Комментарии 31
Простите за вопрос, что такое идея объекта?
Судя по коду, банальный идентификатор с точностью до equals.
Идея объекта возможно не лучший термин, но другого не нашел. Речь идет о том, что мы используем не конкретный объект — экземпляр — почтового ящика джона, а тот факт, что у джона он есть. То есть мы блокируем все операции с ящиком джона в принципе, а не операции на конкретном экземпляре ящика.
Простите за оффтоп, у вас Ктулху со строчной к.
Недавно на stackoverflow спрашивали, как сделать подобную блокировку: . Было предложено безопасное решение без блокирования таблицы локов и без создания лишних объектов.
А не поделитесь, плиз, ссылкой?
Было бы интересно почитать.
А то на ум приходит только заранее создать N-объектов, из которых потом по хэшу выбирать тот, который будет использоваться для блокировки. Либо же создавать их по мере необходимости и класть в таблицу через putIfAbsent, но тогда, возможно, будет множество лишних объектов.
В общем, интересно узнать, какие еще могут быть варианты.
Было бы интересно почитать.
А то на ум приходит только заранее создать N-объектов, из которых потом по хэшу выбирать тот, который будет использоваться для блокировки. Либо же создавать их по мере необходимости и класть в таблицу через putIfAbsent, но тогда, возможно, будет множество лишних объектов.
В общем, интересно узнать, какие еще могут быть варианты.
http://stackoverflow.com/questions/21286831/managing-multiple-locks
В предложеном решении, как и у вас, объекты удаляются сразу, как стали не нужны. Возможно, лучше было бы выдержать некоторое время.
В предложеном решении, как и у вас, объекты удаляются сразу, как стали не нужны. Возможно, лучше было бы выдержать некоторое время.
Спасибо большое за ссылку. Как я и думал, это в точности второй вариант, там кладут через putIfAbsent в таблицу — все-таки это не совсем «без создания лишних объектов».
Но все равно, если количество объектов, которые мы хотим защитить блокировками, ограничено, то такой вариант гораздо проще и, имхо, производительнее предложенного в статье.
Но все равно, если количество объектов, которые мы хотим защитить блокировками, ограничено, то такой вариант гораздо проще и, имхо, производительнее предложенного в статье.
Насчет проще не уверен, ибо количество кода больше. Если вы про вариант с семафором то у него большая проблема с повторным вхождением. Если вместо семафора брать ReentrantLock, то есть на том-же гитхабе вариант UnsafeIdBasedLockManager но у него есть проблемы с возможными race conditions (потому и Unsafe).
Кстати замечание о проблемах с remove есть на линке Stackoverflow тоже.
Насчет производительности, на моем i7 2010 года 50.000.000 операций (из 5 потоков)
Без блокировки: 2020 мс
Safe — пример из статьи: 21044 мс
Unsafe — putIfAbsent в ConcurrentMap: 12192 мс.
Да, в два раза быстрее, но эти «2раза» — 2 наносекунды. Думаю для 99.9999999% приложений это достаточно быстро.
Кстати ConcurrentHashMap не даёт гарантию что не будет synchronized, просто вероятность в 16 раз ниже.
Кстати замечание о проблемах с remove есть на линке Stackoverflow тоже.
Насчет производительности, на моем i7 2010 года 50.000.000 операций (из 5 потоков)
Без блокировки: 2020 мс
Safe — пример из статьи: 21044 мс
Unsafe — putIfAbsent в ConcurrentMap: 12192 мс.
Да, в два раза быстрее, но эти «2раза» — 2 наносекунды. Думаю для 99.9999999% приложений это достаточно быстро.
Кстати ConcurrentHashMap не даёт гарантию что не будет synchronized, просто вероятность в 16 раз ниже.
