Как создать рендерер, который бы работал даже на компьютере вашей бабушки? Изначально перед нами стояла немного другая задача — создать unbiased рендер для всех моделей GPU: NVidia, ATI, Intel.
Хотя идея такого рендера для всех видеокарт витала в воздухе давно, до качественной реализации, тем более на Direct3D, дело не доходило. В своей работе мы пришли к весьма дикой связке и дальше расскажем, что нас к ней привело и как она работает.

О том, что такое unbiased rendering, или рендеринг без допущений, очень хорошо изложил Marchevsky в серии статей
«Трассировка пути на GPU» часть 1, часть 2 и "Unbiased rendering (рендеринг без допущений)".
Вкратце: это рендеринг, который не вносит систематические ошибки в расчет и воспроизводит физически точные эффекты

Ввиду физической достоверности и качества картинки, такой подход заведомо является очень ресурсоёмким. Решить проблему можно путем переноса расчётов на GPU, так как такой подход даёт увеличение скорости расчета до 50‒и раз на каждое GPU устройство.

1200x600 (кликабельно), AMD Radeon HD 6870, render time: 9 min
Существует множество GPGPU платформ (OpenCL, CUDA, FireStream, DirectCompute, C++ AMP, Shaders и др.), но споры об оптимальном выборе идут до сих пор, и однозначного ответа на то, что лучше использовать, нет. Рассмотрим основные аргументы в пользу Direct3D, которые склонили нас к выбору именного этого API:
Из OpenCL и Direct3D мы выбрали то зло, которое, по крайней мере, имеет стабильные драйвера, отточенные десятилетиями игровой индустрии, и имеет лучшую производительность в ряде бенчмарков. Также, исходя из задачи, была отброшена CUDA, несмотря на все инструменты, обильное количество примеров и сильное сообщество разработчиков. C++ AMP в то время еще не был анонсирован, но т.к. его реализация построена поверх DirectX, перенести рендер на него не составит особых проблем.
Связка OpenGL/GLSL также рассматривалась, но быстро была отброшена ввиду ограничений, которые в DirectX решаются с помощью DirectCompute (задачи двунаправленной трассировки пути и пр.).
Так же, отметим ситуацию с GPGPU драйверами потребительского железа, которые выходят с запозданием и долго доводятся до стабильности. Так, при выходе линейки NVIDIA Kepler 600, геймеры сразу получили качественные Direct3D драйверы и более производительные машины для игр, но большая часть GPGPU приложений потеряла свою совместимость или стала менее производительной. Например, Octane Render и Arion Render, построенные на CUDA, начали поддерживать линейку Kepler буквально на днях. К тому же, профессиональное GPGPU железо не всегда оказывается намного лучше в ряде задач, о чем рассказано в статье “NVidia для профессиональных 3D приложений”. Это дает повод собрать рабочую станцию именно на потребительском игровом железе.
Во всех анонсах DirectX 10‒11 пишут о том, что новые модели шейдеров идеально подходят для трассировки лучей и многих других GPGPU задач. Но на деле никто особо не использовал эту возможность. Почему?
Вернемся на год назад. Последнее обновление DX SDK было в июле 2010. Интеграции с VisualStudio нет, сообщества разработчиков GPGPU и качественных примеров нормальных вычислительных задач практически нет. Да что уж там, подсветки синтаксиса шейдеров нет! Вменяемых инструментов дебага тоже нет. PIX не способен выдержать несколько вложенных циклов или шейдер в 400+ строк кода. D3DCompiler мог падать через раз и компилировать сложные шейдеры десятки минут. Ад.
