В сети любого большого content/eyeball провайдера возникает необходимость управления трафиком. И чем больше сеть, тем острее эта необходимость ощущается. В этой статье я попытаюсь описать основной принцип управления трафиком в сети компании, непосредственное отношение к которой я имею. Сразу оговорюсь, что в этой статье упоминается множество торговых марок, терминов и «жаргона». Здесь не будет ни примеров конфигурации роутеров, ни описания этих самых терминов.
Мы привыкли считать, что транспортная MPLS-сеть необходима, в основном, для applications, которых существует множество: L3VPN, L2VPN/VPLS, и т.д. О Traffic Enigineer'инге в сетях MPLS вспоминают или от «хорошей» жизни, или, скорее, теоретически.
Также принято считать, что backup capacity — это роскошь и, как правило, кариеры/транспортники биллят за backup-порт также, как за обычный. Назревает резонный вопрос: зачем покупать капасити, которые будет просто простаивать и, возможно, несколько раз в месяц на короткое время использоваться? Но, с другой стороны, говорить о том, что «backup'ы для трусов» тоже нельзя, backup'ная емкость должна быть. Как же быть? Об этом и пойдет речь в статье.
Собственные пиринговые сети — это явление в наши дни довольно частое. Очевидно, что свой трафик, который ходит по пиринговой сети гораздо дешевле трафика, который уходит в сеть кариера. Также, как правило, кариеры продают порты с коммитом в 50% от максимальной утилизации линка (10GE линк с коммитом всего 5Gbps), таким образом, можно предполагать, что в любом момент времени у нас есть запасное капасити для нашей пиринговой сети. Зачастую кариеры используют 95% percentile для билинга трафика и выставления счёта, т.е. другими словами, 36 часов в месяц мы можем смело использовать того или иного кариера бесплатно, с остальное же время месяца пуская в него трафик в пределах оговоренного коммита.
Но как же сделать так, чтобы максимально исключить ручное вмешательство, второпях что-то где-то не отдепиривать, быстро принимать какие-то решения (которые не всегда правильные). Ведь потери и перегруженные каналы видны сразу, а для принятия решение нужно время. Как построить минимальную по стоимости пиринговую сеть, чтобы максимально защитить от congestion'а имеющейся трафик, бегающий по сети в данный (пиковый, в особенности) момент времени?
Рассмотрим простейшую пиринговую сеть хостинговой компании:
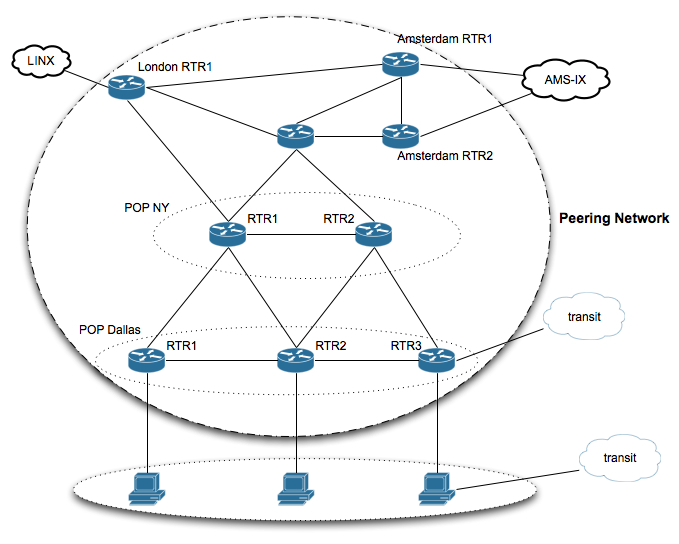
Несколько Point of Presence (POP), линки внутри POP условно-бесплатные, а вот за domestic/transatlantic линки нужно платить. И чем больше мы утилизируем эти линки, тем себестоимость этих самых линков становится ниже. Другими словами, цена трафика обратно пропорциональна загруженности линка.
