Последние несколько месяцев анализаторы надежности паролей попадаются мне чуть ли не в каждой форме регистрации в Интернете. В этой области сегодня наблюдается особенно бурный рост.

Вопрос только в том, действительно ли такая программа помогает защитить учетную запись пользователя? Этот аспект интернет-безопасности, конечно, не настолько важен, как некоторые другие, например:
Если учесть указанные выше факторы, то да, я уверен, что программы, тестирующие безопасность паролей, действительно очень перспективны и могут помочь пользователю. В своей книге, изданной в 2006 году под названием «Идеальные пароли: выбор, защита, аутентификация» (Perfect Passwords: Selection, Protection, Authentication), Марк Бернетт (Mark Burnett), подсчитал частоту употребления нескольких миллионов паролей, раскрытых в результате различных утечек данных. Он пишет, что каждый девятый пользователь выбирал пароль из этого списка самых популярных. Среди них такие «крепкие орешки», как: password1, compaq, 7777777, merlin и rosebud. В прошлом году Бернетт провел новое исследование, изучив 6 миллионов паролей, и на этот раз выяснилось, что 99,8% из них входят в список 10 000 самых популярных, а 91% — в список 1000 самых употребительных. Конечно, на результат во многом влияли методология исследования и смещение выборки — например, поскольку большая часть этих паролей была получена из уже взломанных хешей, весь список изначально смещен в сторону легко взламываемых паролей.
Здесь указаны только легко угадываемые пароли, но держу пари, что большой процент остальных все равно достаточно предсказуем и может быть взломан в результате небольшой сетевой атаки. Поэтому я считаю, что благодаря прямому взаимодействию с пользователями такие анализаторы могут действительно помочь в выборе более надежного пароля. Однако на данный момент они, в большинстве своем, только вредят (не считая нескольких программ с закрытым кодом). Вот почему это происходит.
Надежность пароля лучше всего измерять величиной энтропии, выраженной в битах. Энтропия рассчитывается как число вариантов разделения надвое множества возможных паролей. Вот простейший алгоритм оценки надежности пароля:
Такой анализ методом прямого подбора применим к паролям, состоящим из случайных последовательностей букв, цифр и символов. Однако в большинстве случаев и лишь за редким исключением (за что отдельное спасибо 1Password / KeePass), люди выбирают в качестве пароля упорядоченные комбинации символов — словарные слова, простые клавиатурные последовательности, например qwerty, asdf и zxcvbn, повторы (aaaaaaa), последовательности (например, abcdef или 654321), а также сочетания вышеперечисленных элементов. Если пароль содержит буквы верхнего регистра, то такой буквой, скорее всего, будет первая буква пароля. Использование цифр и специальных символов также зачастую предсказуемо, в частности благодаря использованию сетевого жаргона l33t (цифра 3 заменяет букву e, 0 — o, @ или 4 — a), указанию годов, дат, почтовых индексов и т. д.
В результате упрощенные методы анализа надежности пароля оказываются недостоверными. Без проверки использования общеупотребительных комбинаций рекомендация использовать в пароле цифры и символы ненамного усложнит взлом, зато значительно усложнит запоминание. Один из комиксов на сайте xkcd отлично описывает эту ситуацию:
 >
>
Поэтому я и решил в качестве независимого проекта для очередной «Недели взломщика», проводимой Dropbox, создать анализатор надежности паролей с открытым кодом, который отсеивал бы простые комбинации и, соответственно, не запрещал бы достаточно сложные фразы-пароли типа correcthorsebatterystaple (вернолошадьбатареяскобка). Сейчас эта утилита размещена на dropbox.com/register и доступна для использования на github. Вы можете самостоятельно поэкспериментировать с демо-версией и оценить несколько паролей.
В приведенной ниже таблице zxcvbn сравнивается с другими анализаторами надежности паролей. Смысл сравнения не в том, чтобы доказать несостоятельность остальных приложений — ведь у каждого сайта своя политика в отношении паролей — а в том, чтобы дать вам лучшее представление об особенностях zxcvbn.
Несколько примечаний:
Система zxcvbn не ограничена типом браузера и работает с Internet Explorer (начиная с версии 7)/ Opera / FireFox / Safari / Google Chrome. Самый простой способ добавить ее на свою страницу регистрации — следующий:
Размер скрипта zxcvbn-async.js — всего лишь 350 байт. После выполнения window.load, когда страница загрузится и отобразится, начнется загрузка zxcvbn.js — «тяжелого» файла в 680 Кбайт (или 320 Кбайт в gzip), большую часть которого составляет словарь. Я ни разу не видел, чтобы размер скрипта создавал какие-либо проблемы: поскольку перед выбором пароля пользователь обычно вводит в форму регистрации другие данные, времени для загрузки скрипта предостаточно. Вот полное описание асинхронной загрузки скрипта в разных браузерах.
Zxcvbn добавляет в глобальное пространство имен одну функцию:
Она принимает один обязательный аргумент (пароль) и возвращает результирующий объект со следующими свойствами:
Необязательный аргумент user_inputs представляет собой массив строк, которые zxcvbn добавит в свой встроенный словарь. Теоретически он может включать любые строки, однако предполагается, что это будут данные, введенные пользователем в другие поля формы (например имя или адрес электронной почты). Таким образом, надежность пароля, содержащего персональные данные пользователя, может быть оценена очень низко. Удобен этот список и для учета специального словаря конкретного сайта (например, в моей программе учтен специфический словарь сайта Dropbox).
Программа zxcvbn написана на CoffeeScript. Файлы zxcvbn.js и zxcvbn-async.js обработаны преобразователем closure, но если вы хотите усовершенствовать zxcvbn, отправьте мне pull-запрос, файл README содержит информацию об установке среды разработки.
Далее по тексту я подробно описываю принцип работы zxcvbn.
Zxcvbn работает в три этапа: match (сверка), score (расчет), search (поиск).
Функция search является краеугольным камнем модели. Я начну с нее и вернусь к началу.
