Комментарии 313
Красивая задача
Но имхо абсолютно бестолковая в определении скила программера. Такое гденить на олимпиаде или соревновании по программированию, не очень понимаю уместность этой задачи по отношению к твиттеру.
Надо уметь мыслить нестандартно и уметь искать красивые и изящные решения, а не только сортировать разными методами.
Ведь красивое решение задачи не только приносит удовольствие (что уже само по себе немаловажно для разработчика), но и потом упрощает поддержку кода и уменьшает количество багов как если бы это просто набыдлокодить как попало.
Ведь красивое решение задачи не только приносит удовольствие (что уже само по себе немаловажно для разработчика), но и потом упрощает поддержку кода и уменьшает количество багов как если бы это просто набыдлокодить как попало.
Красивые решения зачастую специфичны и требуют понимания. Т.е можно конечно сделать красиво, но скорее всего программист который первый раз видит решение, будет некоторое время разбирать как же это решение работает. Я бы не сказал что красивое решение обязательно упрощает поддержку кода и уменьшает количество возможных багов. Можно накодить хорошо но стандартно, без красивого решения. К тому же красивое решение в какой то момент времени может прекратить работать, когда надо будет чуть чуть подправить логику работы например.
НЛО прилетело и опубликовало эту надпись здесь
Красота вещь субъективная, кто-то считает красотой обмен значений двух переменных без использования третьей.
Особенно это впечатляет, когда они вещественные. Или указатели.
Хотя есть же и xor-list…
Хотя есть же и xor-list…
Все очень сильно зависит от языка, в Lua обмен значений делается так:
И обмен через третью переменную, наоборот, выглядит странно.
x, y = y, x. И обмен через третью переменную, наоборот, выглядит странно.
В реальной работе за красивые решения оторвут ноги. Код должен быть простым и понятным, потому что его еще нужно поддерживать куче народу.
Даёшь n2 и n3 для любых задач, только пузырек только хардкор. Человек в любом случае должен уметь понимать сложность алгоритма и уметь ее понижать. Иначе никакого масштабирования не получится.
В тёмный век предела возможностей кремния нет возможности на порядок производительность каждые 5 лет
В тёмный век предела возможностей кремния нет возможности на порядок производительность каждые 5 лет
Верно. Под красотой я как раз подразумеваю понятность и лёгкость в поддержке, а не цветочки и галочки.
НЛО прилетело и опубликовало эту надпись здесь
Почему вы считаете эту задачу олимпиадной? Вполне приличная задача на «закодировать без ошибок».
Реалии таковы, что именно такие задачи задают на собеседованиях. И если честно, на них пройти шанс выше, чем на задачах проектирования. Эта задача хороша, потому что она не требует от Вас умения писать что-то «олимпиадное», просто логика, тесты и умение кодировать. На работе очень много кода будет строиться из таких маленьких задачек.
По своему опыту собеседований, люди не отвечают на серьезные вопросы дизайна. Да и после этих вопросов мне очень сложно оценить кандидата. Я трачу все собеседование на один вопрос. И это может быть очень плохо для кандидата, так как он может затупить и тогда все, второго шанса нет. С маленькими задачами лучше, так как их можно сделать 2-3 за интервью. (Когда я проходил в Фейсбук я успевал сделать 3). И если у кандидата возникли проблемы с одной задачей, вторая может его реабилитировать. Плюс, если кандидат не может написать решение в 30-50 строк, тогда простите, почему я должен поверить, что он способен написать большую работающую систему? Если человек не придумал решение, тогда почему я должен поверить, что он может их придумывать? В Твиттере решаются сложные задачи на всех уровнях. Говорить, что какая то задача плохо отражает скилл… Просто нужно решать их и все.
Эти задачи не идеальны, но компании уровня Твиттера просто нет времени проводить собеседование по 10 часов с каждым. Ведь каждое интервью — это время одного инженера, которое стоит денег. Однако, по-моему, спрашивать про фишки языка — вот это глупость, или про то, кто такой Дейкстра и что он сделал для мира программирования. Или что такое Mock тестирование? (Это вопросы реальные и мне их задавали). Эти вопросы вообще бесполезны, так как если вы напишете решение задачи, предложенной выше с верной асимптотикой и проходящее все тесты, тогда, с большое долей вероятности, вы способны освоить технологии быстро и качественно.
По своему опыту собеседований, люди не отвечают на серьезные вопросы дизайна. Да и после этих вопросов мне очень сложно оценить кандидата. Я трачу все собеседование на один вопрос. И это может быть очень плохо для кандидата, так как он может затупить и тогда все, второго шанса нет. С маленькими задачами лучше, так как их можно сделать 2-3 за интервью. (Когда я проходил в Фейсбук я успевал сделать 3). И если у кандидата возникли проблемы с одной задачей, вторая может его реабилитировать. Плюс, если кандидат не может написать решение в 30-50 строк, тогда простите, почему я должен поверить, что он способен написать большую работающую систему? Если человек не придумал решение, тогда почему я должен поверить, что он может их придумывать? В Твиттере решаются сложные задачи на всех уровнях. Говорить, что какая то задача плохо отражает скилл… Просто нужно решать их и все.
Эти задачи не идеальны, но компании уровня Твиттера просто нет времени проводить собеседование по 10 часов с каждым. Ведь каждое интервью — это время одного инженера, которое стоит денег. Однако, по-моему, спрашивать про фишки языка — вот это глупость, или про то, кто такой Дейкстра и что он сделал для мира программирования. Или что такое Mock тестирование? (Это вопросы реальные и мне их задавали). Эти вопросы вообще бесполезны, так как если вы напишете решение задачи, предложенной выше с верной асимптотикой и проходящее все тесты, тогда, с большое долей вероятности, вы способны освоить технологии быстро и качественно.
А почему тогда потом работники на компьютере код пишут? Пусть дальше на бумажках рисуют! Ведь именно этот скилл у них на собеседовании проверяется. Эта дурость уже полностью зафейлена, можно надрочиться на подобных задачках на ресурсах типа глассдора, при этом абсолютно не обязательно быть специалистом, достаточно просто эту хрень решать. Тем более что в 90% случаев эти задачки из одного пула берутся.
Пока практика показывает, что этот метод работают. У нас работают крутые инженеры и фейлов не много. Метод не идеален, однако лучше нет. Почему Вы думаете, что что-то изменится, если будете писать на компе? Он Вам решение нашепчет? Время интервью хотите экономить? Так Вам же хорошо, если дольше будете писать одну задачу. Вопросы не нравятся? Что тогда спрашивать? Как реализовать систему? Так это тоже спрашивают. Если откроете книгу «Cracking coding interview», то увидите, что про это есть глава. Только кандидатам хуже от этих вопросов — они намного сложнее. Спрашивать про язык? А зачем? Допустим Вы спец по с++. «Надрочились», так сказать. А завтра надо будет на python писать, и вы скажете — я не умею… Не хорошо. Может быть спрашивать про технологии? Про SDK? Про инструменты? Ну совсем странно. Хм… А можно ли спрашивать что-то не требующее специальных знаний, чтобы кандидат показал, что он может учиться, что у него есть соображалка? Ах да, мы это и спрашиваем.
Я провел много интервью, и почему-то «надрочившихся» не видел. Зато видел, как люди думают, умеют ли писать код, а не жать «Generate method». Свои задачи я придумываю сам. Мои коллеги тоже. Но проблема в том, что я спрашивал «из пула» — не ответили…
Я провел много интервью, и почему-то «надрочившихся» не видел. Зато видел, как люди думают, умеют ли писать код, а не жать «Generate method». Свои задачи я придумываю сам. Мои коллеги тоже. Но проблема в том, что я спрашивал «из пула» — не ответили…
Я действительно не могу придумать другого метода. Но и в этом вижу недостатки.
Я принципиально почти никогда не готовлюсь к собеседованиям (как и к экзаменам), считая что подготовка исказит результаты.
И в этой ситуации возникает ощущение (может быть конечно ложное), что люди поготовившиеся пару дней имеют бОльшие шансы. Скажем спросили на собеседовании задачу на топологическую сортировку, я про существование её помнил, но даже идеи алгоритма не помнил, на ходу придумать не смог. А потом прочитал на емаксе — она оказалась тривиальнейшей.
И вот ещё, всегда было интересно, почему на собеседованиях спрашивают задачи такого рода? Что проверяется?
1) Наличие мозга? Ну тогда надо давать задачи, к которым невозможно подготовиться, а не какие-то общеизвестные алгоритмы.
2) Знание базовых алгоритмов (dfs/bfs/dijkstra/беллман-форд и т.д.)? Зачем? Ведь в реальной работе они хоть и встречаются — но не часто. Знать их ради тех редких случаев, когда они понадобятся?
Интуитивно я согласен, по какой-то причине работать с людьми, знающими эти вещи приятнее. Но вот обосновать я это не могу.
Ну и тут извечный спор о полезности спортивного программирования для работы. Получается что вопросы на собеседовании (речь идёт не о задаче из данного поста, конечно, она тривиальна) требуют уровня СП, но на самой работе делаешь другое (хотя и не менее интересное). В процессе работы учишься, получаешь опыт, но при этом он не увеличивает твои шансы пройти новое собеседование. Так что же человек должен днём повышать свой профессиональный скилл, а вечерами заниматься СП, чтобы уметь проходить через всё более сложные собеседования? Двойная жизнь какая-то получается. А если мне спортивное программирование уже надоело, т.к. на работе задачи интереснее? Или же СП всё-таки помогает достигать лучших результатов в работе, даже если напрямую и не связан с ней? Как вот это всё измерить?
Я принципиально почти никогда не готовлюсь к собеседованиям (как и к экзаменам), считая что подготовка исказит результаты.
И в этой ситуации возникает ощущение (может быть конечно ложное), что люди поготовившиеся пару дней имеют бОльшие шансы. Скажем спросили на собеседовании задачу на топологическую сортировку, я про существование её помнил, но даже идеи алгоритма не помнил, на ходу придумать не смог. А потом прочитал на емаксе — она оказалась тривиальнейшей.
И вот ещё, всегда было интересно, почему на собеседованиях спрашивают задачи такого рода? Что проверяется?
1) Наличие мозга? Ну тогда надо давать задачи, к которым невозможно подготовиться, а не какие-то общеизвестные алгоритмы.
2) Знание базовых алгоритмов (dfs/bfs/dijkstra/беллман-форд и т.д.)? Зачем? Ведь в реальной работе они хоть и встречаются — но не часто. Знать их ради тех редких случаев, когда они понадобятся?
Интуитивно я согласен, по какой-то причине работать с людьми, знающими эти вещи приятнее. Но вот обосновать я это не могу.
Ну и тут извечный спор о полезности спортивного программирования для работы. Получается что вопросы на собеседовании (речь идёт не о задаче из данного поста, конечно, она тривиальна) требуют уровня СП, но на самой работе делаешь другое (хотя и не менее интересное). В процессе работы учишься, получаешь опыт, но при этом он не увеличивает твои шансы пройти новое собеседование. Так что же человек должен днём повышать свой профессиональный скилл, а вечерами заниматься СП, чтобы уметь проходить через всё более сложные собеседования? Двойная жизнь какая-то получается. А если мне спортивное программирование уже надоело, т.к. на работе задачи интереснее? Или же СП всё-таки помогает достигать лучших результатов в работе, даже если напрямую и не связан с ней? Как вот это всё измерить?
Вообще давать задачу на Топологическую сортировку не хорошо — я согласен. То есть с первым пунктом я полностью согласен. И частично не согласен со вторым. Понимаете, когда я, собеседуя человека, на вопрос о сложности алгоритма получаю ответ, что алгоритм не сложный… Мне кажется это сразу отказ! Это основа. Если вы хотите работать в Google или компании такого рода — это нужно знать. Вопросов почему здесь быть не может. Потому что это Google. DFS, BFS — тоже. Так как просто понимать что такое граф — необходимо. Значит базовую работу с ними нужно уметь делать. DFS помогает в понимании рекурсии, что очень важно. BFS в знании очереди, то есть базовой структуры данных, которые тоже знать необходимо. А вот алгоритм Дейкстры, Форда-Беллмана, потоки и т.п. спрашивать на интервью не нужно — это и правда спец знания. Хотя… Если вы допустим хотите работать с графами (ну например в ФБ в соц. графе) наверное спросить про алгоритмы путей можно.
Готовиться к собеседованию можно, но даже если вы видели задачу, то каков шанс, что вы мне ее объясните и напишите без ошибок? Я спрашивал задачу, которая была во многих местах для эксперимента. Мне говорили ответ. Но когда я слегка ее модифицировал (просто добавил размерность) — почти никто не мог ответить. Те, кто жалуются на вопросы, просто не понимают альтернативы. Проектировать сложнее, чем решать. На вопросы дизайна ответить сложнее, чем накодить задачу.
Теперь про СП.
Я все еще участвую в контестах, так как это помогает мне думать быстрее. Я стал намного продуктивнее в разработке (не кодировании, а именно в разработке — то есть дизайн, проектирование, организация и т.д.), когда снова стал решать. Может быть это только у меня так. Не знаю.
Но еще небольшой момент. У меня много знакомых программистов олимпиадников. И я, если честно, затрудняюсь сказать, кто из них не устроился работать в крутую компанию. Кто не захотел уехать — те в Яндексе или в самых лучших местах в родном городе. И все они работают хорошо — то есть получают повышения, интересные проекты. Я ни в коем случае не говорю, что СП — это единственное. У меня также много знакомых, которые прекрасно работают, не занимаясь СП. Это ответ на ваши вопросы. Как измерить? Я просто вижу живые примеры.
