В статье Распознавание лиц человеческим мозгом: 19 фактов, о которых должны знать исследователи компьютерного зрения упоминался экспериментальный факт: в мозге примата имеются нейроны, селективно реагирующие на изображение морды лица (человека, обезьяны и т.п.), причем средняя задержка составляет около 120 мс. Из чего в комментарии я сделал дилетантский вывод о том, что зрительный образ обрабатывается прямым распространением сигнала, и количество слоёв нейронной сети — около 12.
Предлагаю новое экспериментальное подтверждение этого факта, опубликованное concretely нашим любимым Andrew Ng.
Авторы провели широкомасштабный эксперимент по построению детектора человеческих лиц на основании огромного количества изображений, не маркированных никаким образом. Была построена 9-слойная нейронная сеть со структурой разреженного автоэнкодера с локальными рецептивными полями. Нейронная сеть реализована на кластере из 1000 компьютеров, по 16 ядер в каждом, и содержит 1 миллиард связей между нейронами. Для обучения сети использовали 10 миллионов кадров 200х200 пикселов, случайным образом полученных из роликов YouTube. Обучение методом асинхронного градиентного спуска заняло 3 дня.
В результате обучения на немаркированной выборке, без учителя, вопреки интуиции, в выходном слое сети был выделен нейрон, селективно реагирующий на присутствие лица на изображении. Контрольные эксперименты показали, что этот классификатор устойчив не только к смещению лица на поле изображения, но и к масштабированию и даже к 3D-вращению вне плоскости изображения! Оказалось, что эта нейронная сеть способна обучаться распознаванию разнообразных высокоуровневых понятий, например человеческих фигур или кошек.
Полный текст статьи см. по ссылке, здесь же я привожу краткий пересказ.
В нейробиологии считается, что в мозге можно выделить отдельные нейроны, селективные к определенным обобщенным категориям, таким как человеческие лица. Их еще называют «бабушкины нейроны».
В искусственных нейронных сетях стандартным подходом является обучение с учителем: например, для построения классификатора человеческих лиц берется набор изображение лиц, а также набор изображений, не содержащих лиц, причем каждое изображение промаркировано «лицо» — «не лицо». Необходимость получения больших маркированных коллекций обучающих данных является большой технической проблемой.
В данной работе авторы попытались ответить на два вопроса: можно ли обучить нейронную сеть распознаванию лиц из НЕмаркированных данных, и можно ли экспериментально подтвердить возможность самообучения «бабушкиных нейронов» на немаркированных данных. Это в принципе подтвердит гипотезу о том, что младенцы самостоятельно обучаются группировать похожие изображения (например, лиц) без вмешательства учителя.
Обучающий набор составили путем случайной выборки по одному кадру из 10 млн. роликов YouTube. Из каждого ролика брали только один кадр, чтобы избежать дубликатов в выборке. Каждй кадр масштабировали до размера 200х200 пискелов (что отличает описываемый эксперимент от большинства работ по распознаванию, оперирующих обычно фреймами 32х32 или т.п.) Вот типичные изображения из обучающей выборки:
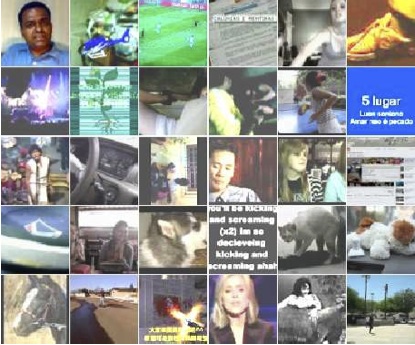
Основой для эксперимента послужил разреженный автоэнкодер (описанный на хабре). Ранние эксперименты с автоэнкодерами, имеющими малую глубину, позволили получить классификаторы низкоуровневых признаков (отрезки, границы и т.п.) аналогичные фильтрам Габора.
Описываемый алгоритм использует многослойный автоэнкодер, а также некоторые важные отличительные особенности:
Локальные рецептивные поля позволяют масштабировать нейронную сеть для крупных изображений. Объединение фреймов (pooling) и локальная нормализация контрастов позволяет добиться инвариантности к перемещению и локальным деформациям.
