Комментарии 40
*на первой картине изображена баба с коромыслом автор — Воснецов…
Дежавю?
Обычно buckets в русскоязычной литературе называют «корзинами», а не «вёдрами».
Увеличивается в два раза при заполнении для амортизации операции выделения памяти, а не потому что в нет массивов с нефиксированным размером.
Если нужна матчасть, гуглите амортизационный анализ.
Если нужна матчасть, гуглите амортизационный анализ.
в C нет массивов*
В реализации по большей части для того, чтобы уменьшить число коллизий и соответственно уменьшить число итераций по сколлайденным бакетам при поиске.
Может расскажете нам про амортизацию выделения памяти под массив для бакетов хэштаблицы? Гугл особо делиться информацией не хочет.
Или Вы имели ввиду, что амортизацией является именно удвоение массива, а не, скажем, инкрементальное увелечение? В таком случае да, я даже не знал что у этого действия есть свое название и как-то глупо было бы увеличивать массив инкрементально, поэтому я не стал вдаваться в детали очевидного решения.
Или Вы имели ввиду, что амортизацией является именно удвоение массива, а не, скажем, инкрементальное увелечение? В таком случае да, я даже не знал что у этого действия есть свое название и как-то глупо было бы увеличивать массив инкрементально, поэтому я не стал вдаваться в детали очевидного решения.
И вообще хотя бы про хэштаблицы — это же совсем базовые вещи. При чём тут вообще PHP?
Что-то вы про классический hash table слишком подробно расписали, а чем PHP-шная реализация отличается от классической не отметили.
Я, например, не понял чем обеспечивается упорядоченность массива после сортировки… pListNext может ссылаться на элемент из другой корзины? Получается, что эффективная итерация в обратном порядке невозможна?
Я, например, не понял чем обеспечивается упорядоченность массива после сортировки… pListNext может ссылаться на элемент из другой корзины? Получается, что эффективная итерация в обратном порядке невозможна?
А, блин. Понял. Тут в одной структуре скрестили практически независимые друг от друга хеш-таблицу (h, pData) и двусвязный список (pListNext, pListLast)…
И почему назвали pListLast а не pListPrev…
Чувствую оверхед на это должен быть приличный (по 3 указателя на каждый элемент против 1 на классическую hash table и 0 для массива). Ну и поиск по числовому индексу в такой структуре происходит через хеш-таблицу тоже, что не очень круто.
Кстати, кто-то объяснит зачем им понадобился именно двусвязный список? Или это исключительно для удаления элементов?
И почему назвали pListLast а не pListPrev…
Чувствую оверхед на это должен быть приличный (по 3 указателя на каждый элемент против 1 на классическую hash table и 0 для массива). Ну и поиск по числовому индексу в такой структуре происходит через хеш-таблицу тоже, что не очень круто.
Кстати, кто-то объяснит зачем им понадобился именно двусвязный список? Или это исключительно для удаления элементов?
pListLast меня тоже сначала смутил… И не понятно зачем нужен pLast (могли бы и односвязным списком для сколлайденых обойтись)
А в чем проблема поиска по числовому индексу через хештаблицу? Он не может быть реализован иначе т.к. массив в пхп это еще и мэп и вы можете использовать не только последовательные ключи.
Двусвязный так же и сортировку упрощает. На самом деле в бакете в пхп, так на память, где-то шесть членов и примерно десять в хештаблице (в структурах), это об экономии памяти.
А в чем проблема поиска по числовому индексу через хештаблицу? Он не может быть реализован иначе т.к. массив в пхп это еще и мэп и вы можете использовать не только последовательные ключи.
Двусвязный так же и сортировку упрощает. На самом деле в бакете в пхп, так на память, где-то шесть членов и примерно десять в хештаблице (в структурах), это об экономии памяти.
Проблема поиска по числовому индексу в том, что это намного медленнее, чем в массивах в более типизированных языках. Я всё думал, может в пхп всё же массивы реализованы в комбинации обычный массив (для целых индексов) + хэш… Но в такой реализации непонятно как реализовать: $m[0] = $m[10000000] = «ok». Всё же надеялся, что светлые умы что-нибудь да придумали)
Для повышения кругозора можете сравнить, как реализуются словари в Python — blip.tv/pycon-us-videos-2009-2010-2011/pycon-2010-the-mighty-dictionary-55-3352147
О, это же Open adressed hash tables en.wikipedia.org/wiki/Open_addressing
Даже не подозревал что они используются. Это и про python 2.7 и про 3.x?
