Здравствуй, Хабр!
В этой статье я хочу рассказать какие есть подходы для обеспечения отказоустойчивости и масштабирования инфраструктуры серверов приложений WebSphere Application Server 7 компании IBM.
Для начала немного терминологии, которая будет использоваться:
Высокая доступность (англ. High availability) — это метод проектирования системы, позволяющий достигать высокого уровня доступности системы в течение какого-либо промежутка времени.
Для бизнес-систем высокая доступность подразумевает создание избыточности в критических бизнес-системах. Тогда отказ одного компонента, будь то отказ маршрутизатора или сетевой карты или ролграмного компонента, не будет вызывать сбой приложения.
Доступность в основном выражется в процентах или в «девятках».
А = MTBF / ( MTBF + MTTR).
90% («одна девятка») — 16.8 часов простоя в неделю
99% («две девятки») — 1.7 часа простоя в неделю
99.9% («три девятки») — 8.8 часов простоя в год
99.99% («четыре девятки») — 53 минуты простоя в год
MTBF (англ. Mean time between failures ) — Средняя продолжительность работы между остановками, то есть показывает, какая наработка в среднем приходится на один отказ.
MTTR (англ. Mean Time to Restoration ) — среднее время, необходимое для восстановления нормальной работы после возникновения отказа.
SPOF (англ. single point of failure ) — часть системы, которая в случае отказа делает систему недоступной.
WAS — J2EE сервер приложений компании IBM. Существует несколько вариантов поставки:
0. Community Edition — открытый проект на базе Apache Geronimo;
1. Express — 1 узел/1 сервер приложений;
2. Base — 1 узел/ n серверов приложений;
3. Network Deployment (ND) — включает в себя набор компонет для построения масшабируемой и отказоустойчивой инфраструктуры из большого количества серверов приложений;
4. и еще несколько различных специфических вариантов (for z/OS, Hypervisor Edition, Extended Deployment).
Далее будем рассматривать все, что связано с именно с версией Network Deployment 7 (WAS ND ). На данный момент уже существют версии 8.0 и 8.5, но подходы описанные в статье применимы и к ним.
Основные термины относящиеся к топологиям Network Deployment:
Ячейка — Организационный юнит, который включает в себя менеджер развертывания(Deployment Manager) и несколько узлов(Node). Менеджер развертывания управляет узлами посредством агентов узлов(Node Agent).
Узел состоит из агента узла, который, как мы уже понимаем, используется для управления, и одним или несколькими серверами приложений (Application Server).

Такая иерархия (Ячейка / Узел / Сервер) помогает организовать все множество серверов и объединять их в группы согласно функциональности и требованиям по доступности.
Сервер приложений — JVM 5й спецификации Java EE (версии WAS 8 и 8.5 соостветствуют спецификации Java EE 6)
Профиль — набор настроек сервера приложений, которые применяются при его запуске. При старте экземпляра JVM, настройки ее окружения считываются из профиля и от его типа зависят функции которые будет выполнять сервер приложений. Менеджер развертывания, агент узла, сервер приложений — это частные примеры профилей. Далее в статье мы рассмотрим зачем и когда применять различные профили и как они взаимодействуют вместе, и чего позволяют добиться.
Stand-alone профиль отличается от федерированного тем, что управление несколькими Stand-alone профилями выполняется из различных административных консолей, а федерированные профили управляются из единой точки, что намного удобнее и быстрее.
Итак, исходя из поставленных задач по обеспечению высокой доступности некой бизнесс-системы работающей на инфраструктуре серверов приложений нам необходимо построить такую инфраструктуру, которая будет обеспечивать выполнение этих требований.
Уровень I
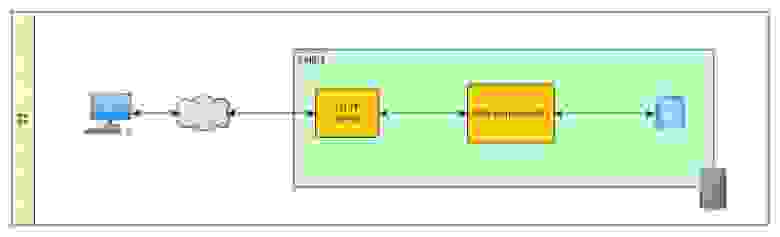
Cтандартная трехуровневая архитектура. Имеем один физический/виртуальный сервер на котором расположен stand-alone профиль WAS со своей административной консолью, СУБД и HTTP-сервер.