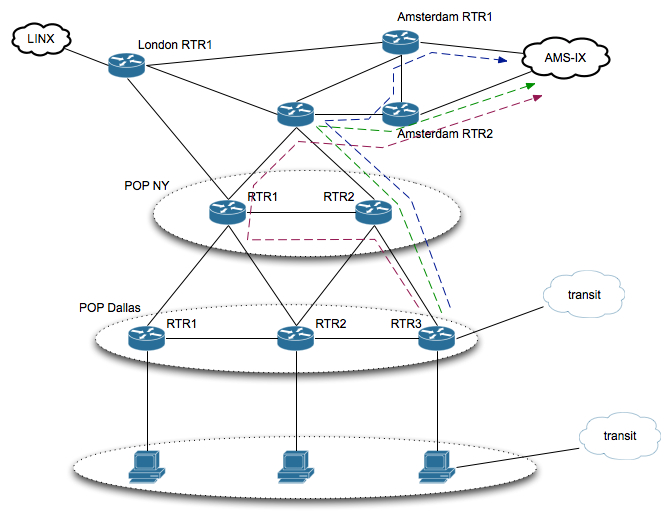
Как видно, из POP Далласа в AMS-IX можно попасть множеством различных маршрутов. Казалось бы, что может быть проще, указывай соответствующие метрики интерфейсов и IGP для тебя всё сделает сам, но не всё так просто. Всё работает отлично, пока не случается авария на пути. Существует несколько способов построения сети. Первый, самый простой и надежный, но далеко не самый дешевый — держать загрузку транспортных линков примерно 50% (как это делает, например, транзитный кариер). Таким образом, выход из строя одного из двух линков сети, не влечет за собой деградацию качества сервиса, даже в пиковое время. Но в самом начале мы договорились, что нас интересует сеть дешевая, построенная скорее не по книжкам, а удовлетворяющая текущим запросам рынка. Выкидывать на ветер половину емкости могут позволить себе далеко не все. Второй способ — ручной: 24х7 NOC, который будет управлять трафиком в ручном режиме в зависимости от оповещений мониторинга. Но какой способ дешевле и/или качественнее, первый или второй, мы оставим на рассуждение читателя.
Что же предлагаем мы? Мы предлагаем построить сеть MPLS, протоколом транспортных распространения меток которой является RSVP-TE, т.е. из любой точки PE-А в любую точку PE-В сети можно попасть, используя Label Switching Path (LSP), сигнальным протоколом которого является RSVP. Соответственно, никого LDP и уж тем более IP трафика вне RSVP LSP по сети не бегает. Полдела сделали. Но в чём принципиальное отличие от сотен таких же сетей? Всё верно, отличия пока нет. Теперь мы заставим наши RSVP Tunnels резервировать Bandwidth вдоль всего LSP на каждом линке пути.
Здесь нужно остановиться и поподробнее объяснить что имеется ввиду. Само резервирование, в данном случае, условное. Каждый LSP обладает рядом свойств, в том числе и Requested Bandwidth. RSVP Path message, передаваемое от роутера к роутеру, резервирует необходимую ёмкость, которая нужна данному конкретному LSP. Если же условие выполнено и на текущем линке есть достаточно капасити, то Path message передаётся дальше к downstream router пока не достигнет egress router PE. В конечном итоге, если LSP таки установлено, то мы уверены, что необходимое капасити вдоль всего участка пути есть в наличии в данный конкретный момент времени.
При этом, мы заставим RSVP tunnels искать себе пути сами сами, опираясь на небольшие направляющие (ERO, setup/hold priority, link colors и тд). Чтобы наши LSP не становились слишком «жирными», мы будем примерно ограничивать LSP в пределах 1-2Gbps, т.е. мапить в этот туннель примерно ~1Gbps трафика. Это занятие мы предоставим нашим BGP RR'ам. Маппинг происходит простым способом: bgp next-hop reachability. Согласно первому пункту BGP best path selection algorithm, bgp prefix считается валидным, если валиден next-hop этого самого маршрута. Поднялся RSVP-туннель — bgp next-hop доступен, маршрут через AMS-IX, в данном случае, также доступен. Важно заметить, что эти самые bgp next-hops, которые появляются в нашем RIB/FIB при поднятии MPLS Tunnel не переносятся нашим IGP. Это ключевой момент.
