В предыдущей статье я уже обозначил основные направления решения задачи холодного старта в рекомендательной системе веб-страниц. Напомню, что проблема холодного старта делится на холодный старт для пользователей (что показывать новым пользователям) и холодный старт для сайтов (кому рекомендовать вновь добавленные сайты). Сегодня я более подробно остановлюсь на методе семантического анализа текстов (text mining) как основном подходе к решению проблемы холодного старта для новых сайтов.
Как мы уже обсуждали, предварительная обработка текста веб-страницы заключается в выделении полезного контента страницы, отброса стоп-слов и лемматизации. Этот стандартный «джентльменский» набор так или иначе появляется почти во всех задачах text mining, и его можно найти во многих уже готовых программных решениях, подобрав то, что нужно для вашей конкретной прикладной задачи и среды разработки.
Итак, первым шагом в предварительной обработке текстов является построение словаря всех различных слов W, встречающихся в корпусе текстов D, и подсчёт статистики встречаемости этих слов в каждом из документов. Сразу обращу внимание, что все описанные в этой статье методы будут опираться на модель «мешка слов», когда порядок следования слов в тексте не учитывается. Контекст слова может быть учтён на этапе лемматизации. Например, в предложении «мы ели землянику, а вдоль опушки росли раскидистые ели», слово «ели» в первом случае нужно лемматизировать как «есть», а во втором — как «ель». Однако учтите, что поддержка контекста при лемматизации — это сложная задача natural language processing, далеко не все лемматизаторы к этому готовы. При дальнейшем же анализе порядок слов не будет учитываться вовсе.
Следующим шагом в обработке текстов является расчет весов TF-IDF для каждого слова w в каждом документе d:
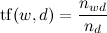
где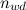 — число вхождений слова в документ,
— число вхождений слова в документ, 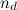 — общее число слов в данном тексте;
— общее число слов в данном тексте;
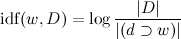 ,
,
где |D| — число текстов в корпусе, а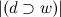 — число текстов, в которых встречается w. Теперь
— число текстов, в которых встречается w. Теперь
 .
.
Или несколько усложненный вариант:
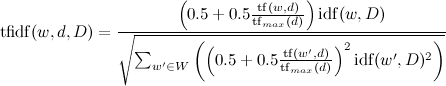 ,
,
где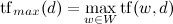 .
.
Веса TF-IDF нужны для достижения двух целей. Во-первых, для слишком длинных текстов отбираются только слова с максимальным TF-IDF, а остальные отбрасываются, что позволяет сократить объём хранимых данных. Например, для методов relevance feedback и LDA, которые будут описаны ниже, нам было достаточно брать N=200 слов c максимальными весами TF-IDF. Во-вторых, эти веса будут в дальнейшем использованы для рекомендаций в алгоритме relevance feedback.
Алгоритм relevance feedback вплотную подводит нас к решению исходной задачи и предназначен для построения рекомендаций на основе текстового контента страниц и лайков пользователя (но без учёта лайков веб-страниц). Сразу оговорюсь, что алгоритм пригоден для рекомендаций новых сайтов, но существенно проигрывает традиционным методам коллаборативной фильтрации при наличии достаточного количества лайков (10-20 лайков и больше).
Первым шагом алгоритма является автоматический поиск ключевых слов (тегов) для каждого пользователя по истории его рейтингов (лайков). Для этого рассчитываются веса всех слов из веб-страниц, которые рейтинговал пользователь:
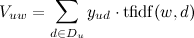 ,
,
где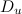 — все веб-страницы, которые лайкал/дизлайкал пользователь,
— все веб-страницы, которые лайкал/дизлайкал пользователь, 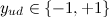 — рейтинг, который проставил пользователь. В качестве профиля пользователя выбирается заданное количество слов с максимальным весом (например, 400 слов).
— рейтинг, который проставил пользователь. В качестве профиля пользователя выбирается заданное количество слов с максимальным весом (например, 400 слов).
Расстояние от пользователя до сайта рассчитывается как скалярное произведение векторов весов слов пользователя и сайта:
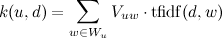 ,
,
где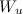 — слова из профиля пользователя.
— слова из профиля пользователя.
В результате алгоритм позволяет оценить сходство любого пользователя, у которого есть лайки, и любой веб-страницы, у которой есть текстовый контент. Кроме того, алгоритм достаточно прост в реализации и позволяет строить интерпретируемый профиль пользователя, состоящий из ключевых тегов его интересов. При регистрации можно просить пользователя указать свои ключевые интересы, что даст возможность делать рекомендации и для новых пользователей.