Перечислим какие точки отказа присутствуют в данной конфигурации и от уровня к уровню будем пытаться их устранить:
1. HTTP cервер;
2. Сервер приложений;
3. База данных;
4. Все програмные компоненты, которые обеспечивают взаимодействие нашего сервера с другими компонентами инфраструктуры ПО ( Firewall, LDAP, и т.д.)
5. Аппаратные средства.

На этом уровне мы устраняем единственную точку отказа — сервер приложений. Для этого нам надо создать кластер из друх серверов приложиний и для управления ими нам понадобятся еще две компоненты:
а) менеджер развертывания;
б) агент управления.
Менеджер развертывания фактически выполняет функцию обьединения административных консолей всех серверов приложений, которые находятся под его управлением. При изменении конфигураций одного или нескольких серверов, настройки «спускаются» от менеджера равертывания на сервера посредством агентов управления.
В случае отказа одного из серверов приложений HAManager автоматически восстановит все данные на втором сервере.
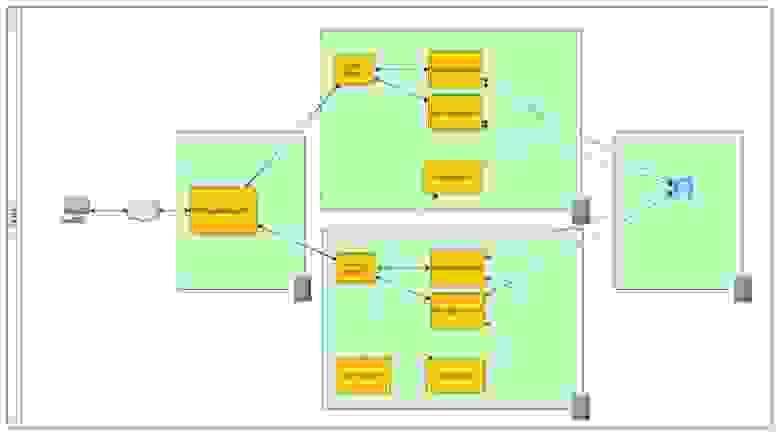
На этом уровне мы можем закрыть сразу несколько точек отказа — HTTP-сервер и физический сервер на котором крутятся сервера приложений. Для этого вынесем нашу БД за пределы наших физических серверов. Уже на 2-х серверах развернем 2 узла и в каждом из них создадим по паре серверов приложений. И обьеденим все сервера в единый кластер. В случае отказа одного из физических серверов данные и состояния приложений будут восстановлены на второй системе. В дополнение к этому используя балансировщик нагрузки (еще один тип профиля) мы можем распределить поступающие запросы между системами и таким образом распределить нагрузку и повысить производительность работы наших приложений. Применяя данную топологию мы получаем новую возможную точку отказа — баланcировщик нагрузки.
Дополним уровень III резервным балансировщиком нагрузки и в дополнение к этому обеспечим надежность нашей БД. Детально мезанизмы кластеризации баз данных рассматривать не будем, т.к. они сами достойны отдельной статьи.
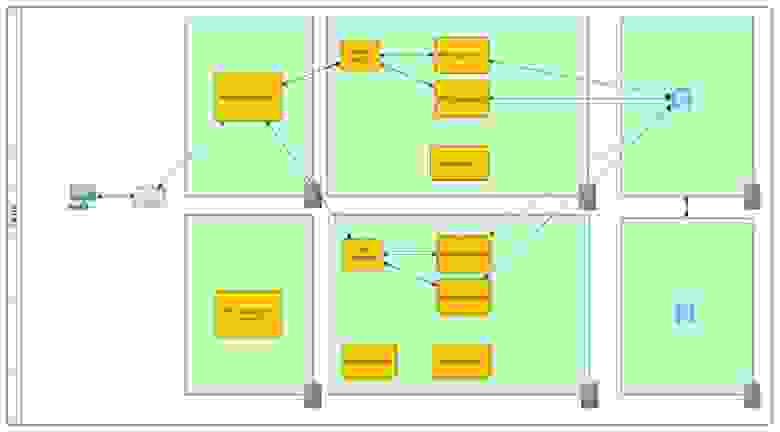
И финальным аккордом продублируем всю инфраструктуру и перенесем ее подальше, на случай если наш дата-центр затопит
В дополнение к этому, возможно будет не лишним вынести наши Front-end сервера в DMZ зону.
