На практике, задачи по объединению строк в одну попадаются достаточно часто. Весьма печально, но стандарт T-SQL не предусматривает возможности использовании строковых данных внутри агрегирующей функции SUM:
Msg 8117, Level 16, State 1, Line 1
Operand data type char is invalid for sum operator.
Хотя для решения подобного рода задач, для MySQL была добавлена функция GROUP_CONCAT, а в Oracle – LISTAGG. В свою же очередь, SQL Server такого встроенного функционала пока не имеет.
Однако, не стоит рассматривать это как недостаток, поскольку возможности T-SQL позволяют выполнять конкатенации строк более гибко и эффективно за счет применения других конструкций, которые будут рассмотрены далее.
Предположим, что нам необходимо объединить через запятую несколько строк в одну, используя для этого данные из следующей таблицы:
Наиболее очевидным решением данной задачи является применение курсора:
Однако, его использование снижает эффективность выполнения запроса и, как минимум, выглядит не слишком элегантно.
Чтобы избавится от него, можно конкатенировать строки через присваивание переменных:
С одной стороны, конструкция получилась очень простой, с другой стороны, ее производительность на большой выборке оставляет желать лучшего.
Для агрегации строк также возможно сделать через XML, применяя следующую конструкцию:
Если посмотреть на план, то можно заметить высокую стоимость вызова метода value:
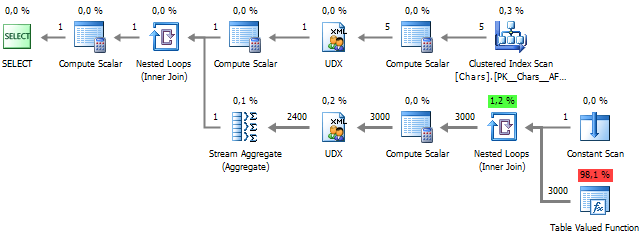
Чтобы избавится от этой операции, можно переписать запрос применяя свойства XQuery:
В результате – получим очень простой и быстрый план выполнения:
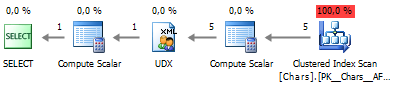
В принципе, конкатенация строк по одному столбцу не вызывает особых сложностей.
Более интересна ситуация, когда требуется выполнить конкатенацию сразу по нескольким столбцам. Например, в наличии у нас следующая таблица:
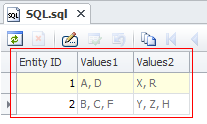
в которой необходимо сгруппировать данные следующим образом:
Как вариант, можно скопировать вызовы XML, но тогда мы получим дублирующие чтения, которые могут существенно повлиять на эффективность выполнения запроса:
В этом можно легко убедится, если взглянуть на план выполнения:
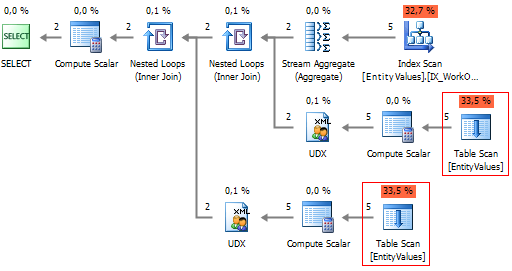
Чтобы сократить повторные чтения можно воспользоваться небольшим XML хаком:
Но данный запрос также будет не оптимальным вследствие многократного вызова метода query.
Можно воспользоваться курсором:
Однако, как показала практика, при работе с большими ETL пакетами, наиболее производительным решением является возможность присваивания переменных в конструкции UPDATE:
SQL Server не имеет встроенного аналога функций GROUP_CONCAT и LISTAGG. Тем не менее, это не мешает, в зависимости от ситуации, эффективно выполнять задачи по конкатенации строк. Цель данного поста – наглядно это показать.
Msg 8117, Level 16, State 1, Line 1
Operand data type char is invalid for sum operator.
Хотя для решения подобного рода задач, для MySQL была добавлена функция GROUP_CONCAT, а в Oracle – LISTAGG. В свою же очередь, SQL Server такого встроенного функционала пока не имеет.
