Интерес к технологиям Big Data постоянно растет, а сам термин приобретает все большую популярность, многие люди хотят поговорить об этом, обсудить перспективы и возможности в этой области. Однако немногие конкретизируют — какие компании представлены на этом рынке, не описывают решения этих компаний, а также не рассказывают про методы, лежащие в основе решений Big Data. Область информационных технологий, относящихся к хранению и обработке данных, претерпела существенные изменения к настоящему моменту и представляет собой стремительно растущий рынок, а значит лакомый кусок для многих всемирно известных и небольших, только начинающих, компаний в этой сфере. У типичной крупной компании имеется несколько десятков оперативных баз данных, хранящих данные об оперативной деятельности компании (о сделках, запасах, остатках и т.п.), которые необходимы аналитикам для бизнес-анализа. Так как сложные, непредвиденные запросы могут привести к непредсказуемой нагрузке на оперативные базы данных, то запросы аналитиков к таким базам данных стараются ограничить. Кроме того, аналитикам необходимы исторические данные, а также данные из нескольких источников. Для того чтобы обеспечить аналитикам доступ к данным, компании создают и поддерживают так называемые хранилища данных, представляющие собой информационные корпоративные базы данных, предназначенные для подготовки отчетов, анализа бизнес-процессов и поддержки системы принятия решений. Хранилища данных служат также источником для оценки эффективности маркетинговых кампаний, прогнозированию, поиску новых возможных рынков и аудиторий для продажи, всевозможному анализу предыдущих периодов деятельности компаний. Как правило, хранилище данных – это предметно-ориентированная БД, строящаяся на временной основе, т.е. все изменения данных отслеживаются и регистрируются по времени, что позволяет проследить динамику событий. Также хранилища данных хранят долговременные данные — это означает, что они никогда не удаляются и не переписываются – вносятся только новые данные, это необходимо для изучения динамики изменения данных во времени. И последнее, хранилища данных, в большинстве случае, консолидированы с несколькими источниками, т.е. данные попадают в хранилище данных из нескольких источников, причем, прежде чем попасть в хранилище данных, эти данные проходят проверку на непротиворечивость и достоверность.
В феврале 2012 года исследовательская и консалтинговая компания Gartner представила свой аналитический отчет для хранилищ данных. В рамках этого отчета хранилища данных определены, как СУБД, которая управляет и поддерживает одну или несколько логических баз данных в хранилище. Кроме этого, СУБД хранилища данных должна поддерживать реляционную модель данных, а также иметь возможность предоставить доступ к данным через программные интерфейсы для того, чтобы сторонние аналитические приложения могли воспользоваться данными, находящимися в хранилище данных. В дополнение к этому, СУБД хранилища данных должна иметь механизмы, изолирующую различные типы нагрузок друг от друга, а также управлять различными параметрами доступа пользователей в рамках одного экземпляра данных.
Так как одним из требований Gartner к хранилищам данных в этом аналитическом отчете была поддержка реляционной модели данных, то, соответственно, решения, основанные на платформе Apache Hadoop, не вошли в число претендентов на рассмотрение в рамках этого отчета. К тому же, Apache Hadoop не совсем подходит под требования, выдвигаемые к современным хранилищам данных, так как обладает низкой скоростью выполнения сложных аналитических запросов по сравнению с остальными решениями, представленными в этом отчете, и, очевидно, не может выполнять задачи, выдвигаемые компаниями к современным хранилищам данных. Несмотря на это, платформа Apache Hadoop является быстроразвивающимся проектом и, возможно в будущем, решения, основанные на этой платформе, займут свое место рядом с решениями других производителей. Также хотелось бы заметить, что Apache Hadoop не предназначен для анализа данных в режиме реального времени – это решение для хранения неструктурированных данных с возможностью анализа этих данных в будущем, что не соответствует требованиям компаний иметь возможность оперативного анализа данных для хранилищ данных. К тому же, парадигма MapReduce подходит не для всего класса аналитических задач, возникающих перед аналитиками. Тем не менее, большинство решений, рассматриваемых в этой статье, поддерживают интеграцию с Apache Hadoop.
По результатам анализа, проведенного в этом отчете, Gardner составил так называемый Magic Quadrant, где разместил компании соответственно полям этого квадрата.
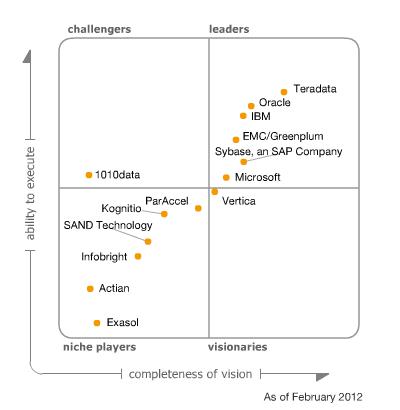
В этой статье я бы хотел подробно остановиться на решениях компаний, находящихся в правом верхнем углу магического квадранта Gartner. Если быть точнее, не на самих решениях, а на тех свойствах решений, которые позволили выбиться им в лидеры и провести анализ этих свойств, а также оценить их применимость в будущем.
Прежде чем приступить к рассмотрению общих черт, присущих лидерам в области хранилищ данных, имеет смысл остановиться на решении от Oracle и рассмотреть его поближе, так как это решение, в целом, отличается от конкурентов. Для хранилищ данных Oracle предлагает использовать свою аппаратные платформу Exadata Database Machine X2-2. Однако, это только аппаратная часть — лицензии на Oracle Database покупаются отдельно. Для того чтобы добиться максимальной производительности, а также отказоустойчивости необходимо приобрести отдельно лицензии на Oracle Real Application Clusters и партиционирование. Oracle утверждает, что в таком виде хранилище данных может использоваться как OLTP система, так и DW решение в одно и то же время. Данное заявление является правдой в ограниченном количестве случаев – зачастую существование нагрузок различных типов на одной платформе приводит к неоптимальной работе обеих. Архитектура Exadata подразумевает под собой разделение на два типа серверов – это вычислительные узлы Exadata Database Server X2-2, где находиться СУБД Oracle Database и узлы Exadata Storage Server, которые хранят данные. Если быть точнее, то на Exadata Storage Server находится Exadata Storage Server Software, которое включает в себя так называемые «Cell Services», что, в свою очередь, позволяет использовать технологию «Smart Scan». «Smart Scan» берет на себя практически всю работу по простому поиску и выборке данных, тем самым освобождая вычислительные узлы от лишней нагрузки. Такая архитектура предоставляет возможность Oracle проводить балансировку нагрузки, и снизить объемы передаваемых данных между двумя типами узлов, но обладает существенным недостатком, а точнее ограниченной масштабируемостью, которая не позволяет масштабировать платформу Exadata линейно. Это приводит к тому, что начиная с определенного момента добавление новых узлов не приносит существенного увеличения производительности, и в тоже время является довольно затратной операцией, так как аппаратное и программное обеспечение Oracle стоит дорого. Тем самым можно сделать вывод, что решения Oracle в сфере хранилищ данных не смогут соответствовать будущим ожиданиям компаний, хотя и обеспечивают приемлемую производительность на текущий момент. То, что Oracle находится на втором месте после Teradata вызвано, по моему мнению, агрессивной маркетинговой политикой Oracle, а также тем, что множество клиентов, уже использующих Oracle, решило консолидировать свои БД на аппаратной платформе Oracle, сократив тем самым расходы на техническое обслуживание и поддержку, не теряя в то же время на производительности. Поэтому Oracle не обладает теми особенностями, которые обладают другие лидеры в этом обзоре, но, несмотря на это, большой опыт разработки баз данных и огромное количество клиентов дало возможность находиться в секторе лидеров.