Zxcvbn рассчитывает степень энтропии пароля как сумму энтропий его составных частей. Любые части пароля, находящиеся между идентифицированными комбинациями, считаются последовательностями, угадываемыми перебором, также имеющими собственную энтропию. Вот пример энтропии, состоящей из энтропии фамилии, энтропии перебора и энтропии клавиатуры:
Здесь мы делаем серьезное допущение, что энтропия пароля является суммой энтропий его частей. Однако это допущение весьма консервативно. Не принимая в расчет «энтропию конфигурации» — т. е. энтропию числа и расположения частей пароля — zxcvbn намеренно недооценивает общую энтропию, не приписывая структуре пароля никакой ценности: программа предполагает, что взломщику структура пароля уже известна (например, «фамилия-подбираемая комбинация-цифры»), и рассчитывает только число попыток угадать элементы пароля. Таким образом, энтропия паролей со сложной структурой сильно недооценивается. Взламывая пароль correcthorsebatterystaple (слово-слово-слово-слово), взломщик при помощи таких программ, как L0phtCrack или John the Ripper, как правило, сначала переберет множество более простых структур (слово, слово-цифра, слово-слово), пока дойдет до слово-слово-слово-слово. Однако есть три причины, по которым этот недостаток программы меня не беспокоит:
Разобравшись с этим допущением, давайте рассмотрим эффективный динамический алгоритм на CoffeeScript, позволяющий найти минимальную непересекающуюся последовательность соответствий. Время его работы — O (n•m) для пароля длины n, включающего m возможных совпадений символьных комбинаций (включая пересекающиеся).
Массив backpointers[j] хранит совпадение с последовательностью, заканчивающейся на позиции пароля j или пустое значение (null), если в последовательности нет такого совпадения. При динамическом программировании построение оптимальной последовательности принято начинать с конца и двигаться в обратном направлении.
Производительность особенно важна для этого скрипта потому, что он работает в браузере в процессе ввода пароля. Чтобы обеспечить работу программы, я начинал с простого подхода O(2m) к вычислению сумм для всех возможных непересекающихся подмножеств, и процесс очень быстро замедлялся с усложнением задачи. Теперь же на полный анализ большинства паролей у zxcvbn уходит не больше нескольких миллисекунд. По самой грубой оценке, в Google Chrome на 2,4 ГГц Intel Xeon, пароль correcthorsebatterystaple в среднем анализируется примерно за 3 мсек. На пароль coRrecth0rseba++ery9/23/2007staple$ в среднем уходит около 12 мсек.
Понятие энтропии не слишком прозрачный показатель. Как понять, достаточно ли надежен пароль на 28 бит? Иными словами, как перейти от оценки энтропии непосредственно ко времени взлома? Для этого применяется модель угрозы. Предположим, что:
Некоторые ориентировочные цифры:
Здесь я ввел коэффициент 0,5, поскольку мы вычисляем среднее время взлома, а не время перебора всего пространства поиска.
Возможно, эти вычисления слишком консервативны. Крупномасштабная кража хешей случается довольно редко, и, если только атака не направлена прямо на вас, взломщик вряд ли отведет 100 ядер на один ваш пароль. Обычно взломщику приходится гадать в режиме онлайн, где ему досаждают сетевая задержка, нарастающая задержка и CAPTCHA.
Теперь рассмотрим, как zxcvbn рассчитывает энтропию каждой комбинации символов в пароле. Точка входа — calc_entropy(). Это простой выбор:
Выше я в общих чертах объяснил, как работает функция repeat_entropy. С полным текстом кода расчета энтропии можно самостоятельно ознакомиться на github, но чтобы дать вам некоторое представление о нем, я опишу две другие расчетные функции: spatial_entropy (энтропия клавиатурных комбинаций) и dictionary_entropy (словарная энтропия).
Рассмотрим клавиатурную комбинацию qwertyhnm. Она начинается с символа q, ее длина — 9 символов, и у нее есть три направления движения: сначала движение направо, затем вниз и направо, затем снова вниз и направо. Параметризируем данную комбинацию:
Тогда общее пространство возможностей включает все возможные клавиатурные комбинации длины L или менее, имеющие t или менее смен направления:

Функция «биноминальный коэффициент из (i – 1) по (j – 1)» подсчитывает возможные конфигурации смены направлений для клавиатурной комбинации длины i, имеющей j смен направления. К обоим элементам добавляется «-1», поскольку первая смена направления всегда происходит на первой букве. При каждом из j смен направлений существует d возможных направлений, т. е. всего dj возможностей на каждую конфигурацию. Взломщик также должен перебрать все начальные символы, отсюда коэффициент s в формуле. Сама формула весьма приблизительна — в частности потому, что многие варианты, учтенные в ней, на реальной клавиатуре невозможны: для клавиатурной комбинации длины 5 с 1 сменой направления операция «начать с “q” и двигаться влево» учтена, но невозможна.
Это выражение на CoffeeScript можно записать так:
Переходим к словарной энтропии:
Самая важная строка — первая: к каждому совпадению привязан свой ранг частоты употребления: такие слова, как the и good имеют низкий ранг, а слова типа photojournalist и maelstrom — высокий. Это позволяет zxcvbn на ходу масштабировать вычисления в соответствии с размером словаря, поскольку, если в пароле используются только распространенные слова, его можно взломать с применением меньшего словаря. Это одна из причин, по которым энтропия пароля correcthorsebatterystaple немного разнится по версиям xkcd и zxcvbn (45,2 бит и 44 бит соответственно). В xkcd использовался фиксированный словарь размером 211 (около 2000 слов), а zxcvbn адаптирует рабочий словарь к конкретной ситуации. Поэтому zxcvbn.js содержит полные словари, а не компактный фильтр Блума, и помимо проверки принадлежности комбинации к определенному массиву, необходимы сведения о ее ранге.
В конце данной статьи, в разделе «Данные», я поясню, откуда берутся ранги по частоте. Энтропия, связанная с использованием букв верхнего регистра, рассчитывается следующим образом:
Таким образом, получаем 1 дополнительный бит энтропии для схемы «первая заглавная» и других распространенных схем. Если же схема использования заглавных букв не относится к распространенным, она добавляет нам:

Вычисления по замещающим символам l33t аналогичны, но тогда вместо переменных для заглавных и строчных букв используются переменные для замененных и незамененных символов.