Однако, не стоит рассматривать это как недостаток, поскольку возможности T-SQL позволяют выполнять конкатенации строк более гибко и эффективно за счет применения других конструкций, которые будут рассмотрены далее.
Предположим, что нам необходимо объединить через запятую несколько строк в одну, используя для этого данные из следующей таблицы:
IF OBJECT_ID('dbo.Chars', 'U') IS NOT NULL
DROP TABLE dbo.Chars
GO
CREATE TABLE dbo.Chars ([Char] CHAR(1) PRIMARY KEY)
INSERT INTO dbo.Chars ([Char])
VALUES ('A'), ('B'), ('C'), ('F'), ('D')
Наиболее очевидным решением данной задачи является применение курсора:
DECLARE
@Chars VARCHAR(100)
, @Char CHAR(1)
DECLARE cur CURSOR LOCAL READ_ONLY FAST_FORWARD FOR
SELECT [Char]
FROM dbo.Chars
OPEN cur
FETCH NEXT FROM cur INTO @Char
WHILE @@FETCH_STATUS = 0 BEGIN
SET @Chars = ISNULL(@Chars + ', ' + @Char, @Char)
FETCH NEXT FROM cur INTO @Char
END
CLOSE cur
DEALLOCATE cur
SELECT @Chars
Однако, его использование снижает эффективность выполнения запроса и, как минимум, выглядит не слишком элегантно.
Чтобы избавится от него, можно конкатенировать строки через присваивание переменных:
DECLARE @Chars VARCHAR(100)
SELECT @Chars = ISNULL(@Chars + ', ' + [Char], [Char])
FROM dbo.Chars
SELECT @Chars
С одной стороны, конструкция получилась очень простой, с другой стороны, ее производительность на большой выборке оставляет желать лучшего.
Для агрегации строк также возможно сделать через XML, применяя следующую конструкцию:
SELECT Chars = STUFF((
SELECT ', ' + [Char]
FROM dbo.Chars
FOR XML PATH(''), TYPE).value('.', 'VARCHAR(MAX)'), 1, 2, '')
Если посмотреть на план, то можно заметить высокую стоимость вызова метода value:

Чтобы избавится от этой операции, можно переписать запрос применяя свойства XQuery:
SELECT Chars = STUFF(CAST((
SELECT [text()] = ', ' + [Char]
FROM dbo.Chars
FOR XML PATH(''), TYPE) AS VARCHAR(100)), 1, 2, '')
В результате – получим очень простой и быстрый план выполнения:

В принципе, конкатенация строк по одному столбцу не вызывает особых сложностей.
Более интересна ситуация, когда требуется выполнить конкатенацию сразу по нескольким столбцам. Например, в наличии у нас следующая таблица:
IF OBJECT_ID('dbo.EntityValues', 'U') IS NOT NULL
DROP TABLE dbo.EntityValues
GO
CREATE TABLE dbo.EntityValues (
EntityID INT
, Value1 CHAR(1)
, Value2 CHAR(1)
)
CREATE NONCLUSTERED INDEX IX_WorkOut_EntityID
ON dbo.EntityValues (EntityID)
GO
INSERT INTO dbo.EntityValues (EntityID, Value1, Value2)
VALUES (1, 'A', 'X'), (2, 'B', 'Y'), (2, 'C', 'Z'), (2, 'F', 'H'), (1, 'D', 'R')
в которой необходимо сгруппировать данные следующим образом:

Как вариант, можно скопировать вызовы XML, но тогда мы получим дублирующие чтения, которые могут существенно повлиять на эффективность выполнения запроса:
SELECT
ev.EntityID
, Values1 = STUFF(CAST((
SELECT [text()] = ', ' + ev2.Value1
FROM dbo.EntityValues ev2
WHERE ev2.EntityID = ev.EntityID