Обзор Oracle Exadata и вскрытие её недостатков от компании Teradata
Тоже самое справедливо и для Microsoft, представленной на рынке решениями SQL Server 2008 R2 DBMS Business Data Warehouse и Fast Track Data Warehouse. По сути, эти решения не обладают достаточной технической функциональностью по сравнению со своими конкурентами, предлагая в то же время много маркетинговых «фишек». Продажи Microsoft во многом основаны на политике демпинга, а также игре на том, что специалистов, знакомых с данными решениями на рынке много, их обучение не должно занимать много времени, качестве и доступности поддержки производителя. Также немаловажную роль играет то, что решения Microsoft можно быстро и эффективно интегрировать в существующую инфраструктуру большинства компаний. Обладая большим количеством клиентов, а также развитой сетью партнеров и реселлеров, Microsoft удалось добиться хороших продаж к текущему моменту. Несмотря на это, существующие решения Microsoft отстают от своих конкурентов технологически, что приводит к мысли, что они не смогут конкурировать с решениями других производителей в будущем. В дополнение к этому, Microsoft не изменяет своей традиции и выпускает продукты с большим количеством ошибок, причем затягивая исправления этих ошибок на долгий срок, что также не способствует распространению продуктов Microsoft. Решение Microsoft PDW, выпущенное в ноябре 2010 года не имеет ни одного отзыва в качестве системы, использующейся для промышленной эксплуатации. Это говорит о том, что никто так и не смог заставить работать это решение более-менее стабильно, обеспечивая текущие потребности компаний.
Однако в этой статье я хотел бы рассмотреть именно те особенности, которые позволили решениям других лидеров быть впереди, а также надеяться на то, что в будущем они смогут отвечать постоянно растущим потребностям компаний.
Прежде чем приступить к рассмотрению, было бы хорошо понять, какое из решений поставляется в виде программного обеспечения, а какое в виде преднастроенного аппаратного-программного комплекса. Преднастроенный аппаратно-программный комплекс избавляет от процедуры настройки и конфигурирования, сокращая время, необходимое для его внедрения, однако стоимость его существенно выше. Решение же, поставляемое в виде программного обеспечения, позволяет выбрать самому аппаратную платформу и не переплачивать за оборудование, а также дает возможность легко увеличить производительность и вместимость за счет добавления новых серверов в будущем. В этом списке можно выделить IBM Netezza, которая поставляется в виде проприетарного оборудования, а именно на блейд серверах IBM. Это означает зависимость от производителя, если быть точным от IBM, т.е. в случае, если возникнет необходимость расширения, то придётся обращаться к IBM и покупать дополнительное оборудование и лицензии у неё. К тому же, процесс расширения для IBM Netezza нетривиален и требует долгого процесса миграции, во время которого система должны находиться в downtime – это ведет к простою и потери времени. Замечание о зависимости от производителя справедливо и для решений Oracle и Teradata. Некоторые решения могут поставляться как в виде hardware, так и в software:
Здесь необходимо сделать уточнение, что решения от Microsoft по сути являются разными разновидностями одного прародителя — Microsoft SQL Server 2008 DBMS R2 и, в целом, отличаются только аппаратной платформой, на которой поставляются (разные сервера от HP и Dell), а также добавлением некоторых программных особенностей. IBM InfoSphere Warehouse – это DB2 10 LUW(Linux, Unix, Windows) c возможностями DPF (Database Partitioning Feature), соответственно обладает теми же возможностями, что и DB2 10, однако в дополнение к ним, может быть развернута с применением MPP архитектуры.
Массово-параллельная архитектура(Massive Parallel Processing, MPP) – это класс параллельных вычислительных систем, состоящих из множества узлов, где каждый узел представляет собой автономную, независимую от других единицу. Если применить это определение к области хранилищ данных, то лучше всего его смысл будет отражать термин «распределённые базы данных». Каждый узел в распределенной базе данных представляет собой полноценную СУБД, работающую независимо от других. Сама же распределенная база данных – это совокупность независимых, автономных узлов, связанных коммуникационной сетью. Все данные в такой сети распределяются между узлами равномерно, т.е. каждый узел хранит свою, уникальную часть данных, логически, тем не менее, представляя единую базу данных. Для пользователя распределенная БД выглядит как единая целая, не разделенная на части база данных. При обращении к распределенной СУБД запрос выполняется параллельно всеми узлами базы данных, выполняя поиск и выборку только в своем, уникальном кусочке данных, что позволяет значительно повысить скорость доступа к данным. Преимущества такой архитектуры очевидны – это линейная масштабируемость, которая обеспечивает стабильные и предсказуемые параметры производительности и развитие системы. Тенденция в области хранилищ данных относительно архитектуры такова, что в будущем останутся только решения, основанные на MPP архитектуре, так как именно они позволяют обрабатывать огромные объемы информации на стандартном аппаратном обеспечении. Недостаток также очевиден – чтобы соответствовать функциональным требованиям ACID, система должна получить отклик от каждого узла, поэтому коммуникационная сеть между узлами должна обладать высокой пропускной способностью, а также отказоустойчивостью. В реальности, для современных хранилищ данных вполне хватает существующих стандартов передачи данных (10 Гигабит), а с внедрением стандарта в 100 Гигабит проблема скорости передачи между узлами вовсе отпадет, так как узким местом будет дисковая подсистема (тоже не факт, так как In-memory DB используют оперативную память для хранения данных).
