Июль уже подходит к концу, а на «хабре» до сих пор никто не вспомнил о CTP релизе MSSQL Server 2014.
Релизу будущего года присвоен позывной «Hekaton». Его появление было заявлено еще на конференции PASS 2012 года и тогда это было только название in-memory движка OLTP. Теперь это название целого релиза с встроенной поддержкой и оптимизацией обработки транзакций непосредственно в оперативной памяти.
Обратимся к истории.
Если в стародавние времена (аж в суровые 70-е годы когда святые Дэйт и Кодд работали в ИБМ, а жесткий диск на 300 МБ весил как взрослая свиноматка) данные оптимизировались изначально под хранение на… да на чем угодно: на лентах лежали известные нам современные файлы состоящие из заголовка, тела и значка конца файла, на дисках файловых систем в современном виде вообще не было – данные из БД шлепались на диски уже размеченные под хранение данных заданной таблицы, то бишь форматирование делалось самой БД и под хранение собственных данных. А были еще ячейки памяти (data cells). Они были мечтой ибо позволяли случайный доступ на чтение и запись в любой момент времени, но как и положено были дорогие и реально огромные (640 КБ в ячейках памяти на 70-й год хватило бы на олимпийский рекорд в зачете жим от груди). Шли годы: здоровенные бобины лент превратились в аккуратненькие картриджи LTO, жесткие диски обзавелись файловыми системами и тоже основательно сбросили в весе, а ячейки памяти превратились в известную всем RAM и частично в SSD. Технически вроде бы вот оно светлое будущее, но нет. Происки врагов эффективного вычисления и обработки данных наступали на всех фронтах. Появилось ООП которое вместо экономных побайтовых запросов начало под предводительством Java ковырять прямо в оперативной памяти сначала мегабайтные, а потом и гигабайтные массивы и загаживать её трупами недоуничтоженных объектов.
В это время базы данных по старинке честно веровали что работают с жестким диском, хотя старались побольше затащить в RAM, но делали это без особой наглости и стыдливо называли словом cache (англ.) – наличные деньги. То есть не могли они сказать: «Эта таблица(база) будет лежать в RAM и точка! ». А стыдливо выводили статистику hit cache, то радуя нас числами вроде 99.8, то огорчая и вводя в уныние показав 25.2.
Встраивание движка Hekaton в ядро MSSQL Server 2014 незначительно расширяет функционалю
Казалось-бы, как может это помочь простым ДБА в деле?
Прилагаю несколько снимков с той скандальной конференции 2012 года. (пикантные места выделены):
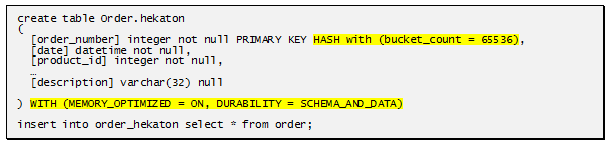

То есть имеем следующее. Мало того что таблицу(базу) можно целиком вытащить в оперативную память (до свидания RAM-drive для temp_db, хотя нет – прощай), так еще и рекомпиляция процедур этих баз будет происходить на уровне Native, что для одной части ДБА значительно повысит скорость работы, а для других – позволит писать более кривой код без потери производительности.
Не скажу, что потрясен этим «революционным» «нововведением», но это просто монументальное изменение в сравнении например с расширением AlwaysOn группы до 8 secondary серверов (Кто-нибудь видел поддержку read-intent в 1С: Предприятие или в Navision? Я нет.), или с введением новых свистелок-перделок интегрированных со свистелками-перделками Office и Sharepoint, для рисования комиксов на тему «Как мы провели квартал».
Понятно, что аналогичный механизм на разного вида костылях уже существует в множестве других СУБД, но главный фокус в том что на уровне ядра СУБД он есть мягко говоря не у всех.
Резюме: В целом, как обычно. Выходит новый релиз, а новинки из разряда тех что нужны были еще вчера (сейчас уже скоростные БД активно переползают на ССД и этот фокус с памятью уже не очень то и нужен), или простые украшалки длямладшего командного среднего управленческого состава. Рывка, вроде реализации SQL 3.0 или хотя бы PL/SQL – в очередной раз не произошло. Опять недождались.
UPD: Для интересующихся сслылка на вайтлисты и прочую документацию. А я пойду выпью за безбажность релиза. Всех с праздничком.
