Современные подходы к разработке программного обеспечения делают большой упор на контроль качества. Теперь недостаточно, как раньше, просто писать код, нужно убедиться в том, что этот код правильно написан.
Уже сложно найти проект, в котором отсутствуют юнит-тесты. Их использование многим кажется избыточным, ведь это трата времени, которое с тем же успехом можно потратить на написание другого кода и “не, ну я точно знаю, что там все правильно”. Но, как мы убеждаемся, в долгосрочной перспективе тесты экономят больше времени, чем отнимают. Облегчается сопровождение кода, рефакторинг становится безопасным, отслеживается правильность любых изменений. Причем, чем выше покрытие — тем сильнее чувствуется полезность тестов.
Соответственно, важным моментом является анализ этого самого покрытия, причем желательно построчно, чтобы видеть, какие участки кода не тестируются и иметь возможность быстро исправлять ситуацию.
Проводить подробный анализ покрытия нам помогает инструмент OpenCover. Он работает с кодом на C#. Это замечательное опенсорсное решение, исходники доступны на гитхабе. Документации не особо много, но вполне хватает.
Итак, чтобы начать пользоваться OpenCover, достаточно скачать исходники и собрать, используя Visual Studio. OpenCover являет собой консольное приложение, все необходимые опции задаются параметрами командной строки, так что прикрутить к любому сборщику, будь то MsBuild, Nant, Rake или что либо другое, не проблема.
Интересен механизм работы — OpenCover запускается вместе с прогоном юнит-тестов. Если быть точным, команда на запуск тестов передается ему в качестве нескольких параметров.(Если в аргументе есть пробелы, то он берется в кавычки полностью, например “-target:%application%”):
Кроме того, у OpenCover есть еще аргументы, регулирующие непосредственно его работу. Приведу только те, которые использую сам, остальные можно найти тут
Итак, нам удалось настроить и запустить OpenCover и мы даже получили отчет в формате xml на много тысяч строк, который содержит очень подробные сведения о покрытии нашего кода. Однако есть проблема — он абсолютно нечитабелен. А хочется наглядно увидеть, что и как покрыто.
Благо, сам автор OpenCover подсказывает нам решение — инструмент под названием ReportGenerator. Он опенсорсный, так что качаем исходники, собираем, получаем исполняемый файл и вперед. В использовании ReportGenerator очень прост. Это также консольное приложение, принимающее несколько параметров. Приведу те, которые мы используем, более полную инструкцию можно найти на странице проекта.
Получаем вот-такие отчеты: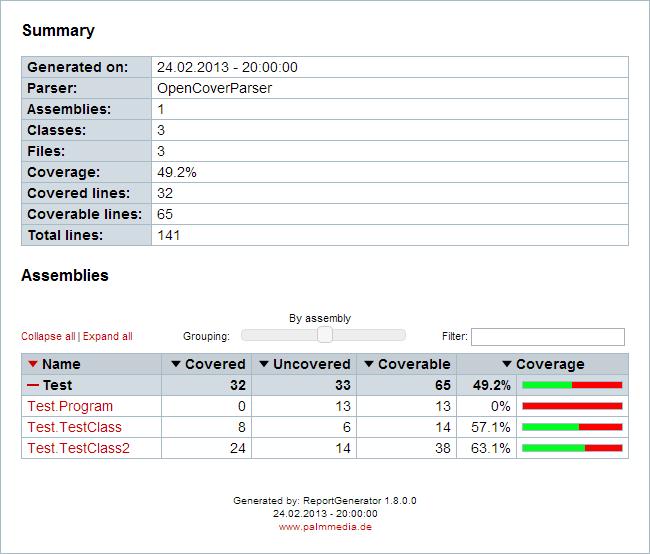

Начало положено, покрытие кода анализируется. Дальше — на ваше усмотрение. Я, например, настроил нашу систему Continuous Integration таким образом, чтобы при покрытии ниже требуемого билд падал. Учитывая строгое отношение к завалившимся билдам, неплохо обеспечивает стабильное написание юнит-тестов :)
Уже сложно найти проект, в котором отсутствуют юнит-тесты. Их использование многим кажется избыточным, ведь это трата времени, которое с тем же успехом можно потратить на написание другого кода и “не, ну я точно знаю, что там все правильно”. Но, как мы убеждаемся, в долгосрочной перспективе тесты экономят больше времени, чем отнимают. Облегчается сопровождение кода, рефакторинг становится безопасным, отслеживается правильность любых изменений. Причем, чем выше покрытие — тем сильнее чувствуется полезность тестов.