Первопроходцем в области MPP архитектуры для хранилищ данных была Teradata, которая представила первую систему с такой архитектурой в 1984 году. С тех пор Teradata прошла большой путь, накопила массу полезного опыта в этой сфере и заслуженно является лидером. В 2000-х появились решения с подобной архитектурой от других производителей – это EMC Greenplum, HP Vertica, Sybase IQ, IBM Netezza, IBM InfoSphere Warehouse и Microsoft PDW. Следует заметить, что архитектура MPP может существовать в двух качествах – это shared nothing и shared everything. В первом случае, каждый узел не разделяет системные ресурсы с другими узлами, выделяя и используя необходимые ему ресурсы самостоятельно. Во втором случае узел использует разделяемые ресурсы, обращаясь к некоему механизму для получения необходимых ему ресурсов. Каждый подход обладает своими преимуществами и недостатками – shared nothing не позволяет утилизировать все ресурсы достаточно эффективно, оставляя часть из них простаивать в любой случае. Shared everything утилизирует ресурсы более эффективно, однако требует механизм межпроцессного согласования при использовании разделяемых ресурсов, что выливается в дополнительное время, необходимое для такого согласования при выделении ресурсов. В качестве системных ресурсов тут выступают оперативная память и дисковая подсистема. Oracle и Microsoft пошли своим путем, используя архитектуру SMP (Symmetric Multiprocessing) в своих разработках. Данная архитектура характеризуется тем, что с единой базой данных работают несколько процессов. Для повышения скорости доступа к данным Oracle и Microsoft рекомендуют использовать партиционирование, разделяя таблицу на несколько логических секций, и тем самым разделяя данные на более маленькие кусочки. Этот подход помогает, если нам необходимо выбрать небольшую часть данных в таблице, однако неэффективен, если мы должны использовать для анализа бОльшую часть данных, содержащихся в таблице (так называемый Full Scan), что при традиционной для хранилищ данных схеме «звезда» или «снежинка» является неизбежным. Для большого понимания, на каких принципах основано каждое решение, приведу таблицу:
Как видно из таблицы, большинство производителей предпочитают использовать более производительный вариант shared nothing, несмотря на то, что он не утилизирует часть системных ресурсов, позволяя им простаивать без дела. Именно архитектура MPP является наиболее подходящей для хранилищ данных, так как предоставляет линейную масштабируемость, позволяя наращивать мощность хранилища данных соответственно постоянно растущим требованиям. Однако для ряда решений, находящихся в правом верхнем секторе магического квадранта Gartner, характерно еще одно свойство, которое помогает увеличить скорость доступа к данным и, соответственно, предоставить их аналитикам настолько быстро, насколько возможно.
Идея хранить данные не по строкам, а по колонкам не нова и принадлежит Sybase, которая выпустила Sybase IQ в 1996 году – первую в мире базу данных, поддерживающую колоночное хранение данных. Основой для этой идеи послужило то, что нагрузка на хранилище данных и оперативные базы данных радикально различается по своему характеру. Если для OLTP систем характерны частые, мелкие транзакции, выполняющие в основном операции добавления или обновления(insert/update), то нагрузка на хранилище данных характеризуется тем, что основными операциями являются чтение больших объемов данных, часто с применением агрегирования. Таким образом, если для OLTP систем хранение построчно является оптимальным, так как при добавлении новой строки нам выгоднее записать её на диск за один проход целиком, то для хранилищ данных такое хранения неэффективно. Например, если у нас данные хранятся построчно, то для таблицы, состоящей из 10 столбцов, при выборке, где будут перечислены всего три столбца, нам придётся прочитать все 10 столбцов, что крайне неэффективно, так как данные из остальных 7 столбцов нам не нужны. В этом же примере, если использовать модель колоночного хранения данных, то данные будут прочитаны только из тех столбцов, которые были перечислены в запросе, уменьшая количество операций чтения в несколько раз. Так как в большинстве запросов, выполняющихся в хранилище данных, применяются всего несколько столбцов из таблицы, то хранения данных в колоночном виде является оптимальным. Крупнейшие игроки на рынке DWH – Oracle, Microsoft и IBM почему-то скромно умалчивают об этом, когда их сравнивают с конкурентами, невнятно обещая поддержку колоночного хранения данных когда-нибудь в будущем. Эта скромность может привести к тому, что решения этих компаний в будущем не будут рассматриваться вовсе. Необходимо также заметить, что решения некоторых компаний, в частности EMC Greenplum и Teradata, поддерживают полиморфную модель хранения данных, т.е. часть данных может храниться в строчном виде, а часть данных в колоночном виде. Это сделано для того, чтобы иметь возможность создавать такие таблицы, где транзакционная нагрузка будет похожа на OLTP, т.е. будет присутствовать много мелких операций «добавления/изменения» данных.
Для того чтобы понять какую модель хранения данных использует каждое решение, приведу таблицу:
Будучи пионерами в области колоночного хранения данных, создатели Sybase IQ использовали идею индексирования данных для обеспечения доступа к ним. Каждая колонка в каждой таблице Sybase IQ должна быть проиндексирована, в противном случае, при выполнении запроса оптимизатор вернет сообщение с ошибкой. В Sybase IQ 15 индекс создается по умолчанию на всю таблицу, это так называемый Fast Projection Default Index. В целом, идея индексирования данных нашла горячую поддержку в сердцах разработчиков Sybase IQ, что выразилось в создании 10 различных типов индексов и рекомендациях использовать их везде и всегда. Рекомендуется создать несколько индексов на таблицу или даже столбец в зависимости от типа и характера данных, а также, принимая во внимания, в каком качестве определенной столбец будет использоваться в запросе, т.е. будет ли он принимать участие в агрегировании с другими столбцами или играть роль предиката. После того, как запросы будут разобраны и необходимые индексы будут созданы, Sybase IQ обещает высокую производительность, как для произвольных запросов, так и запросов, использующих большие объемы данных. Несмотря на некоторые преимущества, предоставляемые таким подходом, Sybase IQ знаменит своей потрясающе медленной загрузкой данных, так как обслуживание большого количества индексов является дорогостоящей операцией.