Готовиться к собеседованию можно, но даже если вы видели задачу, то каков шанс, что вы мне ее объясните и напишите без ошибок? Я спрашивал задачу, которая была во многих местах для эксперимента. Мне говорили ответ. Но когда я слегка ее модифицировал (просто добавил размерность) — почти никто не мог ответить. Те, кто жалуются на вопросы, просто не понимают альтернативы. Проектировать сложнее, чем решать. На вопросы дизайна ответить сложнее, чем накодить задачу.
Теперь про СП.
Я все еще участвую в контестах, так как это помогает мне думать быстрее. Я стал намного продуктивнее в разработке (не кодировании, а именно в разработке — то есть дизайн, проектирование, организация и т.д.), когда снова стал решать. Может быть это только у меня так. Не знаю.
Но еще небольшой момент. У меня много знакомых программистов олимпиадников. И я, если честно, затрудняюсь сказать, кто из них не устроился работать в крутую компанию. Кто не захотел уехать — те в Яндексе или в самых лучших местах в родном городе. И все они работают хорошо — то есть получают повышения, интересные проекты. Я ни в коем случае не говорю, что СП — это единственное. У меня также много знакомых, которые прекрасно работают, не занимаясь СП. Это ответ на ваши вопросы. Как измерить? Я просто вижу живые примеры.
Понимаете, когда я, собеседуя человека, на вопрос о сложности алгоритма получаю ответ, что алгоритм не сложный… Мне кажется это сразу отказ!
А дело всего-то в том, что в тех книжках, по которым человек учился, это называлось worst time, или как-нибудь ещё… Ну ничего, повезёт другому работодателю.
«Algorithm Complexity» или «Big-O notation» — то что я знаю и использую и меня всегда понимали на работе, на интервью, на формах и т.д. С «Worst time» я бы не согласился. К тому же я сделал скидку на волнение кандидата и свой кривой английский, и переформулировал вопрос несколько раз. Другому работодателю не повезет.
К тому же я сделал скидку на волнение кандидата и свой кривой английский, и переформулировал вопрос несколько раз.
Разве это называется «сразу отказ»?
Интересно, что бы сделали с кандидатом, который не помнит, какой из многочисленных алгоритмов сортировки называется сортировкой пузырьком. Или какой из обходов графа принято называть обходом в глубину, а какой — в ширину (т.е. какая компонента динамики обхода используется в названии — быстрая или медленная). Мне это так и не удалось запомнить :(
Я уже говорил выше, что я не люблю терминологию в интервью. Но не знание, что такое сложность алгоритма — это сразу отказ (не термина сложность, а сути).
А что такое быстрая или медленная компонента динамики обхода? Вообще обход в глубину и в ширину сами как бы в названии говорят как они работают. Если вы знаете как они работают, то перепутать их сложно.
Вообще по-моему вы сейчас больше придираетесь, так как ясно, что интервью гибкий процесс со множеством подсказок. Я очень рад, если кандидат начинает диалог — например, «хм… я знаю обходы графа, но совершенно не помню термины. Обход с использованием очереди, когда мы проходим граф слой за слоем, как он называется?» Тогда я отвечу: «В ширину!» и даже не подумаю, что это минус. А если вопрос будет: «Граф? А что это?». Тут сложнее что-то ответить.
А что такое быстрая или медленная компонента динамики обхода? Вообще обход в глубину и в ширину сами как бы в названии говорят как они работают. Если вы знаете как они работают, то перепутать их сложно.
Вообще по-моему вы сейчас больше придираетесь, так как ясно, что интервью гибкий процесс со множеством подсказок. Я очень рад, если кандидат начинает диалог — например, «хм… я знаю обходы графа, но совершенно не помню термины. Обход с использованием очереди, когда мы проходим граф слой за слоем, как он называется?» Тогда я отвечу: «В ширину!» и даже не подумаю, что это минус. А если вопрос будет: «Граф? А что это?». Тут сложнее что-то ответить.
Быстрая или медленная компонента (в моём понимании, тут я опять не знаю терминов) — это так: мы быстро и много раз обходим граф «в ширину» и при этом медленно продвигаемся «в глубину». Или наоборот — часто проходим его «в глубину» до конца, медленно заметая его «в ширину». Перепутать очень легко, тем более, что вариантов названия всего два, и ни у одного нет логического преимущества перед другим.
А уж запомнить аббревиатуры DFS и BFS может только тот, кто узнал их до того, как начал использовать эти алгоритмы. Потому что лучше тратить ресурсы на изучение новых алгоритмов, чем выяснять и запоминать, что «мы говорим прозой».
А уж запомнить аббревиатуры DFS и BFS может только тот, кто узнал их до того, как начал использовать эти алгоритмы. Потому что лучше тратить ресурсы на изучение новых алгоритмов, чем выяснять и запоминать, что «мы говорим прозой».
Хм… В каждом алгоритме мы пройдем все ребра один раз. Сложность одинаковая. O(E). Много раз мы ничего не проходим. Везде все тоже самое. Перепутать два варианта с учетом названий сложно. Но это мое субъективное мнение. Я поверю, что возможно это сложно.
Вообще можно без терминологии жить и разрабатывать что-то с помощью чего-то при помощи какого-то там. Но без терминов вас не поймут. Неужели так сложно выучив и поняв новый алгоритм еще заодно запомнить как он называется? В математике вы учили теоремы с названиями. Тоже зачем? Ну чтобы вас понимали и понимали о чем вы говорите. Почему я должен поверить на интервью, что кандидат знает алгоритм, но не знает название? Особенно таких стандарных вещей, как обходы графов. Это, к сожалению, уже проблемы кандидата. И то, что какой-то компании повезет — может быть, но я лучше перестрахуюсь и не поверю.
Вообще можно без терминологии жить и разрабатывать что-то с помощью чего-то при помощи какого-то там. Но без терминов вас не поймут. Неужели так сложно выучив и поняв новый алгоритм еще заодно запомнить как он называется? В математике вы учили теоремы с названиями. Тоже зачем? Ну чтобы вас понимали и понимали о чем вы говорите. Почему я должен поверить на интервью, что кандидат знает алгоритм, но не знает название? Особенно таких стандарных вещей, как обходы графов. Это, к сожалению, уже проблемы кандидата. И то, что какой-то компании повезет — может быть, но я лучше перестрахуюсь и не поверю.
Значит, надо запомнить, что с графами — не так, как с матрицами. Когда мы обходим матрицу «по строчкам», то просматриваем первую строчку целиком, потом вторую… Когда обходим граф «в ширину» — просматриваем первый уровень глубины, потом второй… Если не встретится ещё какой-нибудь структуры, у которой будет своя логика названий, то запомнить, наверное, удастся.
Если название узнал лет через 10 после того, как стал работать с этим алгоритмом, то может оказаться сложно их связать. В конце концов, обходы графов и поиск кратчайшего пути действительно очевидны. А название… можно выучить, как новое иностранное слово, когда действительно придётся пользоваться им в разговорах.
Неужели так сложно выучив и поняв новый алгоритм еще заодно запомнить как он называется?
Если название узнал лет через 10 после того, как стал работать с этим алгоритмом, то может оказаться сложно их связать. В конце концов, обходы графов и поиск кратчайшего пути действительно очевидны. А название… можно выучить, как новое иностранное слово, когда действительно придётся пользоваться им в разговорах.
Проще всего — представить, как алгоритмы обойдут полный граф (т.е. граф, где между любыми двумя вершинами есть ребро).
Обход в ширину сделает из этого графа звезду, поскольку дойдет до всех вершин из первой. А обход в глубину пройдет все вершины последовательно, сделав из графа длинную цепочку. Лично мне этот способ запоминания казался всегда наглядным.
Обход в ширину сделает из этого графа звезду, поскольку дойдет до всех вершин из первой. А обход в глубину пройдет все вершины последовательно, сделав из графа длинную цепочку. Лично мне этот способ запоминания казался всегда наглядным.
Такое гденить на олимпиаде или соревновании по программированию,
Скажите, такие задачи разве дают на олимпиадах? Я плохой программист и не олимпиадник, но алгоритм решение этой задачи по принципу описанному в конце пришел моментально. Даже не особо понял что он там напридумывал с локальными максимумами.
А еще это называется Water filling algorithm. Но зачем такое знать человеку, который в Твитере работать собрался?
Почему-то сразу вспомнилось решение для Convex Hull.
Задачка интересная.
Я вот только одного не понимаю — каким образом навык быстрого решения подобных задач хоть как-то характеризует разработчика?
Ну ок, ладно, можно как-то оценить, как человек ищет решение. Каким образом это характеризует разработчика?
Как это расскажет, пишет ли он читаемый код, правильно ли выделяет уровни абстракции, хорошо ли понимает чужой код, точно ли декомпозирует задачи?
Я вот только одного не понимаю — каким образом навык быстрого решения подобных задач хоть как-то характеризует разработчика?
Ну ок, ладно, можно как-то оценить, как человек ищет решение. Каким образом это характеризует разработчика?
Как это расскажет, пишет ли он читаемый код, правильно ли выделяет уровни абстракции, хорошо ли понимает чужой код, точно ли декомпозирует задачи?
НЛО прилетело и опубликовало эту надпись здесь
Какой скучный ответ.
НЛО прилетело и опубликовало эту надпись здесь
На самом деле не правильно думаете. forgotten правильные вещи говорит.
Главное в разработчике это то как он пишет код и взаимодействует с командой, да хотя бы банально умеет ли пользоваться гитом, у человека надо узнать тип его мышления и то как этот тип может доперать до решения задачи. А эту задачка реально уровня школьника для олимпиад, если надр<...>ся на на них будешь фигачить пачками, а когда тебе дадут задачу сделать какой-нибудь заумный сервис, голова тупо не сможет осилить, не то что реализовать, так как для этого нужно как раз то что я написал вначале: культура кода, умение работать в команде.
Мораль такова, умение щелкать задачки по олимпиаде еще не означает, что ты крутой разработчик.
Мне кажется, что интервьюеру было лень разбираться, таких много. У обязанности такие, начальство выбирает нескольких девелоперов на собеседование, те ставят оценку, этому было влом.
Главное в разработчике это то как он пишет код и взаимодействует с командой, да хотя бы банально умеет ли пользоваться гитом, у человека надо узнать тип его мышления и то как этот тип может доперать до решения задачи. А эту задачка реально уровня школьника для олимпиад, если надр<...>ся на на них будешь фигачить пачками, а когда тебе дадут задачу сделать какой-нибудь заумный сервис, голова тупо не сможет осилить, не то что реализовать, так как для этого нужно как раз то что я написал вначале: культура кода, умение работать в команде.
Мораль такова, умение щелкать задачки по олимпиаде еще не означает, что ты крутой разработчик.
Мне кажется, что интервьюеру было лень разбираться, таких много. У обязанности такие, начальство выбирает нескольких девелоперов на собеседование, те ставят оценку, этому было влом.
Знание гита — не критично, и гиту можно обучить в будущем.
Эта же задача как раз была на тип мышления, в частности обратить внимание на то, что просто на локальных максимумах код будет работать неправильно. Кроме того, автор сделал ошибку, спрашивая Джастина будет ли работать или нет, да еще и обвиняет в статье, что тот сказал будет. Задача была как раз на то, чтобы автор заметил что работать не будет. Ну и кроме того, отсылает то задачу он сырцом. По нему я думаю можно определить спагетти код это или нет.
Я считаю такую задачу оправданной в качестве задачи для собеседования. Только мне кажется им надо было подготовить все таки несколько задач, потому что по одной сфейленой задаче сложно оценить человека.
Эта же задача как раз была на тип мышления, в частности обратить внимание на то, что просто на локальных максимумах код будет работать неправильно. Кроме того, автор сделал ошибку, спрашивая Джастина будет ли работать или нет, да еще и обвиняет в статье, что тот сказал будет. Задача была как раз на то, чтобы автор заметил что работать не будет. Ну и кроме того, отсылает то задачу он сырцом. По нему я думаю можно определить спагетти код это или нет.
Я считаю такую задачу оправданной в качестве задачи для собеседования. Только мне кажется им надо было подготовить все таки несколько задач, потому что по одной сфейленой задаче сложно оценить человека.
Человек, решающий такую задачу, вовсе не «лучший из лучших», а хороший олимпиадник.
Он может совершенно легко писать жутчайший спагетти-код.
И, кстати, далеко не факт, что «лучшие из лучших» захотят работать на фирму, чья единственная цель состоит в увеличении энтропии Вселенной.
Он может совершенно легко писать жутчайший спагетти-код.
И, кстати, далеко не факт, что «лучшие из лучших» захотят работать на фирму, чья единственная цель состоит в увеличении энтропии Вселенной.
НЛО прилетело и опубликовало эту надпись здесь
Вы наивно полагаете, что олимпиадное задание способно отсеять человека со средним интеллектом.
Можно подумать, высокий интеллект означает умение решать олимпиадные задачи.
С тем же успехом можно сказать, что атлет, который с лёгкостью поднимает тяжеленную штангу, слаб, потому что не может бодро прыгать со скакалкой.
Это просто разные вещи.
Можно подумать, высокий интеллект означает умение решать олимпиадные задачи.
С тем же успехом можно сказать, что атлет, который с лёгкостью поднимает тяжеленную штангу, слаб, потому что не может бодро прыгать со скакалкой.
Это просто разные вещи.
НЛО прилетело и опубликовало эту надпись здесь
Пример со скакалкой и атлетом не в тему.
Вполне может, более того, часто, скакалка одно из необходимых упражнений.