Unsafe — putIfAbsent в ConcurrentMap— это вы так назвали вариант http://stackoverflow.com/questions/21286831/managing-multiple-locks/21339300#21339300? Что ж в нем небезопасного? Если вы там обнаружили ошибку, то сообщите в комментарии к варианту.
Далее, putIfAbsent там используется только в случае столкновения на конкретном id, то есть достаточно редко.
И 12192 мс для 10^7 операций — это 1 микросекунда на операцию, а не наносекунда.
Можете пояснить, чем глобальный лок на manager в вашей реализации лучше, чем глобальный лок на getMailbox()?
Если getMailbox будет всегда таким простым, то наверное ничем, но вот более реалистичная реализация (схематично описанная):
Тут уже разница есть, не так ли?
private Mailbox getMailbox(UserId id) {
Mailbox fromCache = cache.get(id);
if (fromCache != null) {
return fromCache;
}
Mailbox fromPersistenceService = null;
try {
fromPersistenceService = pService.loadMailbox(id);
} catch(MailboxDoesntExistException e) {
fromPersistenceService = new Mailbox();
} catch(MessagingPersistenceServiceException e) {
throw new MessagingServiceException("Couldn't retrieve mailbox due", e);
}
cache.put(id, fromPersistenceService);
return fromPersistenceService;
}
Тут уже разница есть, не так ли?
А что если проверку на уникальность ящика переложить на кэш?
А кэш уже должен проверять, в единственном ли экземпляре этот объект. Т.е., если другой поток вдруг добавил такой ящик, то этот уже не добавится, и будет возвращен предыдущий.
private Mailbox getMailbox(UserId id) {
Mailbox fromCache = cache.get(id);
if (fromCache != null) {
return fromCache;
}
Mailbox fromPersistence = //create mailbox
cache.put(id, fromPersistence);
return cache.get(id);
}
А кэш уже должен проверять, в единственном ли экземпляре этот объект. Т.е., если другой поток вдруг добавил такой ящик, то этот уже не добавится, и будет возвращен предыдущий.
То будет по сути тот-же ConcurrentMap и putIfAbsent но в другом месте. Количество запросов к pService будет больше чем могло бы быть. Работать будет, но имхо менее элегантно.
Количество запросов будет ненамного больше, чем могло бы быть. Т.е., если количество запросов к кэшу на получение ссылки на ящик за время жизни приложения в среднем равно 2 на ящик, то это худший вариант по лишним запросам, но тогда не нужен кэш. Если запросов все-таки много, то кэш будет в подавляющем большинстве случаев сразу отдавать готовый ящик. Зато локов будет меньше, а создание ящиков я бы вообще спрятал в сам кэш, чтобы объекты, которым этот ящик нужен, обращались бы напрямую к кэшу (сейчас не очень понятно, где находится метод getMailbox), получился бы более простой интерфейс.
Ну сейчас мы плавно пересекаем границу, за которой вопрос становится более субъективным и немного философским.
То есть Вы переносите проблему в кэш, а как он там её будет решать дело его. Мне нравится в моём подходе, что блокировка происходит максимально рано, но с минимальным overhead и lock contention.
Если блокировка будет проходить позже, то сложнее искать проблемы при перекрестных вызовах функций. Опять же блокировка должна поддерживать повторный вход, то есть семафоры не катят.
Но в целом это конечно дело вкуса, я использую это во многих проектах и другие люди используют. Те кто пользуются говорят: «Как отлично» и «Нет аналогов». Но это их субъективное мнение, и я уверен, что вы можете написать лучше и более подходяще по Ваш вкус и стиль!
Кстати по поводу использования, проект был частью другой библиотеки (http://svn.anotheria.net/opensource/ano-util/trunk/, search.maven.org/#search%7Cga%7C1%7Cano-util), я его вынес в отдельный git repository и отдельный мавен артефакт, чтобы убрать лишнее. Но сам код работает года 4 на разных сайтах в продакшен.
Так, что выложил просто: может кому-то пригодится.