Дальше всех с идеей колоночного хранения данных пошла HP Vertica, реализовав так называемые проекции (projections), которые представляют собой, если пользоваться терминологией Oracle, материализованные представления, отсортированные по одному или нескольким столбцам. Материализованные представления в HP Vertica, состоящие из одного или нескольких столбцов таблицы, позволяют минимизировать количество операций чтения для запросов, где столбцы, которые нужно прочитать, заранее определены. Проекции, использующиеся в HP Vertica, действительно позволяют добиться более высокой скорости чтения относительно конкурентов, обладая, тем не менее, существенными недостатками – это хранения избыточного объема данных, так как часть столбцов присутствуют в нескольких проекциях одновременно. Неготовность к спонтанным, произвольным запросам, выражающейся в долгом ожидании ответа, не прибавляют решению HP Vertica достоинств. Если быть откровенным, то HP Vertica позволяет добиться хорошей производительности для специфичных запросов только после выяснения всех обстоятельств предстоящей нагрузки и долгой стадии подготовки проекций.
Механизм проекций, эксплуатирующийся в HP Vertica, вынудил создателей этого решения прибегнуть к разработке своеобразного механизма загрузки данных. Прежде всего, надо сказать, что хранение данных в HP Vertica разделено на две области – Write-Optimized Column Store (WOS) и Read-Optimized Column Store (ROS). Перед тем, как данные попадают в ROS они проходят через область WOS, где специальный процесс под названием Tuple Mover отсортировывает данные, сжимает их и помещает в соответствующие проекции в ROS. Непрозрачность этого механизма не дает нам понять, какие данные были загружены, а какие нет. Одним из трюков, которые любят показывать инженеры HP Vertica – это мгновенная загрузка данных, т.е. команда по загрузке нескольких сот гигабайт или нескольких терабайт данных выполняется практически мгновенно – это не так, на самом деле данные сначала попадают в WOS, и только после того, как они будут обработаны процессом Tuple Mover, они будут в области ROS.
Загрузка данных для решений остальных компаний выглядит намного прозаичнее – это механизм параллельной загрузки данных через external tables, позволяющий работать с плоскими файлами, как с обычными таблицами. Такой механизм поддерживают Oracle Exadata, IBM InfoSphere Warehouse, IBM Netezza, EMC Greenplum и Sybase IQ. Самую высокую скорость загрузки данных обеспечивает EMC Greenplum за счет распараллеливания загрузки между всеми логическими узлами хранилища данных, немного отстает от него Oracle Exadata из-за своей SMP архитектуры. Скорость загрузки данных отличается в несколько раз в худшую сторону для тех решений, где нужна предварительная сортировка данных – это IBM Netezza (Zone Maps), дорогостоящие операции с индексами — печально известный Sybase IQ, про IBM DB2 мне, к сожалению, неизвестно.
Microsoft для загрузки данных использует компонент SQL Server-a под названием SQL Server Integration Services (SSIS), который является ни чем иным, как перелицованным, хорошо знакомым многим Data Transformation Services (DTS), существующим в SQL Server с седьмой версии. С помощью этого инструмента, используя графический пользовательский интерфейс и подсказки мастеров, можно создать так называемый «Integration Services Package», который можно использовать в будущем для дальнейшей загрузки данных. Имея опыт использования DTS в Microsoft SQL Server 2000, могу сказать, что стабильность не вызывала никаких проблем (если данные были «чистыми», без мусора), но скорость оставляла желать лучшего.
На фоне конкурентов выгодно отличается набор утилит по загрузке/выгрузке данных, использующийся в Teradata. Объединенные на одной платформе под названием Teradata Parallel Transporter, эти утилиты обладают богатой функциональностью, позволяя загружать/выгружать данные, не блокируя при этом работу пользователей, выполняющих запросы.
Gartner расставил производителей в магическом квадранте соответственно их текущему положению на рынке хранилищ данных. Однако это не означает, что в будущем положение лидеров не изменится относительно друг друга. Все решения, находящиеся в секторе лидеров, имеют механизмы обеспечения отказоустойчивости, инструменты для резервного копирования и восстановления, а также поддерживают тот или иной стандарт SQL. Тем не менее, если углубиться в функциональные возможности каждого решения, то выясниться следующее:
HP Vertica не поддерживает хранимых процедур, функций и различных языков
IBM Netezza не поддерживает индексы, что часто приводит к Full Scan, не поддерживает секционирование таблиц, а также обладает медленной скоростью загрузки данных из-за необходимости предварительной сортировки данных
Недостатки других решений упоминались выше. Это не значит, что все эти решения не обладают достоинствами, позволяющими им выполнять функции хранилища данных. Тем не менее, если в будущем производители не решат проблемы, связанные с текущими недостатками этих решений, то они рискуют потерять свое место в секторе лидеров.
Можно выделить две компании, решения которых наиболее соответствуют будущим потребностям рынка хранилищ данных. Это решение от Teradata и EMC Greenplum. MPP архитектура с концепцией shared nothing, полиморфная модель хранения данных (колоночное и строковое хранение данных), а также богатые функциональные возможности помогут сохранить им свои позиции в будущем. Маркетинговая политика, ведущаяся этими компаниями, несколько отличается друг от друга, позволяя существовать на рынке хранилищ данных совместно, при этом устраняя жесткую конкуренцию между решениями.
Teradata продается в виде преднастроенного аппаратно-программного комплекса и по стоимости сравнима с Oracle Exadata, т.е. находится в верхнем ценовом диапазоне. Высокая цена Teradata обусловлена тем, что компания не старается унифицировать свое решение, предлагая свое видение каждому новому заказчику. Не доверяя процесс внедрения сторонним компаниям Teradata до последнего времени разрабатывала и воплощала концепцию хранилища данных для каждого нового клиента самостоятельно, именно поэтому цикл внедрения у Teradata довольно долгий, а цена на обслуживание и поддержку достаточно высока.
EMC Greenplum может поставляться как в виде программного обеспечения, так и в виде преднастроенного аппаратно-программного комплекса, при чем цена этого решения сравнима с HP Vertica и IBM Netezza, но, при этом, Greenplum лишен большой части недостатков, присущих решениями от HP и IBM. Компания EMC, имея широкую сеть партнеров и дистрибьюторов, старается распространять решение Greenplum через них, что позволяет появляться техническим специалистам по этому продукту. Впоследствии, это может привести к тому, что на рынке труда можно будет найти готовых специалистов и тем самым сократить затраты на разработку и поддержку собственного хранилища данных. Также EMC в последнее время следит за областью Big Data, стараясь соответствовать последним тенденциям, а где-то привнести свои собственные – подтверждением этому является событие Data Science Summit 2012, проведенный EMC в Лас-Вегасе. Тем самым EMC пытается привлечь внимание ведущих профессионалов в области Big Data к проблемам, существующим в этой сфере, а также выслушать новые идеи и мысли. Из этого можно сделать вывод, что присутствие и расширение EMC на рынке хранилищ данных – это стратегическая цель для компании, и развитие идей, заложенных в Greenplum, не прекратится в ближайшем будущем. Подводя итог, можно сказать, что Greenplum полностью подходит под требования, предъявляемым к современным хранилищам данных и является одним из лучших решений, наряду с Teradata, оставляя конкурентов далеко позади.