Используемый автоэнкодер состоит из трех повторяющихся слоев, в каждом из которых используются одинаковые подуровни: локальной фильтрации, локального объединения (pooling), локальной нормализации контрастов.
Важнейшей особенностью данной структуры является локальная связность между нейронами. Первый подуровень использует рецептивные поля 18х18 пикселов, а второй подуровень объединяет фреймы по 5х5 пересекающихся соседних областей. Обратите внимание, что локальные рецептивные поля не используют конволюции, т.е. параметры каждого рецетивного поля не повторяются, они уникальны. Этот подход боолее приближен к биологическому прототипу, а также позволяет обучиться большему количеству инвариантов.

Локальная нормализация контраста также имитирует процессы в биологическом зрительном тракте. Из активации каждого нейрона вычитают взвешенное среднее значение активаций соседних нейронов (весовые коэффициенты по Гауссу). Затем производится нормализация по локальному среднеквадратичному значению активаций соседних нейронов, также взвешенных по Гауссу.
Целевая функция при обучении сети минимизирует значение погрешности воспроизведения исходного изображения разреженным автоэнкодером. Оптимизация производится глобально для всех управляемых параметров сети (свыше 1 миллиарда параметров) методом асинхронного градиентного спуска (asynchronous SGD). Для решения столь масштабной задачи был реализован паралеллизм модели, заключающийся в том, что локальные веса нейронной сети распределяются на различные машины. Один экземпляр модели распределяется на 169 компьютеров, по 16 процессорных ядер в каждом.
Для дальнейшего распараллеливания процесса обучения реализован асинхронный градиентный спуск с использованием нескольких экземпляров модели. В описываемом эксперименте обучающую выборку разделили на 5 порций, и проводили обучение каждой порции на отдельном экземпляре модели. Модели передают обновленные значения параметров на централизованные «серверы параметров» (256 серверов). В упрощенном изложении, перед обработкой мини-серии из 100 обучающих изображений, модель запрашивает параметры у серверы параметров, обучается (обновляет параметры) и передает градиенты параметров на серверы параметров.
Такой асинхронный градиентный спуск обладает устойчивостью к сбоям отдельных узлов сети.
Для проведения данного эксперимента был разработан фреймворк DistBelief, который решает все вопросы коммуникаций между параллельными компьютерами в кластере, включая диспетчиризацию запросов к серверам параметров. Процесс обучения длился 3 дня.
Удивительно, но в процессе обучения сформировались нейроны, лучший из которых показал точность в распознавании лиц 81.7%. Гистограмма уровней активации (относительно порогового значения Ноль) показывает, какое количество изображений в тестовой выборке вызывало ту или иную активацию «бабушкиного нейрона». Синим цветом показаны изображения, не содержащие лиц (случайные изображения), красным цветом — содержащие лица.

Для того, чтобы подтвердить, что классификатор обучен именно распознаванию лиц, провели визуализацию обученной сети двумя методами.
Первый метод — отбор тестовых изображений, вызвавших наибольшую активацию нейрона-классификатора:

Второй подход — численная оптимизация для получения оптимального стимула. Методом градиентного спуска был получен входной паттерн, который максимизирует значение выходной активации классификатора при заданных параметрах нейронной сети:

Более подробно количественные оценки и выводы о результатах эксперимента см. в оригинале статьи. От себя хочу заметить, что масштабным вычислительным экспериментом была доказана возможность самообучения нейронной сети без учителя, причем параметры этой сети (в частности, число слоев и межсоединений) приблизительно соответствуют биологическим значениям.
Предлагаю новое экспериментальное подтверждение этого факта, опубликованное concretely нашим любимым Andrew Ng.
Авторы провели широкомасштабный эксперимент по построению детектора человеческих лиц на основании огромного количества изображений, не маркированных никаким образом. Была построена 9-слойная нейронная сеть со структурой разреженного автоэнкодера с локальными рецептивными полями. Нейронная сеть реализована на кластере из 1000 компьютеров, по 16 ядер в каждом, и содержит 1 миллиард связей между нейронами. Для обучения сети использовали 10 миллионов кадров 200х200 пикселов, случайным образом полученных из роликов YouTube. Обучение методом асинхронного градиентного спуска заняло 3 дня.
