 Обрабатываете много данных в браузере?
Обрабатываете много данных в браузере? Хотите отправлять их обратно на сервер?
Да так, чтобы отправлялось побыстрее и помещалось в один http запрос?
В статье я покажу как мы решили эту задачу в новом проекте, используя сжатие и современные возможности javascript.
Описание задачи
Хабраюзер aneto пожаловался мне, что Яндекс.Директ плохо обрабатывает пересечения ключевиков между собой. А тем временем задача актуальная и практически нерешаемая вручную. Так мы и сделали небольшой сервис, решающий эту проблему.
Обрабатываемых ключевиков бывает много — десятки тысяч строк. Из-за квадратичной сложности алгоритм обработки требователен к памяти и вычислительным мощностям. Поэтому не грешно было бы привлечь браузер пользователя и перенести обработку с сервера на клиент.
В ходе разработки у нас появилось две проблемы:
- При медленном соединении данные передаются слишком долго.
- Часто данные не умещаются в один post запрос из-за ограничений nginx/apache/php/etc.
Решение
Есть множество способов решения. В нашем случае прокатил вариант, основанный на современных стандартах: Typed Arrays, Workers, XHR 2. В двух словах: мы сжимаем данные и отправляем их на сервер в двоичном виде. Эти простые действия позволили нам сократить размер передаваемых данных более чем в 2 раза.
Рассмотрим алгоритм пошагово.
Шаг 0: Исходные данные
Для примера я сгенерировал массив, содержащий различные данные о множестве пользователей. В примере он будет загружаться через JSONP и отправляться обратно на сервер.
Код загрузки и функция отправки данных
<script>
function setDemoData(data) {
window.initialData = data;
}
function send(data) {
var http = new XMLHttpRequest();
http.open('POST', window.location.href, true);
http.setRequestHeader('X-Requested-With', 'XMLHttpRequest');
http.onreadystatechange = function() {
if (http.readyState == 4) {
if (http.status === 200) {
// xhr success
}
else {
// xhr error;
}
}
};
http.send(data);
}
</script>
<script src="http://nodge.ru/habr/demoData.js"></script>
Попробуем отправить данные как есть и посмотрим в дебагер:
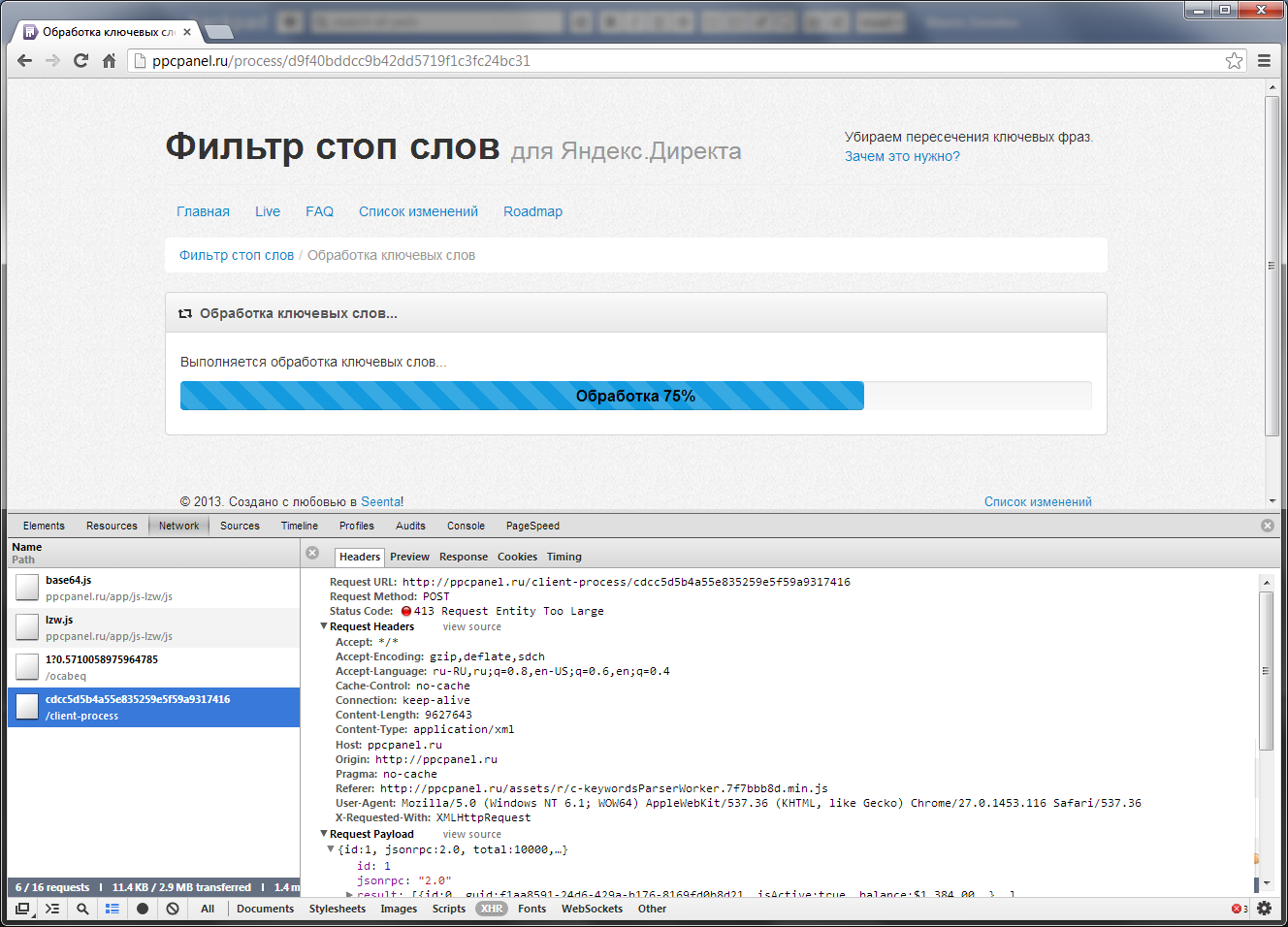
var data = JSON.stringify(initialData);
send(data);
При простой передаче объем запроса — 9402 Кб. Много, будем сокращать.