Отчет Gartner о DWH
В феврале 2012 года исследовательская и консалтинговая компания Gartner представила свой аналитический отчет для хранилищ данных. В рамках этого отчета хранилища данных определены, как СУБД, которая управляет и поддерживает одну или несколько логических баз данных в хранилище. Кроме этого, СУБД хранилища данных должна поддерживать реляционную модель данных, а также иметь возможность предоставить доступ к данным через программные интерфейсы для того, чтобы сторонние аналитические приложения могли воспользоваться данными, находящимися в хранилище данных. В дополнение к этому, СУБД хранилища данных должна иметь механизмы, изолирующую различные типы нагрузок друг от друга, а также управлять различными параметрами доступа пользователей в рамках одного экземпляра данных.
Так как одним из требований Gartner к хранилищам данных в этом аналитическом отчете была поддержка реляционной модели данных, то, соответственно, решения, основанные на платформе Apache Hadoop, не вошли в число претендентов на рассмотрение в рамках этого отчета. К тому же, Apache Hadoop не совсем подходит под требования, выдвигаемые к современным хранилищам данных, так как обладает низкой скоростью выполнения сложных аналитических запросов по сравнению с остальными решениями, представленными в этом отчете, и, очевидно, не может выполнять задачи, выдвигаемые компаниями к современным хранилищам данных. Несмотря на это, платформа Apache Hadoop является быстроразвивающимся проектом и, возможно в будущем, решения, основанные на этой платформе, займут свое место рядом с решениями других производителей. Также хотелось бы заметить, что Apache Hadoop не предназначен для анализа данных в режиме реального времени – это решение для хранения неструктурированных данных с возможностью анализа этих данных в будущем, что не соответствует требованиям компаний иметь возможность оперативного анализа данных для хранилищ данных. К тому же, парадигма MapReduce подходит не для всего класса аналитических задач, возникающих перед аналитиками. Тем не менее, большинство решений, рассматриваемых в этой статье, поддерживают интеграцию с Apache Hadoop.
По результатам анализа, проведенного в этом отчете, Gardner составил так называемый Magic Quadrant, где разместил компании соответственно полям этого квадрата.

В этой статье я бы хотел подробно остановиться на решениях компаний, находящихся в правом верхнем углу магического квадранта Gartner. Если быть точнее, не на самих решениях, а на тех свойствах решений, которые позволили выбиться им в лидеры и провести анализ этих свойств, а также оценить их применимость в будущем.
Прежде чем приступить к рассмотрению общих черт, присущих лидерам в области хранилищ данных, имеет смысл остановиться на решении от Oracle и рассмотреть его поближе, так как это решение, в целом, отличается от конкурентов. Для хранилищ данных Oracle предлагает использовать свою аппаратные платформу Exadata Database Machine X2-2. Однако, это только аппаратная часть — лицензии на Oracle Database покупаются отдельно. Для того чтобы добиться максимальной производительности, а также отказоустойчивости необходимо приобрести отдельно лицензии на Oracle Real Application Clusters и партиционирование. Oracle утверждает, что в таком виде хранилище данных может использоваться как OLTP система, так и DW решение в одно и то же время. Данное заявление является правдой в ограниченном количестве случаев – зачастую существование нагрузок различных типов на одной платформе приводит к неоптимальной работе обеих. Архитектура Exadata подразумевает под собой разделение на два типа серверов – это вычислительные узлы Exadata Database Server X2-2, где находиться СУБД Oracle Database и узлы Exadata Storage Server, которые хранят данные. Если быть точнее, то на Exadata Storage Server находится Exadata Storage Server Software, которое включает в себя так называемые «Cell Services», что, в свою очередь, позволяет использовать технологию «Smart Scan». «Smart Scan» берет на себя практически всю работу по простому поиску и выборке данных, тем самым освобождая вычислительные узлы от лишней нагрузки. Такая архитектура предоставляет возможность Oracle проводить балансировку нагрузки, и снизить объемы передаваемых данных между двумя типами узлов, но обладает существенным недостатком, а точнее ограниченной масштабируемостью, которая не позволяет масштабировать платформу Exadata линейно. Это приводит к тому, что начиная с определенного момента добавление новых узлов не приносит существенного увеличения производительности, и в тоже время является довольно затратной операцией, так как аппаратное и программное обеспечение Oracle стоит дорого. Тем самым можно сделать вывод, что решения Oracle в сфере хранилищ данных не смогут соответствовать будущим ожиданиям компаний, хотя и обеспечивают приемлемую производительность на текущий момент. То, что Oracle находится на втором месте после Teradata вызвано, по моему мнению, агрессивной маркетинговой политикой Oracle, а также тем, что множество клиентов, уже использующих Oracle, решило консолидировать свои БД на аппаратной платформе Oracle, сократив тем самым расходы на техническое обслуживание и поддержку, не теряя в то же время на производительности. Поэтому Oracle не обладает теми особенностями, которые обладают другие лидеры в этом обзоре, но, несмотря на это, большой опыт разработки баз данных и огромное количество клиентов дало возможность находиться в секторе лидеров.
Обзор Oracle Exadata и вскрытие её недостатков от компании Teradata
Тоже самое справедливо и для Microsoft, представленной на рынке решениями SQL Server 2008 R2 DBMS Business Data Warehouse и Fast Track Data Warehouse. По сути, эти решения не обладают достаточной технической функциональностью по сравнению со своими конкурентами, предлагая в то же время много маркетинговых «фишек». Продажи Microsoft во многом основаны на политике демпинга, а также игре на том, что специалистов, знакомых с данными решениями на рынке много, их обучение не должно занимать много времени, качестве и доступности поддержки производителя. Также немаловажную роль играет то, что решения Microsoft можно быстро и эффективно интегрировать в существующую инфраструктуру большинства компаний. Обладая большим количеством клиентов, а также развитой сетью партнеров и реселлеров, Microsoft удалось добиться хороших продаж к текущему моменту. Несмотря на это, существующие решения Microsoft отстают от своих конкурентов технологически, что приводит к мысли, что они не смогут конкурировать с решениями других производителей в будущем. В дополнение к этому, Microsoft не изменяет своей традиции и выпускает продукты с большим количеством ошибок, причем затягивая исправления этих ошибок на долгий срок, что также не способствует распространению продуктов Microsoft. Решение Microsoft PDW, выпущенное в ноябре 2010 года не имеет ни одного отзыва в качестве системы, использующейся для промышленной эксплуатации. Это говорит о том, что никто так и не смог заставить работать это решение более-менее стабильно, обеспечивая текущие потребности компаний.