То есть Вы переносите проблему в кэш, а как он там её будет решать дело его. Мне нравится в моём подходе, что блокировка происходит максимально рано, но с минимальным overhead и lock contention.
Если блокировка будет проходить позже, то сложнее искать проблемы при перекрестных вызовах функций. Опять же блокировка должна поддерживать повторный вход, то есть семафоры не катят.
Но в целом это конечно дело вкуса, я использую это во многих проектах и другие люди используют. Те кто пользуются говорят: «Как отлично» и «Нет аналогов». Но это их субъективное мнение, и я уверен, что вы можете написать лучше и более подходяще по Ваш вкус и стиль!
Кстати по поводу использования, проект был частью другой библиотеки (http://svn.anotheria.net/opensource/ano-util/trunk/, search.maven.org/#search%7Cga%7C1%7Cano-util), я его вынес в отдельный git repository и отдельный мавен артефакт, чтобы убрать лишнее. Но сам код работает года 4 на разных сайтах в продакшен.
Так, что выложил просто: может кому-то пригодится.
НЛО прилетело и опубликовало эту надпись здесь
На практике Safe… полностью хватает. Unsafe был экспериментом, попыткой улучшить. Экспериментом не до конца удачным — 0,01% ошибок из-за race condition при уничтожении лока и паралельном его-же создании…
Но знаете, что хорошо в гитхабе: можно форкнуть, попробовать и сделать pool request.
У Вас получится что-то интересное и будет нам всем от этого польза ;-)
Но знаете, что хорошо в гитхабе: можно форкнуть, попробовать и сделать pool request.
У Вас получится что-то интересное и будет нам всем от этого польза ;-)
Ой, кажется у вас молоко убежало
public class UnsafeIdBasedLockManager<K> extends AbstractIdBasedLockManager<K>
implements IdBasedLockManager<K> {
private ConcurrentMap<K, IdBasedLock<K>> locks = new ConcurrentHashMap<K, IdBasedLock<K>>();
// blah blah blah
}
Почему бы не захватить лишний раз lock, чтобы таки его отпустить…
И еще вопрос: зачем вообще refCount быть AtomicInteger? Во всех случаях он и так бережно обернут lockами или synchronized .
@Override
public void releaseLock(IdBasedLock<K> lock) {
K id = lock.getId();
lock.lock();
if (lock.getRefCount().get() == 1) {
IdBasedLock previous = locks.remove(id);
}
lock.decreaseRefCount();
lock.unlockWithoutRelease();
}
И еще вопрос: зачем вообще refCount быть AtomicInteger? Во всех случаях он и так бережно обернут lockами или synchronized .
Встречая подобные оптимизации, неизменно задаюсь вопросом — а как определили необходимость таких оптимизаций? Проводились ли тесты и было спрогнозировано, что система скоро будет сильно тормозить, или может быть были жалобы от пользователей? А как будет работать в случае распределенного приложения? Нужны ли наносекунды, если отправление почты требует сотен миллисекунд? Ну и тому подобные вопросы :)
Вы сейчас о чем конкретно?