Выше я рассказал вам о методах вычисления энтропии комбинаций, но еще не объяснил, как zxcvbn находит сами комбинации. Сверка со списком слов в словаре — довольно простая процедура: каждая подстрока пароля проверяется на наличие ее аналога в словаре:
Ranked_dict определяет частоту употребления слова. Это похоже на массив слов, но только отсортированный сверху вниз по частоте употребления, при этом частота и значение меняются местами. Замены l33t определяются отдельной функцией, использующей в качестве примитива dictionary_match. Клавиатурные последовательности (например, bvcxz) определяются при помощи смежностных графов, с подсчетом смен направления и сдвигов. Даты и года определяются при помощи регулярных выражений. В разделе matching.coffee на github можно узнать о механизме сверки со словарем подробнее.
Как уже говорилось ранее, список 10 000 самых распространенных паролей взят из статьи Бернетта, опубликованной в 2011 году.
Частотный словарь имен и фамилий был составлен на основе данных переписи населения США 2000 года, находящихся в свободном доступе. Чтобы программа zxcvbn не приводила к сбоям в работе Internet Explorer 7, я обрезал длинный словарь фамилий на 80 % (т. е. 80 % американцев носят фамилии, встречающиеся в этом списке), а словарь имен — на 90 %.
Словарь 40 000 самых распространенных слов в английском языке был взят из материалов одного проекта на Wiktionary, составленных на основе около 29 млн. слов из телевизионных программ и фильмов, демонстрируемых в США. Расчет был на то, что все списки, которые я нашел в Интернете, и все слова из телевизионных и киносценариев будут наиболее употребительными (следовательно, будут часто встречаться в паролях), а потому представляют собой лучшие источники — однако это лишь непроверенная гипотеза. Списки с момента составления немного устарели, например, Frasier стоит на 824-м месте по частоте употребления.
На первый взгляд может показаться, что создать хорошую программу для оценки надежности паролей почти так же сложно, как и хорошую программу для их взлома. По определению это так, если ваша цель — точность, ведь «идеальная энтропия» в соответствии с идеальной моделью измеряется именно количеством вариантов, которые нужно перебрать программе взлома (используемой смышленым взломщиком) для подбора пароля. Но в данном случае цель программы заключается не в точности, а в том, чтобы дать пользователю хороший совет при выборе пароля. И это даже упрощает задачу: например, я могу позволить себе недооценить степень энтропии пароля, и единственным недостатком этого будет отбор программой более надежных паролей, чем нужно (что может раздражать пользователя, но не создаст для него опасности).
Точная оценка надежности пароля остается нелегкой задачей, в основном ввиду существования огромного количества возможных комбинаций. Zxcvbn не распознает слова, если из них убрать первую букву или гласные или написать их с ошибками; не распознает n-граммы; почтовые индексы крупных населенных пунктов; разорванные клавиатурные последовательности (например, qzwxec) и многое другое. Неочевидные комбинации (например, числа Каталана) распознавать не столь важно, однако каждая общеупотребимая комбинация, не распознанная zxcvbn, но известная взломщику, приводит к завышению оценки энтропии пароля — и это самой большой дефект программы. Возможные пути его устранения:
Тем не менее, я считаю, что даже с учетом этих недостатков, zxcvbn дает пользователям весьма дельные советы по выбору надежного пароля в мире, где слишком часто выбираются неудачные пароли. Надеюсь, эта программа окажется полезной и для вас. «Форкните» ее на github и развлекайтесь!
Большое спасибо Крису Варенхорсту, Гаутаму Джайраману, Бену Дарнеллу, Алисии Чен, Тодду Айзенбергеру, Каннану Гундану, Крису Бекманну, Райану Хантеру, Брайану Смиту, Мартину Бейкеру, Ивану Киригину, Джулии Танг, Тидо Великому, Рэмзи Хомсэни, Барту Волькмеру и Саре Нийоги за рецензирование данной статьи.
Перевод выполнен ABBYY Language Services
p.s. В комментариях принимаются идеи на тему «где брать материалы для перевода», «материалы какой тематики интересуют хабрапользователей» и даже конкретные ссылки — претенденты на перевод.

Вопрос только в том, действительно ли такая программа помогает защитить учетную запись пользователя? Этот аспект интернет-безопасности, конечно, не настолько важен, как некоторые другие, например:
- предотвращение взлома веб-страниц за счёт нарастающей задержки или использования CAPTCHA;
- предотвращение офлайн-взлома путем применения достаточно медленной хеш-функции с индивидуализированной на уровне пользователя «солью»;
- защита хешей паролей.
Если учесть указанные выше факторы, то да, я уверен, что программы, тестирующие безопасность паролей, действительно очень перспективны и могут помочь пользователю. В своей книге, изданной в 2006 году под названием «Идеальные пароли: выбор, защита, аутентификация» (Perfect Passwords: Selection, Protection, Authentication), Марк Бернетт (Mark Burnett), подсчитал частоту употребления нескольких миллионов паролей, раскрытых в результате различных утечек данных. Он пишет, что каждый девятый пользователь выбирал пароль из этого списка самых популярных. Среди них такие «крепкие орешки», как: password1, compaq, 7777777, merlin и rosebud. В прошлом году Бернетт провел новое исследование, изучив 6 миллионов паролей, и на этот раз выяснилось, что 99,8% из них входят в список 10 000 самых популярных, а 91% — в список 1000 самых употребительных. Конечно, на результат во многом влияли методология исследования и смещение выборки — например, поскольку большая часть этих паролей была получена из уже взломанных хешей, весь список изначально смещен в сторону легко взламываемых паролей.
Здесь указаны только легко угадываемые пароли, но держу пари, что большой процент остальных все равно достаточно предсказуем и может быть взломан в результате небольшой сетевой атаки. Поэтому я считаю, что благодаря прямому взаимодействию с пользователями такие анализаторы могут действительно помочь в выборе более надежного пароля. Однако на данный момент они, в большинстве своем, только вредят (не считая нескольких программ с закрытым кодом). Вот почему это происходит.