Однако в этой статье я хотел бы рассмотреть именно те особенности, которые позволили решениям других лидеров быть впереди, а также надеяться на то, что в будущем они смогут отвечать постоянно растущим потребностям компаний.
Прежде чем приступить к рассмотрению, было бы хорошо понять, какое из решений поставляется в виде программного обеспечения, а какое в виде преднастроенного аппаратного-программного комплекса. Преднастроенный аппаратно-программный комплекс избавляет от процедуры настройки и конфигурирования, сокращая время, необходимое для его внедрения, однако стоимость его существенно выше. Решение же, поставляемое в виде программного обеспечения, позволяет выбрать самому аппаратную платформу и не переплачивать за оборудование, а также дает возможность легко увеличить производительность и вместимость за счет добавления новых серверов в будущем. В этом списке можно выделить IBM Netezza, которая поставляется в виде проприетарного оборудования, а именно на блейд серверах IBM. Это означает зависимость от производителя, если быть точным от IBM, т.е. в случае, если возникнет необходимость расширения, то придётся обращаться к IBM и покупать дополнительное оборудование и лицензии у неё. К тому же, процесс расширения для IBM Netezza нетривиален и требует долгого процесса миграции, во время которого система должны находиться в downtime – это ведет к простою и потери времени. Замечание о зависимости от производителя справедливо и для решений Oracle и Teradata. Некоторые решения могут поставляться как в виде hardware, так и в software:
| DWH | Software | Hardware |
| EMC Greenplum | X | X |
| HP Vertica | X | |
| IBM InfoSphere Warehouse (DB2) | X | |
| IBM Netezza | X | |
| Microsoft SQL Server 2008 DBMS R2 BDW | X | |
| Microsoft SQL Server 2008 DBMS R2 PDW | X | |
| Microsoft SQL Server 2008 DBMS R2 FTDW | X | |
| Oracle Exadata | X | |
| Sybase IQ | X | |
| Teradata Database 14 | X |
Здесь необходимо сделать уточнение, что решения от Microsoft по сути являются разными разновидностями одного прародителя — Microsoft SQL Server 2008 DBMS R2 и, в целом, отличаются только аппаратной платформой, на которой поставляются (разные сервера от HP и Dell), а также добавлением некоторых программных особенностей. IBM InfoSphere Warehouse – это DB2 10 LUW(Linux, Unix, Windows) c возможностями DPF (Database Partitioning Feature), соответственно обладает теми же возможностями, что и DB2 10, однако в дополнение к ним, может быть развернута с применением MPP архитектуры.
MPP архитектура
Массово-параллельная архитектура(Massive Parallel Processing, MPP) – это класс параллельных вычислительных систем, состоящих из множества узлов, где каждый узел представляет собой автономную, независимую от других единицу. Если применить это определение к области хранилищ данных, то лучше всего его смысл будет отражать термин «распределённые базы данных». Каждый узел в распределенной базе данных представляет собой полноценную СУБД, работающую независимо от других. Сама же распределенная база данных – это совокупность независимых, автономных узлов, связанных коммуникационной сетью. Все данные в такой сети распределяются между узлами равномерно, т.е. каждый узел хранит свою, уникальную часть данных, логически, тем не менее, представляя единую базу данных. Для пользователя распределенная БД выглядит как единая целая, не разделенная на части база данных. При обращении к распределенной СУБД запрос выполняется параллельно всеми узлами базы данных, выполняя поиск и выборку только в своем, уникальном кусочке данных, что позволяет значительно повысить скорость доступа к данным. Преимущества такой архитектуры очевидны – это линейная масштабируемость, которая обеспечивает стабильные и предсказуемые параметры производительности и развитие системы. Тенденция в области хранилищ данных относительно архитектуры такова, что в будущем останутся только решения, основанные на MPP архитектуре, так как именно они позволяют обрабатывать огромные объемы информации на стандартном аппаратном обеспечении. Недостаток также очевиден – чтобы соответствовать функциональным требованиям ACID, система должна получить отклик от каждого узла, поэтому коммуникационная сеть между узлами должна обладать высокой пропускной способностью, а также отказоустойчивостью. В реальности, для современных хранилищ данных вполне хватает существующих стандартов передачи данных (10 Гигабит), а с внедрением стандарта в 100 Гигабит проблема скорости передачи между узлами вовсе отпадет, так как узким местом будет дисковая подсистема (тоже не факт, так как In-memory DB используют оперативную память для хранения данных).