В результате обучения на немаркированной выборке, без учителя, вопреки интуиции, в выходном слое сети был выделен нейрон, селективно реагирующий на присутствие лица на изображении. Контрольные эксперименты показали, что этот классификатор устойчив не только к смещению лица на поле изображения, но и к масштабированию и даже к 3D-вращению вне плоскости изображения! Оказалось, что эта нейронная сеть способна обучаться распознаванию разнообразных высокоуровневых понятий, например человеческих фигур или кошек.
Полный текст статьи см. по ссылке, здесь же я привожу краткий пересказ.
Концепция
В нейробиологии считается, что в мозге можно выделить отдельные нейроны, селективные к определенным обобщенным категориям, таким как человеческие лица. Их еще называют «бабушкины нейроны».
В искусственных нейронных сетях стандартным подходом является обучение с учителем: например, для построения классификатора человеческих лиц берется набор изображение лиц, а также набор изображений, не содержащих лиц, причем каждое изображение промаркировано «лицо» — «не лицо». Необходимость получения больших маркированных коллекций обучающих данных является большой технической проблемой.
В данной работе авторы попытались ответить на два вопроса: можно ли обучить нейронную сеть распознаванию лиц из НЕмаркированных данных, и можно ли экспериментально подтвердить возможность самообучения «бабушкиных нейронов» на немаркированных данных. Это в принципе подтвердит гипотезу о том, что младенцы самостоятельно обучаются группировать похожие изображения (например, лиц) без вмешательства учителя.
Обучающие данные
Обучающий набор составили путем случайной выборки по одному кадру из 10 млн. роликов YouTube. Из каждого ролика брали только один кадр, чтобы избежать дубликатов в выборке. Каждй кадр масштабировали до размера 200х200 пискелов (что отличает описываемый эксперимент от большинства работ по распознаванию, оперирующих обычно фреймами 32х32 или т.п.) Вот типичные изображения из обучающей выборки:
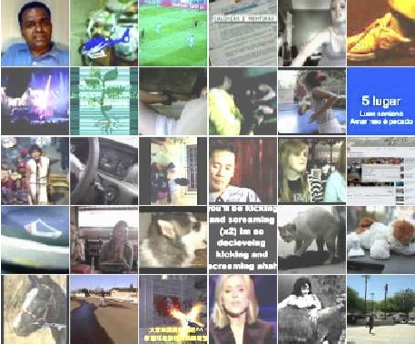
Алгоритм
Основой для эксперимента послужил разреженный автоэнкодер (описанный на хабре). Ранние эксперименты с автоэнкодерами, имеющими малую глубину, позволили получить классификаторы низкоуровневых признаков (отрезки, границы и т.п.) аналогичные фильтрам Габора.
Описываемый алгоритм использует многослойный автоэнкодер, а также некоторые важные отличительные особенности:
- локальные рецептивные поля
- объединение фреймов (pooling)
- локальная нормализация контрастов.
Локальные рецептивные поля позволяют масштабировать нейронную сеть для крупных изображений. Объединение фреймов (pooling) и локальная нормализация контрастов позволяет добиться инвариантности к перемещению и локальным деформациям.
Используемый автоэнкодер состоит из трех повторяющихся слоев, в каждом из которых используются одинаковые подуровни: локальной фильтрации, локального объединения (pooling), локальной нормализации контрастов.
Важнейшей особенностью данной структуры является локальная связность между нейронами. Первый подуровень использует рецептивные поля 18х18 пикселов, а второй подуровень объединяет фреймы по 5х5 пересекающихся соседних областей. Обратите внимание, что локальные рецептивные поля не используют конволюции, т.е. параметры каждого рецетивного поля не повторяются, они уникальны. Этот подход боолее приближен к биологическому прототипу, а также позволяет обучиться большему количеству инвариантов.