Вы давно на скакалке прыгали? Попробуйте хотя б минут 10 поскакать.
Первая же ссылка из гугла про скакалку
Вполне может, более того, часто, скакалка одно из необходимых упражнений.
Вы давно на скакалке прыгали? Попробуйте хотя б минут 10 поскакать.
Первая же ссылка из гугла про скакалку
Вас не спрашивают олимпиадные задачи! Почитайте задачи с финала Mail.Ru, или с opencup.ru. Вот это олимпиадные задачи. Там надо тренироваться, знать алгоритмы, оценивать время работы, знать хаки языка, быстро придумывать, строить из заготовок и многое другое.
Эта задача не сложная. Я не полагаю, я знаю, что вас спросят не одну это задачу, а 3-4. И они в сумме покажут много чего. Знание гита, с++ или предыдущий опыт мне ничего не скажут. Я не работал с Вами, я не буду в шоке от того, как вы круто манипулируете клавиатурой со скоростью набора 200 символов в минуту. Я скажу — этот кандидат решил поставленную задачу, задал верные вопросы, знает как оценивать сложность решения и пишет код умно (то есть не сажает тупых ошибок, которые потом не найти).
Я не занимаюсь штангой, но перед каждым занятием Muay Thai я должен прыгать на скакалке. Кстати видел как разминаются штангисты на днях :) догадаетесь?
Эта задача не сложная. Я не полагаю, я знаю, что вас спросят не одну это задачу, а 3-4. И они в сумме покажут много чего. Знание гита, с++ или предыдущий опыт мне ничего не скажут. Я не работал с Вами, я не буду в шоке от того, как вы круто манипулируете клавиатурой со скоростью набора 200 символов в минуту. Я скажу — этот кандидат решил поставленную задачу, задал верные вопросы, знает как оценивать сложность решения и пишет код умно (то есть не сажает тупых ошибок, которые потом не найти).
Я не занимаюсь штангой, но перед каждым занятием Muay Thai я должен прыгать на скакалке. Кстати видел как разминаются штангисты на днях :) догадаетесь?
О, вам тоже не нравится Твиттер? :)
НЛО прилетело и опубликовало эту надпись здесь
Не смог удержаться:
Да впринципе никак, таким компаниям это вообще не надо, для них главное умение нестандартно мыслить :)
Нестандартно мыслить? Главное для разработчика в Твиттере? А зачем?
Это просто идеология компании такая. Они к разработчикам относятся, как к ключевым людям в компании. Они ждут от разработчиков идей, которые помогут развивать продукт и бизнес компании. Делать то, что раньше никто не делал. Это не та компания, где разработчик приходит на работу, а у него на столе талмуд от Product Manager с подробным описанием следующей фичи, а разработчику надо только аккуратно закодить, то что требуется. Это просто разные подходы к должности.
Тем не менее, это не ответ на вопрос «зачем».
Почему это не ответ? Если ты хочешь чтобы твоя компания выигрывала у конкурентов, тебе надо делать то, что никто больше не делает, а для этого тебе нужны люди, которые мыслят не стандартно и умют эти мысли вополщать в дело.
Безусловно, нужны люди, которые способны мыслить нестандартно и абстрактно. Но для реализации этих идей отлично подходят хорошие исполнители: им дали задачу, они сделали качественное решение. Как-то по-другому думать при этом вовсе не нужно.
В твиттере считают, что реализовывать идею лучше доверить автору этой идеи. В этом если подумать есть смысл. Иногда реализация идеи важнее самой идеи и в процессе реализации могут возникать очень сложные проблемы требующие опять же не стандартных подходов. Если отдавать такую реализацию людям которые умеют только кодить по шаблонам программирования и код лесенкой оформлять, то лучше даже и не браться. Программирование, как известно это не стрижка газонов, и если ты хочешь толкать индустрию и возможности железа туда где еще никто не был, то мелочей которые можно доверить кому-то другому почти не остается.
Не так: тебе нужны и люди, которые мыслят нестандартно, и люди, которые умеют эти мысли воплощать в дело. Очевидно, в компаниях чуть более, чем из одного человека, это должны быть разные люди; притом первым не обязательно уметь программировать, а вторым решать задачки на скорость. Весь опыт человечества как бы подсказывает нам, что разделение труда в этом месте рулит; непонятно, зачем софтверные компании регулярно на эти грабли наступают — в условиях кадрового голода, ага — и притом в результате нанимают каких-то невнятных индусов.
Не знаю как насчет опыта всего человечества, но мой личный опыт мне говорит, что чем меньше людей которые не умеют программировать и пишут хорошие алгоритмы трогают код, тем лучше он в результате оказывается.
Я ничего не понял.
Ок. Поясняю. Твиттер нанимает программиста. Ему дают задачку на программирование. Задачка хорошая. Красивая. Решение предлагается не правильное. Человек не нанимается. Что не так? Нет у твиттера разделения труда на классы программистов. Все должны мочь делать все.
Ага. А зачем?
Чтобы не тратить время и силы на перевод с языка алгоритмиста на язык кодера? И сохранить возможность алгоритмисту разобраться, правильно ли кодер воплотил его идеи.
Пара «алгоритмист с неплохим навыком кодирования» и «кодер с неплохим пониманием алгоритмов», очевидно, гораздо сильнее пары посредственных кодероалгоритмистов. Это ж типичный маговоин выходит.
Потому что программировать этот человек, может быть, умеет, а вот алгоритм придумать не может. Так что он не попадает в «чем меньше людей, которые...» по обоим признакам — и его надо брать. Даже два раза :)
Я тоже. С терминами «умеют программировать» и «пишут хорошие алгоритмы» что-то случилось. Либо они обозначают одно и то же — и тогда получаем противоречие, либо «пишут» надо заменить на «разрабатывают» — и получаем разделение труда, противоречащее предыдущим комментариям.
Видится мне, что одного без другого не бывает.
Бывает, знаю вагон примеров. Если уж на то пошло, то способность человека нестандартно мыслить в стрессовой ситуации вообще абсолютно ничегошеньки не имеет общего со способностью нестандартно мыслить в рабочей ситуации.
Ну почему все сразу негативно относятся к такому виду собеседования?
Лично я тоже даю на собеседованиях такие задачи, но я смотрю на другое.
Мне важны следующие параметры в порядке приоритета:
1) Решена ли задача (задача несложная, решить ее как угодно можно за 5 минут)
Если задача не решена — разговаривать просто не о чем. Лучше решение за O(N^2), чем вообще никакого.
2) Безопасность решения (зависит от сферы применения: thread safe, race condition etc) Частично вложено в п. 1
3) Читабельность/гибкость
4) Оптимальность
5) Элегантность
etc
Этот чел предложил неправильное решение (это ОК; кто не ошибается — тот ничего не делает), но он не смог протестировать свое решение и отдал решение на проверку собеседователю (фактически он отдал нерабочий код в продакшен). Вы же в голову к человеку не залезете? А если он так будет подходить к коду, который потом попадет в реальный продакшен? Лучше лишний раз подстраховаться и не взять хорошего разраба, чем взять плохого.
Лично я тоже даю на собеседованиях такие задачи, но я смотрю на другое.
Мне важны следующие параметры в порядке приоритета:
1) Решена ли задача (задача несложная, решить ее как угодно можно за 5 минут)
Если задача не решена — разговаривать просто не о чем. Лучше решение за O(N^2), чем вообще никакого.
2) Безопасность решения (зависит от сферы применения: thread safe, race condition etc) Частично вложено в п. 1
3) Читабельность/гибкость
4) Оптимальность
5) Элегантность
etc
Этот чел предложил неправильное решение (это ОК; кто не ошибается — тот ничего не делает), но он не смог протестировать свое решение и отдал решение на проверку собеседователю (фактически он отдал нерабочий код в продакшен). Вы же в голову к человеку не залезете? А если он так будет подходить к коду, который потом попадет в реальный продакшен? Лучше лишний раз подстраховаться и не взять хорошего разраба, чем взять плохого.
Ну а мне в первую очередь важно, как человек умеет работать с абстракциями, насколько он хорошо себе их представляет, насколько он может читать код и насколько он понимает, как писать читаемый код самому. Кажется, ни один из этих навыков предложенное задание не тестирует.
Собеседователь плохо отревьюил решение.
Не протестированное решение поехало в продакшн.
А весь workflow выглядит так: сам придумал, сам написал, сам протестировал, сам закомитил, сам выкатил.
Не протестированное решение поехало в продакшн.
А весь workflow выглядит так: сам придумал, сам написал, сам протестировал, сам закомитил, сам выкатил.
Мне кажется, что нельзя конструктивно обсуждать это конкретное собеседование.
Мы знам версию только одной стороны и она может быть сильно искажена.
Просто весь вайн начался на тему: «Вот опять олимпиадные задачи на интервью»
ИМХО такой способ проверки не так плох, как кажется. Просто надо его правильно использовать. Именно об этом я написал выше.
Опять же автор не знает, на чем именно он завалился. Возможно интервьюер уже сказал себе НЕТ на раннем этапе — просто из вежливости дослушал ну или что-то в этом роде. Ну или сомневался или все что угодно.
Мы знам версию только одной стороны и она может быть сильно искажена.
Просто весь вайн начался на тему: «Вот опять олимпиадные задачи на интервью»
ИМХО такой способ проверки не так плох, как кажется. Просто надо его правильно использовать. Именно об этом я написал выше.
Опять же автор не знает, на чем именно он завалился. Возможно интервьюер уже сказал себе НЕТ на раннем этапе — просто из вежливости дослушал ну или что-то в этом роде. Ну или сомневался или все что угодно.
Ещё проблема (для меня) — в стрессовых ситуациях. Не раз бывало, что на собеседовании задача не решена, или решена совсем плохо — по пути домой в голову приходит отличное решение. Но уже увы.
Мне кажется, что провалом было не неверное перво решение, а то, что не было тестов, которые бы значительно отличались от первого. Не было продумано «а в каких ещё условиях может работать этот код».
Автор оригнального поста является еще студентом и собеседовался на позицию стажёра. Очевидно, что опыта промышленной разработки ПО скорее всего у него очень мало, потому имеет смысл посмотреть как человек решает такие задачки.
Я тоже противник подобных «олимпиадных» задач на собеседованиях — действительно, они не выявляют наличие или отсутствие скиллов хорошего разработчика.
Однако мне кажется на данный вопрос нужно взглянуть с другой стороны: а почему Twitter задаёт такие задачи? Может быть, они ищут не очередного фронт-ендщика, а кого-то другого. Может быть, кандидат будет работать в области, где нужно решать по какому алгоритму распределять пользователей по серверам БД, опираясь на специфику нагрузки именно на twitter.com. И при их объёмах, разница во времени обработки запроса в жалкие 10 мс — критична в плане нагрузки на CPU. Среднестатистический веб-разработчик, имеющий опыт работы с кучей систем контроля версий, умеющий верстать с закрытыми глазами, имеющий опыт построения сложных enterprise-систем, гуру ООП и декомпозиции — не выжмет эти 10 мс. «Олимпиадник» — возможно (хотя бы, сэкономив на кол-ве вызовов функций во время работы данного алгоритма, игнорируя SRP, абстракции и превратив код в трудновоспринимаемую лапшу).
А может быть они и просто выкаблучиваются на ровном месте, т.к. поток собеседований бесконечен и тратить по 2 часа на очередного кандидата слишком неэффективно :))
Однако мне кажется на данный вопрос нужно взглянуть с другой стороны: а почему Twitter задаёт такие задачи? Может быть, они ищут не очередного фронт-ендщика, а кого-то другого. Может быть, кандидат будет работать в области, где нужно решать по какому алгоритму распределять пользователей по серверам БД, опираясь на специфику нагрузки именно на twitter.com. И при их объёмах, разница во времени обработки запроса в жалкие 10 мс — критична в плане нагрузки на CPU. Среднестатистический веб-разработчик, имеющий опыт работы с кучей систем контроля версий, умеющий верстать с закрытыми глазами, имеющий опыт построения сложных enterprise-систем, гуру ООП и декомпозиции — не выжмет эти 10 мс. «Олимпиадник» — возможно (хотя бы, сэкономив на кол-ве вызовов функций во время работы данного алгоритма, игнорируя SRP, абстракции и превратив код в трудновоспринимаемую лапшу).
А может быть они и просто выкаблучиваются на ровном месте, т.к. поток собеседований бесконечен и тратить по 2 часа на очередного кандидата слишком неэффективно :))
Они могут себе такое позволить, обычно такие задачки идут на потоковые вакансии, на которые можно брать вообще любого и он справится, но так неспортивно, поэтому устравается этот бег в мешках, чтобы отсеять 90% кандидатов. С тем же успехом можно было выбирать случайно из кандидатов человека и нанимать.
А вот когда целевая вакансия на конкретного специалиста, тут начинаются уже настоящие собеседования, на правильные темы с правильной оценкой.
А вот когда целевая вакансия на конкретного специалиста, тут начинаются уже настоящие собеседования, на правильные темы с правильной оценкой.
Может я что-то упустил, но на какую вакансию автор оригинального поста устраивался в Twitter? Так как задачка, скажем так, специфическая.
«Следом Джастин попросил меня написать несколько тестов»
Что за нелепые тесты вы написали? Если бы вы нормально написали тесты, то сразу бы поняли свою ошибку. Тест как на последней картинке как раз бы и не прошел. Только из-за этого я бы вас и не взял на работу, а то что ошиблись — бывает.
Что за нелепые тесты вы написали? Если бы вы нормально написали тесты, то сразу бы поняли свою ошибку. Тест как на последней картинке как раз бы и не прошел. Только из-за этого я бы вас и не взял на работу, а то что ошиблись — бывает.