Первопроходцем в области MPP архитектуры для хранилищ данных была Teradata, которая представила первую систему с такой архитектурой в 1984 году. С тех пор Teradata прошла большой путь, накопила массу полезного опыта в этой сфере и заслуженно является лидером. В 2000-х появились решения с подобной архитектурой от других производителей – это EMC Greenplum, HP Vertica, Sybase IQ, IBM Netezza, IBM InfoSphere Warehouse и Microsoft PDW. Следует заметить, что архитектура MPP может существовать в двух качествах – это shared nothing и shared everything. В первом случае, каждый узел не разделяет системные ресурсы с другими узлами, выделяя и используя необходимые ему ресурсы самостоятельно. Во втором случае узел использует разделяемые ресурсы, обращаясь к некоему механизму для получения необходимых ему ресурсов. Каждый подход обладает своими преимуществами и недостатками – shared nothing не позволяет утилизировать все ресурсы достаточно эффективно, оставляя часть из них простаивать в любой случае. Shared everything утилизирует ресурсы более эффективно, однако требует механизм межпроцессного согласования при использовании разделяемых ресурсов, что выливается в дополнительное время, необходимое для такого согласования при выделении ресурсов. В качестве системных ресурсов тут выступают оперативная память и дисковая подсистема. Oracle и Microsoft пошли своим путем, используя архитектуру SMP (Symmetric Multiprocessing) в своих разработках. Данная архитектура характеризуется тем, что с единой базой данных работают несколько процессов. Для повышения скорости доступа к данным Oracle и Microsoft рекомендуют использовать партиционирование, разделяя таблицу на несколько логических секций, и тем самым разделяя данные на более маленькие кусочки. Этот подход помогает, если нам необходимо выбрать небольшую часть данных в таблице, однако неэффективен, если мы должны использовать для анализа бОльшую часть данных, содержащихся в таблице (так называемый Full Scan), что при традиционной для хранилищ данных схеме «звезда» или «снежинка» является неизбежным. Для большого понимания, на каких принципах основано каждое решение, приведу таблицу:
| DWH | SMP | MPP | |
| Shared nothing | Shared everything | ||
| EMC Greenplum | X | ||
| HP Vertica | X | ||
| IBM InfoSphere Warehouse (DB2) | X | ||
| IBM Netezza | X | ||
| Microsoft SQL Server 2008 DBMS R2 BDW | X | ||
| Microsoft SQL Server 2008 DBMS R2 PDW | X | ||
| Microsoft SQL Server 2008 DBMS R2 FTDW | X | ||
| Oracle Exadata | X | ||
| Sybase IQ | X | ||
| Teradata Database 14 | X | ||
Как видно из таблицы, большинство производителей предпочитают использовать более производительный вариант shared nothing, несмотря на то, что он не утилизирует часть системных ресурсов, позволяя им простаивать без дела. Именно архитектура MPP является наиболее подходящей для хранилищ данных, так как предоставляет линейную масштабируемость, позволяя наращивать мощность хранилища данных соответственно постоянно растущим требованиям. Однако для ряда решений, находящихся в правом верхнем секторе магического квадранта Gartner, характерно еще одно свойство, которое помогает увеличить скорость доступа к данным и, соответственно, предоставить их аналитикам настолько быстро, насколько возможно.
Колоночное хранение
Идея хранить данные не по строкам, а по колонкам не нова и принадлежит Sybase, которая выпустила Sybase IQ в 1996 году – первую в мире базу данных, поддерживающую колоночное хранение данных. Основой для этой идеи послужило то, что нагрузка на хранилище данных и оперативные базы данных радикально различается по своему характеру. Если для OLTP систем характерны частые, мелкие транзакции, выполняющие в основном операции добавления или обновления(insert/update), то нагрузка на хранилище данных характеризуется тем, что основными операциями являются чтение больших объемов данных, часто с применением агрегирования. Таким образом, если для OLTP систем хранение построчно является оптимальным, так как при добавлении новой строки нам выгоднее записать её на диск за один проход целиком, то для хранилищ данных такое хранения неэффективно. Например, если у нас данные хранятся построчно, то для таблицы, состоящей из 10 столбцов, при выборке, где будут перечислены всего три столбца, нам придётся прочитать все 10 столбцов, что крайне неэффективно, так как данные из остальных 7 столбцов нам не нужны. В этом же примере, если использовать модель колоночного хранения данных, то данные будут прочитаны только из тех столбцов, которые были перечислены в запросе, уменьшая количество операций чтения в несколько раз. Так как в большинстве запросов, выполняющихся в хранилище данных, применяются всего несколько столбцов из таблицы, то хранения данных в колоночном виде является оптимальным. Крупнейшие игроки на рынке DWH – Oracle, Microsoft и IBM почему-то скромно умалчивают об этом, когда их сравнивают с конкурентами, невнятно обещая поддержку колоночного хранения данных когда-нибудь в будущем. Эта скромность может привести к тому, что решения этих компаний в будущем не будут рассматриваться вовсе. Необходимо также заметить, что решения некоторых компаний, в частности EMC Greenplum и Teradata, поддерживают полиморфную модель хранения данных, т.е. часть данных может храниться в строчном виде, а часть данных в колоночном виде. Это сделано для того, чтобы иметь возможность создавать такие таблицы, где транзакционная нагрузка будет похожа на OLTP, т.е. будет присутствовать много мелких операций «добавления/изменения» данных.
Для того чтобы понять какую модель хранения данных использует каждое решение, приведу таблицу:
| DWH | Row-oriented | Column-oriented |
| EMC Greenplum | X | X |
| HP Vertica | X | |
| IBM InfoSphere Warehouse (DB2) | X | |
| IBM Netezza | X | |
| Microsoft SQL Server 2008 DBMS R2 BDW | X | |
| Microsoft SQL Server 2008 DBMS R2 PDW | X | |
| Microsoft SQL Server 2008 DBMS R2 FTDW | X | |
| Oracle Exadata | X | |
| Sybase IQ 15 | X | |
| Teradata Database 14 | X | X |
Будучи пионерами в области колоночного хранения данных, создатели Sybase IQ использовали идею индексирования данных для обеспечения доступа к ним. Каждая колонка в каждой таблице Sybase IQ должна быть проиндексирована, в противном случае, при выполнении запроса оптимизатор вернет сообщение с ошибкой. В Sybase IQ 15 индекс создается по умолчанию на всю таблицу, это так называемый Fast Projection Default Index. В целом, идея индексирования данных нашла горячую поддержку в сердцах разработчиков Sybase IQ, что выразилось в создании 10 различных типов индексов и рекомендациях использовать их везде и всегда. Рекомендуется создать несколько индексов на таблицу или даже столбец в зависимости от типа и характера данных, а также, принимая во внимания, в каком качестве определенной столбец будет использоваться в запросе, т.е. будет ли он принимать участие в агрегировании с другими столбцами или играть роль предиката. После того, как запросы будут разобраны и необходимые индексы будут созданы, Sybase IQ обещает высокую производительность, как для произвольных запросов, так и запросов, использующих большие объемы данных. Несмотря на некоторые преимущества, предоставляемые таким подходом, Sybase IQ знаменит своей потрясающе медленной загрузкой данных, так как обслуживание большого количества индексов является дорогостоящей операцией.
Дальше всех с идеей колоночного хранения данных пошла HP Vertica, реализовав так называемые проекции (projections), которые представляют собой, если пользоваться терминологией Oracle, материализованные представления, отсортированные по одному или нескольким столбцам. Материализованные представления в HP Vertica, состоящие из одного или нескольких столбцов таблицы, позволяют минимизировать количество операций чтения для запросов, где столбцы, которые нужно прочитать, заранее определены. Проекции, использующиеся в HP Vertica, действительно позволяют добиться более высокой скорости чтения относительно конкурентов, обладая, тем не менее, существенными недостатками – это хранения избыточного объема данных, так как часть столбцов присутствуют в нескольких проекциях одновременно. Неготовность к спонтанным, произвольным запросам, выражающейся в долгом ожидании ответа, не прибавляют решению HP Vertica достоинств. Если быть откровенным, то HP Vertica позволяет добиться хорошей производительности для специфичных запросов только после выяснения всех обстоятельств предстоящей нагрузки и долгой стадии подготовки проекций.