примечание: англ. cache, от фр. cacher — «прятать»; произносится [kæʃ] — «кэш» часто путают с cash — собственно наличные. Учитывая цены на устройства быстрого доступа — второй вариант жизненнее. :)
Релизу будущего года присвоен позывной «Hekaton». Его появление было заявлено еще на конференции PASS 2012 года и тогда это было только название in-memory движка OLTP. Теперь это название целого релиза с встроенной поддержкой и оптимизацией обработки транзакций непосредственно в оперативной памяти.
Обратимся к истории.
Если в стародавние времена (аж в суровые 70-е годы когда святые Дэйт и Кодд работали в ИБМ, а жесткий диск на 300 МБ весил как взрослая свиноматка) данные оптимизировались изначально под хранение на… да на чем угодно: на лентах лежали известные нам современные файлы состоящие из заголовка, тела и значка конца файла, на дисках файловых систем в современном виде вообще не было – данные из БД шлепались на диски уже размеченные под хранение данных заданной таблицы, то бишь форматирование делалось самой БД и под хранение собственных данных. А были еще ячейки памяти (data cells). Они были мечтой ибо позволяли случайный доступ на чтение и запись в любой момент времени, но как и положено были дорогие и реально огромные (640 КБ в ячейках памяти на 70-й год хватило бы на олимпийский рекорд в зачете жим от груди). Шли годы: здоровенные бобины лент превратились в аккуратненькие картриджи LTO, жесткие диски обзавелись файловыми системами и тоже основательно сбросили в весе, а ячейки памяти превратились в известную всем RAM и частично в SSD. Технически вроде бы вот оно светлое будущее, но нет. Происки врагов эффективного вычисления и обработки данных наступали на всех фронтах. Появилось ООП которое вместо экономных побайтовых запросов начало под предводительством Java ковырять прямо в оперативной памяти сначала мегабайтные, а потом и гигабайтные массивы и загаживать её трупами недоуничтоженных объектов.
В это время базы данных по старинке честно веровали что работают с жестким диском, хотя старались побольше затащить в RAM, но делали это без особой наглости и стыдливо называли словом cache (англ.) – наличные деньги. То есть не могли они сказать: «Эта таблица(база) будет лежать в RAM и точка! ». А стыдливо выводили статистику hit cache, то радуя нас числами вроде 99.8, то огорчая и вводя в уныние показав 25.2.
Встраивание движка Hekaton в ядро MSSQL Server 2014 незначительно расширяет функционалю
Казалось-бы, как может это помочь простым ДБА в деле?
Прилагаю несколько снимков с той скандальной конференции 2012 года. (пикантные места выделены):
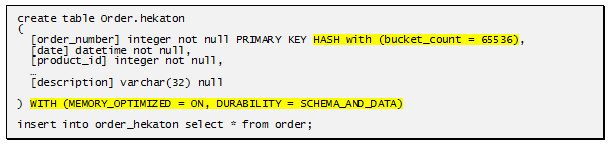
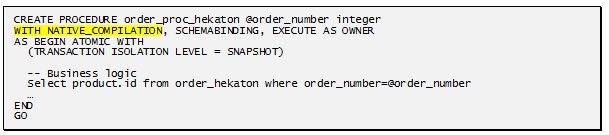
То есть имеем следующее. Мало того что таблицу(базу) можно целиком вытащить в оперативную память (до свидания RAM-drive для temp_db, хотя нет – прощай), так еще и рекомпиляция процедур этих баз будет происходить на уровне Native, что для одной части ДБА значительно повысит скорость работы, а для других – позволит писать более кривой код без потери производительности.
Не скажу, что потрясен этим «революционным» «нововведением», но это просто монументальное изменение в сравнении например с расширением AlwaysOn группы до 8 secondary серверов (Кто-нибудь видел поддержку read-intent в 1С: Предприятие или в Navision? Я нет.), или с введением новых свистелок-перделок интегрированных со свистелками-перделками Office и Sharepoint, для рисования комиксов на тему «Как мы провели квартал».
Понятно, что аналогичный механизм на разного вида костылях уже существует в множестве других СУБД, но главный фокус в том что на уровне ядра СУБД он есть мягко говоря не у всех.
Резюме: В целом, как обычно. Выходит новый релиз, а новинки из разряда тех что нужны были еще вчера (сейчас уже скоростные БД активно переползают на ССД и этот фокус с памятью уже не очень то и нужен), или простые украшалки для
UPD: Для интересующихся сслылка на вайтлисты и прочую документацию. А я пойду выпью за безбажность релиза. Всех с праздничком.
примечание: англ. cache, от фр. cacher — «прятать»; произносится [kæʃ] — «кэш» часто путают с cash — собственно наличные. Учитывая цены на устройства быстрого доступа — второй вариант жизненнее. :)