Когда тесты пишутся после реализации алгоритма, такое часто бывает.
Это перевод и автор топика, в общем-то, ни при чем. Но полностью согласен с Вашим недоумением, контртест для решения с локальными минимумами придумывается на раз.
Вряд ли что-нибудь изменилось, если бы переводчик написал тесты :)
PS опять не обновил комменты…
PS опять не обновил комменты…
Я немного не понял второго решение, разве оно правильно сработает на массиве [2,5,3,3,7,2,7,6], т.е. когда у нас 2 лужы…
Upd. это оказывается второй комментарий на gist :)
Upd. это оказывается второй комментарий на gist :)
Есть ощущение, что ваше решение не будет работать в случае, если в середине массива есть «высокая стена», а крайние «башенки» имеют не одинаковую высоту.
Если он находит предварительно максимум, то это уже не один проход.
Мне кажется, нужно идти одновременно с двух концов и корректировать объём по мере прохода.
Мне кажется, нужно идти одновременно с двух концов и корректировать объём по мере прохода.
Вот из-за таких вопросов на собеседовании и понижается самооценка. Ты можешь писать код, который работает и даже неплохо работает, ты будешь хотеть устроиться на работу, где хотят от тебя то же самое что ты и делал перед этим, но обязательно кто-то должен спросить «как спуститься с квадратного люка имея лишь Х метров круглого и какой из них догорит быстрее?». Потом после заваленного интервью посмотришь форумы, где сотни людей спорят как это лучше решить — через индексы Миклухо-МакКлая или Неопределенный Бульбулятор Фримана и ощущаешь себя таким ничтожеством — потому что не только не знаешь все эти методы, но даже не понимаешь где и кому все эти навыки могут пригодиться.
решил закодить эту задачу
вызывать так
int sum(int *m,int count,int s) //s играет роль локальной переменной, минус одна строка
{
for(int i=1;i<count;i++)
if(m[i]<m[0]) s+=m[0]-m[i];
else return s+sum(&m[i],count-i,0);
return 0;
}
вызывать так
int m[]={1,5,3,3,5,2,1,8};
int s=sum(m,sizeof(m)/sizeof(int),0);
Задача плохо поставлена. Не сказано, какой уровень воды. Я могу вообще сказать, что он затопит все вокруг (см. картинку 3), а значит будет просто myarr.Select(x=>maxlevel-x).Sum();
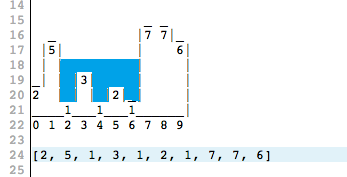
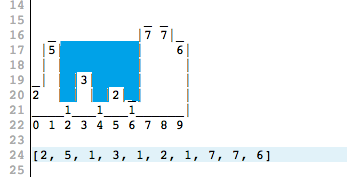
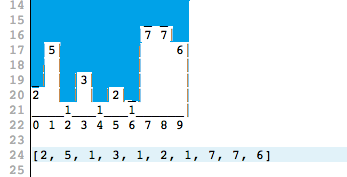
То есть можно догадаться о том, что имелось ввиду, но догадываться от постановки задачи сильно отличается. например, почему лужа не между тройкой и семеркой, а между пятеркой? для точки [4] локальными максимумами будут 3 и 2, но мы заливаем между 5 и 7.
«На картинке выше все, что расположено слева от точки 1, выплескивается. Вода справа от точки 7 также прольется.»
Вас бы тоже не взяли.
Вас бы тоже не взяли.
Стен -1 и 10 нету. Вода сливается к нулю по краям. А насчет «недолива», в условии и не оговорено время, которое идет дождь, про его остановку ничего не сказано, так что вполне логично предположить что он зальет по максимуму. Ну мне кажется все именно так.
НЛО прилетело и опубликовало эту надпись здесь
НЛО прилетело и опубликовало эту надпись здесь
>>Всегда в этот момент хочется попросить интервьюера решить в ответ задачу аналогичной сложности.
Блин-блинский!
Да ведь это же отличный способ поглумиться, когда ты идешь на пяток интервью чисто для тренировки перед Самым Главным Интервью :)
Блин-блинский!
Да ведь это же отличный способ поглумиться, когда ты идешь на пяток интервью чисто для тренировки перед Самым Главным Интервью :)
Про сапогом по лицу — Вы случаем не это в виду имеете: www.youtube.com/watch?v=XfpLwPe1Ik4?
99% интервьюеров в свое время прошли аналогичное собеседование, так что они заведомо в состоянии решить вашу задачу :)
PS. Сапогом по лицу — это слишком мягко в указанном случае.
PS. Сапогом по лицу — это слишком мягко в указанном случае.
Поверьте, перед подготовкой каждой такой задачи, она проходит проверку на коллегах :)
Вау, а задачка-то отличная, даже в этом посте уже можно запросто отличить людей, которые настроены на решение проблем, от тех, кто настроен на нытье на надуманные темы:
— это не для программистов, а для олимпиадников,
— у меня ничего ни работает, условия некорректные
— нихаачуууу…
и т.п.
А то что после решения требуют оформить почти как в настоящий продакшен с юнит-тестами и т.п., позволит сразу оценить и чистоту кода и подход к декомпозиции на подзадачи и т.п. Почти все, что можно рассчитывать узнать о кандидате в такой короткий срок.
— это не для программистов, а для олимпиадников,
— у меня ничего ни работает, условия некорректные
— нихаачуууу…
и т.п.
А то что после решения требуют оформить почти как в настоящий продакшен с юнит-тестами и т.п., позволит сразу оценить и чистоту кода и подход к декомпозиции на подзадачи и т.п. Почти все, что можно рассчитывать узнать о кандидате в такой короткий срок.
Интересно, а как дела с собеседованиями на вконтакте? Вроде бы, там сплошные олимпиадники и всё такое.
Решение на J
Не судите строго — основной текст и заморочка — это обрезание краёв. Пойду спрошу у гуру как это сделать.
Интересно было бы узнать у автора — а чем twitter лучше чем амазон? Дилетанский взгляд конечно: но в амазоне какие-то новые технологии делают, a что делают в твиттере — я не известно.
Не судите строго — основной текст и заморочка — это обрезание краёв. Пойду спрошу у гуру как это сделать.
f =: 3 : '>. /> +/ each (<@((-.@((i.@{.@I. , (({:@I.) + i.@(# - {:@I.))) (4 : ''1 x } y'') ]))@(1&>) # ]))("1) (-/~) y'
f 2 5 1 2 3 4 7 7 6
10
f 2 5 1 3 1 2 1 7 7 6
17
Интересно было бы узнать у автора — а чем twitter лучше чем амазон? Дилетанский взгляд конечно: но в амазоне какие-то новые технологии делают, a что делают в твиттере — я не известно.
Понимаю тех, кто минусует — жуткое решение.
Стоило включить мозг на 5 минут, отвлекшись от того, что хотел решить быстрее (кстати о стрессе на собеседовании), и тут же стало ясно как решить правильнее.
для пояснения пишу с комментариями:
Стоило включить мозг на 5 минут, отвлекшись от того, что хотел решить быстрее (кстати о стрессе на собеседовании), и тут же стало ясно как решить правильнее.
для пояснения пишу с комментариями:
w =: 0 5 3 5 1 2 NB. исходные данные
s =: >./\ - [ NB. функция для подсчёта "дыр" слева-направо.
+/ (f w) <. f&.|. w
NB. >. - это поиск максимума.
NB. / - это between, т.е. вставка максимума между всеми элементами списка - т.е. по сути поиск глобального максимума.
NB. но если мы пишем /\ - то это between, но с сохранением промежуточных результатов, т.е. бегущий максимум. >./ w это 5, а >./\ w это 0 5 5 5 5 5 . всё отлично, но только данный подход считает так, как будто стены нет слева, а вот справа есть. для этого ниже делается реверс.
NB. &. - это применение одной функции, потом глагола, потом инверсной.
NB. |. - revers списка.
NB. т.е. f&.|. w - это будет: развернуть список, потом применить к нему f, а потом ещё раз развернуть. т.е. в данном случае, чтобы подсчитать впадины справа налево.
NB. в итоге: считаем дырки слева направо, потом справа-налево и берём меньшие значение для каждой дырки.
Что это за язык?
Я на всякий случай вычислил md5 из решения. baa63d9e9d0e7be8661817ea7b07db3b
Текст изменился и я делаю вывод, что это не perl.
Я на всякий случай вычислил md5 из решения. baa63d9e9d0e7be8661817ea7b07db3b
Текст изменился и я делаю вывод, что это не perl.
Решение на perl было бы так:
perl -nE '
Где задача в файле task.txt:
perl -nE '
1 while s/([#-]) ( *)([#-])/\1-\2\3/g; $sum+=s/-/x/g;}END{say $sum
Где задача в файле task.txt:
#
# #
# # #
# # #
# # # #
## ## # #
##############
Даю ссылку с упоминаниями на этот сайт:
habrahabr.ru/tag/j
А зачем нужен md5 решения?
Кстати позже закинул эту задачу в рассылку по этому языку и получил решение от профессионалов:
habrahabr.ru/tag/j
А зачем нужен md5 решения?
Кстати позже закинул эту задачу в рассылку по этому языку и получил решение от профессионалов:
+/@(-~ >./\ <. >./\.) 2 5 1 3 1 2 1 7 7 6
17
А можно пояснить? Что такое md5 от решения? md5 от исходного кода? Зачем его вычислять? Как при этом может измениться текст и причём тут perl?
<sarcasm>Ну это же общеизвестный факт: программы на perl обладают столь высокой энтропией, что неподвержены алгоритмам хеширования.</sarcasm>
Все равно не понял(
То что программы на perl обладают высокой энтропией — понятно. Из чего следовало бы, что они слабо подвержены алгоритмам сжатия.
А вот как энтропия связана с хешированием? Считается что хэш от текста с высокой энтропией равен исходному тексту? Но ведь это неправда, я даже не вижу повода такое предположить.
То что программы на perl обладают высокой энтропией — понятно. Из чего следовало бы, что они слабо подвержены алгоритмам сжатия.
А вот как энтропия связана с хешированием? Считается что хэш от текста с высокой энтропией равен исходному тексту? Но ведь это неправда, я даже не вижу повода такое предположить.
Какое хитрое решение. Вот написал на js логически простое, два цикла и максимальная сложность 2n.
«Достаточно неплохо, хотя ваше решение делает 2 прохода, но есть другой интересный алгоритм, который делает всего один проход».
Решение в два прохода находится достаточно быстро :) Сложнее уложиться ровно в один проход
Я попробовал сделать в один проход строго слева направо. Получилось ужасно — потребовался стек индексов.
ну как-то так. Или это и есть «стек индексов»?
Решил в один проход. Не хотел двигать стенки как в оригинальном решении из поста. Решал сначала геометрически на бумажке — не уверен что без листка будет понятно.
Скрытый текст
var calculate = function( arr ){ // one cycle solution
var minMax,
sum = 0,
fullSum = 0,
el,
maxMax,
i, _i = arr.length - 1;
minMax = arr[0]; // first item is the current left max
maxMax = arr[_i]; // last item is the current right max
for( i = 0; i <= _i; i++ ){
el = arr[ i ];
if( minMax < el ){ // if the wall is getting higher
sum += ( el - minMax ) * i; //add rectangular currentHeight-lastHeight x distanceFromStart
fullSum += ( el - minMax ) * i; //add such rectangular to the whole avaliable free space
minMax = el;
}else{ // if we are getting down
fullSum += minMax - el; // add down delta to the whole avaliable free space sum
}
el = arr[ _i - i ];
if( maxMax < el ){ // same from the right side
sum += ( el - maxMax ) * i;
maxMax = el;
}
}
return fullSum - sum; // here we get whole avaliable space and reversed space that would be filled with water
};
// testing
[
[[0,0,0,10,0,0,0,0,0],0],
[[0,1,0,10,0,0,0,0,0],1],
[[1,0,1], 1],
[[5,0,5], 5],
[[0,1,0,1,0], 1],
[[1,0,1,0,1,0,1,0], 3],
[[1,0,1,0], 1],
[[1,0,1,2,0,2], 3],
[[2,5,1,2,3,4,7,7,6], 10],
[[5,1,0,1],1], //# thanks https://news.ycombinator.com/item?id=6640085
[[2,5,1,2,3,4,7,7,6,3,5], 12] //# thanks https://news.ycombinator.com/item?id=6640105
].forEach(function( el ){
if( calculate( el[0] ) !== el[1] ) throw( el );
});
Решение «в лоб»:
use strict;
use warnings;
my @list = (2, 5, 1, 2, 3, 4, 7, 7, 6);
my $max = (sort { $a <=> $b } @list)[-1];
my $vol = 0;
for (my $y = $max; $y >= 0; $y--) {
my $left = 0;
my $right = 0;
for (my $x = 0; $x < @list; $x++) {
next if $list[$x] < $y;
$left = $x + 1;
last;
}
for (my $x = $#list; $x > $left; $x--) {
next if $list[$x] < $y;
$right = $x - 1;
last;
}
for (my $x = $left; $x < $right; $x++) {
$vol++ if $list[$x] < $y;
}
}
print "Volume = $vol\n";
йа тупой.