Соответственно, важным моментом является анализ этого самого покрытия, причем желательно построчно, чтобы видеть, какие участки кода не тестируются и иметь возможность быстро исправлять ситуацию.
Проводить подробный анализ покрытия нам помогает инструмент OpenCover. Он работает с кодом на C#. Это замечательное опенсорсное решение, исходники доступны на гитхабе. Документации не особо много, но вполне хватает.
Итак, чтобы начать пользоваться OpenCover, достаточно скачать исходники и собрать, используя Visual Studio. OpenCover являет собой консольное приложение, все необходимые опции задаются параметрами командной строки, так что прикрутить к любому сборщику, будь то MsBuild, Nant, Rake или что либо другое, не проблема.
Интересен механизм работы — OpenCover запускается вместе с прогоном юнит-тестов. Если быть точным, команда на запуск тестов передается ему в качестве нескольких параметров.(Если в аргументе есть пробелы, то он берется в кавычки полностью, например “-target:%application%”):
- -target:%application% — приложение, которое нужно запустить (В нашем случае — Gallio.Echo, как более распространенный пример — nunit-console). Важное замечание — путь к приложению должен быть абсолютным, так как мы передаем его в качестве параметра, и в переменной Path он искаться не будет.
- -targetdir:%path% — папка, в которой нужно запустить %application%
- -targetargs:%args% — параметры, передаваемые %application%
Кроме того, у OpenCover есть еще аргументы, регулирующие непосредственно его работу. Приведу только те, которые использую сам, остальные можно найти тут
- -output:%path% — указывает, куда поместить отчет
- -filter:%filters% — Определяет, что учитывать при анализе. Фильтры имеют формат +[%assembly%]%type% для включаемых сборок/типов и то же самое, но со знаком минус в начале для исключаемых. Фильтров может быть множество, разделяются пробелами, в таком случае аргумент заключается в кавычки. Исключающие фильтры имеют приоритет над включающими.
- -register — Динамическая регистрация сборки OpenCover.Profiler, необходимо для работы приложения. Можно опустить, если предварительно зарегестрировать вручную с помощью regsvr32.exe. Если у текущего пользователя нет прав админа, нужно использовать -register:user
- -returntargetcode — Указывает, что нужно возвращать errorlevel, полученный приложением, указаным в параметре -target. Если опустить этот параметр и, например, у вас упадет какой-то тест, то приложение не остановит работу. Необходим, если вы используете анализ покрытия в контексте Continuous Integration, так как можно без проблем совместить анализ с обычным прогоном юнит-тестов и избежать их повторного запуска.
Итак, нам удалось настроить и запустить OpenCover и мы даже получили отчет в формате xml на много тысяч строк, который содержит очень подробные сведения о покрытии нашего кода. Однако есть проблема — он абсолютно нечитабелен. А хочется наглядно увидеть, что и как покрыто.
Благо, сам автор OpenCover подсказывает нам решение — инструмент под названием ReportGenerator. Он опенсорсный, так что качаем исходники, собираем, получаем исполняемый файл и вперед. В использовании ReportGenerator очень прост. Это также консольное приложение, принимающее несколько параметров. Приведу те, которые мы используем, более полную инструкцию можно найти на странице проекта.
- -reports:%reports% — Исходные файлы отчетов, если их несколько, разделяем точкой с запятой
- -targetdir:%path% — Указывает, куда поместить сгенерированые отчеты
- -reporttypes:%types% — Типы генерируемых отчетов. Мы используем -reporttypes:Html, нам хватает.
Получаем вот-такие отчеты:
Начало положено, покрытие кода анализируется. Дальше — на ваше усмотрение. Я, например, настроил нашу систему Continuous Integration таким образом, чтобы при покрытии ниже требуемого билд падал. Учитывая строгое отношение к завалившимся билдам, неплохо обеспечивает стабильное написание юнит-тестов :)