Надежность пароля лучше всего измерять величиной энтропии, выраженной в битах. Энтропия рассчитывается как число вариантов разделения надвое множества возможных паролей. Вот простейший алгоритм оценки надежности пароля:
# n: длина пароля
# c: мощность пароля: размер символьного пространства
# (26 для пароля, содержащего только буквы нижнего регистра, 62 — для пароля, содержащего буквы верхнего и нижнего регистров, а также цифры)
Энтропия = n * lg(c) # логарифм по основанию 2
Такой анализ методом прямого подбора применим к паролям, состоящим из случайных последовательностей букв, цифр и символов. Однако в большинстве случаев и лишь за редким исключением (за что отдельное спасибо 1Password / KeePass), люди выбирают в качестве пароля упорядоченные комбинации символов — словарные слова, простые клавиатурные последовательности, например qwerty, asdf и zxcvbn, повторы (aaaaaaa), последовательности (например, abcdef или 654321), а также сочетания вышеперечисленных элементов. Если пароль содержит буквы верхнего регистра, то такой буквой, скорее всего, будет первая буква пароля. Использование цифр и специальных символов также зачастую предсказуемо, в частности благодаря использованию сетевого жаргона l33t (цифра 3 заменяет букву e, 0 — o, @ или 4 — a), указанию годов, дат, почтовых индексов и т. д.
В результате упрощенные методы анализа надежности пароля оказываются недостоверными. Без проверки использования общеупотребительных комбинаций рекомендация использовать в пароле цифры и символы ненамного усложнит взлом, зато значительно усложнит запоминание. Один из комиксов на сайте xkcd отлично описывает эту ситуацию:
>Поэтому я и решил в качестве независимого проекта для очередной «Недели взломщика», проводимой Dropbox, создать анализатор надежности паролей с открытым кодом, который отсеивал бы простые комбинации и, соответственно, не запрещал бы достаточно сложные фразы-пароли типа correcthorsebatterystaple (вернолошадьбатареяскобка). Сейчас эта утилита размещена на dropbox.com/register и доступна для использования на github. Вы можете самостоятельно поэкспериментировать с демо-версией и оценить несколько паролей.
В приведенной ниже таблице zxcvbn сравнивается с другими анализаторами надежности паролей. Смысл сравнения не в том, чтобы доказать несостоятельность остальных приложений — ведь у каждого сайта своя политика в отношении паролей — а в том, чтобы дать вам лучшее представление об особенностях zxcvbn.
qwER43@! |
Tr0ub4dour&3 |
correcthorsebatterystaple |
|
|---|---|---|---|
| zxcvbn |  |
 |
 |
| Dropbox (старый) | |
|
|
| Citibank | 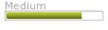 |
 |
 |
| Bank of America | Недопустимый | Недопустимый | Недопустимый |
 |
|
|
|
| PayPal |  |
 |
|
| eBay |  |
|
Недопустимый |
 |
|
 |
|
| Yahoo! |  |
|
 |
| Gmail |  |
|
 |
Несколько примечаний:
- Эти скриншоты я сделал 3 апреля 2012 года.
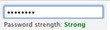
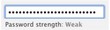
- Zxcvbn считает correcthorsebatterystaple самым надежным паролем из трех. Остальные приложения либо считают его самым неэффективным, либо вовсе не разрешают его использовать. (Twitter присвоил трем паролям примерно одинаковую степень надежности, но если приглядеться, можно заметить небольшую разницу.)
- Zxcvbn считает qwER43@! неэффективным паролем, поскольку он представляет собой зашифрованную клавиатурную последовательность QWERTY. За каждую смену направления и сдвиг символа он увеличивает ей энтропию.
- Анализатор паролей PayPal посчитал qwER43@! неэффективным паролем, но aaAA11!!! — надежным. Можно предположить, что он распознает клавиатурные последовательности.
- В форме регистрации Bank of America не разрешается использование паролей длиннее 20 символов, в том числе correcthorsebatterystaple. По их правилам в паролях могут использоваться некоторые специальные символы, но «&» и «!» не разрешены, соответственно, запрещено использование двух оставшихся паролей. eBay также не допускает использование паролей длиной более 20 символов.
- Похоже, что за редким исключением протестированные программы не руководствуются теми же примитивными критериями, что и я, иначе correcthorsebatterystaple получил бы самый высокий рейтинг благодаря своей длине. Прежняя версия анализатора паролей Dropbox добавляла паролю баллы за каждую использованную один раз строчную букву, заглавную букву, цифру и специальный символ до определенного предела для каждой из этих групп символов. Такой подход защищает только от атак методом полного перебора, хотя в эту систему заложена опция проверки нового пароля по словарю наиболее употребительных слов. Принципов работы остальных протестированных программ я не знаю, но известно, что разработчики часто применяют вот такие таблицы критериев надежности (которые, однако, проверяют пароль по небольшому набору комбинаций).
- За базовое слово пароля во второй колонке я взял Troubadour, а не Troubador, как в xkcd (последнее написание встречается редко).
Установка
Система zxcvbn не ограничена типом браузера и работает с Internet Explorer (начиная с версии 7)/ Opera / FireFox / Safari / Google Chrome. Самый простой способ добавить ее на свою страницу регистрации — следующий:
<script src="zxcvbn-async.js" type="text/javascript">
</script>
Размер скрипта zxcvbn-async.js — всего лишь 350 байт. После выполнения window.load, когда страница загрузится и отобразится, начнется загрузка zxcvbn.js — «тяжелого» файла в 680 Кбайт (или 320 Кбайт в gzip), большую часть которого составляет словарь. Я ни разу не видел, чтобы размер скрипта создавал какие-либо проблемы: поскольку перед выбором пароля пользователь обычно вводит в форму регистрации другие данные, времени для загрузки скрипта предостаточно. Вот полное описание асинхронной загрузки скрипта в разных браузерах.