Механизм проекций, эксплуатирующийся в HP Vertica, вынудил создателей этого решения прибегнуть к разработке своеобразного механизма загрузки данных. Прежде всего, надо сказать, что хранение данных в HP Vertica разделено на две области – Write-Optimized Column Store (WOS) и Read-Optimized Column Store (ROS). Перед тем, как данные попадают в ROS они проходят через область WOS, где специальный процесс под названием Tuple Mover отсортировывает данные, сжимает их и помещает в соответствующие проекции в ROS. Непрозрачность этого механизма не дает нам понять, какие данные были загружены, а какие нет. Одним из трюков, которые любят показывать инженеры HP Vertica – это мгновенная загрузка данных, т.е. команда по загрузке нескольких сот гигабайт или нескольких терабайт данных выполняется практически мгновенно – это не так, на самом деле данные сначала попадают в WOS, и только после того, как они будут обработаны процессом Tuple Mover, они будут в области ROS.
Загрузка данных для решений остальных компаний выглядит намного прозаичнее – это механизм параллельной загрузки данных через external tables, позволяющий работать с плоскими файлами, как с обычными таблицами. Такой механизм поддерживают Oracle Exadata, IBM InfoSphere Warehouse, IBM Netezza, EMC Greenplum и Sybase IQ. Самую высокую скорость загрузки данных обеспечивает EMC Greenplum за счет распараллеливания загрузки между всеми логическими узлами хранилища данных, немного отстает от него Oracle Exadata из-за своей SMP архитектуры. Скорость загрузки данных отличается в несколько раз в худшую сторону для тех решений, где нужна предварительная сортировка данных – это IBM Netezza (Zone Maps), дорогостоящие операции с индексами — печально известный Sybase IQ, про IBM DB2 мне, к сожалению, неизвестно.
Microsoft для загрузки данных использует компонент SQL Server-a под названием SQL Server Integration Services (SSIS), который является ни чем иным, как перелицованным, хорошо знакомым многим Data Transformation Services (DTS), существующим в SQL Server с седьмой версии. С помощью этого инструмента, используя графический пользовательский интерфейс и подсказки мастеров, можно создать так называемый «Integration Services Package», который можно использовать в будущем для дальнейшей загрузки данных. Имея опыт использования DTS в Microsoft SQL Server 2000, могу сказать, что стабильность не вызывала никаких проблем (если данные были «чистыми», без мусора), но скорость оставляла желать лучшего.
На фоне конкурентов выгодно отличается набор утилит по загрузке/выгрузке данных, использующийся в Teradata. Объединенные на одной платформе под названием Teradata Parallel Transporter, эти утилиты обладают богатой функциональностью, позволяя загружать/выгружать данные, не блокируя при этом работу пользователей, выполняющих запросы.
Итоги
Gartner расставил производителей в магическом квадранте соответственно их текущему положению на рынке хранилищ данных. Однако это не означает, что в будущем положение лидеров не изменится относительно друг друга. Все решения, находящиеся в секторе лидеров, имеют механизмы обеспечения отказоустойчивости, инструменты для резервного копирования и восстановления, а также поддерживают тот или иной стандарт SQL. Тем не менее, если углубиться в функциональные возможности каждого решения, то выясниться следующее:
HP Vertica не поддерживает хранимых процедур, функций и различных языков
IBM Netezza не поддерживает индексы, что часто приводит к Full Scan, не поддерживает секционирование таблиц, а также обладает медленной скоростью загрузки данных из-за необходимости предварительной сортировки данных
Недостатки других решений упоминались выше. Это не значит, что все эти решения не обладают достоинствами, позволяющими им выполнять функции хранилища данных. Тем не менее, если в будущем производители не решат проблемы, связанные с текущими недостатками этих решений, то они рискуют потерять свое место в секторе лидеров.
Можно выделить две компании, решения которых наиболее соответствуют будущим потребностям рынка хранилищ данных. Это решение от Teradata и EMC Greenplum. MPP архитектура с концепцией shared nothing, полиморфная модель хранения данных (колоночное и строковое хранение данных), а также богатые функциональные возможности помогут сохранить им свои позиции в будущем. Маркетинговая политика, ведущаяся этими компаниями, несколько отличается друг от друга, позволяя существовать на рынке хранилищ данных совместно, при этом устраняя жесткую конкуренцию между решениями.
Teradata продается в виде преднастроенного аппаратно-программного комплекса и по стоимости сравнима с Oracle Exadata, т.е. находится в верхнем ценовом диапазоне. Высокая цена Teradata обусловлена тем, что компания не старается унифицировать свое решение, предлагая свое видение каждому новому заказчику. Не доверяя процесс внедрения сторонним компаниям Teradata до последнего времени разрабатывала и воплощала концепцию хранилища данных для каждого нового клиента самостоятельно, именно поэтому цикл внедрения у Teradata довольно долгий, а цена на обслуживание и поддержку достаточно высока.
EMC Greenplum может поставляться как в виде программного обеспечения, так и в виде преднастроенного аппаратно-программного комплекса, при чем цена этого решения сравнима с HP Vertica и IBM Netezza, но, при этом, Greenplum лишен большой части недостатков, присущих решениями от HP и IBM. Компания EMC, имея широкую сеть партнеров и дистрибьюторов, старается распространять решение Greenplum через них, что позволяет появляться техническим специалистам по этому продукту. Впоследствии, это может привести к тому, что на рынке труда можно будет найти готовых специалистов и тем самым сократить затраты на разработку и поддержку собственного хранилища данных. Также EMC в последнее время следит за областью Big Data, стараясь соответствовать последним тенденциям, а где-то привнести свои собственные – подтверждением этому является событие Data Science Summit 2012, проведенный EMC в Лас-Вегасе. Тем самым EMC пытается привлечь внимание ведущих профессионалов в области Big Data к проблемам, существующим в этой сфере, а также выслушать новые идеи и мысли. Из этого можно сделать вывод, что присутствие и расширение EMC на рынке хранилищ данных – это стратегическая цель для компании, и развитие идей, заложенных в Greenplum, не прекратится в ближайшем будущем. Подводя итог, можно сказать, что Greenplum полностью подходит под требования, предъявляемым к современным хранилищам данных и является одним из лучших решений, наряду с Teradata, оставляя конкурентов далеко позади.
Отчет Gartner о DWH







