносит страницы гостевой физической памяти в два перечня — “allocate” и “free”). От псевдо-устройства vmmemctl, которое является драйвером в комплекте VMware Tools, в ОС поступает запрос на выделение требуемого объема памяти, после его получения, страницы этого объема сообщаются гипервизору как свободные.
Memory Compression
Технология заключается в компрессии страниц памяти. Активируется вместе с свапированием виртуальным машин (не путать со свапом ОС) когда значение свободной памяти хоста преодолевает рубеж в 2%.
Метод заключается в создании специальной области памяти для каждой виртуальной машины — compression cache, которая предназначена содержать сжатые страницы памяти. Эта область изначально пуста и растет по мере ее накопления. Когда принимается решение о свапировании страницы памяти, сначала происходит ее анализ на уровень сжатия. Если уровень более 50%, происходит сжатие страницы и помещение ее в compression cache.
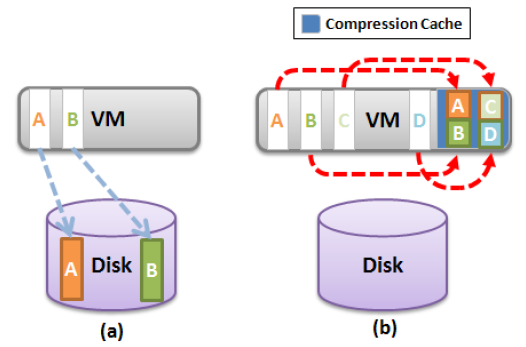
Таким образом, страница не попадает сразу в свап (рисунок a), а продолжает находится физической памяти хоста, но в сжатом виде (рисунок b). Таким образом высвобождается как минимум в два раза больше памяти ценой доступа к ней.
Если эта страница понадобилась, проводится декомпрессия ее из кеша и становится доступна вновь в гостевой памяти. Это значительно сокращает время извлечения страницы, по сравнению со свапом.
Объем compression cache имеет размер по-умолчанию равный 10% от сконфигурированной памяти виртуальной машины. Когда кеш заполняется, страницы к которым не было обращения долгое время, извлекаются через декомпрессию и выпадают в свап. Из compression cache страницы никогда не перемещаются в свап в сжатом виде.
Когда же необходимо высвободить даже ту область памяти которая используется под compression cache (в случае чрезвычайной нехватки памяти), тогда все сжатые страницы извлекаются и выпадают в свап, а область становится свободной.
Важно так же отметь, что объем памяти используемый под compression cache причисляется к гостевой памяти виртуальной машины. То есть этот объем не аллоцируется отдельно так, как память для оверхеда. Поэтому важно соблюдать оптимальное значение максимального размера compression cache. При слишком скромном размере, много сжатых страниц памяти будут выпадать в свап, значительно нивелируя преимущества memory compression. При слишком большом значении — в кеше будет находится слишком много страниц которые могут вообще долгое время быть не востребованными, а раздутый кеш будет попросту тратить объем гостевой памяти. Поведение технологии регулируется расширенными параметрами, наименование которых начинается с Mem.MemZip. Например, размер кеша в первую очередь регулируется параметром Mem.MemZipMaxPc.
Hypervisor Swapping
В случае когда применяя TPS, ballooning и memory compression гипервизору не удается превысить рубеж свободной памяти хоста в 2%, ESXi активно использует свапинг виртуальных машин (страницы начинают выпадать в .swap файл, создаваемый на дисковом хранилище при запуске виртуальной машины).
Как правило, если рассматривать свапинг виртуальных машин сам по себе, он позволяет гарантировано добиться высвобождения определенного значения памяти на определенной время, но обладает такими серьезными недостатками:
- Гипервизор на самом деле не знает какие страницы памяти оптимальнее засвапировать так, как это знает операционная система которая ими распоряжается;
- По этой же причине существует проблема двойного свапирования. Когда менеджер управленя памяти ОС решает засвапировать ту же страницу, которую уже успел засвапировать гипервизор, страница извлекается гипервизором, и сразу же выпадает в свап операционной системы;
- Ну и конечно же свапирование очень дорогое для виртуальной машины. Задержки, во время которых происходит извлечение страниц из свапа, могут доходить до десятка милисекунд. Это приводит к серьезному падению производительности.