Даже не подозревал что они используются. Это и про python 2.7 и про 3.x?
Я решил не возвращаться к нашему кейсу с ключами 54 и 90… А вообще спасибо, мне нравятся ваши статьи, довольно интересно заглядывать внутрь.
Не очень понял график с памятью. Типа при 4096 элементах памяти требуется дофига, а при 4097 уже с гулькин нос? И вообще научитесь подписывать оси на графике. Это ж технический пост, а не какой-то дешёвый маркетинг.
4096-8191 элементов потребляется одинаковое количество памяти. Графики можете в виде лестницы представить.
А вот вы неправы. Я вчитался в детали и запустил тест. График в статье показывает разницу до и после вставки определённого элемента и падает он не до нуля, а до 132-136. А график кумулятивного потребления памяти выглядел бы так:
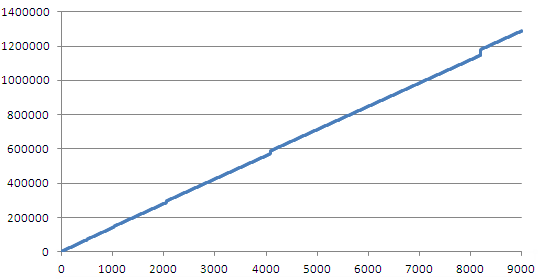
(по вертикали общий объём памяти в байтах)
Заметьте, совсем другая картина: нет никаких ужасающих скачков. Сами корзины едят гораздо больше памяти, чем собственно хэш-таблица.

(по вертикали общий объём памяти в байтах)
Заметьте, совсем другая картина: нет никаких ужасающих скачков. Сами корзины едят гораздо больше памяти, чем собственно хэш-таблица.
Интересно ещё представить график в другом виде, как я это делал в своей недавней статье:
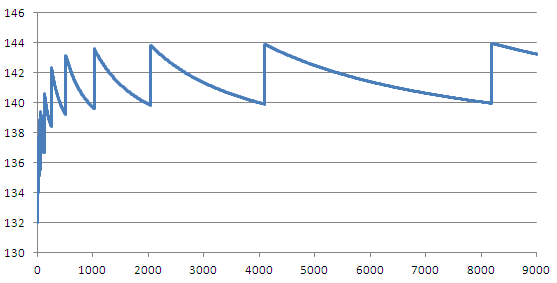
По вертикали отношение используемой памяти в байтах к числу элементов в массиве, то есть количество байт на элемент. Тестировалось на PHP 5.3.2-1ubuntu4.14 (i686).
Видно, что в пределе расширение хэш-таблицы вызывает прыжки на 4 байта, со 140 до 144, вызывая трёхпроцентные колебания вокруг общего среднего. Кстати, интересен вопрос, почему у маленьких таблиц затраты на запись от 132, а дальше нижний порог доходит до 140.

По вертикали отношение используемой памяти в байтах к числу элементов в массиве, то есть количество байт на элемент. Тестировалось на PHP 5.3.2-1ubuntu4.14 (i686).
Видно, что в пределе расширение хэш-таблицы вызывает прыжки на 4 байта, со 140 до 144, вызывая трёхпроцентные колебания вокруг общего среднего. Кстати, интересен вопрос, почему у маленьких таблиц затраты на запись от 132, а дальше нижний порог доходит до 140.
Да, простите за хреновые графики. Просто так долго искал тулзу, которая способна построить график по, хотя бы, 1000 точек (тобишь не юзает гугловские чарты, которые вываливаются в 400 из-за длинных урлов), что терпения уже еле хватало на детали.
Кстати если кто-нибудь подскажет действительно хорошую тулзу для чартов, буду признателен.
Кстати если кто-нибудь подскажет действительно хорошую тулзу для чартов, буду признателен.
Я использую неправославный Excel, но вообще люди любят gnuplot.
Асимптотика O(1) при работе с массивами радует.
Когда читаю книги о том же PHP, всегда, когда сталкивался вновь с теми же массивами (циклы, функции и тп.), хотелось видеть не только описание на примере, но также пару строк о том, где эти массивы применяются при разработке приложений. Ведь, легче разобраться в том, что понятно, как и где это можно будет применить на практике.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Как устроены массивы в PHP