Комментарии 12
Очень жаль, что вы не попробовали биномиальный метод с большими числами. По идее, производительность по сравнению с решением «большими числами в лоб» могла бы сильно возрасти, при идеальной точности.
НЛО прилетело и опубликовало эту надпись здесь
Ок, спасибо за критику, попробую исправить потом.
По крайней мере другие методы хоть правильно реализованы я надеюсь.
По крайней мере другие методы хоть правильно реализованы я надеюсь.
Кстати, в биномиальной реализации C(n,k) используется не тот алгоритм, что в статье. И он может привести к ненужному переполнению когда 2*k>n.
Если я ничего не перепутал, то биномиальный метод пишется в 10 строчек (без уточнения с сокращением дроби — с ним получается на 8 строк больше).
Если я ничего не перепутал, то биномиальный метод пишется в 10 строчек (без уточнения с сокращением дроби — с ним получается на 8 строк больше).
ulong Multinom(int[] array){
ulong res=1;
int sum=array[0];
for(int i=1;i<array.Length;i++){
for(int j=1;j<=array[i];j++){
res=res*(++sum)/j;
}
}
return res;
}
НЛО прилетело и опубликовало эту надпись здесь
Минус мне. На самом деле я не задумываясь скопировал этот метод вот отсюда: http://blog.plover.com/math/choose.html, как посоветовали в одном из ответов.
Да, этот способ работает, и теперь в основном везде побеждает Binom. Хотя в некоторых случаях все равно мой способ охватывает большие значения (на большом количестве аргументов). Доработаю и обновлю статью потом.
И, по небольшом размышлении, можно обойтись и без сокращения дроби: если у нас long a; int n,k; то достаточно вместо a*n/k написать (a/k)*n+(a%k)*n/k. Ненужного переполнения при этом не случится.
А почему тогда в Math.NET используется способ c LogGamma, а не биномиальный метод? И есть подозрения, что не только там.
В подобных статьях хотелось бы видеть анализ алгоритмов, а не тесты производительности и точности некоторых конкретных реализаций. Представленные вами результаты тестирования не вполне позволяют делать выбор между предложенными алгоритмами в каких-либо других обстоятельствах реализации, при наличии ограничений на ресурсы. Хотелось бы по каждому алгоритму видеть что-то вроде «потребляет памяти О(...) и требует операций О(...)».
Мне кажется, в вашем алгоритме будет лучше раскладывать числа в произведение простых — тогда все промежуточные вычисления можно будет свести к сложению и вычитанию степеней и лишь в самом конце перемножить оставшееся. Мы поймаем переполнение только если сам результат не влазит в размер типа и не будет ошибок округлений. Например,
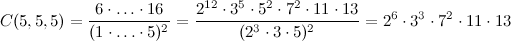
Мне кажется, в вашем алгоритме будет лучше раскладывать числа в произведение простых — тогда все промежуточные вычисления можно будет свести к сложению и вычитанию степеней и лишь в самом конце перемножить оставшееся. Мы поймаем переполнение только если сам результат не влазит в размер типа и не будет ошибок округлений. Например,

Через простые числа, наверное, удобнее всего делать так:
Такой метод удобен тем, что из всех операций с длинными числами в нем есть только умножение на короткое целое число. Поэтому если стоит задача «напечатать результат», а BigInteger в наличии нет, то использовать его — самый быстрый вариант. В других методах пришлось бы добавлять цикл деления. Конечно, это тоже всего несколько строчек, но и они дают лишний шанс ошибиться.
ulong Multinom(int[] arr){
int s=0;
foreach(int a in arr) s+=a;
ulong res=1;
for(int p=2;p<=s;p++){
for(int q=2;q*q<=p;q++) if(p%q==0) goto _cont;
int pow=0;
for(int h=s/p;h!=0;h/=p) pow+=h;
foreach(int a in arr){
for(int h=a/p;h!=0;h/=p) pow-=h;
}
while(pow--!=0) res*=p;
_cont: ;
}
return res;
}
Такой метод удобен тем, что из всех операций с длинными числами в нем есть только умножение на короткое целое число. Поэтому если стоит задача «напечатать результат», а BigInteger в наличии нет, то использовать его — самый быстрый вариант. В других методах пришлось бы добавлять цикл деления. Конечно, это тоже всего несколько строчек, но и они дают лишний шанс ошибиться.
Эта штука очень часто попадается как подзадача в олимпиадном программировании. Но, как заметили выше, метод с подсчётом степеней чисел не применяется, все раскладывают сразу на простые.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Методы вычисления мультиномиальных коэффициентов