В поисках решения для построения HA кластера на linux, я наткнулся на довольно интересный продукт, который, по моим наблюдениям, несправедливо обделен вниманием уважаемого сообщества. Судя по русскоязычным статьям, при необходимости организации отказоустойчивости на уровне сервисов, более популярно использование heartbeat и pacemaker. Ни первое, ни второе решение у нас в компании не прижилось, уж не знаю почему. Может сыграла роль сложность конфигурации и использования, низкая стабильность, отсутствие подробной и обновляемой документации, поддержки.
После очередного обновления centos, мы обнаружили, что разработчик pacemaker перестал поддерживать репозиторий для данной ОС, а в официальных репозиториях была сборка, подразумевающая совершенно другую конфигурацию (cman вместо corosync). Переконфигурировать pacemaker желания уже не было, и мы стали искать другое решение. На каком-то из англоязычных форумов, я прочел про Red Hat Cluster Suite, мы решили его попробовать.
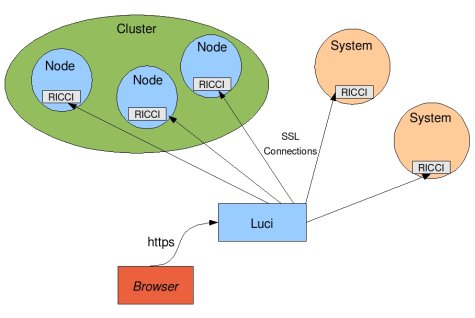
RHCS состоит из нескольких основных компонентов:
Как и в heartbeat и pacemaker, ресурсы кластера управляются стандартизированными скриптами (resource agents, RA). Кардинальное отличие от pacemaker состоит в том, что redhat не подразумевает добавления пользовательских кастомных RA в систему. Но это с лихвой компенсируется тем, что есть универсальный resource agent для добавления обычных init скриптов, он называется script.
Управление ресурсами идет только на уровне групп сервисов. Сам по себе ресурс невозможно включить или выключить. Для распределения ресурсов по нодам и приоритезации запуска на определенных нодах используются failover domains, домен представляет собой правила запуска групп ресурсов на определенных нодах, приоритезацию и failback. Одну группу ресурсов можно привязать к одному домену.
Данная инструкция тестировалась на centos 6.3 — 6.4.
Если будет интерес, в следующей статье могу написать про использование shared storage и fencing в данной системе.
После очередного обновления centos, мы обнаружили, что разработчик pacemaker перестал поддерживать репозиторий для данной ОС, а в официальных репозиториях была сборка, подразумевающая совершенно другую конфигурацию (cman вместо corosync). Переконфигурировать pacemaker желания уже не было, и мы стали искать другое решение. На каком-то из англоязычных форумов, я прочел про Red Hat Cluster Suite, мы решили его попробовать.
Общая информация
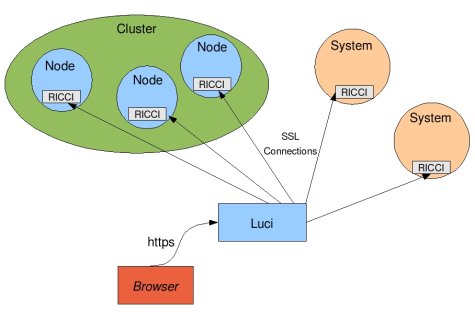
RHCS состоит из нескольких основных компонентов:
- cman — отвечает за кластеризацию, взаимодействие между нодами, кворум. По сути, он и собирает кластер.
- rgmanager — менеджер ресурсов кластера, занимается добавлением, мониторингом, управлением групп ресурсов кластера.
- ricci — демон для удаленного управления кластером
- luci — красивый веб интерфейс, который подключается к ricci на всех нодах и предоставляет централизованное управление через веб-интерфейс.
Как и в heartbeat и pacemaker, ресурсы кластера управляются стандартизированными скриптами (resource agents, RA). Кардинальное отличие от pacemaker состоит в том, что redhat не подразумевает добавления пользовательских кастомных RA в систему. Но это с лихвой компенсируется тем, что есть универсальный resource agent для добавления обычных init скриптов, он называется script.
Управление ресурсами идет только на уровне групп сервисов. Сам по себе ресурс невозможно включить или выключить. Для распределения ресурсов по нодам и приоритезации запуска на определенных нодах используются failover domains, домен представляет собой правила запуска групп ресурсов на определенных нодах, приоритезацию и failback. Одну группу ресурсов можно привязать к одному домену.
Гайд по настройке:
Данная инструкция тестировалась на centos 6.3 — 6.4.
- Весь набор пакетов, которые будут необходимы для полноценной работы одной ноды удобно объединен в группу «High Availability» в репозитории. Ставим их, используя yum, отдельно ставим luci. На момент написания статьи, luci надо ставить из base репозитория, если устанавливать со включенным epel, ставится некорректная версия python-webob и luci стартует неправильно.
yum groupinstall "High Availability" yum install --disablerepo=epel* luci
- Чтобы первоначально запустить первую ноду, нужно прописать конфиг cluster.conf (в centos по умолчанию /etc/cluster/cluster.conf). Для первоначального запуска нам хватит такой конфигурации:
<?xml version="1.0"?> <cluster config_version="1" name="cl1"> <clusternodes> <clusternode name="node1" nodeid="1"/> </clusternodes> </cluster>
Где node1 это FQDN ноды, по которому другие ноды будут с ней общаться.
Это единственный конфиг, который я правил из консоли при настройке этой системы.
- Устанавливаем пароль для пользователя ricci. Этот пользователь создается при установке пакета ricci, и будет использоваться для подключения нод в веб-интерфейсе luci.
passwd ricci
- Запускаем сервисы:
service cman start service rgmanager start service modclusterd start service ricci start service luci start
Тут надо заметить, что luci лучше ставить на отдельный сервер, не задейстованный в кластере, чтобы при недоступности ноды, luci была доступна.
Также, удобно сразу включить сервисы в автозагрузку:
chkconfig ricci on chkconfig cman on chkconfig rgmanager on chkconfig modclusterd on chkconfig luci on
- Теперь можно зайти в веб-интерфейс luci, который при правильном старте сервиса поднимается по https на порту 8084. Залогиниться можно под пользователем root.
Видим довольно красивый веб-интерфейс:
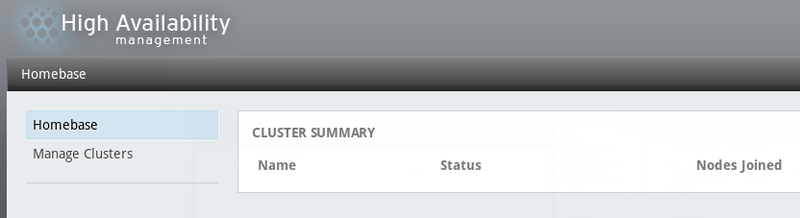
В котором добавляем наш кластер из одной ноды, нажав Manage clusters -> Add, указываем имя ноды, пароль пользователя ricci и нажимаем Add cluster. Осталось только добавить ноды.
- Чтобы добавить сервер как ноду, на нем должна быть установлена группа пакетов «High Availability» и запущен ricci. Ноды добавляются в управлении кластером на вкладке Nodes, указывается имя сервера и пароль пользователя ricci на нем. После добавления ноды, ricci синхронизирует на нее cluster.conf, после чего запускает на ней все нужные сервисы.
Если будет интерес, в следующей статье могу написать про использование shared storage и fencing в данной системе.