Метод LDA в нашем блоге уже достаточно подробно описывал Сергей Николенко. Алгоритм предназначен для описания текстов с точки зрения их тематик. Основное предположение модели LDA состоит в том, что каждый документ имеет несколько тематик, смешанных в некоторой пропорции. LDA — это вероятностная модель порождения текста, обучение которой позволяет выявить для каждого документа вероятностное распределение по тематикам, что в дальнейшем позволяет решать ряд прикладных задач, в том числе задачу рекомендаций.
Спецификой нашей задачи является наличие категорий для каждой веб-страницы и для каждого пользователя (всего категорий 63). Возникает вопрос: как согласовать полученные LDA-топики с известными категориями? Если обучать LDA без учета разделения на категории, то нужно брать достаточно большое количество топиков (более 200), иначе топики LDA фактически повторяют категории, и результатом работы алгоритма является разделение по тем же категориям (музыка, наука, религия и т.д.), которое нам и так известно. Сквозное обучение может быть полезно для задачи выявления ошибок классификации по категориям и рекомендации категорий для новых сайтов. Для рекомендаций же лучше обучать LDA по каждой категории отдельно с небольшим количеством LDA-топиков (5-7) на каждую категорию. В этом случае получается автоматическое разделение каждой категории на подкатегории, примерно вот так:

После того как получены LDA-топики для всех сайтов, можно строить рекомендации для каждого из пользователей. Для этого для каждого пользователя обучается логистическая регрессия на LDA-топиках сайтов, которые он рейтинговал. Положительным событием здесь является лайк, отрицательным — дизлайк. Длина вектора параметров регрессии для пользователя равна произведению числа LDA-топиков на число категорий, которые когда-либо были отмечены у пользователя в профиле (если пользователь отключил категорию в своем профиле, то информация по его предпочтениям в этой категории не потеряется). Рекомендация строится на основе оценки вероятности лайка по обученным параметрам регрессии пользователей и LDA-топикам сайтов стандартным образом.
Качество рекомендаций на LDA-топиках превосходит метод RF. Однако RF прост в реализации и позволяет получать интерпретируемый профиль пользователя. Кроме того, RF лучше работает при очень малом количестве слов в тексте (порог — 10-20 слов). С другой стороны, метод LDA позволяет решить ряд побочных задач, а именно:
Поэтому оптимальным представляется комбинация этих двух методов. Оба они действуют на этапе «раскрутки» новых страниц (до тех пор, пока сайт не набрал достаточно лайков, чтобы коллаборативная фильтрация смогла работать в полную силу). Если у страницы весь контент — это 5-10 слов (например, у страницы с фотографиями часто весь текстовый контент — это заголовок или подпись к картинке), то целесообразно использовать RF, в противном случае LDA. Для перечисленных выше дополнительных задач без топиков LDA не обойтись.
Удачи в дальнейшем изучении методов text mining!
Предварительная обработка текстового контента (preprocessing)
Как мы уже обсуждали, предварительная обработка текста веб-страницы заключается в выделении полезного контента страницы, отброса стоп-слов и лемматизации. Этот стандартный «джентльменский» набор так или иначе появляется почти во всех задачах text mining, и его можно найти во многих уже готовых программных решениях, подобрав то, что нужно для вашей конкретной прикладной задачи и среды разработки.
Итак, первым шагом в предварительной обработке текстов является построение словаря всех различных слов W, встречающихся в корпусе текстов D, и подсчёт статистики встречаемости этих слов в каждом из документов. Сразу обращу внимание, что все описанные в этой статье методы будут опираться на модель «мешка слов», когда порядок следования слов в тексте не учитывается. Контекст слова может быть учтён на этапе лемматизации. Например, в предложении «мы ели землянику, а вдоль опушки росли раскидистые ели», слово «ели» в первом случае нужно лемматизировать как «есть», а во втором — как «ель». Однако учтите, что поддержка контекста при лемматизации — это сложная задача natural language processing, далеко не все лемматизаторы к этому готовы. При дальнейшем же анализе порядок слов не будет учитываться вовсе.
TF-IDF (TF — term frequency, IDF — inverse document frequency)
Следующим шагом в обработке текстов является расчет весов TF-IDF для каждого слова w в каждом документе d:
где
— число вхождений слова в документ,  — общее число слов в данном тексте;
— общее число слов в данном тексте; ,
,где |D| — число текстов в корпусе, а
— число текстов, в которых встречается w. Теперь .
.Или несколько усложненный вариант:
,где
.Веса TF-IDF нужны для достижения двух целей. Во-первых, для слишком длинных текстов отбираются только слова с максимальным TF-IDF, а остальные отбрасываются, что позволяет сократить объём хранимых данных. Например, для методов relevance feedback и LDA, которые будут описаны ниже, нам было достаточно брать N=200 слов c максимальными весами TF-IDF. Во-вторых, эти веса будут в дальнейшем использованы для рекомендаций в алгоритме relevance feedback.
