Совсем недавно, перейдя на новый проект, я решил для разнообразия также перейти с Eclipse на Idea. С идеей у меня уже был опыт еще с 6-й версии, она мне нравилась, но проблем у нее было достаточно много. Тогда я отказался от нее в виду периодических глюков при долгой работе. Увидев, что уже на дворе 11-я версия я обрадовался и решил опять попытать счастья, так как по интерфейсу идея для меня гораздо приятней…
Около месяца назад заметил, что при активной разработке, когда выделенные под кучу 768мб памяти заполнены под 80%, любое действие, вроде движения мышкой, переключения фокуса, просто прокрутка колесом мышки или непосредственно скроллом в окне вызывает большое потребление памяти и оставшиеся 20% памяти съедаются за несколько секунд работы. После чего, естественно, про комфортную работу можно забыть и приходится перегружать среду в виду постоянного срабатывания сборщика. Сегодня эта ситуация меня окончательно достала и я решил узнать — в чем же собственно проблема?
Интуитивно я понимал, что вероятней всего каждое движение мышки и любое действие вроде прокрутки генерирует определенные события, которые потом обрабатываются, но ТАК МНОГО этих событий я не ожидал. Для затравки — 2 скриншота потребления памяти при движении мыши в окне редактора и скроллинге внутри открытого класса на 1000 строк:
Движение: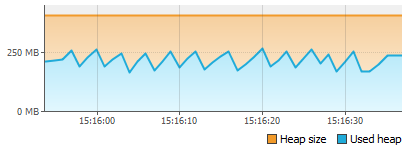
Скроллинг: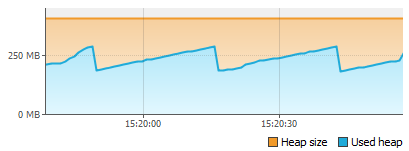
Обычная прокрутка в окне редактирования кода в пике съедает почти 100мб памяти за несколько секунд… Любое движение мыши генерирует объектов на десятки мегабайт… Единственный позитивный момент во всем этом, что все эти объекты потом собираются.
Естественно, мне стало интересно, что же такого генерирует идея при таких простых действиях. Итак, повторим эксперимент:

1.5 млн объектов за прокрутку несколько дороговато, не находите? Зато теперь более менее стало понятно, где таится проблема. Это некий класс IntervalTreeImpl и его внутренний класс NodeCachedOffsets. Теперь у нас есть целых 2 пути для исследования: 1) скачать исходники IntervalTreeImpl и посмотреть и где и как создается NodeCachedOffsets и почему их так много (кстати, большое спасибо разработчикам за открытые исходные коды); 2) Проанализировать стек вызовов при прокрутке.
Я пошел сначала первым путем, а потом имея представление о том, что происходит, проанализировал стек вызовов, чтобы окончательно убедится в верности выводов… Итак, кому интересно — исходник Вы можете найти тут. Попробуйте сами разобраться просмотрев код, где же таится проблема.
Проанализировав код, становится более-менее понятно чего же ожидать от стека вызовов, вот собственно его самая интересная часть:

и
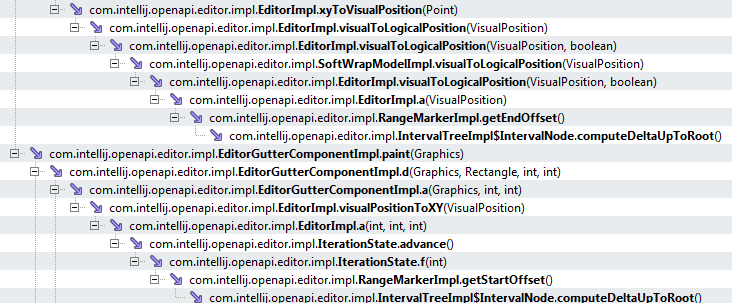
Обратите внимание на метод computeDeltaUpToRoot() он находится в самом конце стека и кроме этого вызывается довольно часто и в разных разветвлениях стека. Вообщем, имея код, ошибка на лицо — этот метод вызывается очень часто и во многих местах и при этом он постоянно генерирует новые объекты проблемного NodeCachedOffsets класса. Очевидно, что для решения проблемы нужно всего лишь избавится от постоянного создания этих объектов и заменить их, например, просто большим примитивом (как вариант) или изменить сам подход к отрисовке окна редактирования (требует много рефакторинга).
В целом тут я хотел красиво решить проблему и продемонстрировать ее решение, но… Каково же было мое удивление, когда скачав последние исходники с целью исправления проблемы (git://git.jetbrains.org/idea/community.git), обнаружил, что эта ошибка уже исправлена, да еще и 5 месяцев назад… Сам фикс можно просмотреть тут. Странно, что в последней версии идеи (11.1.2) этого фикса все еще нет. Хотелось бы получить его поскорее… Тем не менее довольно приятно, что ребята заботятся о продукте.
Около месяца назад заметил, что при активной разработке, когда выделенные под кучу 768мб памяти заполнены под 80%, любое действие, вроде движения мышкой, переключения фокуса, просто прокрутка колесом мышки или непосредственно скроллом в окне вызывает большое потребление памяти и оставшиеся 20% памяти съедаются за несколько секунд работы. После чего, естественно, про комфортную работу можно забыть и приходится перегружать среду в виду постоянного срабатывания сборщика. Сегодня эта ситуация меня окончательно достала и я решил узнать — в чем же собственно проблема?
Интуитивно я понимал, что вероятней всего каждое движение мышки и любое действие вроде прокрутки генерирует определенные события, которые потом обрабатываются, но ТАК МНОГО этих событий я не ожидал. Для затравки — 2 скриншота потребления памяти при движении мыши в окне редактора и скроллинге внутри открытого класса на 1000 строк:
Движение:
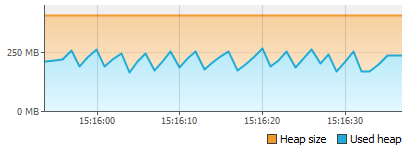
Скроллинг:
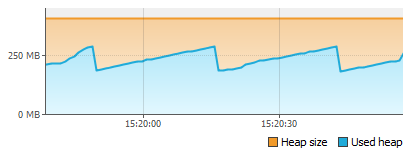
Обычная прокрутка в окне редактирования кода в пике съедает почти 100мб памяти за несколько секунд… Любое движение мыши генерирует объектов на десятки мегабайт… Единственный позитивный момент во всем этом, что все эти объекты потом собираются.
Естественно, мне стало интересно, что же такого генерирует идея при таких простых действиях. Итак, повторим эксперимент:

1.5 млн объектов за прокрутку несколько дороговато, не находите? Зато теперь более менее стало понятно, где таится проблема. Это некий класс IntervalTreeImpl и его внутренний класс NodeCachedOffsets. Теперь у нас есть целых 2 пути для исследования: 1) скачать исходники IntervalTreeImpl и посмотреть и где и как создается NodeCachedOffsets и почему их так много (кстати, большое спасибо разработчикам за открытые исходные коды); 2) Проанализировать стек вызовов при прокрутке.
Я пошел сначала первым путем, а потом имея представление о том, что происходит, проанализировал стек вызовов, чтобы окончательно убедится в верности выводов… Итак, кому интересно — исходник Вы можете найти тут. Попробуйте сами разобраться просмотрев код, где же таится проблема.
Проанализировав код, становится более-менее понятно чего же ожидать от стека вызовов, вот собственно его самая интересная часть:
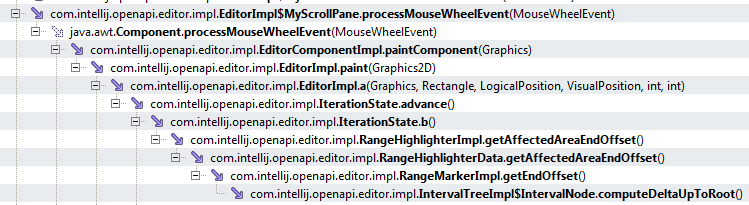
и
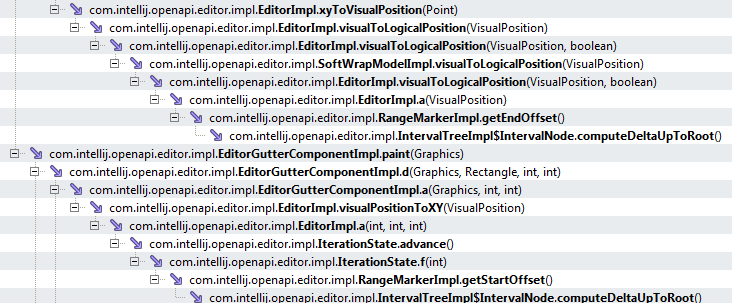
Обратите внимание на метод computeDeltaUpToRoot() он находится в самом конце стека и кроме этого вызывается довольно часто и в разных разветвлениях стека. Вообщем, имея код, ошибка на лицо — этот метод вызывается очень часто и во многих местах и при этом он постоянно генерирует новые объекты проблемного NodeCachedOffsets класса. Очевидно, что для решения проблемы нужно всего лишь избавится от постоянного создания этих объектов и заменить их, например, просто большим примитивом (как вариант) или изменить сам подход к отрисовке окна редактирования (требует много рефакторинга).
В целом тут я хотел красиво решить проблему и продемонстрировать ее решение, но… Каково же было мое удивление, когда скачав последние исходники с целью исправления проблемы (git://git.jetbrains.org/idea/community.git), обнаружил, что эта ошибка уже исправлена, да еще и 5 месяцев назад… Сам фикс можно просмотреть тут. Странно, что в последней версии идеи (11.1.2) этого фикса все еще нет. Хотелось бы получить его поскорее… Тем не менее довольно приятно, что ребята заботятся о продукте.