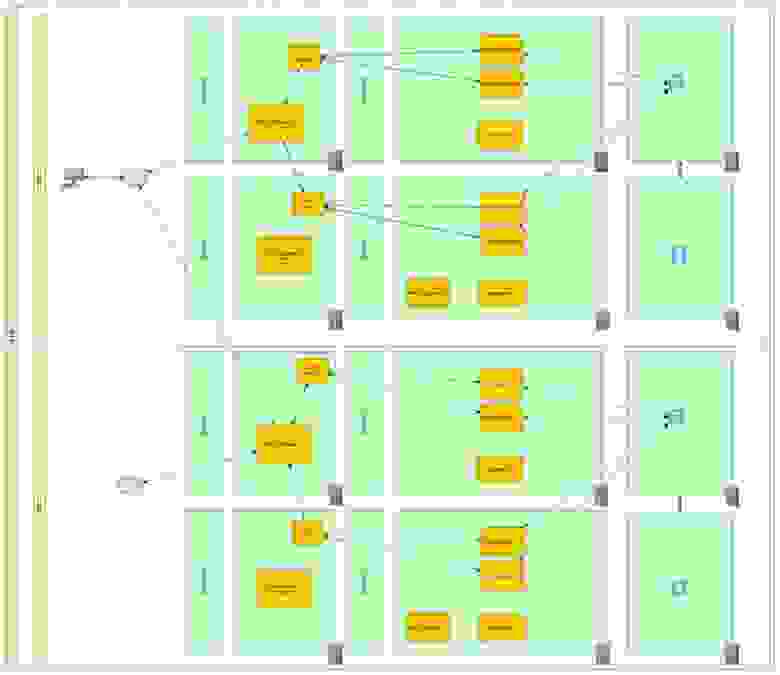
Как видим обеспечение непрерывной работы критических бизнесс-систем может быть ОЧЕНЬ затратным и прежде чем начинать построение таких решений необходимо оценить все риски и готовность к внедрению.
Спасибо за внимание.
В этой статье я хочу рассказать какие есть подходы для обеспечения отказоустойчивости и масштабирования инфраструктуры серверов приложений WebSphere Application Server 7 компании IBM.
Для начала немного терминологии, которая будет использоваться:
Высокая доступность (англ. High availability) — это метод проектирования системы, позволяющий достигать высокого уровня доступности системы в течение какого-либо промежутка времени.
Для бизнес-систем высокая доступность подразумевает создание избыточности в критических бизнес-системах. Тогда отказ одного компонента, будь то отказ маршрутизатора или сетевой карты или ролграмного компонента, не будет вызывать сбой приложения.
Доступность в основном выражется в процентах или в «девятках».
А = MTBF / ( MTBF + MTTR).
90% («одна девятка») — 16.8 часов простоя в неделю
99% («две девятки») — 1.7 часа простоя в неделю
99.9% («три девятки») — 8.8 часов простоя в год
99.99% («четыре девятки») — 53 минуты простоя в год
MTBF (англ. Mean time between failures ) — Средняя продолжительность работы между остановками, то есть показывает, какая наработка в среднем приходится на один отказ.
MTTR (англ. Mean Time to Restoration ) — среднее время, необходимое для восстановления нормальной работы после возникновения отказа.
SPOF (англ. single point of failure ) — часть системы, которая в случае отказа делает систему недоступной.
WAS — J2EE сервер приложений компании IBM. Существует несколько вариантов поставки:
0. Community Edition — открытый проект на базе Apache Geronimo;
1. Express — 1 узел/1 сервер приложений;
2. Base — 1 узел/ n серверов приложений;
3. Network Deployment (ND) — включает в себя набор компонет для построения масшабируемой и отказоустойчивой инфраструктуры из большого количества серверов приложений;
4. и еще несколько различных специфических вариантов (for z/OS, Hypervisor Edition, Extended Deployment).
Далее будем рассматривать все, что связано с именно с версией Network Deployment 7 (WAS ND ). На данный момент уже существют версии 8.0 и 8.5, но подходы описанные в статье применимы и к ним.
Основные термины относящиеся к топологиям Network Deployment:
Ячейка — Организационный юнит, который включает в себя менеджер развертывания(Deployment Manager) и несколько узлов(Node). Менеджер развертывания управляет узлами посредством агентов узлов(Node Agent).
Узел состоит из агента узла, который, как мы уже понимаем, используется для управления, и одним или несколькими серверами приложений (Application Server).