Шаг 1: Сжатие данных
В javascript нет встроенных функций для сжатия данных. Для сжатия можно использовать любой удобный для вас алгоритм: LZW, Deflate, LZMA и другие. Выбор будет зависеть, в основном, от наличия библиотек под клиент и сервер. Соответствующие javascript библиотеки легко находятся на гитхабе: раз, два, три.
Мы пробовали использовать все три варианта, но с PHP удалось подружить только LZW. Это очень простой алгоритм. В примере воспользуемся такой реализацией:
Функция сжатия по LZW
var LZW = {
compress: function(uncompressed) {
"use strict";
var i, l,
dictionary = {},
w = '', k, wk,
result = [],
dictSize = 256;
// initial dictionary
for (i = 0; i < dictSize; i++) {
dictionary[String.fromCharCode(i)] = i;
}
for (i = 0, l = uncompressed.length; i < l; i++) {
k = uncompressed.charAt(i);
wk = w + k;
if (dictionary.hasOwnProperty(wk)) {
w = wk;
}
else {
result.push(dictionary[w]);
dictionary[wk] = dictSize++;
w = k;
}
}
if (w !== '') {
result.push(dictionary[w]);
}
result.dictionarySize = dictSize;
return result;
}
};Так как LZW рассчитан на работу с ASCII, предварительно экранируем unicode символы. Библиотека взята здесь.
Итак, сжимаем данные и отправляем на сервер:
var data = JSON.stringify(initialData);
data = stringEscape(data);
data = LZW.compress(data);
send(data.join('|'));Объем запроса — 6079 Кб (сжатие 65%), сэкономили 3323 Кб. Более сложный алгоритм сжатия покажет лучшие результаты, но мы идем к следующему шагу.
Шаг 2: Перевод в двоичные данные
Так как после сжатия по LZW мы получаем массив чисел, то совершенно неэффективно передавать его в качестве строки. Намного эффективнее передать его как двоичные данные.
Для этого мы можем использовать Typed Arrays:
// используем 16-битный или 32-битный массив в зависимости от объема данных
var type = data.dictionarySize > 65535 ? 'Uint32Array' : 'Uint16Array',
count = data.length,
buffer = new ArrayBuffer((count+2) * window[type].BYTES_PER_ELEMENT),
// по первому байту будем определять тип массива
bufferBase = new Uint8Array(buffer, 0, 1),
// для оптимизации распаковки на сервере передадим итоговый размер словаря LZW
bufferDictSize = new window[type](buffer, window[type].BYTES_PER_ELEMENT, 1),
bufferData = new window[type](buffer, window[type].BYTES_PER_ELEMENT*2, count);
bufferBase[0] = type === 'Uint32Array' ? 32 : 16; // записываем тип массива
bufferDictSize[0] = data.dictionarySize; // записываем размер словаря LZW
bufferData.set(data); // записываем данные
data = new Blob([buffer]); // оборачиваем ArrayBuffer в Blob для передачи по XHR
send(data); Объем запроса — 3686 Кб (сжатие 39%), сэкономили 6079 Кб. Теперь размер запроса уменьшился более чем в два раза, обе описанные проблемы решены.
Шаг 3: Обработка на сервере.