Предположим, наша сеть построена. В час пик у нас на каждом транспортном линке между POP ~9Gbps. На текущий момент мы построили сеть, фактически, ничем не отличающуюся от вышеизложенной IGP-сети.
Но вот теперь и начинается самое основное. Один или несколько из наших транспортных линков падают из-за аварии.
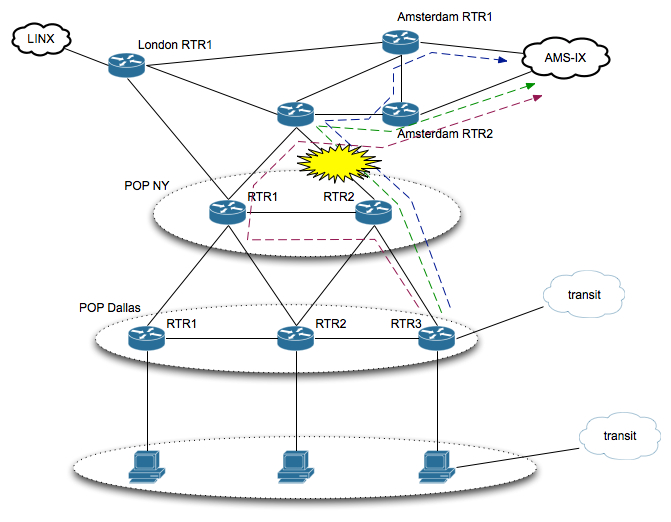
В случае с IGP, трафик смаршрутизировался бы через NY RTR1 и на 10GE стыке между POPs NY и следующим роутером на пути к Amsterdam RTR1 у нас получился бы жуткий congestion (в 10GE линк попыталось бы влезь одновременно почти 20Gbps) и куча жалоб клиентов. Что же c нашими туннелями? Те туннели, который находились на этом линке начинают активно искать себе альтернативные маршруты с достаточным capacity на всем пути. Но если таких маршрутов согласно Traffic Engineering Database (TED) нет? Те туннели, которые не нашли себе маршрута остаются в down до тех пор, пока не будет достаточно капасити. Но куда же девать этот трафик, который раньше шел по этим туннелям? Как мы уже договорились ранее, направления (per AS-PATH basis) мапятся в туннель, bgp next-hop которого поднимается этим самым туннелем. Другими словами, на нашем PE Dallas RTR3 bgp best стали те маршруты, которые пришли к нам от транзитного кариера и лишний трафик автоматически развернулся в транзит (зеленый LSP).

Наш трафик там будет оставаться до тех пор, пока либо не поднимется наш упавший линк, либо не освободиться достаточно капасити на всём протяженности пути к конечному PE.
В таком случае, возразит читатель, к каждому PE в схеме должен быть подключен отдельный кариер(ы). Это не совсем так. Нас интересует backup, а если так, то вендоры уже давно позаботились и придумали для нас BGP best external (Cisco и Juniper поддерживают это). Но много ручной работы с RSVP! Это опять же не так, к нам на помощь приходят RSVP automatic mesh на тех PE, в которых количество трафика незначительно. Фактически, из рутинной работы в нашей сети остаётся только мониторинг за количеством трафика, который мапится в тот или иной LSP и выравнивании его в пределах оговоренной нормы. Чтобы наша сеть отражала реальную картину (мы договорились, никакого LDP и/или IP-трафика), мы используем Autobandwidth на всех туннелях RSVP. Эта особенность есть как у Cisco, так и у Juniper.
На выходе мы получили сеть, которая одновременно и качественна и не дорогая. Таким образом, мы экономим не только свои деньги, но и деньги клиентам, которым не нужно платить двойную цену за наличие простаивающего резервного capacity.