«это убило бы нашу производительность на корню»
Конечно, вот Вам пример такого synchronize:
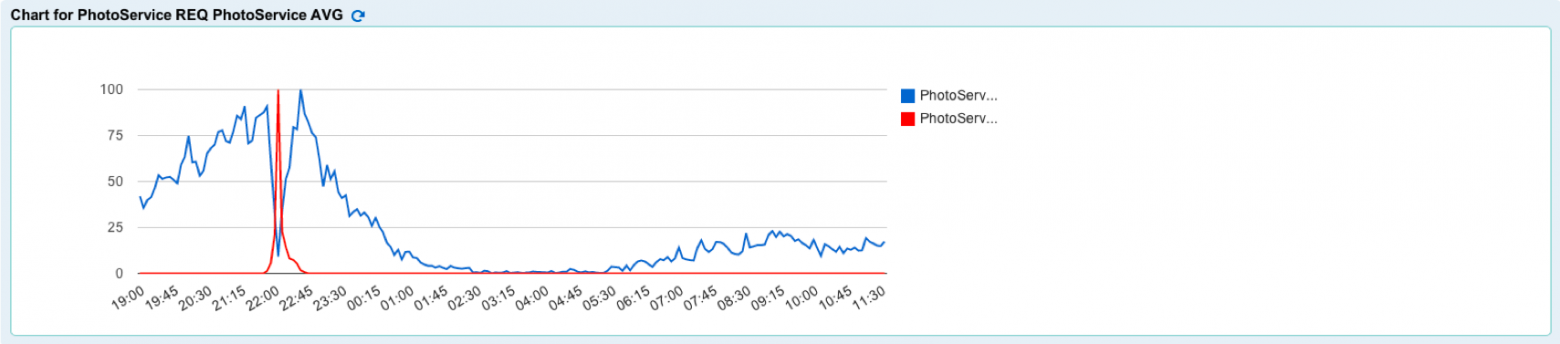
Средняя длительность обработки подымается (ведь все ждут одного), количество обработанных запросов падает, и вот результат для пользователя:

В данном случае страница, которая выдавалась за 200-300 миллисекунд, стала выдаваться за 58 (!) секунд. Чувствительно?

Средняя длительность обработки подымается (ведь все ждут одного), количество обработанных запросов падает, и вот результат для пользователя:

В данном случае страница, которая выдавалась за 200-300 миллисекунд, стала выдаваться за 58 (!) секунд. Чувствительно?
Ваш SafeIdBasedLockManager.obtainLock все еще synchronized. Советую посмотреть в сторону Ctrie, которая позволит решить туже задачу намного эффективней.
Попробовал. К сожалению есть race conditions, те же что и с ConcurrentMap. Скорость практически такая же как и synchronized:
Unsynched: Workers 5000000, Counters: 4780209 -> 219791 in 326 ms, ErrorRate: 0.0439582
---> Safely synched: Workers 5000000, Counters: 5000000 -> 0 in 2526 ms, ErrorRate: 0.0
---> CTRIE synched: Workers 5000000, Counters: 4998390 -> 1610 in 2236 ms, ErrorRate: 3.22E-4
Unsafely synched: Workers 5000000, Counters: 4999808 -> 192 in 1762 ms, ErrorRate: 3.84E-5
https://github.com/anotheria/idbasedlock/blob/ctrie/java/net/anotheria/idbasedlock/CtrieIdBasedLockManager.java
Unsynched: Workers 5000000, Counters: 4780209 -> 219791 in 326 ms, ErrorRate: 0.0439582
---> Safely synched: Workers 5000000, Counters: 5000000 -> 0 in 2526 ms, ErrorRate: 0.0
---> CTRIE synched: Workers 5000000, Counters: 4998390 -> 1610 in 2236 ms, ErrorRate: 3.22E-4
Unsafely synched: Workers 5000000, Counters: 4999808 -> 192 in 1762 ms, ErrorRate: 3.84E-5
https://github.com/anotheria/idbasedlock/blob/ctrie/java/net/anotheria/idbasedlock/CtrieIdBasedLockManager.java
Или я не понимаю Ваш вывод, или в вашем примере +12% скорости.
Вы также не указали количество потоков используемое и какое железо.
Я убежден что при использовании сильно-параллельной архитектуры, с большим количеством сокетов(и толстым Interconnect-ом), те например 4-восмиядерхых Xeon-а разница будет более чем ощутима.
Вы также не указали количество потоков используемое и какое железо.
Я убежден что при использовании сильно-параллельной архитектуры, с большим количеством сокетов(и толстым Interconnect-ом), те например 4-восмиядерхых Xeon-а разница будет более чем ощутима.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
IdBasedLocking