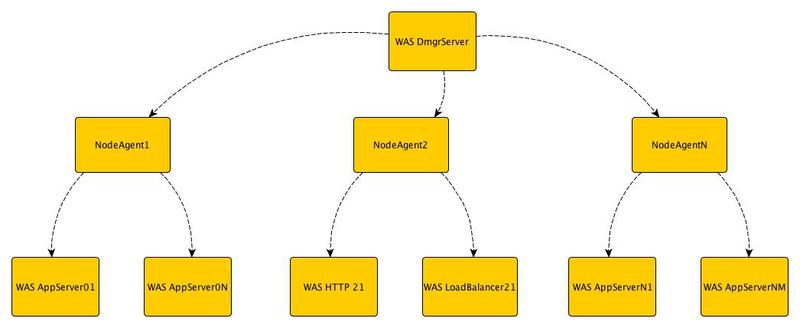
Такая иерархия (Ячейка / Узел / Сервер) помогает организовать все множество серверов и объединять их в группы согласно функциональности и требованиям по доступности.
Сервер приложений — JVM 5й спецификации Java EE (версии WAS 8 и 8.5 соостветствуют спецификации Java EE 6)
Профиль — набор настроек сервера приложений, которые применяются при его запуске. При старте экземпляра JVM, настройки ее окружения считываются из профиля и от его типа зависят функции которые будет выполнять сервер приложений. Менеджер развертывания, агент узла, сервер приложений — это частные примеры профилей. Далее в статье мы рассмотрим зачем и когда применять различные профили и как они взаимодействуют вместе, и чего позволяют добиться.
Stand-alone профиль отличается от федерированного тем, что управление несколькими Stand-alone профилями выполняется из различных административных консолей, а федерированные профили управляются из единой точки, что намного удобнее и быстрее.
Постановка задачи
Итак, исходя из поставленных задач по обеспечению высокой доступности некой бизнесс-системы работающей на инфраструктуре серверов приложений нам необходимо построить такую инфраструктуру, которая будет обеспечивать выполнение этих требований.
Уровень I
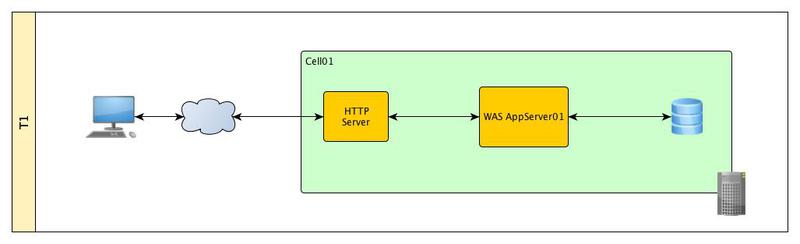
Cтандартная трехуровневая архитектура. Имеем один физический/виртуальный сервер на котором расположен stand-alone профиль WAS со своей административной консолью, СУБД и HTTP-сервер.
Перечислим какие точки отказа присутствуют в данной конфигурации и от уровня к уровню будем пытаться их устранить:
1. HTTP cервер;
2. Сервер приложений;
3. База данных;
4. Все програмные компоненты, которые обеспечивают взаимодействие нашего сервера с другими компонентами инфраструктуры ПО ( Firewall, LDAP, и т.д.)
5. Аппаратные средства.
Уровень II
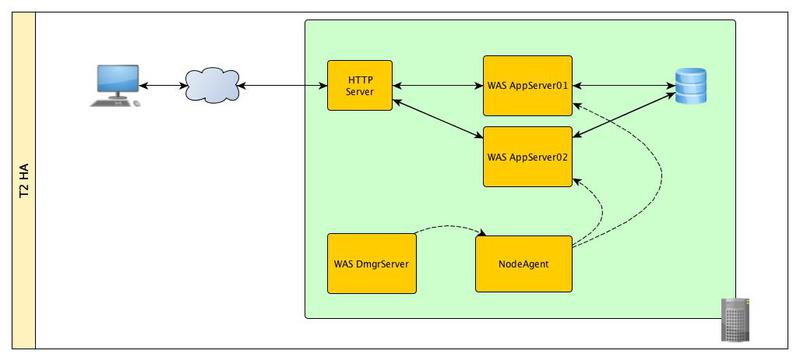
На этом уровне мы устраняем единственную точку отказа — сервер приложений. Для этого нам надо создать кластер из друх серверов приложиний и для управления ими нам понадобятся еще две компоненты:
а) менеджер развертывания;
б) агент управления.
Менеджер развертывания фактически выполняет функцию обьединения административных консолей всех серверов приложений, которые находятся под его управлением. При изменении конфигураций одного или нескольких серверов, настройки «спускаются» от менеджера равертывания на сервера посредством агентов управления.