Мы привыкли считать, что транспортная MPLS-сеть необходима, в основном, для applications, которых существует множество: L3VPN, L2VPN/VPLS, и т.д. О Traffic Enigineer'инге в сетях MPLS вспоминают или от «хорошей» жизни, или, скорее, теоретически.
Также принято считать, что backup capacity — это роскошь и, как правило, кариеры/транспортники биллят за backup-порт также, как за обычный. Назревает резонный вопрос: зачем покупать капасити, которые будет просто простаивать и, возможно, несколько раз в месяц на короткое время использоваться? Но, с другой стороны, говорить о том, что «backup'ы для трусов» тоже нельзя, backup'ная емкость должна быть. Как же быть? Об этом и пойдет речь в статье.
Собственные пиринговые сети — это явление в наши дни довольно частое. Очевидно, что свой трафик, который ходит по пиринговой сети гораздо дешевле трафика, который уходит в сеть кариера. Также, как правило, кариеры продают порты с коммитом в 50% от максимальной утилизации линка (10GE линк с коммитом всего 5Gbps), таким образом, можно предполагать, что в любом момент времени у нас есть запасное капасити для нашей пиринговой сети. Зачастую кариеры используют 95% percentile для билинга трафика и выставления счёта, т.е. другими словами, 36 часов в месяц мы можем смело использовать того или иного кариера бесплатно, с остальное же время месяца пуская в него трафик в пределах оговоренного коммита.
Но как же сделать так, чтобы максимально исключить ручное вмешательство, второпях что-то где-то не отдепиривать, быстро принимать какие-то решения (которые не всегда правильные). Ведь потери и перегруженные каналы видны сразу, а для принятия решение нужно время. Как построить минимальную по стоимости пиринговую сеть, чтобы максимально защитить от congestion'а имеющейся трафик, бегающий по сети в данный (пиковый, в особенности) момент времени?
Рассмотрим простейшую пиринговую сеть хостинговой компании:

Несколько Point of Presence (POP), линки внутри POP условно-бесплатные, а вот за domestic/transatlantic линки нужно платить. И чем больше мы утилизируем эти линки, тем себестоимость этих самых линков становится ниже. Другими словами, цена трафика обратно пропорциональна загруженности линка.

Как видно, из POP Далласа в AMS-IX можно попасть множеством различных маршрутов. Казалось бы, что может быть проще, указывай соответствующие метрики интерфейсов и IGP для тебя всё сделает сам, но не всё так просто. Всё работает отлично, пока не случается авария на пути. Существует несколько способов построения сети. Первый, самый простой и надежный, но далеко не самый дешевый — держать загрузку транспортных линков примерно 50% (как это делает, например, транзитный кариер). Таким образом, выход из строя одного из двух линков сети, не влечет за собой деградацию качества сервиса, даже в пиковое время. Но в самом начале мы договорились, что нас интересует сеть дешевая, построенная скорее не по книжкам, а удовлетворяющая текущим запросам рынка. Выкидывать на ветер половину емкости могут позволить себе далеко не все. Второй способ — ручной: 24х7 NOC, который будет управлять трафиком в ручном режиме в зависимости от оповещений мониторинга. Но какой способ дешевле и/или качественнее, первый или второй, мы оставим на рассуждение читателя.
Что же предлагаем мы? Мы предлагаем построить сеть MPLS, протоколом транспортных распространения меток которой является RSVP-TE, т.е. из любой точки PE-А в любую точку PE-В сети можно попасть, используя Label Switching Path (LSP), сигнальным протоколом которого является RSVP. Соответственно, никого LDP и уж тем более IP трафика вне RSVP LSP по сети не бегает. Полдела сделали. Но в чём принципиальное отличие от сотен таких же сетей? Всё верно, отличия пока нет. Теперь мы заставим наши RSVP Tunnels резервировать Bandwidth вдоль всего LSP на каждом линке пути.