Релевантная обратная связь (relevance feedback, RF)
Алгоритм relevance feedback вплотную подводит нас к решению исходной задачи и предназначен для построения рекомендаций на основе текстового контента страниц и лайков пользователя (но без учёта лайков веб-страниц). Сразу оговорюсь, что алгоритм пригоден для рекомендаций новых сайтов, но существенно проигрывает традиционным методам коллаборативной фильтрации при наличии достаточного количества лайков (10-20 лайков и больше).
Первым шагом алгоритма является автоматический поиск ключевых слов (тегов) для каждого пользователя по истории его рейтингов (лайков). Для этого рассчитываются веса всех слов из веб-страниц, которые рейтинговал пользователь:
,где
— все веб-страницы, которые лайкал/дизлайкал пользователь, — рейтинг, который проставил пользователь. В качестве профиля пользователя выбирается заданное количество слов с максимальным весом (например, 400 слов). Расстояние от пользователя до сайта рассчитывается как скалярное произведение векторов весов слов пользователя и сайта:
,где
— слова из профиля пользователя.В результате алгоритм позволяет оценить сходство любого пользователя, у которого есть лайки, и любой веб-страницы, у которой есть текстовый контент. Кроме того, алгоритм достаточно прост в реализации и позволяет строить интерпретируемый профиль пользователя, состоящий из ключевых тегов его интересов. При регистрации можно просить пользователя указать свои ключевые интересы, что даст возможность делать рекомендации и для новых пользователей.
Латентное распределение Дирихле (latent Dirichlet allocation, LDA)
Метод LDA в нашем блоге уже достаточно подробно описывал Сергей Николенко. Алгоритм предназначен для описания текстов с точки зрения их тематик. Основное предположение модели LDA состоит в том, что каждый документ имеет несколько тематик, смешанных в некоторой пропорции. LDA — это вероятностная модель порождения текста, обучение которой позволяет выявить для каждого документа вероятностное распределение по тематикам, что в дальнейшем позволяет решать ряд прикладных задач, в том числе задачу рекомендаций.
Спецификой нашей задачи является наличие категорий для каждой веб-страницы и для каждого пользователя (всего категорий 63). Возникает вопрос: как согласовать полученные LDA-топики с известными категориями? Если обучать LDA без учета разделения на категории, то нужно брать достаточно большое количество топиков (более 200), иначе топики LDA фактически повторяют категории, и результатом работы алгоритма является разделение по тем же категориям (музыка, наука, религия и т.д.), которое нам и так известно. Сквозное обучение может быть полезно для задачи выявления ошибок классификации по категориям и рекомендации категорий для новых сайтов. Для рекомендаций же лучше обучать LDA по каждой категории отдельно с небольшим количеством LDA-топиков (5-7) на каждую категорию. В этом случае получается автоматическое разделение каждой категории на подкатегории, примерно вот так:
После того как получены LDA-топики для всех сайтов, можно строить рекомендации для каждого из пользователей. Для этого для каждого пользователя обучается логистическая регрессия на LDA-топиках сайтов, которые он рейтинговал. Положительным событием здесь является лайк, отрицательным — дизлайк. Длина вектора параметров регрессии для пользователя равна произведению числа LDA-топиков на число категорий, которые когда-либо были отмечены у пользователя в профиле (если пользователь отключил категорию в своем профиле, то информация по его предпочтениям в этой категории не потеряется). Рекомендация строится на основе оценки вероятности лайка по обученным параметрам регрессии пользователей и LDA-топикам сайтов стандартным образом.
Подведем итоги
Качество рекомендаций на LDA-топиках превосходит метод RF. Однако RF прост в реализации и позволяет получать интерпретируемый профиль пользователя. Кроме того, RF лучше работает при очень малом количестве слов в тексте (порог — 10-20 слов). С другой стороны, метод LDA позволяет решить ряд побочных задач, а именно:
- автоматически рекомендовать категории при добавлении нового сайта;
- выявить некорректно классифицированные сайты;
- найти двойников веб-сайтов, плагиат и т.п.;
- отобразить теги основных топиков сайта;
- отобразить основные теги в той или иной категории.
Поэтому оптимальным представляется комбинация этих двух методов. Оба они действуют на этапе «раскрутки» новых страниц (до тех пор, пока сайт не набрал достаточно лайков, чтобы коллаборативная фильтрация смогла работать в полную силу). Если у страницы весь контент — это 5-10 слов (например, у страницы с фотографиями часто весь текстовый контент — это заголовок или подпись к картинке), то целесообразно использовать RF, в противном случае LDA. Для перечисленных выше дополнительных задач без топиков LDA не обойтись.
Удачи в дальнейшем изучении методов text mining!