С другой стороны — слабое внедрение технологии. Большинство научных статей и публикаций были написаны, используя CUDA, и заточены под железо NVIDIA. Команда NVIDIA OptiX тоже не особо заинтересована в исследованиях для других вендоров. Немецкая компания mentalimages, которая десятилетиями накапливала опыт и патенты в этой области, теперь так же принадлежит NVIDIA. Все это создает нездоровый перекос в сторону одного вендора, но рынок есть рынок. Для нас это все означало, что все новые GPGPU техники трассировки и рендеринга надо исследовать заново, но только на DirectX и на железе ATI и Intel, что часто приводило к совершенно другим результатам, например на архитектуре VLIW5.
Устраняем проблемы
Перед описанием реализации приведу несколько полезных советов, которые помогли нам в разработке:
Растеризация vs трассировка
Не смотря на то, что используется DirectX, о растеризации речи не идет. Стандартный Pipeline вершинных, Hull, Domain, геометрических и пиксельных шейдеров не используется. Речь идет о трассировке путей света средствами пиксельных и Compute шейдеров. Идея комбинирования растеризации + трассировки, конечно же, возникала, но оказалась очень сложной в реализации. Первое пересечение лучей можно заменить растеризацией, но после этого сгенерировать второстепенные лучи очень непросто. Зачастую оказывалось так, что лучи находились под поверхностью, и результат оказывался неверным. К такому же заключению пришли ребята из Sony Pictures Imageworks, разрабатывающие Arnold Renderer.
Rendering
Существуют два основных подхода организации рендеринга:
Мы остановились на первом варианте с использованием шейдеров для GPGPU, но перед тем как что‒либо рендерить, нужно подготовить геометрию и данные о сцене, правильно разместив их в памяти GPU.
Данные о сцене включают в себя:
Никаких вершинных и индексных буферов при рендере не используется. В Direct3D11 данные унифицированы, все хранится в одинаковом формате, но можно сказать устройству, как на них смотреть: как на Buffer, Texture1D/2D/3D/Array/CUBE, RenderTarget и т.д. Данные, к которым производится более‒менее линейный доступ, лучше хранить в виде Buffer'ов. Данные с хаотичным доступом, например, ускоряющие структуры сцены, лучше хранить в текстуре, т.к. при частых обращениях часть данных закешируется.
Быстроменяющиеся и небольшие куски данных разумно хранить в константных буферах, это параметры камеры, источники освещения и материалы, если их не много и они умещаются в буфер, размером 4096 x float4. При интерактивном рендеринге изменение положения камеры, настройка материалов и света — самая частая операция. Изменение геометрии происходит несколько реже, но константной памяти все равно не хватит, чтобы разместить ее.
Т.к. памяти в GPU относительно мало, нужно использовать умные подходы к ее организации и стараться запаковать все, что только можно запаковать и использовать сжатие данных. Текстуры материалов мы размещаем в многослойном текстурном атласе, т.к. количество текстурных слотов GPU ограничено. Также, в GPU имеются встроенные форматы сжатия текстур – DXT, которые используются для текстурных атласов и могут уменьшить размер текстур до 8‒и раз.
Упаковка текстур в атлас:

В итоге, расположение данных в памяти выглядит так:

Предполагается, что данные света и материалов смогут поместиться в константных регистрах. Но в случае, если сцена достаточно сложная, материалы и свет будут помещены в глобальную память, где для них должно хватить места.

Переходим к рендерингу: в вершинном шейдере рисуем квад, размером с экран, и используем технику маппинга текселей в пикселы, чтобы при растеризации каждый пиксел пиксельного шейдера имел правильные текстурные координаты, а следовательно, правильные значения x и y на экране.

Далее, для каждого пиксела в шейдере производится рассчет алгоритма трассировки пути лучей. Этим способом производятся GPGPU вычисления на пиксельных шейдерах. Такой подход может показаться не самым оптимальным, и более разумно было бы использовать DirectCompute, для которого никаких вершинных шейдеров и скрин‒квада создавать не надо. Но многочисленные тесты показали, что DirectCompute оказывается на 10‒15% медленнее. В задаче трассировки пути все преимущества от использования SharedMemory или использоания пакетов лучей быстро сходят на нет из-за случайно природы алгоритма.
Для рендеринга используются две техники: интерактивный просмотр работает на модифицированной однонаправленной трассировке пути (Path Tracing), а для конечного рендеринга может быть использована двунаправленная трассировка пути (Bidirectional Path Tracing), т.к. ее фреймрейт весьма не интерактивен на сложных сценах. Семплирование методом Metropolis Light Transport пока не используется, т.к. его эффективность еще не оправдалась, о чем говорит один из разработчиков V-Ray на закрытом форуме ChaosGroup:
vlado posted:
Отметим, чем очень хорош unbiased‒рендеринг — он основан на методе Монте‒Карло, а это значит, что в общем случае каждая итерация рендеринга не зависит от предыдущей. Именно это делает данный алгоритм привлекательным для вычислений на GPU, многоядерных системах и кластерах.
Чтобы поддержать железо классов DX10 и DX11 и не переписывать все заново под каждую версию, стоит использовать DirectX11, который с небольшими ограничениями работает на DX10 Железe. Имея поддержку широкого класса железа и предрасположенность алгоритма к распределению, мы сделали Multi‒Device рендеринг, принцип работы которого очень прост: в каждый GPU нужно поместить одинаковые данные, шейдеры и просто собирать результат с каждого GPU по мере его готовности, перезапуская рендеринг при изменениях в сцене. Алгоритм позволяет распределить рендеринг на очень большое количество устройств. Эта концепция замечательно подходит для вычислений в облаках. Но, облачных GPU‒провайдеров не так много, и компьют‒тайм стоит тоже не очень дешево.
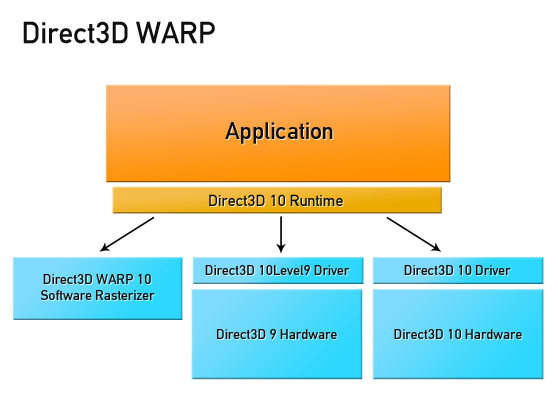