Здесь нужно остановиться и поподробнее объяснить что имеется ввиду. Само резервирование, в данном случае, условное. Каждый LSP обладает рядом свойств, в том числе и Requested Bandwidth. RSVP Path message, передаваемое от роутера к роутеру, резервирует необходимую ёмкость, которая нужна данному конкретному LSP. Если же условие выполнено и на текущем линке есть достаточно капасити, то Path message передаётся дальше к downstream router пока не достигнет egress router PE. В конечном итоге, если LSP таки установлено, то мы уверены, что необходимое капасити вдоль всего участка пути есть в наличии в данный конкретный момент времени.
При этом, мы заставим RSVP tunnels искать себе пути сами сами, опираясь на небольшие направляющие (ERO, setup/hold priority, link colors и тд). Чтобы наши LSP не становились слишком «жирными», мы будем примерно ограничивать LSP в пределах 1-2Gbps, т.е. мапить в этот туннель примерно ~1Gbps трафика. Это занятие мы предоставим нашим BGP RR'ам. Маппинг происходит простым способом: bgp next-hop reachability. Согласно первому пункту BGP best path selection algorithm, bgp prefix считается валидным, если валиден next-hop этого самого маршрута. Поднялся RSVP-туннель — bgp next-hop доступен, маршрут через AMS-IX, в данном случае, также доступен. Важно заметить, что эти самые bgp next-hops, которые появляются в нашем RIB/FIB при поднятии MPLS Tunnel не переносятся нашим IGP. Это ключевой момент.
Предположим, наша сеть построена. В час пик у нас на каждом транспортном линке между POP ~9Gbps. На текущий момент мы построили сеть, фактически, ничем не отличающуюся от вышеизложенной IGP-сети.
Но вот теперь и начинается самое основное. Один или несколько из наших транспортных линков падают из-за аварии.

В случае с IGP, трафик смаршрутизировался бы через NY RTR1 и на 10GE стыке между POPs NY и следующим роутером на пути к Amsterdam RTR1 у нас получился бы жуткий congestion (в 10GE линк попыталось бы влезь одновременно почти 20Gbps) и куча жалоб клиентов. Что же c нашими туннелями? Те туннели, который находились на этом линке начинают активно искать себе альтернативные маршруты с достаточным capacity на всем пути. Но если таких маршрутов согласно Traffic Engineering Database (TED) нет? Те туннели, которые не нашли себе маршрута остаются в down до тех пор, пока не будет достаточно капасити. Но куда же девать этот трафик, который раньше шел по этим туннелям? Как мы уже договорились ранее, направления (per AS-PATH basis) мапятся в туннель, bgp next-hop которого поднимается этим самым туннелем. Другими словами, на нашем PE Dallas RTR3 bgp best стали те маршруты, которые пришли к нам от транзитного кариера и лишний трафик автоматически развернулся в транзит (зеленый LSP).

Наш трафик там будет оставаться до тех пор, пока либо не поднимется наш упавший линк, либо не освободиться достаточно капасити на всём протяженности пути к конечному PE.
В таком случае, возразит читатель, к каждому PE в схеме должен быть подключен отдельный кариер(ы). Это не совсем так. Нас интересует backup, а если так, то вендоры уже давно позаботились и придумали для нас BGP best external (Cisco и Juniper поддерживают это). Но много ручной работы с RSVP! Это опять же не так, к нам на помощь приходят RSVP automatic mesh на тех PE, в которых количество трафика незначительно. Фактически, из рутинной работы в нашей сети остаётся только мониторинг за количеством трафика, который мапится в тот или иной LSP и выравнивании его в пределах оговоренной нормы. Чтобы наша сеть отражала реальную картину (мы договорились, никакого LDP и/или IP-трафика), мы используем Autobandwidth на всех туннелях RSVP. Эта особенность есть как у Cisco, так и у Juniper.
На выходе мы получили сеть, которая одновременно и качественна и не дорогая. Таким образом, мы экономим не только свои деньги, но и деньги клиентам, которым не нужно платить двойную цену за наличие простаивающего резервного capacity.