Zxcvbn добавляет в глобальное пространство имен одну функцию:
zxcvbn(password, user_inputs)
Она принимает один обязательный аргумент (пароль) и возвращает результирующий объект со следующими свойствами:
result.entropy # бит
result.crack_time # оценка фактического времени взлома (сек.)
result.crack_time_display # то же время взлома, в более удобном формате:
# «мгновенно», «6 минут», «века» и т. д.
result.score # рейтинг надежности, равный 0, 1, 2, 3 или 4,
# если время взлома меньше 10**2, 10**4, 10**6,
# 10**8 или бесконечности, соответственно.
# (полезно для графического представления надежности в виде линейчатой диаграммы)
result.match_sequence # выявленные комбинации символов, учтенные при
# подсчете энтропии
result.calculation_time # время расчета ответа (мс); обычно всего несколько мс
Необязательный аргумент user_inputs представляет собой массив строк, которые zxcvbn добавит в свой встроенный словарь. Теоретически он может включать любые строки, однако предполагается, что это будут данные, введенные пользователем в другие поля формы (например имя или адрес электронной почты). Таким образом, надежность пароля, содержащего персональные данные пользователя, может быть оценена очень низко. Удобен этот список и для учета специального словаря конкретного сайта (например, в моей программе учтен специфический словарь сайта Dropbox).
Программа zxcvbn написана на CoffeeScript. Файлы zxcvbn.js и zxcvbn-async.js обработаны преобразователем closure, но если вы хотите усовершенствовать zxcvbn, отправьте мне pull-запрос, файл README содержит информацию об установке среды разработки.
Далее по тексту я подробно описываю принцип работы zxcvbn.
Модель
Zxcvbn работает в три этапа: match (сверка), score (расчет), search (поиск).
- Функция match проводит сверку по всем известным ей комбинациям (включая пересекающиеся). На текущий момент zxcvbn поддерживает сверку с несколькими словарями (словарь английских слов, имен и фамилий, а также список 10 000 самых распространенных паролей Бернетта), последовательными клавиатурными комбинациями (QWERTY, Dvorak и цифровой), повторами (aaa), цифровыми и символьными последовательностями (123, gfedcba), годами в диапазоне от 1900 до 2019, а также датами (в форматах 3-13-1997, 13.3.1997, 1331997). Во всех словарях распознается верхний регистр и распространенные эквиваленты l33t.
- Функция score вычисляет степень энтропии для каждой совпавшей комбинации отдельно от оставшейся части пароля (предполагая, что взломщику известна эта комбинация). Простой пример — rrrrr. В данном случае взломщику нужно перебрать все варианты повторов от 1 до 5, начинающиеся со строчной буквы:
entropy = lg(26*5) # около 7 бит
- Функция search использует принцип «бритвы Оккама»; из полного множества возможно пересекающихся совпадений поиск выдает простейшую непересекающуюся последовательность (с минимальной энтропией). Например, если пароль — damnation, его можно разбить на 2 слова: dam и nation, либо рассматривать как одно. В данном случае важно рассматривать слово именно как единое целое, ведь перебирающий слова взломщик подберет пароль как одно слово гораздо быстрее, чем как два. Кстати, пересекающиеся комбинации также являются основной причиной появления таких непредумышленно фатальных доменных имен, как childrens-laughter.com, но без дефиса (прим. пер.: children’s laughter — детский смех, children slaughter — детоубийство).
Функция search является краеугольным камнем модели. Я начну с нее и вернусь к началу.
Поиск минимума энтропии
Zxcvbn рассчитывает степень энтропии пароля как сумму энтропий его составных частей. Любые части пароля, находящиеся между идентифицированными комбинациями, считаются последовательностями, угадываемыми перебором, также имеющими собственную энтропию. Вот пример энтропии, состоящей из энтропии фамилии, энтропии перебора и энтропии клавиатуры:
entropy("stockwell4$eR123698745") == surname_entropy("stockwell") +
bruteforce_entropy("4$eR") +
keypad_entropy("123698745")
Здесь мы делаем серьезное допущение, что энтропия пароля является суммой энтропий его частей. Однако это допущение весьма консервативно. Не принимая в расчет «энтропию конфигурации» — т. е. энтропию числа и расположения частей пароля — zxcvbn намеренно недооценивает общую энтропию, не приписывая структуре пароля никакой ценности: программа предполагает, что взломщику структура пароля уже известна (например, «фамилия-подбираемая комбинация-цифры»), и рассчитывает только число попыток угадать элементы пароля. Таким образом, энтропия паролей со сложной структурой сильно недооценивается. Взламывая пароль correcthorsebatterystaple (слово-слово-слово-слово), взломщик при помощи таких программ, как L0phtCrack или John the Ripper, как правило, сначала переберет множество более простых структур (слово, слово-цифра, слово-слово), пока дойдет до слово-слово-слово-слово. Однако есть три причины, по которым этот недостаток программы меня не беспокоит:
- Разработать хорошую модель структурной энтропии не так-то просто; я не располагаю статистическими данными о том, какие структуры используются пользователями чаще всего, так что для верности лучше занизить оценку энтропии пароля.
- При сложной структуре пароля сумма энтропий его частей зачастую уже обеспечивает ему отличный рейтинг сложности. Например, даже зная структуру слово-слово-слово-слово пароля correcthorsebatterystaple, взломщик будет взламывать этот пароль веками.
- Большинство людей не пользуется сложными структурами при создании паролей. А пренебрежение структурой, как правило, уменьшает общую энтропию всего на несколько бит.
Разобравшись с этим допущением, давайте рассмотрим эффективный динамический алгоритм на CoffeeScript, позволяющий найти минимальную непересекающуюся последовательность соответствий. Время его работы — O (n•m) для пароля длины n, включающего m возможных совпадений символьных комбинаций (включая пересекающиеся).