правильное решение:
правильное решение:
use strict;
use warnings;
my @list = (2, 5, 1, 2, 3, 4, 7, 7, 6);
my $max = (sort { $a <=> $b } @list)[-1];
my $vol = 0;
my $y = 1;
while(1) {
my ($left, $right);
my $linevol = 0;
for (@list) {
if (!$left && $_ >= $y) {
$left = 1;
next;
}
if ($left && $_ >= $y) {
$vol += $linevol;
$linevol = 0;
$right = 1;
next;
}
$linevol++ if $left && $_ < $y;
}
last unless $right;
$y++;
}
print "Volume = $vol\n";
Еще вариант:
use strict;
use warnings;
my @list = (2, 5, 1, 2, 3, 4, 7, 7, 6);
my $vol = 0;
my $y = 1;
my $do = 1;
while($do) {
$do = 0;
my $linevol = 0;
for (my $x = 1; $x < @list; $x++) {
next if $list[$x - 1] < $y;
if ($list[$x] < $y) {
$list[$x] = $y;
$linevol++;
next;
}
$vol += $linevol;
$linevol = 0;
$do = 1;
}
$y++;
}
print "Volume = $vol\n";
Или так (без вложенного цикла):
use strict;
use warnings;
my @list = (2, 5, 1, 2, 3, 4, 7, 7, 6);
my @copy = @list;
my $vol = 0;
my $tmpvol = 0;
for (my $x = 1; $x < @copy; $x++) {
if ($copy[$x] < $copy[$x - 1]) {
$tmpvol += $copy[$x - 1] - $copy[$x];
$copy[$x] = $copy[$x - 1];
next;
}
$vol += $tmpvol;
$tmpvol = 0;
}
my $level = 0;
if ($tmpvol) {
for (my $x = @list - 1; $x > 0; $x--) {
last if $list[$x] >= $copy[$x];
$level = $list[$x] if $list[$x] > $level;
$tmpvol -= $copy[$x] - $level;
}
$vol += $tmpvol;
}
print "Volume = $vol\n";
На следующий день я показал эту задачу знакомому аспиранту, занимающемуся теоретическим computer science. После 40 минут размышлений у него также ничего не получилось.О боже…
Я вот все думаю, почему так отличаются подходы если ты сам ищеш себе сотрудника или если ищет тот кого назначили искать.
Формальные тесты на сообразительность просто глупы в условии стресса если Вы ищете не оператора боевого дрона. Почему если я ищу сотрудника то мне гораздо важнее узнать что он за человек, чем живёт и интересуется, а сторонний человек начинает тестировать сообразительность итп. Профи видит профи через 10 минут простого, доброжелательного общения по теме. Остальные 50 минут потрать узнавая что за человек, как легко будет с ним работать, видиш ли ты в нём партнера. Все хочу молодёже пожелать искать работу в боевых конторах, которые вынуждены выживать и конкурировать, там можно расти как специалисту. А вфейсбуках и гуглах больших конторах очень велика вероятность что похороните Вы свои таланты и поростёте мхом. Будете микроскопом гвозди забивать. Да и платят они не бог весть как много, если только плюшками халявными коспенсируют. Всякая большая контора обрастает со временем кучей ненужных проверяльщиков и надзирателей талант которых не без основания можно поставить под сомнение. Их отличие от Вас только в том, что те вопросы они сначала в спокойной обстановке сами обсосали, без стресса, за чашкой халявного кофе и булкой. Они вряд ли умнее Вас, просто им повезло когда то в этой лотерее. Не рвитесь сразу к ним, начните с меньшего но интересного, а то, есть вероятность, что ничего стоящего в жизни так и не попробуете.
Формальные тесты на сообразительность просто глупы в условии стресса если Вы ищете не оператора боевого дрона. Почему если я ищу сотрудника то мне гораздо важнее узнать что он за человек, чем живёт и интересуется, а сторонний человек начинает тестировать сообразительность итп. Профи видит профи через 10 минут простого, доброжелательного общения по теме. Остальные 50 минут потрать узнавая что за человек, как легко будет с ним работать, видиш ли ты в нём партнера. Все хочу молодёже пожелать искать работу в боевых конторах, которые вынуждены выживать и конкурировать, там можно расти как специалисту. А в
НЛО прилетело и опубликовало эту надпись здесь
Больше всего расстраивает что хотят получить все и сразу не понимая что спеца надо растить. Что толку в знании алгоритмов которые не прийдётся применять? Гораздо важнее как человек может учиться и есть ли у него желание учиться. Мне ещё не известно ни одно место работы приходя куда не надо было что то учить и с чем то разбираться. Человек не может знать всего и глупо ждать от него всезнания. Парадокс в том что все мы видим что методы используемые большими конторами при поиске спецов часто не эффективны, более того, даю руку на отсечение, часто на работу не попадают те кто гораздо ценнее тех кто прошел лотерею. Говорил и продолжаю говорить, любое промежуточное звено между соискателем и тем кто будет работать с ним непосредственно приносит больше вреда нежели пользы. Отговорки о том дескать много народу, отвлекают от работы итп не принимаю. Как правило любой коллектив до 50 человек имеет уже руководителя (тимлида) (если нет то пора завести) который в конечном итоге и должен принимать решение о приеме человека. В коллективе до 50 человек не так велика текучка что бы позволить себе отдавать другим на откуп выбор спеца в свою комманду (а если велика то следует задуматься о смене руководителя). Ни в жисть бы не доверил другому выбирать сотрудника для меня. Более того скажу, более высокие профессиональные знания зачастую значат для меня меньше чем умение человека общаться и быть товарищем органичной частью коллектива. я насмотрелся в своё время на «спецов» начинающих орать на молодёж по пустякам, убивая у них в итоге всякое желание что то делать, неулыбчивых, не желающих делиться знаниями с другими, трясущихся над своей позицией в тиме. Потому в топку эти твитгуглофейсовые методы подбора персонала. Очень хочется чтоб люди там работающие прочитали эти строки и что то пеменяли в этом направлениие.
Подпишусь под каждым словом. Придерживаюсь того же мнения один в один.
Интересен вариант, когда собеседующийся задаёт подготовленную задачу интервьюеру.
Как-то так на PHP в 1 проход
function calculateBulb($heights) {
$started = false;
$start_max = 0;
$end_max = 0;
$water = 0;
$c = count($heights);
for($i = 0; $i < $c; $i++) {
if($i<1) {
continue;
}
if($i>7) {
break;
}
if(!$started) {
if($start_max <= $heights[$i]) {
$start_max = $heights[$i];
continue;
}
if($start_max > $heights[i]) {
$started = true;
$water += ($start_max - $heights[$i]);
}
} else if($heights[$i] >= $start_max) {
continue;
} else {
$water += ($start_max - $heights[$i]);
}
}
return $water;
}
$heights = [2,5,1,2,3,4,7,7,6];
echo(calculateBulb($heights)); // 10
$heights = [2,5,1,3,1,2,1,7,7,6];
echo(calculateBulb($heights)); // 17
$heights = [2,5,1,3,8,2,1,7,7,6];
echo(calculateBulb($heights)); // 13
В последнем варианте не 17 часом должно получиться?
Должно быть 17.
Нет. Если сливается все, что перед 1 и после 7 — должно быть 13. Там 8 в середине списка.
Только вот между 8 и 7 будет еще 4 куба. Он как раз из-за 8 не до 5 сливается, а только до 7.
До заливки:
После:
Разница:
Сумма 17.
[2,5,1,3,8,2,1,7,7,6];
После:
[2,5,5,5,8,7,7,7,7,6];
Разница:
[0,0,4,2,0,5,6,0,0,0];
Сумма 17.
Если с хэшами:
land = [2, 5, 1, 3, 1, 7, 1, 7, 2, 3, 2, 6]
data = {}
result = 0
for index, height in enumerate(land):
for level in xrange(1, height + 1):
result += index - data.get(level, index)
data[level] = index + 1
print result
double area(double X[],int N){
double S=0;
for(int a=0,b=N-1;a<b;){
double ha=X[a],hb=X[b];
if(ha<hb) while(X[++a]<ha) S+=ha-X[a];
else while(X[--b]<hb) S+=hb-X[b];
}
return S;
}
Вы очень близки к правильному решению.
Но вот X = {1, 2, 3, 4, 5} зациклит вашу программу.
Но вот X = {1, 2, 3, 4, 5} зациклит вашу программу.
Но почему double?
Ваше решение на самом деле классное, т.к. более компактное по сравнению с кодом, который дан в конце заметки.
Простите, что придираюсь по мелочам, но зачем вы используете такую конструкцию:
вместо
Она же фактически не сильно добавляет компактности, зато код становится чуть менее наглядным, т.к. используется конструкция for без инкремента, то есть фактически там, где должен был использоваться более канонический (для этого случая) while. Нет?
Простите, что придираюсь по мелочам, но зачем вы используете такую конструкцию:
for(int a=0,b=N-1;a<b;) {...}
вместо
int a=0,b=N-1;
while(a<b) {...}
Она же фактически не сильно добавляет компактности, зато код становится чуть менее наглядным, т.к. используется конструкция for без инкремента, то есть фактически там, где должен был использоваться более канонический (для этого случая) while. Нет?
Совершенно правильно, в начале я так и написал. Если бы я заметил, что массив целый, то было бы
Просто искал путь сэкономить ещё одну строчку так, чтобы это было не очень заметно (не противоречило моим принципам разделения на строки).
С другой стороны, переменные a и b локальны в цикле, так что можно и поразмыслить, что должно быть более каноническим. While в данной ситуации нагляднее, согласен.
int a=0,b=N-1,S=0;
Просто искал путь сэкономить ещё одну строчку так, чтобы это было не очень заметно (не противоречило моим принципам разделения на строки).
С другой стороны, переменные a и b локальны в цикле, так что можно и поразмыслить, что должно быть более каноническим. While в данной ситуации нагляднее, согласен.
НЛО прилетело и опубликовало эту надпись здесь
Сходу придумал решение в стиле метода монте Карло. Льем сверху сплошную линию из воды, затем для каждого кубика решаем, встал он на своё место или перелился ниже. В конце концов кубики начнут выливаться. Условие выхода — вылились все кубики.
Сложность n2 конечно, но в качестве референса для юнит теста подойдёт.
Сложность n2 конечно, но в качестве референса для юнит теста подойдёт.
Блин, камменты читать некогда, но чую, что задача решена неверно
Зафейлится на нескольких «лужах»
Зафейлится на нескольких «лужах»
Прочитайте этот :)
field = [" 1 ",
" 1 1 ",
"1 11 1 1 ",
"1 111 1 11",
"111111111111"]
def process(row):
i = 0
##print row,
for c in row:
if c == '1':
break
i = i+1
##print ", i=", i,
j = len(row)
for c in row[::-1]:
if c == '1':
break
j = j-1
##print ", j=", j
while i < j:
if row[i] == ' ':
row=row[:i]+'-'+row[i+1:]
i = i+1
print row
for row in field:
process(row)
Даже страшно подумать сколько проходов я делаю
Решение подобной задачи на собеседовании лишь показывает как человек умеет решать подобные задачи.
1) Начинаем с начала, идем вперед, пока не находим первое число, меньшее за предыдущее. Назовем предыдущее Х (если не находим такого — конец).
2) Плюсуем разницы между Х и всеми следующими числами, меньшими за него.
3) Повторяем данную процедуру снова, и так до конца массива (конец массива прерывает суммирование).
Вроде все?
2) Плюсуем разницы между Х и всеми следующими числами, меньшими за него.
3) Повторяем данную процедуру снова, и так до конца массива (конец массива прерывает суммирование).
Вроде все?
Скажите что я гений, раз для меня все так просто или что дурак, раз чего-то явного не заметил.
НЛО прилетело и опубликовало эту надпись здесь
3115132
Точно. Ну да, выходит что надо пункт 1 изменить на «начинаем с обоих концов» и выйдет тоже, что написано в топике в конце (я прочитал).
Хотя вроде проще, чем описано в топике, нет?
НЛО прилетело и опубликовало эту надпись здесь
вашу тестовую модель у себя прогоняю
Что-то я удивлён комментариям. Это не олимпиадная задача. Это самая реальная задача для программиста, с которыми периодически приходится сталкиваться.
Не более «олимпиадная» чем посчитать даты перекрытия двух календарей (имеется ввиду пользовательский «календарь» — органайзер),
не более олимпиадная чем держать какую-то очередь lazy заданий в памяти, создать индекс (как в БД) у массива данных,
выбрать подходящую реализацию «дерева» в БД, или дефрагментировать диск/иное хранилище (имеется ввиду порядок копирования секторов туда-сюда).
Видимо твиттеру захотелось нанять не просто программиста, который может «применять паттерны», «писать поддерживаемый код» и «подключать библиотеки»,
но и кто самостоятельно может подумать и написать код с тестом (в принципе написать хоть что-нибудь, не обязательно на скорость), не погразнув в проблемах off-by-one.
Давайте тогда отнесём к «олимпиадным» задачам граматикм, сортировки, деревья, принцип работы регулярных выражений. А ведь даже чтобы что-то отсортировать готовым алгоритмом, нужно хотя бы знать что функция сравнения должна быть транзитивной.
Не более «олимпиадная» чем посчитать даты перекрытия двух календарей (имеется ввиду пользовательский «календарь» — органайзер),
не более олимпиадная чем держать какую-то очередь lazy заданий в памяти, создать индекс (как в БД) у массива данных,
выбрать подходящую реализацию «дерева» в БД, или дефрагментировать диск/иное хранилище (имеется ввиду порядок копирования секторов туда-сюда).
Видимо твиттеру захотелось нанять не просто программиста, который может «применять паттерны», «писать поддерживаемый код» и «подключать библиотеки»,
но и кто самостоятельно может подумать и написать код с тестом (в принципе написать хоть что-нибудь, не обязательно на скорость), не погразнув в проблемах off-by-one.