Пришедшие на сервер данные теперь необходимо распаковать перед обработкой. Естественно, нужно использовать тот же алгоритм что и на клиенте. Вот пример как это можно сделать на php:
Пример обработки на PHP
<?php
$data = readBinaryData(file_get_contents('php://input'));
$data = lzw_decompress($data);
$data = unicode_decode($data);
$data = json_decode($data, true);
function readBinaryData($buffer) {
$bufferType = unpack('C', $buffer); // первый байт - тип массива
if ($bufferType[1] === 16) {
$dataSize = 2;
$unpackModifier = 'v';
}
else {
$dataSize = 4;
$unpackModifier = 'V';
}
$buffer = substr($buffer, $dataSize); // remove type from buffer
$data = new SplFixedArray(strlen($buffer)/$dataSize);
$stepCount = 2500; // распаковываем частями по 2500 элементов
for ($i=0, $l=$data->getSize(); $i<$l; $i+=$stepCount) {
if ($i + $stepCount < $l) {
$bytesCount = $stepCount * $dataSize;
$currentBuffer = substr($buffer, 0, $bytesCount);
$buffer = substr($buffer, $bytesCount);
}
else {
$currentBuffer = $buffer;
$buffer = '';
}
$dataPart = unpack($unpackModifier.'*', $currentBuffer);
$p = $i;
foreach ($dataPart as $item) {
$data[$p] = $item;
$p++;
}
}
return $data;
}
function lzw_decompress($compressed) {
$dictSize = 256;
// первый элемент - размер словаря
$dictionary = new SplFixedArray($compressed[0]);
for ($i = 0; $i < $dictSize; $i++) {
$dictionary[$i] = chr($i);
}
$i = 1;
$w = chr($compressed[$i++]);
$result = $w;
for ($l = count($compressed); $i < $l; $i++) {
$entry = '';
$k = $compressed[$i];
if (isset($dictionary[$k])) {
$entry = $dictionary[$k];
}
else {
if ($k === $dictSize) {
$entry = $w . $w[0];
}
else {
return null;
}
}
$result .= $entry;
$dictionary[$dictSize++] = $w .$entry[0];
$w = $entry;
}
return $result;
}
function replace_unicode_escape_sequence($match) {
return mb_convert_encoding(pack('H*', $match[1]), 'UTF-8', 'UCS-2BE');
}
function unicode_decode($str) {
return preg_replace_callback('/\\\\u([0-9a-f]{4})/i', 'replace_unicode_escape_sequence', $str);
}Для других языков, думаю, все так же просто.
Шаг 4: Workers
Так как приведенным выше кодом сжимаются достаточно объемные данные, то страница будет подвисать на время сжатия. Довольно неприятный эффект. Чтобы от него избавиться создадим поток, в котором будем производить все вычисления. В javascript для этого есть Workers. Как использовать Workers можно посмотреть в полном примере ниже или в документации.
Шаг 5: Поддержка браузерами
Очевидно, что приведенный выше javascript код не будет работать в IE6 =)
Для работы нам необходимы Typed Arrays, XHR 2 и Workers.
Список поддерживаемых браузеров: IE10+, Firefox 21+, Chrome 26+, Safari 5.1+, Opera 15+, IOS 5+, Android 4.0+ (без Workers).
Для проверки можно использовать Modernizr, либо примерно такой код:
Определение поддержки необходимых стандартов
var compressionSupported = (function() {
var check = [
'Worker',
'Uint16Array', 'Uint32Array', 'ArrayBuffer', // Typed Arrays
'Blob', 'FormData' // xhr2
];
var supported = true;
for (var i = 0, l = check.length; i<l; i++) {
if (!(check[i] in window)) {
supported = false;
break;
}
}
return supported;
})();Примеры
Код из статьи опубликован на JS Bin: страница, worker. Открываете страницу, открываете инструменты разработчика и смотрите на размер трех post запросов.
В реальном проекте решение работает здесь. Можно скачать тестовый файл, добавить в него что-нибудь уникальное для обхода кеша и попробовать загрузить на обработку.
Заключение
Конечно, данный метод подойдет не для всех случаев, но он имеет право на жизнь. Иногда проще/разумнее вместо сжатия сделать несколько запросов. А может у вас изначально числовые данные, то не нужно переводить их в строку и сжимать — достаточно использовать Typed Arrays.
Резюме:
- Можно использовать сжатие не только server→client, но и client→server.
- XHR 2 и Typed Arrays позволяют существенно уменьшить объем передаваемых данных.
- Использование Workers позволит не блокировать взаимодействие пользователя со страницей.
- И, конечно, не передавайте излишние данные без необходимости.
С удовольствием отвечу на вопросы и приму улучшения для кода. Ошибки и опечатки проверил, но на всякий случай — пишите в личные сообщения. Всем добра.
UPDATE 1:
Отдельно стоит сказать про изображения. Большинство форматов (jpeg, png, gif) уже сжаты, поэтому сжимать их повторно нет смысла. Изображения нужно передавать как бинарные данные, а не в строковом виде (base64). Я сделал небольшой пример для canvas показывающий преобразование base64 в Blob.
UPDATE 2:
Если используете или планируете использовать SSL, то прочитайте эту статью. В SSL уже предусмотрено двухстороннее сжатие запросов.
UPDATE 3:
Заменил base64 на экранирование unicode символов. Получилось намного эффективнее. Спасибо consumer, seriyPS и TolTol.