С появление DirectX11 на помощь пришла замечательная технология — WARP (Windows Advanced Rasterization Platform). WARP Device транслирует Ваш GPU код в SSE‒оптимизированный многопоточный код, позволяя производить GPU вычисления на всех ядрах CPU. Причем абсолютно любых CPU: x86, x64 и даже ARM! С точки зрения программирования, такое устройство ничем не отличается от GPU устройства. Именно на основе WARP в C++ AMP реализованы гетерогенные вычисления. WARP Device — тоже ваш бро, используйте WARP Device.
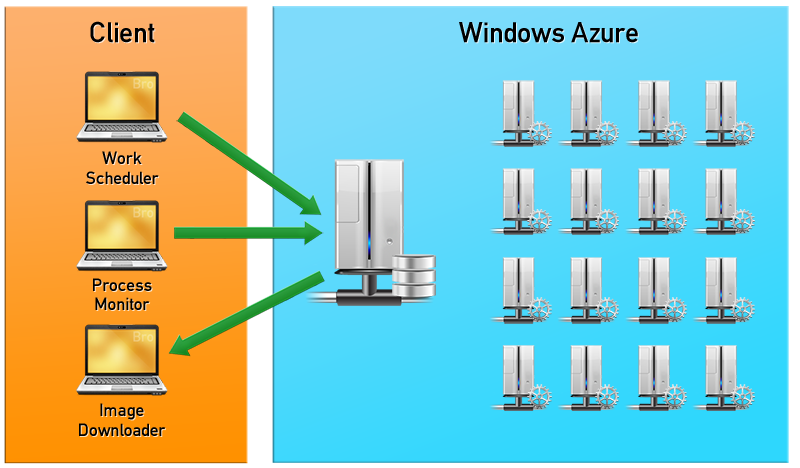
Благодаря этой технологии мы смогли запустить GPU рендеринг в CPU облаке. Немного бесплатного доступа к Windows Azure мы получили через программу BizSpark. Для хранения данных был использован Azure Storage, данные с геометрией сцены и текстурами хранились в “блобах” (Blobs), данные о заданиях рендеринга, закачке и скачке сцен находятся в очередях (Queues). Для обеспечения стабильной работы использовалось три процесса: распределитель задач (Work Scheduler), наблюдатель за процессами (Process Monitor) и процесс, скачивающий отрендеренные изображения (Image Downloader). Work Scheduler ответственен за загрузку данных в блобы и постановку задач. Process Monitor отвечает за поддержание всех воркеров (Worker – вычислительный узел Azure) в рабочем состоянии. Если один из воркеров перестает отвечать, то происходит инициализация нового экземпляра, таким образом, обеспечивается максимальная работоспособность системы. Image Downloader собирает отрисованные куски картинки со всех воркеров и передает готовое или промежуточное изображение клиенту. Как только задача рендеринга выполнилась, Process Monitor ликвидирует образы воркеров, чтобы не было простаивающих ресурсов, за работу которых пришлось бы платить.
Эта схема неплохо работает, и за этим, как нам кажется, будущее рендеринга – Pixar уже осуществляет рендеринг в облаке. Обычно облачная тарификация идет только за скачанный траффик, который состоит из отрендеренных картинок размером не больше нескольких мегабайт. Единственное узкое место такого подхода – канал пользователя. Если вам нужно редерить анимацию с размером асетов в несколько десятков или сотен GB, то у вас проблемы.
Результатом всей этой работы стал плагин RenderBro для Autodesk 3DS Max, который, как и задумывалось, должен рендерить даже на бабушкином компьютере и может использовать любые вычислительные ресурсы.
Сейчас он находится на стадии закрытого альфа тестирования. Если Вы GPU‒энтузист, 3D‒художник, задумали построить ATI/NVIDIA кластер, у Вас куча разных GPU и CPU или любая другая интересная конфигурация, дайте знать, будет интересно вместе поработать. Очень хотелось бы проверить рендер на чем-нибудь вроде этого:

Так же, впереди C++ AMP версия рендера, более серьезные облачные тесты и разработка плагинов для других редакторов. Присоединяйтесь!
Хотя идея такого рендера для всех видеокарт витала в воздухе давно, до качественной реализации, тем более на Direct3D, дело не доходило. В своей работе мы пришли к весьма дикой связке и дальше расскажем, что нас к ней привело и как она работает.

О том, что такое unbiased rendering, или рендеринг без допущений, очень хорошо изложил Marchevsky в серии статей
«Трассировка пути на GPU» часть 1, часть 2 и "Unbiased rendering (рендеринг без допущений)".
Вкратце: это рендеринг, который не вносит систематические ошибки в расчет и воспроизводит физически точные эффекты
- глобальное освещение
- мягкие тени, реалистичные переотражения
- глубину резкости и motion blur
- подповерхностное рассеивание и многое другое

Ввиду физической достоверности и качества картинки, такой подход заведомо является очень ресурсоёмким. Решить проблему можно путем переноса расчётов на GPU, так как такой подход даёт увеличение скорости расчета до 50‒и раз на каждое GPU устройство.

1200x600 (кликабельно), AMD Radeon HD 6870, render time: 9 min
Почему Direct3D
Существует множество GPGPU платформ (OpenCL, CUDA, FireStream, DirectCompute, C++ AMP, Shaders и др.), но споры об оптимальном выборе идут до сих пор, и однозначного ответа на то, что лучше использовать, нет. Рассмотрим основные аргументы в пользу Direct3D, которые склонили нас к выбору именного этого API:
- Работает на всем спектре видеокарт, эмулируется на всех моделях процессоров: один и тот же шейдер работает везде
- Именно спецификации Direct3D задают направление развития потребительского железа
- Всегда первым получает самые свежие и стабльные драйверы
- Остальные кросс‒вендорные технологии не стабильны, либо слабо поддерживаются
Из OpenCL и Direct3D мы выбрали то зло, которое, по крайней мере, имеет стабильные драйвера, отточенные десятилетиями игровой индустрии, и имеет лучшую производительность в ряде бенчмарков. Также, исходя из задачи, была отброшена CUDA, несмотря на все инструменты, обильное количество примеров и сильное сообщество разработчиков. C++ AMP в то время еще не был анонсирован, но т.к. его реализация построена поверх DirectX, перенести рендер на него не составит особых проблем.
Связка OpenGL/GLSL также рассматривалась, но быстро была отброшена ввиду ограничений, которые в DirectX решаются с помощью DirectCompute (задачи двунаправленной трассировки пути и пр.).
Так же, отметим ситуацию с GPGPU драйверами потребительского железа, которые выходят с запозданием и долго доводятся до стабильности. Так, при выходе линейки NVIDIA Kepler 600, геймеры сразу получили качественные Direct3D драйверы и более производительные машины для игр, но большая часть GPGPU приложений потеряла свою совместимость или стала менее производительной. Например, Octane Render и Arion Render, построенные на CUDA, начали поддерживать линейку Kepler буквально на днях. К тому же, профессиональное GPGPU железо не всегда оказывается намного лучше в ряде задач, о чем рассказано в статье “NVidia для профессиональных 3D приложений”. Это дает повод собрать рабочую станцию именно на потребительском игровом железе.
Почему не Direct3D
Во всех анонсах DirectX 10‒11 пишут о том, что новые модели шейдеров идеально подходят для трассировки лучей и многих других GPGPU задач. Но на деле никто особо не использовал эту возможность. Почему?
- Не было инструментов и поддержки
- Исследования сдвинуты в сторону NVIDIA CUDA ввиду сильного маркетинга
- Привязка к одной платформе
Вернемся на год назад. Последнее обновление DX SDK было в июле 2010. Интеграции с VisualStudio нет, сообщества разработчиков GPGPU и качественных примеров нормальных вычислительных задач практически нет. Да что уж там, подсветки синтаксиса шейдеров нет! Вменяемых инструментов дебага тоже нет. PIX не способен выдержать несколько вложенных циклов или шейдер в 400+ строк кода. D3DCompiler мог падать через раз и компилировать сложные шейдеры десятки минут. Ад.
С другой стороны — слабое внедрение технологии. Большинство научных статей и публикаций были написаны, используя CUDA, и заточены под железо NVIDIA. Команда NVIDIA OptiX тоже не особо заинтересована в исследованиях для других вендоров. Немецкая компания mentalimages, которая десятилетиями накапливала опыт и патенты в этой области, теперь так же принадлежит NVIDIA. Все это создает нездоровый перекос в сторону одного вендора, но рынок есть рынок. Для нас это все означало, что все новые GPGPU техники трассировки и рендеринга надо исследовать заново, но только на DirectX и на железе ATI и Intel, что часто приводило к совершенно другим результатам, например на архитектуре VLIW5.