Давайте тогда отнесём к «олимпиадным» задачам граматикм, сортировки, деревья, принцип работы регулярных выражений. А ведь даже чтобы что-то отсортировать готовым алгоритмом, нужно хотя бы знать что функция сравнения должна быть транзитивной.
Не забывайте о том, что это было телефонное интервью и решение фактически нужно было дать за достаточно короткое время.
Очень хорошо сказано, особенно третий абзац!
Вот когда мне с такими задачами приходится сталкиваться, я их решаю на ура. И эту решил, без спойлера и без бумажки. Но ни на одном собеседовании я подобное решить не способен. Не учитываются психологические факторы, различные у разных людей. К тому же, на практике всё, что Вы перечислили, встречается с вероятностью 0,0000001%. А паттерны, кстати, лично я не очень уважаю. А уважаю умение думать головой и знание тонкостей языка. Только вот заставлять думать головой на собеседовании — это извращение, потому что у человека даже в течение дня IQ может прилично скакать. Смотреть надо по опыту и по делам, а не делать выводы из решений подобных задачек.
НЛО прилетело и опубликовало эту надпись здесь
Пытался решить без спойлера. Возмем второй пример {2,5,1,3,1,2,1,7,7,6}: Идем слева, находим первый обрыв — это высота 5. Дальше идем и ищем первую стену выше или равной 5 — это 7. Пока шли, мы считали сумму высот между ними — это 1+3+1+2+1=8 (назовем это груном в озере) и ширину озера = 5, дальше берем объем озера между 5 и 7 равный 5*5=25 и вычитаем объем грунта 8, получаем 17. начиная с последнего места повторяем, и так до конца.
Итого, 40 минут. В реальности — это, конечно, издевательство над кандидатом. Ничего не показывает.
Итого, 40 минут. В реальности — это, конечно, издевательство над кандидатом. Ничего не показывает.
private static int calc(int[] arr) {
int h = 0;
int w = 0;
int stone = 0;
int lake = 0;
for (int i = 1; i < arr.length; i++) {
if (h == 0) {
if (arr[i] < arr[i - 1]) {
h = arr[i - 1];
stone = arr[i];
w = 1;
}
} else {
if (arr[i] < h) {
stone += arr[i];
w++;
} else {
lake = w * h - stone;
}
}
}
return lake;
}
Задачка элементарна решил сразу как только прочитал задание, даже код накидал
Насколько я понял вода накапливается только в ямках, а если ямка образуется с границами массива то она как бы стекается и не учитывается, Если это так то по ссылке простое решение в 1 проход.
ideone.com/sRkkSc
Насколько я понял вода накапливается только в ямках, а если ямка образуется с границами массива то она как бы стекается и не учитывается, Если это так то по ссылке простое решение в 1 проход.
ideone.com/sRkkSc
Неправильно работает, проверь для 1, 2, 3, 2, 5, 3, 4. Должно получиться 2, а не 1 как у тебя.
Да я уже понял. Вот правильное решение: ideone.com/niitb7
Только оно уже получается не в 1 проход, и мне как то не верится, что за 1 проход можно найти решение.
Только оно уже получается не в 1 проход, и мне как то не верится, что за 1 проход можно найти решение.
Правильно?
roof=([2,5,1,3,1,2,1,7,7,6])
sum = 0
max = roof[0]
for i in range(1,len(roof)-1):
if roof[i] > max:
max = roof[i]
else:
sum += max-roof[i]
print sum
roof=([2,5,1,3,1,2,1,7,7,6])
sum = 0
max = roof[0]
for i in range(1,len(roof)-1):
if roof[i] > max:
max = roof[i]
else:
sum += max-roof[i]
print sum
Повторяюсь, но у тебя тоже неправильно работает. Проверь для 1, 2, 3, 2, 5, 3, 4. У тебя ответ 3 вместо 2.
И что она сказала? 17 или 18?
Вот так правильно на Python:
Это если совсем по-простому без наворотов. И в один проход.
При чем там выводы что это типа олимпиадная задачка? Элементарная комбинаторика. 3 минуты и фсё.
line = [2, 5, 1, 3, 1, 2, 1, 7, 7, 6]
S = 0
D = 0
M = line[0]
for k in line[1:]:
if k >= M:
M = k
S += D
D = 0
if M > k: D += M - k
print('S=', S)
Это если совсем по-простому без наворотов. И в один проход.
При чем там выводы что это типа олимпиадная задачка? Элементарная комбинаторика. 3 минуты и фсё.
И что она выдаст на [5, 1, 3]?
OK, Редмонд. Поймали :). Поторопился — не потестил, как положено.
Введем пару индексов, будем ловить внутренний максимум, и коррекция в конце. Ну и напишем так, что это будет выглядеть почти на всех языках одинаково. И вначале проверка на вшивость.
И все равно задача простая.
Введем пару индексов, будем ловить внутренний максимум, и коррекция в конце. Ну и напишем так, что это будет выглядеть почти на всех языках одинаково. И вначале проверка на вшивость.
line = [5, 1, 3, 1, 3]
S = 0
Len = len(line)
if Len > 2:
D = 0
Max = line[0]
Max2 = 0
Idx = 0
Idx2 = 0
for k in xrange(1, Len):
if line[k] >= Max:
Max = line[k]
Max2 = 0
S += D
D = 0
Idx = k
Idx2 = Idx
if Max > line[k]:
D += Max - line[k]
if Max2 <= line[k]:
Max2 = line[k]
Idx2 = k
if D > 0:
S = S+D-(Max-Max2)*(Idx2-Idx)
print('S=', S)
И все равно задача простая.
[5,4,3,2,1]. Выдала 9 вместо 0.
Следующая попытка?
Следующая попытка?
Поправим и это:
Кстати, по ходу я нашел очень изящное минимальное решение. Завтра пропущу через тесты и выложу. Сейчас уже давно байки пора.
line = [5, 4, 3, 2, 1]
S = 0
Len = len(line)
if Len > 2:
D = 0
Max = line[0]
Max2 = 0
Idx = 0
Idx2 = 0
Sum2 = 0
for k in xrange(1,Len):
if line[k] >= Max:
Max = line[k]
Max2 = 0
S += D
D = 0
Idx = k
Idx2 = Idx
if Max > line[k]:
D += Max - line[k]
if Max2 <= line[k]:
Max2 = line[k]
Idx2 = k
Sum2 = 0
else: Sum2 += Max - line[k]
if D > 0 and (Idx2-Idx) > 1: S = S+D-(Max-Max2)*(Idx2-Idx) - Sum2
print('S=', S)
Кстати, по ходу я нашел очень изящное минимальное решение. Завтра пропущу через тесты и выложу. Сейчас уже давно байки пора.
Что же, посмотрим. А пока [5,1,4,2,3]. Может быть, она не такая уж простая?
line = [2, 5, 1, 2, 3, 4, 7, 7, 7, 6, 6, 5, 2, 6]
S = 0
End = len(line)-1
if End > 1:
Df = 0
Dt = 0
Sf = 0
St = 0
MAXf = line[0]
MAXt = line[End]
IDXf = 0
IDXt = 0
k = 1
while k <= End and IDXf < End-IDXt:
if line[k] >= MAXf:
Sf += MAXf*(k-IDXf-1)-Df
MAXf = line[k]
Df = 0
IDXf = k
if MAXf > line[k]: Df += line[k]
if line[End-k] >= MAXt and IDXf != End-IDXt:
St += MAXt*(k-IDXt-1)-Dt
MAXt = line[End-k]
Dt = 0
IDXt = k
if MAXt > line[End-k]: Dt += line[End-k]
k += 1
S = Sf+St
print('S=', S)
Симметричное решение. Хотел сделать асимметрично, как выше по ветке, но слишком много костылей появляется. А симметрия — это всегда красиво.
И все равно на алгоритм и код у меня в сумме ушло не более 20мин.
Да, вчера я не тестировал (во время работы невозможно), поэтому проколы. Сегодня нормально потестил.
вашу тестовую модель у себя прогоняю
вашу тестовую модель у себя прогоняю
Ваш бы пафос да в народных целях направить. Три попытки, а урок так и не извлекли.
На самом деле эта задача учит не торопиться с выводами.
На самом деле эта задача учит не торопиться с выводами.
Решение на джаваскрипте. Принцип получился тот же, что и в решении из поста.
JSFiddle
function calcVolume(land) {
var r = land.length - 1, l = 0, rm = 0, lm = 0, v = 0;
while(l < r) {
lm = Math.max(land[l], lm);
rm = Math.max(land[r], rm);
v += lm >= rm ? rm - land[r--] : lm - land[l++];
}
return v;
}
JSFiddle
В переводе есть несколько неточностей, довольно сильно, на мой взгляд, смещающих акценты. Return internship — это, грубо говоря, повторная стажировка. Автор — студент. Следующим летом в Амазоне он будет не работать, а стажироваться. Собеседование в твиттер тоже было собеседованием по поводу стажировки.
Мы, конечно, слышим только одну сторону этой ситуации, а что интервьюер транслировал своему начальству мы никогда не узнаем. Есть масса разных вариантов на самом деле. Например:
— он сказал, что кандидат хороший, а потом о нём просто забыли / потеряли резюме
— он сказал, что кандидат хороший, но были кандидаты лучше, поэтому этого не позвали
— стажерская позиция была для сильного алгоритмиста, поэтому кандидат отсеялся
— его отвлекли от работы, чтобы он провел интервью. сначала он как бы «забыл», потом после звонка HR все же позвонил кандидату, быстренько дал одну задачу, увидел ошибку, написал «не подходит» и поторопился вернуться к работе
Давать на интервью одну задачу — дело вкуса. На мой взгляд это странный подход, но если интервьюер всё же так хочет, то мне кажется он должен «раскрыть карты». Грубо говоря сказать «я дам только одну задачу и надеюсь увидеть полный цикл от проектирования алгоритма до разработки работающего кода и его тестирования». Нам отсюда, конечно, судить сложно — может быть на стажировку в твиттер приходят лучшие студенты CalTech и MIT, так что им есть из кого выбирать и есть повод быть разбочивыми. Но если учесть сильнейший кадровый кризис в отрасли, то интервьюер, на мой взгляд, со своей задачей (проверка адекватности кандидата) не справился.
Мы, конечно, слышим только одну сторону этой ситуации, а что интервьюер транслировал своему начальству мы никогда не узнаем. Есть масса разных вариантов на самом деле. Например:
— он сказал, что кандидат хороший, а потом о нём просто забыли / потеряли резюме
— он сказал, что кандидат хороший, но были кандидаты лучше, поэтому этого не позвали
— стажерская позиция была для сильного алгоритмиста, поэтому кандидат отсеялся
— его отвлекли от работы, чтобы он провел интервью. сначала он как бы «забыл», потом после звонка HR все же позвонил кандидату, быстренько дал одну задачу, увидел ошибку, написал «не подходит» и поторопился вернуться к работе
Давать на интервью одну задачу — дело вкуса. На мой взгляд это странный подход, но если интервьюер всё же так хочет, то мне кажется он должен «раскрыть карты». Грубо говоря сказать «я дам только одну задачу и надеюсь увидеть полный цикл от проектирования алгоритма до разработки работающего кода и его тестирования». Нам отсюда, конечно, судить сложно — может быть на стажировку в твиттер приходят лучшие студенты CalTech и MIT, так что им есть из кого выбирать и есть повод быть разбочивыми. Но если учесть сильнейший кадровый кризис в отрасли, то интервьюер, на мой взгляд, со своей задачей (проверка адекватности кандидата) не справился.
тег сорс не работает
int sum_a(int *m,int l, int r){
int res = 0;
int min = m[l]>m[r]?m[r]:m[l];
for (int i = l+1; i < r; i++){
if (m[i]>min)
return sum_a(m, l, i) + sum_a(m, i, r);
else
res += min — m[i];
}
return res;
}
int _tmain(int argc, _TCHAR* argv[])
{
int m[]={8,1,10,1,2,1,8};
int s=sum_a(m,0,sizeof(m)/sizeof(int)-1);
return 0;
}
int sum_a(int *m,int l, int r){
int res = 0;
int min = m[l]>m[r]?m[r]:m[l];
for (int i = l+1; i < r; i++){
if (m[i]>min)
return sum_a(m, l, i) + sum_a(m, i, r);
else
res += min — m[i];
}
return res;
}
int _tmain(int argc, _TCHAR* argv[])
{
int m[]={8,1,10,1,2,1,8};
int s=sum_a(m,0,sizeof(m)/sizeof(int)-1);
return 0;
}
Как то так. заняло минут 20 и вышло весьма коряво и отнюдь не одним проходом, но вроде как работает) Впрочем думаю в твиттер меня бы тоже не взяли по этим результатам)
Я пару раз видел людей, которые подобное решали на собеседованиях, а потом фиксили баги и чинили верстку в проекте.
Там кто-то выше заикнулся про «я оцениваю элегантность решения» — ну это же вообще ужас. Почему в IT каждый третий программист считает себя вправе оценивать элегантность решения? ЧСВ из всех дыр прет.
Там кто-то выше заикнулся про «я оцениваю элегантность решения» — ну это же вообще ужас. Почему в IT каждый третий программист считает себя вправе оценивать элегантность решения? ЧСВ из всех дыр прет.