FOR XML PATH(''), TYPE) AS VARCHAR(100)), 1, 2, '')
, Values2 = STUFF(CAST((
SELECT [text()] = ', ' + ev2.Value2
FROM dbo.EntityValues ev2
WHERE ev2.EntityID = ev.EntityID
FOR XML PATH(''), TYPE) AS VARCHAR(100)), 1, 2, '')
FROM (
SELECT DISTINCT EntityID
FROM dbo.EntityValues
) ev
В этом можно легко убедится, если взглянуть на план выполнения:

Чтобы сократить повторные чтения можно воспользоваться небольшим XML хаком:
SELECT
ev.EntityID
, Values1 = STUFF(REPLACE(
CAST([XML].query('for $a in /a return xs:string($a)') AS VARCHAR(100)), ' ,', ','), 1, 1, '')
, Values2 = STUFF(REPLACE(
CAST([XML].query('for $b in /b return xs:string($b)') AS VARCHAR(100)), ' ,', ','), 1, 1, '')
FROM (
SELECT DISTINCT EntityID
FROM dbo.EntityValues
) ev
CROSS APPLY (
SELECT [XML] = CAST((
SELECT
[a] = ', ' + ev2.Value1
, [b] = ', ' + ev2.Value2
FROM dbo.EntityValues ev2
WHERE ev2.EntityID = ev.EntityID
FOR XML PATH('')
) AS XML)
) t
Но данный запрос также будет не оптимальным вследствие многократного вызова метода query.
Можно воспользоваться курсором:
IF OBJECT_ID('tempdb.dbo.#EntityValues') IS NOT NULL
DROP TABLE #EntityValues
GO
SELECT DISTINCT
EntityID
, Values1 = CAST(NULL AS VARCHAR(100))
, Values2 = CAST(NULL AS VARCHAR(100))
INTO #EntityValues
FROM dbo.EntityValues
DECLARE
@EntityID INT
, @Value1 CHAR(1)
, @Value2 CHAR(1)
DECLARE cur CURSOR LOCAL READ_ONLY FAST_FORWARD FOR
SELECT
EntityID
, Value1
, Value2
FROM dbo.EntityValues
OPEN cur
FETCH NEXT FROM cur INTO
@EntityID
, @Value1
, @Value2
WHILE @@FETCH_STATUS = 0 BEGIN
UPDATE #EntityValues
SET
Values1 = ISNULL(Values1 + ', ' + @Value1, @Value1)
, Values2 = ISNULL(Values2 + ', ' + @Value2, @Value2)
WHERE EntityID = @EntityID
FETCH NEXT FROM cur INTO
@EntityID
, @Value1
, @Value2
END
CLOSE cur
DEALLOCATE cur
SELECT *
FROM #EntityValues
Однако, как показала практика, при работе с большими ETL пакетами, наиболее производительным решением является возможность присваивания переменных в конструкции UPDATE:
IF OBJECT_ID('tempdb.dbo.#EntityValues') IS NOT NULL
DROP TABLE #EntityValues
GO
DECLARE
@Values1 VARCHAR(100)
, @Values2 VARCHAR(100)
SELECT
EntityID
, Value1
, Value2
, RowNum = ROW_NUMBER() OVER (PARTITION BY EntityID ORDER BY 1/0)
, Values1 = CAST(NULL AS VARCHAR(100))
, Values2 = CAST(NULL AS VARCHAR(100))
INTO #EntityValues
FROM dbo.EntityValues
UPDATE #EntityValues
SET
@Values1 = Values1 =
CASE WHEN RowNum = 1
THEN Value1
ELSE @Values1 + ', ' + Value1
END
, @Values2 = Values2 =
CASE WHEN RowNum = 1
THEN Value2
ELSE @Values2 + ', ' + Value2
END
SELECT
EntityID
, Values1 = MAX(Values1)
, Values2 = MAX(Values2)
FROM #EntityValues
GROUP BY EntityID
SQL Server не имеет встроенного аналога функций GROUP_CONCAT и LISTAGG. Тем не менее, это не мешает, в зависимости от ситуации, эффективно выполнять задачи по конкатенации строк. Цель данного поста – наглядно это показать.