# совпадения: полный массив возможных совпадений, найденных для пароля
# у каждого совпадения есть начальный индекс (match.i) и конечный индекс
# (match.j) в составе пароля, включительно
minimum_entropy_match_sequence = (password, matches) ->
# например, 26 – для паролей, состоящих только из букв нижнего регистра
bruteforce_cardinality = calc_bruteforce_cardinality password
up_to_k = [] # минимальная энтропия до k, включительно
backpointers = [] # для оптимальной последовательности совпадений до k, включительно
# содержит последнее совпадение (match.j = k).
# ноль означает, что последовательность заканчивается символом подбора
for k in [0...password.length]
# лучший на данный момент начальный сценарий:
# добавление символа подбора к последовательности с минимальной энтропией
# с длиной k-1.
up_to_k[k] = (up_to_k[k-1] or 0) + lg bruteforce_cardinality
backpointers[k] = null
for match in matches when match.j = k
[i, j] = [match.i, match.j]
# проверяем, что минимальная энтропия до i-1 + энтропия данного
# совпадения меньше текущего минимума на j
candidate_entropy = (up_to_k[i-1] or 0) + calc_entropy(match)
if candidate_entropy < up_to_k[j]
up_to_k[j] = candidate_entropy
backpointers[j] = match
# двигаемся в обратном направлении, раскодируем лучшую последовательность
match_sequence = []
k = password.length – 1
while k >= 0
match = backpointers[k]
if match
match_sequence.push match
k = match.i – 1
else
k -= 1
match_sequence.reverse()
# заполняем «просветы» между совпавшими комбинациями фрагментами,
# угадываемыми подбором
# в результате последовательность совпадений покрывает весь пароль:
# совпадение1.j = совпадение2.i – 1 для каждого смежного совпадения1,
# совпадения2.
make_bruteforce_match = (i, j) ->
pattern: ‘bruteforce’
i: i
j: j
token: password[i..j]
entropy: lg Math.pow(bruteforce_cardinality, j – i + 1)
cardinality: bruteforce_cardinality
k = 0
match_sequence_copy = []
for match in match_sequence # заполняем пробелы между совпадениями
[i, j] = [match.i, match.j]
if i – k > 0
match_sequence_copy.push make_bruteforce_match(k, i – 1)
k = j + 1
match_sequence_copy.push match
if k < password.length # заполняем «просвет» в конце
match_sequence_copy.push make_bruteforce_match(k, password.length – 1)
match_sequence = match_sequence_copy
# или исключительный случай — при пустом пароле « »
min_entropy = up_to_k[password.length - 1] or 0
crack_time = entropy_to_crack_time min_entropy
# окончательный результирующий объект
password: password
entropy: round_to_x_digits min_entropy, 3
match_sequence: match_sequence
crack_time: round_to_x_digits crack_time, 3
crack_time_display: display_time crack_time
score: crack_time_to_score crack_time
Массив backpointers[j] хранит совпадение с последовательностью, заканчивающейся на позиции пароля j или пустое значение (null), если в последовательности нет такого совпадения. При динамическом программировании построение оптимальной последовательности принято начинать с конца и двигаться в обратном направлении.
Производительность особенно важна для этого скрипта потому, что он работает в браузере в процессе ввода пароля. Чтобы обеспечить работу программы, я начинал с простого подхода O(2m) к вычислению сумм для всех возможных непересекающихся подмножеств, и процесс очень быстро замедлялся с усложнением задачи. Теперь же на полный анализ большинства паролей у zxcvbn уходит не больше нескольких миллисекунд. По самой грубой оценке, в Google Chrome на 2,4 ГГц Intel Xeon, пароль correcthorsebatterystaple в среднем анализируется примерно за 3 мсек. На пароль coRrecth0rseba++ery9/23/2007staple$ в среднем уходит около 12 мсек.
Модель угрозы: соотношение между энтропией и временем взлома
Понятие энтропии не слишком прозрачный показатель. Как понять, достаточно ли надежен пароль на 28 бит? Иными словами, как перейти от оценки энтропии непосредственно ко времени взлома? Для этого применяется модель угрозы. Предположим, что:
- пароли хранятся в виде хешей с «солью» и «соль» для каждого пользователя выбрана случайно, что делает атаку с помощью радужной таблицы нецелесообразной;
- взломщику удалось украсть все хеши и всю «соль» и теперь он подбирает пароль в режиме офлайн на максимально возможной скорости;
- в распоряжении взломщика несколько процессоров.
Некоторые ориентировочные цифры:
# для таких хеш-функций, как bcrypt/scrypt/PBKDF2, за нижнюю границу времени одной попытки можно
# смело принимать 10 мсек.
# обычно же попытки длятся дольше — в этом случае мы предполагаем, что у взломщика имеется
# быстрое железо и вычисление хеша # выполняется относительно быстро;
# если вы используете другую хеш-функцию на своем сайте, соответствующим образом скорректируйте
# это время — возможно, на несколько порядков!
SINGLE_GUESS = .010 # секунд
NUM_ATTACKERS = 100 # число параллельно атакующих ядер
SECONDS_PER_GUESS = SINGLE_GUESS / NUM_ATTACKERS
entropy_to_crack_time = (entropy) ->
.5 * Math.pow(2, entropy) * SECONDS_PER_GUESS
Здесь я ввел коэффициент 0,5, поскольку мы вычисляем среднее время взлома, а не время перебора всего пространства поиска.
Возможно, эти вычисления слишком консервативны. Крупномасштабная кража хешей случается довольно редко, и, если только атака не направлена прямо на вас, взломщик вряд ли отведет 100 ядер на один ваш пароль. Обычно взломщику приходится гадать в режиме онлайн, где ему досаждают сетевая задержка, нарастающая задержка и CAPTCHA.
Вычисление энтропии
Теперь рассмотрим, как zxcvbn рассчитывает энтропию каждой комбинации символов в пароле. Точка входа — calc_entropy(). Это простой выбор:
calc_entropy = (match) ->
return match.entropy if match.entropy?
entropy_func = switch match.pattern
when ‘repeat’ then repeat_entropy
when ‘sequence’ then sequence_entropy
when ‘digits’ then digits_entropy
when ‘year’ then year_entropy
when ‘date’ then date_entropy
when ‘spatial’ then spatial_entropy
when ‘dictionary’ then dictionary_entropy
match.entropy = entropy_func match
Выше я в общих чертах объяснил, как работает функция repeat_entropy. С полным текстом кода расчета энтропии можно самостоятельно ознакомиться на github, но чтобы дать вам некоторое представление о нем, я опишу две другие расчетные функции: spatial_entropy (энтропия клавиатурных комбинаций) и dictionary_entropy (словарная энтропия).