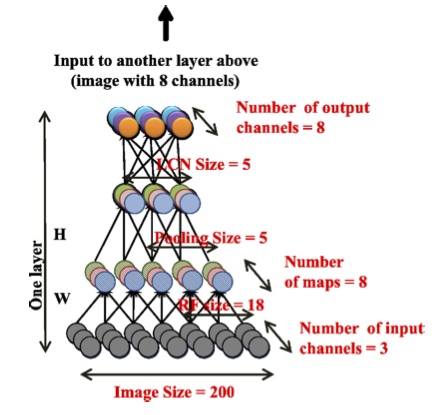
Локальная нормализация контраста также имитирует процессы в биологическом зрительном тракте. Из активации каждого нейрона вычитают взвешенное среднее значение активаций соседних нейронов (весовые коэффициенты по Гауссу). Затем производится нормализация по локальному среднеквадратичному значению активаций соседних нейронов, также взвешенных по Гауссу.
Целевая функция при обучении сети минимизирует значение погрешности воспроизведения исходного изображения разреженным автоэнкодером. Оптимизация производится глобально для всех управляемых параметров сети (свыше 1 миллиарда параметров) методом асинхронного градиентного спуска (asynchronous SGD). Для решения столь масштабной задачи был реализован паралеллизм модели, заключающийся в том, что локальные веса нейронной сети распределяются на различные машины. Один экземпляр модели распределяется на 169 компьютеров, по 16 процессорных ядер в каждом.
Для дальнейшего распараллеливания процесса обучения реализован асинхронный градиентный спуск с использованием нескольких экземпляров модели. В описываемом эксперименте обучающую выборку разделили на 5 порций, и проводили обучение каждой порции на отдельном экземпляре модели. Модели передают обновленные значения параметров на централизованные «серверы параметров» (256 серверов). В упрощенном изложении, перед обработкой мини-серии из 100 обучающих изображений, модель запрашивает параметры у серверы параметров, обучается (обновляет параметры) и передает градиенты параметров на серверы параметров.
Такой асинхронный градиентный спуск обладает устойчивостью к сбоям отдельных узлов сети.
Для проведения данного эксперимента был разработан фреймворк DistBelief, который решает все вопросы коммуникаций между параллельными компьютерами в кластере, включая диспетчиризацию запросов к серверам параметров. Процесс обучения длился 3 дня.
Результаты эксперимента
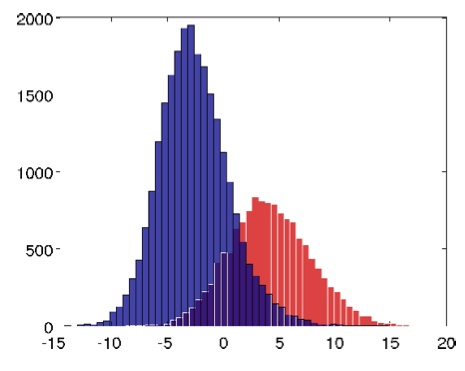
Удивительно, но в процессе обучения сформировались нейроны, лучший из которых показал точность в распознавании лиц 81.7%. Гистограмма уровней активации (относительно порогового значения Ноль) показывает, какое количество изображений в тестовой выборке вызывало ту или иную активацию «бабушкиного нейрона». Синим цветом показаны изображения, не содержащие лиц (случайные изображения), красным цветом — содержащие лица.
Для того, чтобы подтвердить, что классификатор обучен именно распознаванию лиц, провели визуализацию обученной сети двумя методами.
Первый метод — отбор тестовых изображений, вызвавших наибольшую активацию нейрона-классификатора:

Второй подход — численная оптимизация для получения оптимального стимула. Методом градиентного спуска был получен входной паттерн, который максимизирует значение выходной активации классификатора при заданных параметрах нейронной сети:

Более подробно количественные оценки и выводы о результатах эксперимента см. в оригинале статьи. От себя хочу заметить, что масштабным вычислительным экспериментом была доказана возможность самообучения нейронной сети без учителя, причем параметры этой сети (в частности, число слоев и межсоединений) приблизительно соответствуют биологическим значениям.