- Снижение эффекта пересечения с работой менеджера управления памятью ОС путем случайной выборки страниц памяти для свапирования;
- Применения Memory Compression для снижения количества страниц отправляемых в свап;
- Применение SSD дисков для хранеия свапа. Так, вынеся свап на SSD, у которого скорость чтение значительно выше чем у обычных дисков, можно значительно снизить задержку на извлечении страниц из свапа. Название этому подходу дали Host Сache, и дают рекомендацию использовать лучше локальные SSD, нежели использовать на удаленной СХД.
Некоторые результаты тестов проведенных VMware
Сравнивают падение производительность конфигурации Sharepoint с включенной memory comression и без нее:
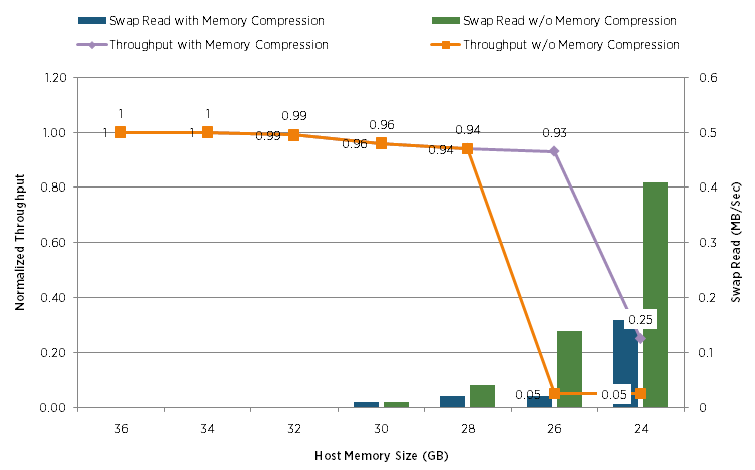
По горизонтали постепенно уменьшали количество физической памяти доступной гипервизору. А по вертикали слева можно проследить падение производительности.
В этом тесте аналогично сравнивали падение производительности нагрузок Swingbench:

А в этом тесте, сравнивают падение производительности с применением Host Cache на SSD дисках и без:
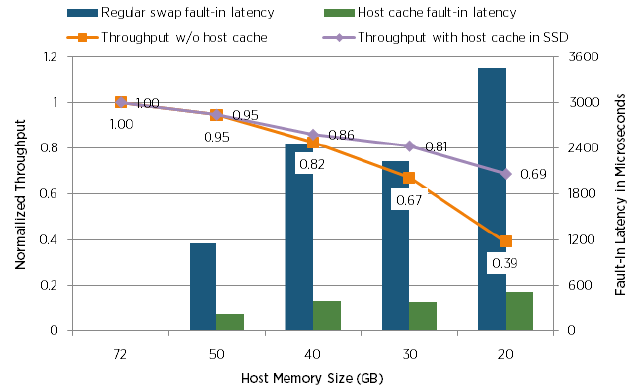
К сожалению, так и осталось и не ясно какой же тип диска использовался в тесте без Host Cache.
Дополнительно на всех графиках выше показаны значение свапирования, что позволяет легко проследить работу и технологий TPS и ballooning, которые так же были включены в этих тестах. Подробные тесты технологий TPS и ballooning смотрите в ссылках ниже.
В этом топике думаю так же следует вспомнить о заявленной в ESXi 5.0 фиче Memory fault isolation. Гипервизор способен обнаружить сбойные регионы памяти и изолировать их. Так, если сбойный регион был обнаружен среди страниц гостевой памяти, виртуальная машина перезапускается. А вот в пурпурный экран ESXi теперь будет падать только когда такой регион занят кодом гипервизора.
По метериалам:
www.petri.co.il/memory-compression-in-vsphere-4-1.htm
www.vmware.com/pdf/Perf_Best_Practices_vSphere5.0.pdf
www.vmware.com/files/pdf/mem_mgmt_perf_vsphere5.pdf
www.vmware.com/support/vsphere5/doc/vsphere-esx-vcenter-server-50-new-features.html