Рассмотрим клавиатурную комбинацию qwertyhnm. Она начинается с символа q, ее длина — 9 символов, и у нее есть три направления движения: сначала движение направо, затем вниз и направо, затем снова вниз и направо. Параметризируем данную комбинацию:
s # число возможных начальных символов
# 47 — для клавиатуры QWERTY/Dvorak, 15 — для цифровой клавиатуры PC и 16 —
# для цифровой клавиатуры Macintosh
L # длина пароля; L >= 2
t # число смен направления; t <= L – 1
# например, пароль длиной 3 может иметь не более 2 смен направления («qaw»)
d # средний «порядок» каждой клавиши равен числу смежных с ней клавиш;
# для клавиатур QWERTY/Dvorak он составляет порядка 4,6 (у клавиши g – 6 соседей,
# у тильды – только 1)
Тогда общее пространство возможностей включает все возможные клавиатурные комбинации длины L или менее, имеющие t или менее смен направления:
Функция «биноминальный коэффициент из (i – 1) по (j – 1)» подсчитывает возможные конфигурации смены направлений для клавиатурной комбинации длины i, имеющей j смен направления. К обоим элементам добавляется «-1», поскольку первая смена направления всегда происходит на первой букве. При каждом из j смен направлений существует d возможных направлений, т. е. всего dj возможностей на каждую конфигурацию. Взломщик также должен перебрать все начальные символы, отсюда коэффициент s в формуле. Сама формула весьма приблизительна — в частности потому, что многие варианты, учтенные в ней, на реальной клавиатуре невозможны: для клавиатурной комбинации длины 5 с 1 сменой направления операция «начать с “q” и двигаться влево» учтена, но невозможна.
Это выражение на CoffeeScript можно записать так:
lg = (n) -> Math.log(n) / Math.log(2)
nPk = (n, k) ->
return 0 if k > n
result = 1
result *= m for m in [n-k+1..n]
result
nCk = (n, k) ->
return 1 if k = 0
k_fact = 1
k_fact *= m for m in [1..k]
nPk(n, k) / k_fact
spatial_entropy = (match) ->
if match.graph in ['qwerty', 'dvorak']
s = KEYBOARD_STARTING_POSITIONS
d = KEYBOARD_AVERAGE_DEGREE
else
s = KEYPAD_STARTING_POSITIONS
d = KEYPAD_AVERAGE_DEGREE
possibilities = 0
L = match.token.length
t = match.turns
# оценка числа клавиатурных комбинаций длины L, имеющих t или менее смен направления
for i in [2..L]
possible_turns = Math.min(t, i – 1)
for j in [1..possible_turns]
possibilities += nCk(i – 1, j – 1) * s * Math.pow(d, j)
entropy = lg possibilities
# добавляем дополнительную энтропию, связанную со смещением клавиш
# (% вместо 5, A вместо a)
# расчеты аналогичны вычислению дополнительной энтропии, связанной
# с употреблением заглавных букв в словарных словах
# см. след. фрагмент кода
if match.shifted_count
S = match.shifted_count
U = match.token.length – match.shifted_count # расчет без учета сдвига
possibilities = 0
possibilities += nCk(S + U, i) for i in [0..Math.min(S, U)]
entropy += lg possibilities
entropy
Переходим к словарной энтропии:
dictionary_entropy = (match) ->
entropy = lg match.rank
entropy += extra_uppercasing_entropy match
entropy += extra_l33t_entropy match
entropy
Самая важная строка — первая: к каждому совпадению привязан свой ранг частоты употребления: такие слова, как the и good имеют низкий ранг, а слова типа photojournalist и maelstrom — высокий. Это позволяет zxcvbn на ходу масштабировать вычисления в соответствии с размером словаря, поскольку, если в пароле используются только распространенные слова, его можно взломать с применением меньшего словаря. Это одна из причин, по которым энтропия пароля correcthorsebatterystaple немного разнится по версиям xkcd и zxcvbn (45,2 бит и 44 бит соответственно). В xkcd использовался фиксированный словарь размером 211 (около 2000 слов), а zxcvbn адаптирует рабочий словарь к конкретной ситуации. Поэтому zxcvbn.js содержит полные словари, а не компактный фильтр Блума, и помимо проверки принадлежности комбинации к определенному массиву, необходимы сведения о ее ранге.
В конце данной статьи, в разделе «Данные», я поясню, откуда берутся ранги по частоте. Энтропия, связанная с использованием букв верхнего регистра, рассчитывается следующим образом:
extra_uppercase_entropy = (match) ->
word = match.token
return 0 if word.match ALL_LOWER
# самая распространенная схема употребления заглавных букв — выделение
# первой буквы в слове,
# поэтому она увеличивает область поиска всего в два раза (строчная +
# заглавная):
# всего 1 дополнительный бит энтропии.
# написание всего слова или последней буквы слова заглавными буквами тоже
# достаточно широко распространено,
# чтобы не завысить оценку надежности, примем дополнительную энтропию,
# создаваемую при этом, за 1 бит
for regex in [START_UPPER, END_UPPER, ALL_UPPER]
return 1 if word.match regex
# в противном случае, подсчитаем количество возможных способов употребления
# заглавных букв
# U+L заглавных и строчных с U и менее заглавных
# или, если заглавных больше, чем строчных (например, PASSwORD), — число
# способов употребления строчных букв для U+L букв с L и менее строчных
U = (chr for chr in word.split(”) when chr.match /[A-Z]/).length
L = (chr for chr in word.split(”) when chr.match /[a-z]/).length
possibilities = 0
possibilities += nCk(U + L, i) for i in [0..Math.min(U, L)]
lg possibilities
Таким образом, получаем 1 дополнительный бит энтропии для схемы «первая заглавная» и других распространенных схем. Если же схема использования заглавных букв не относится к распространенным, она добавляет нам:
Вычисления по замещающим символам l33t аналогичны, но тогда вместо переменных для заглавных и строчных букв используются переменные для замененных и незамененных символов.