Реализация
Устраняем проблемы
Перед описанием реализации приведу несколько полезных советов, которые помогли нам в разработке:
- По возможности, переходите на VisualStudio2012. Долгожданная интеграция с DirectX, встроенный debug шейдеров, и, о чудо, подсветка синтаксиса HLSL сэкономят вам кучу времени.
- Если VS2012 — не варинат, можно использовать инструменты типа NVidia Parallel Nsight, но опять возникает привязка к одному типу GPU.
- Используйте Windows 8.0 SDK, это ваш бро. Даже если разрабатываете на Windows Vista / 7 и старых версиях VisualStudio, в вашем распоряжении будут последние D3D библиотеки, включая свежий D3DCompiler, который сокращает время компиляции шейдеров в 2‒4 раза и стабильно работает. Для настройки DirectX из Windows 8.0 SDK имеется подробный мануал.
- Если вы все еще используете D3DX, задумайтесь о том, чтобы отказаться от него, это не бро. В Windows 8.0 SDK прекратили его поддержку по весьма понятным причинам.
Растеризация vs трассировка
Не смотря на то, что используется DirectX, о растеризации речи не идет. Стандартный Pipeline вершинных, Hull, Domain, геометрических и пиксельных шейдеров не используется. Речь идет о трассировке путей света средствами пиксельных и Compute шейдеров. Идея комбинирования растеризации + трассировки, конечно же, возникала, но оказалась очень сложной в реализации. Первое пересечение лучей можно заменить растеризацией, но после этого сгенерировать второстепенные лучи очень непросто. Зачастую оказывалось так, что лучи находились под поверхностью, и результат оказывался неверным. К такому же заключению пришли ребята из Sony Pictures Imageworks, разрабатывающие Arnold Renderer.
Rendering
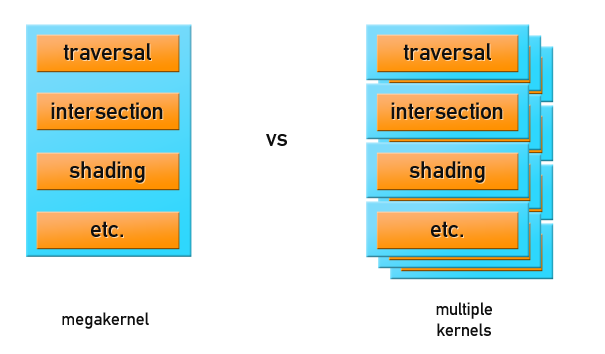
Существуют два основных подхода организации рендеринга:
- Все вычисления происходят в мега-ядре программы GPU, которая ответственна как за трассировку, так и за шейдинг. Это самый быстрый способ рендеринга. Но если сцена не помещается в память GPU, то произойдет либо свопинг сцены, либо приложение сломается.
- Out Of Core Rendering: в GPU передается только геометрия сцены либо ее часть, вместе с буфером лучей для трассировки, и производится многопроходная трассировка лучей. Шейдинг производится либо на CPU, либо еще одним проходом на GPU. Такие подходы не славятся потрясающей производительностью, зато позволяют рендерить сцены продакшн‒размера.
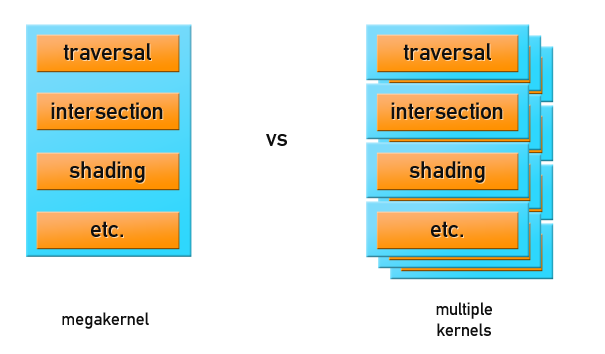
Мы остановились на первом варианте с использованием шейдеров для GPGPU, но перед тем как что‒либо рендерить, нужно подготовить геометрию и данные о сцене, правильно разместив их в памяти GPU.
Данные о сцене включают в себя:
- геометрию (вершины, треугольники, нормали, текстурные координаты)
- ускоряющую структуру (узлы Kd‒дерева или BVH)
- материалы поверхностей (тип, цвета, указатели на текстуры, отражательные экспоненты и многое другое)
- текстуры материалов, карты нормалей и пр.
- источники освещения (сингулярные и протяженные)
- положение и параметры камеры, такие как DOF, FOV и пр.
Никаких вершинных и индексных буферов при рендере не используется. В Direct3D11 данные унифицированы, все хранится в одинаковом формате, но можно сказать устройству, как на них смотреть: как на Buffer, Texture1D/2D/3D/Array/CUBE, RenderTarget и т.д. Данные, к которым производится более‒менее линейный доступ, лучше хранить в виде Buffer'ов. Данные с хаотичным доступом, например, ускоряющие структуры сцены, лучше хранить в текстуре, т.к. при частых обращениях часть данных закешируется.
Быстроменяющиеся и небольшие куски данных разумно хранить в константных буферах, это параметры камеры, источники освещения и материалы, если их не много и они умещаются в буфер, размером 4096 x float4. При интерактивном рендеринге изменение положения камеры, настройка материалов и света — самая частая операция. Изменение геометрии происходит несколько реже, но константной памяти все равно не хватит, чтобы разместить ее.
Т.к. памяти в GPU относительно мало, нужно использовать умные подходы к ее организации и стараться запаковать все, что только можно запаковать и использовать сжатие данных. Текстуры материалов мы размещаем в многослойном текстурном атласе, т.к. количество текстурных слотов GPU ограничено. Также, в GPU имеются встроенные форматы сжатия текстур – DXT, которые используются для текстурных атласов и могут уменьшить размер текстур до 8‒и раз.
Упаковка текстур в атлас:

В итоге, расположение данных в памяти выглядит так:

Предполагается, что данные света и материалов смогут поместиться в константных регистрах. Но в случае, если сцена достаточно сложная, материалы и свет будут помещены в глобальную память, где для них должно хватить места.

Переходим к рендерингу: в вершинном шейдере рисуем квад, размером с экран, и используем технику маппинга текселей в пикселы, чтобы при растеризации каждый пиксел пиксельного шейдера имел правильные текстурные координаты, а следовательно, правильные значения x и y на экране.
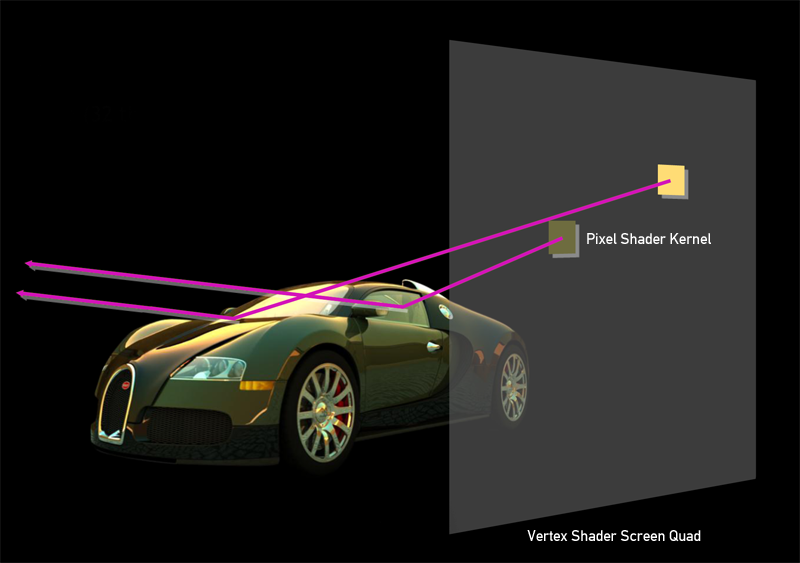
Далее, для каждого пиксела в шейдере производится рассчет алгоритма трассировки пути лучей. Этим способом производятся GPGPU вычисления на пиксельных шейдерах. Такой подход может показаться не самым оптимальным, и более разумно было бы использовать DirectCompute, для которого никаких вершинных шейдеров и скрин‒квада создавать не надо. Но многочисленные тесты показали, что DirectCompute оказывается на 10‒15% медленнее. В задаче трассировки пути все преимущества от использования SharedMemory или использоания пакетов лучей быстро сходят на нет из-за случайно природы алгоритма.
Для рендеринга используются две техники: интерактивный просмотр работает на модифицированной однонаправленной трассировке пути (Path Tracing), а для конечного рендеринга может быть использована двунаправленная трассировка пути (Bidirectional Path Tracing), т.к. ее фреймрейт весьма не интерактивен на сложных сценах. Семплирование методом Metropolis Light Transport пока не используется, т.к. его эффективность еще не оправдалась, о чем говорит один из разработчиков V-Ray на закрытом форуме ChaosGroup:
vlado posted:
“...I came to the conclusion that MLT is way overrated. It can be very useful in some special situations, but for most everyday scenarios, it performs (much) worse than a well-implemented path tracer. This is because MLT cannot take advantage of any sort of sample ordering (e.g. quasi-Monte Carlo sampling, or the Schlick sequence that we use, or N-rooks sampling etc). A MLT renderer must fall back to pure random numbers which greatly increases the noise for many simple scenes (like an open skylight scene).”
Multi‒Core. Multi‒Device. Cloud.
Отметим, чем очень хорош unbiased‒рендеринг — он основан на методе Монте‒Карло, а это значит, что в общем случае каждая итерация рендеринга не зависит от предыдущей. Именно это делает данный алгоритм привлекательным для вычислений на GPU, многоядерных системах и кластерах.
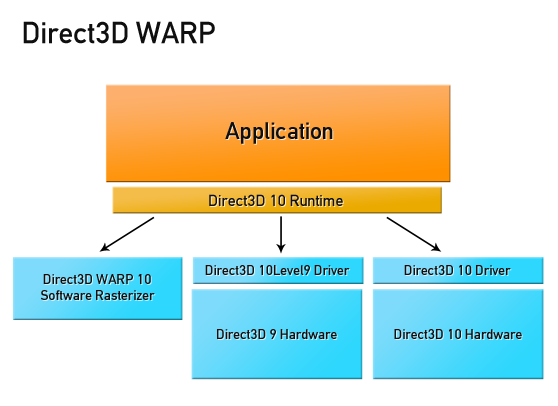
Чтобы поддержать железо классов DX10 и DX11 и не переписывать все заново под каждую версию, стоит использовать DirectX11, который с небольшими ограничениями работает на DX10 Железe. Имея поддержку широкого класса железа и предрасположенность алгоритма к распределению, мы сделали Multi‒Device рендеринг, принцип работы которого очень прост: в каждый GPU нужно поместить одинаковые данные, шейдеры и просто собирать результат с каждого GPU по мере его готовности, перезапуская рендеринг при изменениях в сцене. Алгоритм позволяет распределить рендеринг на очень большое количество устройств. Эта концепция замечательно подходит для вычислений в облаках. Но, облачных GPU‒провайдеров не так много, и компьют‒тайм стоит тоже не очень дешево.