В случае отказа одного из серверов приложений HAManager автоматически восстановит все данные на втором сервере.
Уровень III

На этом уровне мы можем закрыть сразу несколько точек отказа — HTTP-сервер и физический сервер на котором крутятся сервера приложений. Для этого вынесем нашу БД за пределы наших физических серверов. Уже на 2-х серверах развернем 2 узла и в каждом из них создадим по паре серверов приложений. И обьеденим все сервера в единый кластер. В случае отказа одного из физических серверов данные и состояния приложений будут восстановлены на второй системе. В дополнение к этому используя балансировщик нагрузки (еще один тип профиля) мы можем распределить поступающие запросы между системами и таким образом распределить нагрузку и повысить производительность работы наших приложений. Применяя данную топологию мы получаем новую возможную точку отказа — баланcировщик нагрузки.
Уровень VI
Дополним уровень III резервным балансировщиком нагрузки и в дополнение к этому обеспечим надежность нашей БД. Детально мезанизмы кластеризации баз данных рассматривать не будем, т.к. они сами достойны отдельной статьи.
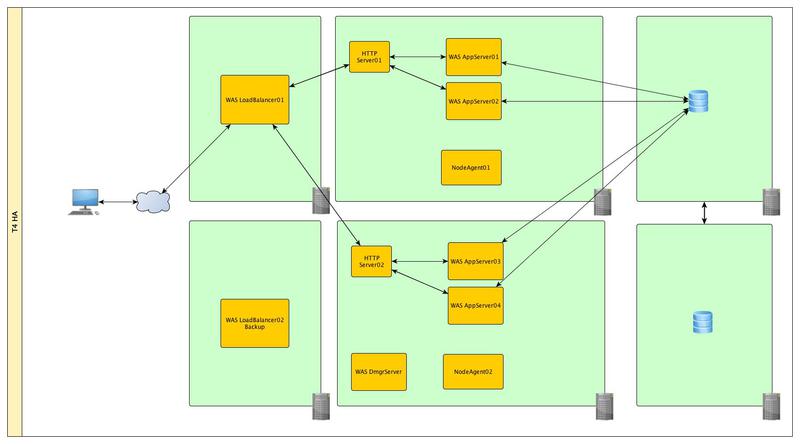
Уровень V
И финальным аккордом продублируем всю инфраструктуру и перенесем ее подальше, на случай если наш дата-центр затопит
В дополнение к этому, возможно будет не лишним вынести наши Front-end сервера в DMZ зону.
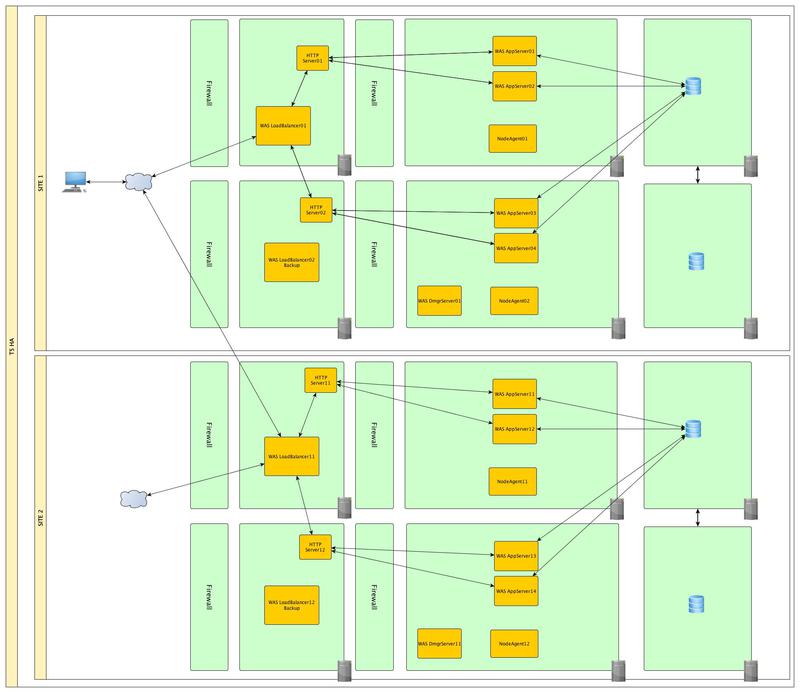
Итого
Как видим обеспечение непрерывной работы критических бизнесс-систем может быть ОЧЕНЬ затратным и прежде чем начинать построение таких решений необходимо оценить все риски и готовность к внедрению.
Спасибо за внимание.