Может быть специфика области? (:
На вопрос о специфике области сложно ответить из этой статьи. Эта статья, как и большинство других ее клонов по сценарию «жил-был анонимус, решил устроиться в корпорацию на [никому-не-скажу-какую-позицию], HR и собеседующий опоздали, он сильно волновался, а потом завалил собеседование, не ответит на вопрос о том, почему канализационный люк круглый», полностью бесполезна, так как рассматривает конкретную ситуацию в конкретной компании, остальные же важные переменные — позиция и т.д. — оставлены за кадром.
Предполагаю же, что речь идет о www.linkedin.com/pub/michael-kozakov/47/16/166, и, честно говоря, мне кажется, что это собеседующий был выпендрежником, а не герой статьи шел на какую-то суперпозицию.
Предполагаю же, что речь идет о www.linkedin.com/pub/michael-kozakov/47/16/166, и, честно говоря, мне кажется, что это собеседующий был выпендрежником, а не герой статьи шел на какую-то суперпозицию.
Тут многие спрашивают, зачем такие задачки, мол, как они скил прогера определяют.
Я предлагаю взглянуть вам с другой стороны на эту ситуацию: как такие задачи характеризуют того, кто проводит собеседование?
Согласитесь, что задача не тривиальная, и нужно иметь не стандартный ум, чтобы её придумать.
Я предлагаю взглянуть вам с другой стороны на эту ситуацию: как такие задачи характеризуют того, кто проводит собеседование?
Согласитесь, что задача не тривиальная, и нужно иметь не стандартный ум, чтобы её придумать.
Возможно, эта задача нагло утащена из какой-нибудь книги.
Так и есть. Я видел ее (может быть, чуть с другими условиями, но помню, что ограничения были жесткие, квадрат бы не прошел) раньше в каких-то архивах олимпиадных задач, но вот что-то так и не смог найти сейчас.
Значит собеседующий читал эту книгу (: тоже кое-что говорит
Я к тому, что задачу можно оценивать не только с точки зрения оценки скилов претендента, но и с другой стороны.
Привык брать от ситуации всё (:
Я к тому, что задачу можно оценивать не только с точки зрения оценки скилов претендента, но и с другой стороны.
Привык брать от ситуации всё (:
У меня такое впечатление, что соискателя просто «прокатили», надо было отвязаться от человека, но не говорить же ему — извините, мы передумали и все такое. Решили поступить иначе.
В пользу этого, говорит то, что про него забыли, он сидел и ждал собеседования. Когда «вспомнили», подобрали тест посложнее.
Да и сам подход к оценке результатов довольно предвзятый. Конечно, классно когда решают такие тесты в очень сжатые сроки на собеседовании, но требовать, чтобы решение было идеальным — нельзя. Это должен был понимать каждый нормальный программист.
В пользу этого, говорит то, что про него забыли, он сидел и ждал собеседования. Когда «вспомнили», подобрали тест посложнее.
Да и сам подход к оценке результатов довольно предвзятый. Конечно, классно когда решают такие тесты в очень сжатые сроки на собеседовании, но требовать, чтобы решение было идеальным — нельзя. Это должен был понимать каждый нормальный программист.
Задача интересна тем, что в ней довольно просто допустить ошибку, судя по комментариям.
Если бы программист просто решил её правильно, не важно каким алгоритмом, это уже было бы неплохо.
Многие гонятся за оптимальным алгоритмом и вообще выдают ошибочное решение. Это характеризует как-то программиста:)
Вообще я уже давно понял, если идёшь на приличную позицию — нужно хорошо готовиться!
Многие приходят и думают, что они и так всё знают, в итоге заваливаются на простых вопросах :(
Если бы программист просто решил её правильно, не важно каким алгоритмом, это уже было бы неплохо.
Многие гонятся за оптимальным алгоритмом и вообще выдают ошибочное решение. Это характеризует как-то программиста:)
Вообще я уже давно понял, если идёшь на приличную позицию — нужно хорошо готовиться!
Многие приходят и думают, что они и так всё знают, в итоге заваливаются на простых вопросах :(
По мне решении намного проще и прозаичнее (В примерах ваши данные + свои для тестирования. В [] правильный ответ для сравнения):
public class Main {
public static void main(String[] args) {
System.out.println("Capacity: [10] = " + calculate(new int[]{2,5,1,2,3,4,7,7,6}));
System.out.println("Capacity: [17] = " + calculate(new int[]{2,5,1,3,1,2,1,7,7,6}));
System.out.println("Capacity: [42] = " + calculate(new int[]{4, 3, 1, 5, 8, 0, 4, 0 ,0 , 5, 5, 7, 5, 8, 3, 3}));
System.out.println("Capacity: [0] = " + calculate(new int[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0}));
System.out.println("Capacity: [0] = " + calculate(new int[]{0, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0}));
System.out.println("Capacity: [45] = " + calculate(new int[]{0, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, 9}));
}
public static int calculate(int[] list) {
int cap = 0, firstVal = 0, tempCap = 0;
for (Integer val : list) {
if (val < firstVal) {
tempCap += firstVal - val;
continue;
}
cap += tempCap;
firstVal = val;
tempCap = 0;
}
return cap;
}
}
Смысл задачи проверить ход мыслей претендента на вакансию. Очень часто люди допускают ошибки и простые задачи пытаются решить сложным путем, как в данном случае.
Задача решается в один проход. Сначала расчитывается максимальный объем воды исходя из высоты левой стенки и из этого значения вычитается объем воды, который будет вытеснен стенками идущими справа. То есть по сути нужно вычесть высоту всех стенок из полученного значения.
Никаких экстремумов и матанализа — это и не нужно в Твиттере.
Задача решается в один проход. Сначала расчитывается максимальный объем воды исходя из высоты левой стенки и из этого значения вычитается объем воды, который будет вытеснен стенками идущими справа. То есть по сути нужно вычесть высоту всех стенок из полученного значения.
Никаких экстремумов и матанализа — это и не нужно в Твиттере.
Мне эту же задачу задавали на собеседовании в Google
Автору еще повезло что его не индиец собеседовал с их ужасным акцентом. Этот неловкий момент когда выслушиваешь предложение, а оказывается что это был вопрос. В этот момент хочется послать человеку учебник по английскому произношению.
Комменты еще не читал, увидев фразу, что знакомый аспирант решал 40 минут и не решил, задумался. На решение и написание ушло 8,5 минут:
Соответственно вывод консоли:
Ничего супер сложного не увидел.
P.S. хабр тупит второе утро подряд, то 404, то нажатие на кнопку «Написать» ни к чему не приводит — это печально.
static void Main(string[] args)
{
Console.WriteLine(GetVolume(new int[] { 2, 5, 1, 2, 3, 4, 7, 7, 6 }));
Console.WriteLine(GetVolume(new int[] { 2, 5, 1, 3, 1, 2, 1, 7, 7, 6 }));
Console.ReadKey();
}
static int GetVolume(int[] data)
{
var left = -1;
var right = -1;
var volume = 0;
var quantity = 0;
for (int i = 0, j = data.Length - 1; i <= j; i++, j--)
{
if (left == -1 && data[i] > data[i + 1]) left = i;
if (right == -1 && data[j] > data[j - 1]) right = j;
if (left != -1 && left != i)
{
volume += data[i];
quantity++;
}
if (i == j) break;
if (right != -1 && right != j)
{
volume += data[j];
quantity++;
}
}
return left == -1 || right == -1 ? 0 : (data[left] < data[right] ? data[left] : data[right]) * quantity - volume;
}
Соответственно вывод консоли:
10
17
Ничего супер сложного не увидел.
P.S. хабр тупит второе утро подряд, то 404, то нажатие на кнопку «Написать» ни к чему не приводит — это печально.
А попробуйте 2, 7, 1, 1, 6, 2, 4, 1, 1, 2
{ 1, 0, 7, 0, 1 } выдает -4.
Да, согласен, просто рассматривал ситуации из поста, сейчас почитал комменты и действительно с подсчетом объема с столбцах нужно что то придумать. Пошел думать.
Тогда только так:
static void Main(string[] args)
{
var format = "Получилось: {0}, должно быть {1}";
Console.WriteLine(format, GetVolume(new int[] { 2, 5, 1, 2, 3, 4, 7, 7, 6 }), 10); //10
Console.WriteLine(format, GetVolume(new int[] { 2, 5, 1, 3, 1, 2, 1, 7, 7, 6 }), 17); //17
Console.WriteLine(format, GetVolume(new int[] { 5, 4, 3, 2, 1 }), 0); //0
Console.WriteLine(format, GetVolume(new int[] { 1, 2, 3, 2, 5, 3, 4 }), 2); //2
Console.WriteLine(format, GetVolume(new int[] { 2, 7, 1, 1, 6, 2, 4, 1, 1, 2 }), 14); //14
Console.WriteLine(format, GetVolume(new int[] { 0, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, 1 }), 1); //1
Console.ReadKey();
}
static int GetVolume(int[] data)
{
var leftTop = 0;
var rightTop = 0;
var volume = 0;
for (int i = 0, j = data.Length - 1; i < j; i++, j--)
{
if (data[i] > leftTop) leftTop = data[i];
if (data[j] > rightTop) rightTop = data[j];
if (leftTop >= rightTop)
{
i--;
volume += rightTop - data[j];
continue;
}
j++;
volume += leftTop - data[i];
}
return volume;
}
Один раз на собеседовании в крупную компанию столкнулся с логическими задачами и прямо ответил, что не считаю это показателем при трудоустройстве, и лично у меня лампочка не включается в условиях стресса. На что собеседник ответил, что может быть оно и так, но на его практике все толковые программисты умеют хорошо решать подобные задачи.
Вот написал свое решение практически за O(1): github.com/KvanTTT/Twitter-Puddles-Counter
Правда сгенерированные ответы много памяти занимают. Однако их можно уменьшить как минимум в 4 раза, если учитывать симметрию по оси X и оси Y. Я имею ввиду: V(x_1, x_2, ..., x_n) = V(x_n, x_n-1, ..., x_1) и V(x_1, x_2, ..., x_n) = n*h — V(h — x_1, h — x_2, ..., h — x_n). Возможно есть и другие, более сложные зависимости.
Правда сгенерированные ответы много памяти занимают. Однако их можно уменьшить как минимум в 4 раза, если учитывать симметрию по оси X и оси Y. Я имею ввиду: V(x_1, x_2, ..., x_n) = V(x_n, x_n-1, ..., x_1) и V(x_1, x_2, ..., x_n) = n*h — V(h — x_1, h — x_2, ..., h — x_n). Возможно есть и другие, более сложные зависимости.
Закостылил решение с одним проходом
Perl
use strict;
use warnings;
print '1 ' . DoIt((0, 9, 8, 5, 1, 0, 1)) ."\n";
print '9 ' . DoIt((7, 1, 7, 2, 5)) ."\n";
print '10 ' . DoIt((2,5,1,2,3,4,7,7,6)) ."\n";
print '17 ' . DoIt((2,5,1,3,1,2,1,7,7,6)) ."\n";
print '42 ' . DoIt((4, 3, 1, 5, 8, 0, 4, 0 ,0 , 5, 5, 7, 5, 8, 3, 3)) ."\n";
sub DoIt {
my $pool = 0;
my $border = 0;
my $capacity = 0;
my $n = $#_ + 1;
foreach my $val (@_) {
$n --;
if ($val < $border) {
unless ($n <= 0) {
$pool += $border - $val;
next;
} else {
$pool = 0;
foreach my $rev_val (reverse @_) {
$pool += $val - $rev_val;
last if $rev_val < $val;
}
}
}
$border = $val;
$capacity += $pool;
$pool = 0;
}
return $capacity;
}
upd
#!/usr/bin/perl
use strict;
use warnings;
print '10 ' . DoIt((2,5,1,2,3,4,7,7,6)) ."\n";
print '17 ' . DoIt((2,5,1,3,1,2,1,7,7,6)) ."\n";
print '42 ' . DoIt((4,3,1,5,8,0,4,0,0,5,5,7,5,8,3,3)) ."\n";
print '0 ' . DoIt((0,1,2,3,4,5,6,7,8,9,0)) ."\n";
print '0 ' . DoIt((0,9,8,7,6,5,4,3,2,1,0)) ."\n";
print '45 ' . DoIt((0,9,8,7,6,5,4,3,2,1,0,9)) ."\n";
print '1 ' . DoIt((0,9,8,7,6,5,4,3,2,1,0,1)) ."\n";
print '9 ' . DoIt((7,1,7,2,5)) ."\n";
print '2 ' . DoIt((1,0,7,0,1)) ."\n";
print '44 ' . DoIt((4,3,1,5,8,0,4,0,0,5,5,7,5,8,3,1,3,3)) ."\n";
sub DoIt {
my $pool = 0;
my $border = 0;
my $capacity = 0;
my $n = $#_ + 1;
foreach my $val (@_) {
$n --;
if ($val < $border && $n > 0) {
$pool += $border - $val;
next;
}
elsif ($val < $border && $n <= 0) {
$pool = 0;
foreach my $rev_val (reverse @_) {
$pool += $val - $rev_val if $rev_val < $val;
last if $rev_val > $val;
}
}
$border = $val;
$capacity += $pool;
$pool = 0;
}
return $capacity;
}
Мой вариант в 1 строку: habrahabr.ru/post/200190/#comment_6928260
Еще вариант, требует дополнительной памяти пропорционально максимальной высоте стен.