С появление DirectX11 на помощь пришла замечательная технология — WARP (Windows Advanced Rasterization Platform). WARP Device транслирует Ваш GPU код в SSE‒оптимизированный многопоточный код, позволяя производить GPU вычисления на всех ядрах CPU. Причем абсолютно любых CPU: x86, x64 и даже ARM! С точки зрения программирования, такое устройство ничем не отличается от GPU устройства. Именно на основе WARP в C++ AMP реализованы гетерогенные вычисления. WARP Device — тоже ваш бро, используйте WARP Device.
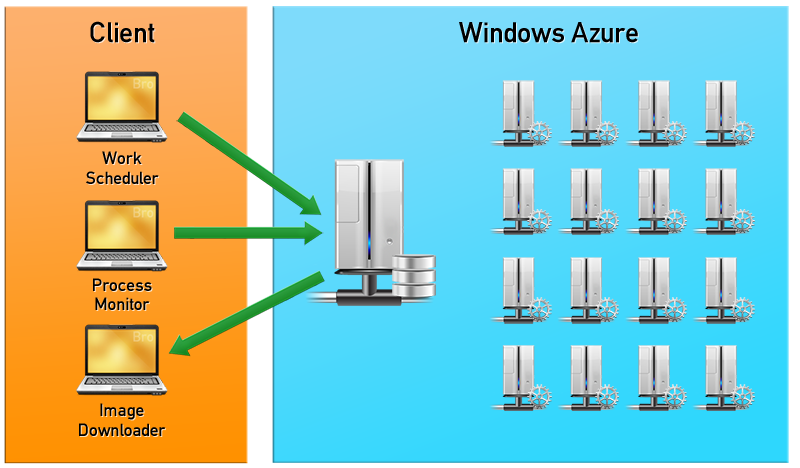
Благодаря этой технологии мы смогли запустить GPU рендеринг в CPU облаке. Немного бесплатного доступа к Windows Azure мы получили через программу BizSpark. Для хранения данных был использован Azure Storage, данные с геометрией сцены и текстурами хранились в “блобах” (Blobs), данные о заданиях рендеринга, закачке и скачке сцен находятся в очередях (Queues). Для обеспечения стабильной работы использовалось три процесса: распределитель задач (Work Scheduler), наблюдатель за процессами (Process Monitor) и процесс, скачивающий отрендеренные изображения (Image Downloader). Work Scheduler ответственен за загрузку данных в блобы и постановку задач. Process Monitor отвечает за поддержание всех воркеров (Worker – вычислительный узел Azure) в рабочем состоянии. Если один из воркеров перестает отвечать, то происходит инициализация нового экземпляра, таким образом, обеспечивается максимальная работоспособность системы. Image Downloader собирает отрисованные куски картинки со всех воркеров и передает готовое или промежуточное изображение клиенту. Как только задача рендеринга выполнилась, Process Monitor ликвидирует образы воркеров, чтобы не было простаивающих ресурсов, за работу которых пришлось бы платить.
Эта схема неплохо работает, и за этим, как нам кажется, будущее рендеринга – Pixar уже осуществляет рендеринг в облаке. Обычно облачная тарификация идет только за скачанный траффик, который состоит из отрендеренных картинок размером не больше нескольких мегабайт. Единственное узкое место такого подхода – канал пользователя. Если вам нужно редерить анимацию с размером асетов в несколько десятков или сотен GB, то у вас проблемы.
Результат
Результатом всей этой работы стал плагин RenderBro для Autodesk 3DS Max, который, как и задумывалось, должен рендерить даже на бабушкином компьютере и может использовать любые вычислительные ресурсы.

Сейчас он находится на стадии закрытого альфа тестирования. Если Вы GPU‒энтузист, 3D‒художник, задумали построить ATI/NVIDIA кластер, у Вас куча разных GPU и CPU или любая другая интересная конфигурация, дайте знать, будет интересно вместе поработать. Очень хотелось бы проверить рендер на чем-нибудь вроде этого:

Так же, впереди C++ AMP версия рендера, более серьезные облачные тесты и разработка плагинов для других редакторов. Присоединяйтесь!