Совпадение комбинаций
Выше я рассказал вам о методах вычисления энтропии комбинаций, но еще не объяснил, как zxcvbn находит сами комбинации. Сверка со списком слов в словаре — довольно простая процедура: каждая подстрока пароля проверяется на наличие ее аналога в словаре:
dictionary_match = (password, ranked_dict) ->
result = []
len = password.length
password_lower = password.toLowerCase()
for i in [0...len]
for j in [i...len]
if password_lower[i..j] of ranked_dict
word = password_lower[i..j]
rank = ranked_dict[word]
result.push(
pattern: ‘dictionary’
i: i
j: j
token: password[i..j]
matched_word: word
rank: rank
)
result
Ranked_dict определяет частоту употребления слова. Это похоже на массив слов, но только отсортированный сверху вниз по частоте употребления, при этом частота и значение меняются местами. Замены l33t определяются отдельной функцией, использующей в качестве примитива dictionary_match. Клавиатурные последовательности (например, bvcxz) определяются при помощи смежностных графов, с подсчетом смен направления и сдвигов. Даты и года определяются при помощи регулярных выражений. В разделе matching.coffee на github можно узнать о механизме сверки со словарем подробнее.
Данные
Как уже говорилось ранее, список 10 000 самых распространенных паролей взят из статьи Бернетта, опубликованной в 2011 году.
Частотный словарь имен и фамилий был составлен на основе данных переписи населения США 2000 года, находящихся в свободном доступе. Чтобы программа zxcvbn не приводила к сбоям в работе Internet Explorer 7, я обрезал длинный словарь фамилий на 80 % (т. е. 80 % американцев носят фамилии, встречающиеся в этом списке), а словарь имен — на 90 %.
Словарь 40 000 самых распространенных слов в английском языке был взят из материалов одного проекта на Wiktionary, составленных на основе около 29 млн. слов из телевизионных программ и фильмов, демонстрируемых в США. Расчет был на то, что все списки, которые я нашел в Интернете, и все слова из телевизионных и киносценариев будут наиболее употребительными (следовательно, будут часто встречаться в паролях), а потому представляют собой лучшие источники — однако это лишь непроверенная гипотеза. Списки с момента составления немного устарели, например, Frasier стоит на 824-м месте по частоте употребления.
Заключение
На первый взгляд может показаться, что создать хорошую программу для оценки надежности паролей почти так же сложно, как и хорошую программу для их взлома. По определению это так, если ваша цель — точность, ведь «идеальная энтропия» в соответствии с идеальной моделью измеряется именно количеством вариантов, которые нужно перебрать программе взлома (используемой смышленым взломщиком) для подбора пароля. Но в данном случае цель программы заключается не в точности, а в том, чтобы дать пользователю хороший совет при выборе пароля. И это даже упрощает задачу: например, я могу позволить себе недооценить степень энтропии пароля, и единственным недостатком этого будет отбор программой более надежных паролей, чем нужно (что может раздражать пользователя, но не создаст для него опасности).
Точная оценка надежности пароля остается нелегкой задачей, в основном ввиду существования огромного количества возможных комбинаций. Zxcvbn не распознает слова, если из них убрать первую букву или гласные или написать их с ошибками; не распознает n-граммы; почтовые индексы крупных населенных пунктов; разорванные клавиатурные последовательности (например, qzwxec) и многое другое. Неочевидные комбинации (например, числа Каталана) распознавать не столь важно, однако каждая общеупотребимая комбинация, не распознанная zxcvbn, но известная взломщику, приводит к завышению оценки энтропии пароля — и это самой большой дефект программы. Возможные пути его устранения:
- На данный момент программа zxcvbn работает только с английскими словами, и ее частотный словарь в основном отражает особенности американского английского языка и его орфографии. Имена и фамилии также в основном взяты из материалов переписей населения США. Из всех современных раскладок клавиатуры zxcvbn распознает лишь несколько. Существенным улучшением могло бы стать добавление специфичных для конкретных стран наборов данных с возможностью выбора при загрузке.
- Как показывает исследование, проведенное Джозефом Бонно, помимо общеупотребительных слов люди зачастую выбирают в качестве пароля общеизвестные фразы. Программа zxcvbn работала бы лучше, если бы распознавала «Гарри Поттер» как общеупотребительную фразу, а не как имя и фамилию средней частоты употребления. Свод n-грамм Google занимает один терабайт, и даже хороший список биграмм непрактично подгружать в браузер, так что добавление этой функции потребует серверной обработки данных и инфраструктурных затрат. Проверка пароля через сервер позволила бы использовать гораздо более обширный словарь, например базу униграмм Google.
- Zxcvbn хорошо бы научить мириться с неправильным (до определенной степени) написанием слов. Это обогатило бы ее базу множеством словесных комбинаций (например тех, в которых пропущена первая буква). Однако это трудная задача, поскольку сегментация слов — сложный процесс, особенно когда они усложнены подстановками жаргона l33t.
Тем не менее, я считаю, что даже с учетом этих недостатков, zxcvbn дает пользователям весьма дельные советы по выбору надежного пароля в мире, где слишком часто выбираются неудачные пароли. Надеюсь, эта программа окажется полезной и для вас. «Форкните» ее на github и развлекайтесь!
Большое спасибо Крису Варенхорсту, Гаутаму Джайраману, Бену Дарнеллу, Алисии Чен, Тодду Айзенбергеру, Каннану Гундану, Крису Бекманну, Райану Хантеру, Брайану Смиту, Мартину Бейкеру, Ивану Киригину, Джулии Танг, Тидо Великому, Рэмзи Хомсэни, Барту Волькмеру и Саре Нийоги за рецензирование данной статьи.
Перевод выполнен ABBYY Language Services
p.s. В комментариях принимаются идеи на тему «где брать материалы для перевода», «материалы какой тематики интересуют хабрапользователей» и даже конкретные ссылки — претенденты на перевод.

{kind=link}