#include <cstddef>
#include <iostream>
template <std::size_t N>
int calc_volume(int const (&heights)[N])
{
int const max_height = 9;
int volume = 0;
int max_left_height = 0;
int prev_height = 0;
int tmp_volume[max_height + 1] = {};
for (int i = 0; i != N; ++i)
{
int const cur_height = heights[i];
if (cur_height > max_height)
return -1;
for (int j = prev_height; j < cur_height; ++j)
{
volume += tmp_volume[j];
tmp_volume[j] = 0;
}
for (int j = cur_height; j < max_left_height; ++j)
++tmp_volume[j];
if (cur_height > max_left_height)
max_left_height = cur_height;
prev_height = cur_height;
}
return volume;
}
int main()
{
int const heights1[] = { 2, 5, 1, 2, 3, 4, 7, 7, 6 }; // 10
int const heights2[] = { 2, 5, 1, 3, 1, 2, 1, 7, 7, 6 }; // 17
int const heights3[] = { 2, 5, 1, 3, 8, 2, 1, 7, 7, 6 }; // 17
int const heights4[] = { 4, 3, 1, 5, 8, 0, 4, 0 ,0 , 5, 5, 7, 5, 8, 3, 3 }; // 42
int const heights5[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 }; // 0
int const heights6[] = { 0, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0 }; // 0
int const heights7[] = { 0, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, 9 }; // 45
int const heights8[] = { 0, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, 1 }; // 1
int const heights9[] = { 7, 1, 7, 2, 5 }; // 9
int const vol = calc_volume(heights1);
std::cout << "volume: " << vol;
return 0;
}
Реализация на Haskell:
Версия для Data.Vector (все же эффективнее) с дебажным выводом массива.
water :: Integral a => [a] -> a
water vec = inwater 0 0 0 vec
where inwater ml mr ac vec
| length vec <= 1 = ac
| leftMax >= rightMax = inwater leftMax rightMax (ac + rightMax - last vec) (take (length vec - 1) vec)
| otherwise = inwater leftMax rightMax (ac + leftMax - head vec) (drop 1 vec)
where
leftMax = if head vec > ml then head vec else ml
rightMax = if last vec > mr then last vec else mr
main = putStrLn $ show $ water [2,5,1,3,1,2,1,7,5,6]
Версия для Data.Vector (все же эффективнее) с дебажным выводом массива.
В следующий раз наверное будет такая же задача, но уже для трех измерений :) Кто-нибудь уже пытался ее решить в такой вариации? (для N можно будет потом обобщить).
А для двумерного массива разве уже решали здесь? Выше вроде только одномерный массив обсуждается.
Учитывая, что предварительной задачей был подсчёт седловых точек, можно предположить, что задачу с двумерным массивом должны были бы дать следующей (если бы автор справился с одномерной).
Решение в двумерном случае было бы интересно увидеть.
Но здесь еще (как мне кажется) нужно уточнить некоторые детали, например, проливается ли вода по диагонали.
Но здесь еще (как мне кажется) нужно уточнить некоторые детали, например, проливается ли вода по диагонали.
Давайте считать, что не проливается.
Например, так. (в 9 строчек уложиться не удалось)
using namespace std;
typedef pair<int,int> intpair;
class comppair{
public:
bool operator()(const intpair &j1,const intpair &j2){
return j1.second>j2.second;
}
};
void Push(int *Arr,priority_queue<intpair,vector<intpair>,comppair> &Que,vector<bool> &V,int crd){
if(V[crd]) return;
V[crd]=true;
Que.push(intpair(crd,Arr[crd]));
}
int area(int *Arr,int M,int N){
if(N<3 || M<3) return 0;
vector<bool> Fill(M*N,true),Ready(M*N,false);
priority_queue<intpair,vector<intpair>,comppair> Que;
for(int i=0;i<M;i++){
Push(Arr,Que,Ready,i*N);
Push(Arr,Que,Ready,i*N+N-1);
}
for(int i=1;i<N-1;i++){
Push(Arr,Que,Ready,i);
Push(Arr,Que,Ready,N*(M-1)+i);
}
int smin=INT_MIN;
int res=0;
while(!Que.empty()){
intpair P=Que.top();
Que.pop();
int crd=P.first;
if(P.second>smin) smin=P.second;
else res+=smin-P.second;
int x=crd%N,y=crd/N;
if(x>0) Push(Arr,Que,Ready,crd-1);
if(x<N-1) Push(Arr,Que,Ready,crd+1);
if(y>0) Push(Arr,Que,Ready,crd-N);
if(y<M-1) Push(Arr,Que,Ready,crd+N);
Fill[crd]=false;
}
return res;
}
В общем, очередной обход графа.
Прошу прощения за возможные ошибки — STL я использую чуть реже, чем никогда, а на C# нет приоритетной очереди.
А вот и для любого числа измерений
using namespace std;
typedef pair<int,int> intpair;
class comppair{
public:
bool operator()(const intpair &j1,const intpair &j2){
return j1.second>j2.second;
}
};
void Push(int *Arr,priority_queue<intpair,vector<intpair>,comppair> &Que,vector<bool> &V,int crd){
if(V[crd]) return;
V[crd]=true;
Que.push(intpair(crd,Arr[crd]));
}
int area(int *Arr,int NDim,int *Dim){
vector<int> Vol(NDim);
int V=1;
for(int i=0;i<NDim;i++){
if(Dim[i]<3) return 0;
Vol[i]=V;
V*=Dim[i];
}
vector<bool> Ready(V,false);
priority_queue<intpair,vector<intpair>,comppair> Que;
for(int i=0;i<V;i++){
bool qbnd=false;
for(int k=0;k<NDim;k++){
int x=(i/Vol[k])%Dim[k];
if(x==0 || x==Dim[k]-1){
qbnd=true; break;
}
}
if(qbnd) Push(Arr,Que,Ready,i);
}
int smin=INT_MIN;
int res=0;
while(!Que.empty()){
intpair P=Que.top();
Que.pop();
int crd=P.first;
if(P.second>smin) smin=P.second;
else res+=smin-P.second;
for(int k=0;k<NDim;k++){
int x=(crd/Vol[k])%Dim[k];
if(x!=0) Push(Arr,Que,Ready,crd-Vol[k]);
if(x!=Dim[k]-1) Push(Arr,Que,Ready,crd+Vol[k]);
}
}
return res;
}
Получилось даже проще, чем для двух.
НЛО прилетело и опубликовало эту надпись здесь
Попробовал я эту Codility. Она предложила задачку с ожидаемым временем O(N), я запостил O(N*log(N)). Как ни странно, прошло (думаю, что я бы смог завалить своё решение, если действительно существует O(N)). Но задачка была интересная.
Интересно, зависит ли сложность задачи от указанных образования и опыта.
Интересно, зависит ли сложность задачи от указанных образования и опыта.
Да, наиболее вероятное, на мой взгляд, высказанное мнение — что соискателя сознательно пытались слить, давая очень трудное для телефонного разговора задание и подталкивая к неправильному решению.
Вариант с визуализацией в консоли:
Вариант без визуализации:
Вариант с визуализацией в консоли:
Скрытый текст
<script>
console.clear();
var a =[], b =[]
,width =6
,h =12;
for(var i =0; i < width; i++)
a.push(Math.random() * h +1 |0), b.push(0);
//a=[9,0,10,9,10,0];
var c = 0;
for(var hh =1; hh < h +1; hh++){
var land =0
,lastC =0
,visL =[]; //visualLeft
for(var i =0; i < width; i++){
land = land || a[i] >= hh;
if(land && a[i] < hh){
c++;
lastC++;
visL.push(b[i]); //for visualize
b[i] = hh; //visualize
}
if(a[i] >= hh){
lastC =0;
visL =[];
}
}
c -= lastC;
while(lastC-- && lastC >=0) //for visualize
b[--i] = visL[lastC];
}
for(var j =0; j < h; j++){
var s ='';
for(var i =0; i < width; i++)
s += h - a[i] <= j ? 'M' : (h - b[i] <= j ?'.':'_');
console.log(s +' '+ (h - j) );
}
console.log('c = '+ c);
console.log('a = '+ a.join(','));
console.log('b = '+ b.join(','));
</script>
Вариант без визуализации:
<script>
var width =6
,h =12
,a=[9,0,10,9,10,0] //c = 10 будет в консоли
,c = 0;
for(var hh =1; hh < h +1; hh++){
var land =0
,lastC =0;
for(var i =0; i < width; i++){
land = land || a[i] >= hh;
if(land && a[i] < hh){
c++;
lastC++;
}
if(a[i] >= hh)
lastC =0;
}
c -= lastC;
}
console.log('c = '+ c);
console.log('a = '+ a.join('\t,'));
</script>
Показал эту задачу знакомой блондинке, студентке 4 курса экономфака АНХ, которая изучала программирование только в рамках школьной программы.
Через две с половиной минуты получил ответ: «Слева и справа от максимума задачи абсолютно симметричны, так что надо решить одну. Рассмотрим часть массива слева от максимума — найдем там новый максимум. Все справа от него до первого максимума заполнено водой, причем понятно, до какого уровня. Дальше ищем третий максимум и тд. Понятно, что не составит труда написать это за линейную сложность»
Я уважаю переводчика, но, увы, никак не могу поверить, что аспирант в CS решал эту задачу 40 минут (если, конечно, это не аспирант кафедры арбузокатания стеклоочистительного факультета Карагандинского Государственного Заборостроительного Университета). Либо автор статьи совсем не умеет решать задачи (что маловероятно), либо это была шутка
Через две с половиной минуты получил ответ: «Слева и справа от максимума задачи абсолютно симметричны, так что надо решить одну. Рассмотрим часть массива слева от максимума — найдем там новый максимум. Все справа от него до первого максимума заполнено водой, причем понятно, до какого уровня. Дальше ищем третий максимум и тд. Понятно, что не составит труда написать это за линейную сложность»
Я уважаю переводчика, но, увы, никак не могу поверить, что аспирант в CS решал эту задачу 40 минут (если, конечно, это не аспирант кафедры арбузокатания стеклоочистительного факультета Карагандинского Государственного Заборостроительного Университета). Либо автор статьи совсем не умеет решать задачи (что маловероятно), либо это была шутка
Мне бы такую знакомую блондинку…
По-моему вся соль в «Понятно, что не составит труда написать это за линейную сложность».
Разворачиваем алгоритм и используем стек. Это и правда понятно =)
К сожалению, она явно сказала «найдём там новый максимум». Либо мы должны идти от края и запоминать все текущие максимумы — но тогда получаем «правильное» решение из статьи, которое описывается совсем не так. Либо искать каждый раз от текущего максимума до края — а это N^2.
Но может быть, она и вправду видит глубже на пару уровней. Такое тоже бывает.
Но может быть, она и вправду видит глубже на пару уровней. Такое тоже бывает.
Мое карявенькое решение задачи, с визуализацией и поэтессами codepen.io/d4rkr00t/pen/hlnfo
на модели {5,1,3,6,1,6,1,3,1,4} ошибка — 12 вместо 18
попробуйте эти модели прогнать
поправил, теперь все модели ваши проходит
или у меня кеш не сбрасывается, или ещё что, но модель {5,1,3,6,1,6,1,3,1,4} так и показывает ошибку: скрин
{kind=link}
все хорошо, наверно кэш www.dropbox.com/s/v38yhn6yj20hw06/Screenshot%202013-11-04%2017.05.34.png
{kind=link}
да, поправилось.
держите ещё модель с ошибкой: {0,6,5,4,3,2,1,0,2,1,1,2}
держите ещё модель с ошибкой: {0,6,5,4,3,2,1,0,2,1,1,2}
а в чем тут ошибка?
там где дна нет (высота = 0) воды быть не должно — в «бездну» сливается :)
выше подобную модель мне «подсовывали»…
выше подобную модель мне «подсовывали»…
это тоже поправил
И я разомнусь.
На python, с рекурсией
На python, с рекурсией
def pool(array, voda = 0):
row = [x-1 if x > 1 else 0 for x in array]
str_row = ''.join(['1' if x else '0' for x in row])
str_row = str_row[str_row.find('1'):str_row.rfind('1')]
cur_voda = str_row.count('0')
voda += cur_voda
if '1' in str_row:
return pool(row, voda)
return voda<source lang="python">
рекурсия зло.
Ну ок, рекурсия тут вовсе не нужна
gist с тестами
def pool(array):
voda = 0
while sum(array):
array = [x-1 if x > 1 else 0 for x in array]
str_row = ''.join(['1' if x else '0' for x in array])
str_row = str_row[str_row.find('1'):str_row.rfind('1')]
cur_voda = str_row.count('0')
voda += cur_voda
return voda
gist с тестами
Неприятно осознавать, что такую задачу на собеседовании я бы не решил за разумное время (15 мин)
Вряд ли интервьювер бы ждал больше. (Под решением я подразумеваю рабочий код)
С другой стороны в условиях коммерческой разработки с жесткими дедлайнами и высокими требованиями к качеству продукта я работаю вполне успешно.
Я вижу два объяснения:
1. Я достаточно жестко «вошел в колею» — проектирую, пишу код в соответствии со стандартами, отдаю в тестирование, деплоймент на продакшн, поддержка. Сложно перестроиться на что-то новое.
2. Задача достаточно сильно оторвана от жизни.
Вряд ли интервьювер бы ждал больше. (Под решением я подразумеваю рабочий код)
С другой стороны в условиях коммерческой разработки с жесткими дедлайнами и высокими требованиями к качеству продукта я работаю вполне успешно.
Я вижу два объяснения:
1. Я достаточно жестко «вошел в колею» — проектирую, пишу код в соответствии со стандартами, отдаю в тестирование, деплоймент на продакшн, поддержка. Сложно перестроиться на что-то новое.
2. Задача достаточно сильно оторвана от жизни.
Я один заметил что на картинке высота башенок 5 и 6 совпадают?
Как я завалил собеседование в Twitter