I. В чём проблема.
Почтовые ящики, «Входящие» личных сообщений, RSS — всё это объединяет одно удобство: чёткое разделение прочитанных и непрочитанных сообщений. Однако в блогах и социальных сетях, по крайней мере самых распространённых, такая возможность чаще всего не предусмотрена. И по досадному совпадению именно эти ресурсы не предоставляют пользователям потоки RSS.
Вроде бы не так сложно помнить, что ты прочитал, а что ещё нет. Но если следишь за очень динамичной лентой или за активным обсуждением одной темы, порой не так уж просто сразу разобраться. Да и постоянно прочитывать одно-два первых предложений вхолостую, чтобы только понять, что ты это уже читал, — не такое уж приятное и безвредное занятие.
Раньше я пользовался таким способом: назначал пользовательские стили поверх сайтовых, которые бы ярче выделяли просмотренные ссылки; в конце очередного чтения открывал последний (он же обычно верхний) пост отдельно, чтобы ссылка на него попала в историю браузера; впоследствии первая такая ссылка на прочитанный пост и служила водоразделом старых и новых сообщений. Однако это всё равно не очень наглядный способ.
Конечно, можно написать целое расширение для любимого браузера или хитрый пользовательский скрипт под одно из распространённых расширений, но хотелось найти способ простой и кроссбраузерный. Так и родилась следующая идея. Я не программист, поэтому не ставлю задачу предложить готовое изящное решение и понимаю, что способ мой и в принципе неуклюж, и в реализации наверняка уродлив. Поэтому задачи у описания будут скорее такие:
1. Обсудить саму проблему. Возможно, давно известны принципиально иные способы, проще, надёжнее и красивее. То есть я ломлюсь в открытую дверь и изобретаю велосипед. Поделитесь ими, пожалуйста.
2. Подумать сообща над особенностями текущей реализации. Возможно, способ можно усовершенствовать в большом и малом. Впрочем, совсем уж в малом, может, и не нужно, не движок же мы разрабатываем и не библиотеку.
То есть всё это на правах очень черновой идеи.
II. Решение в общих чертах.
Относительно идеальный «оверлейный» способ выглядел бы так: лента состоит из однородных соподчинённых элементов с постоянными уникальными идентификаторами; создаём букмарклет, который будет принимать указание на последний прочитанный пост, наглядно помечать и его, и все следующие за ним более старые посты, запоминать идентификатор последнего прочитанного поста и впоследствии восстанавливать по нему границу.
Но тут мы натыкаемся на целый ряд проблем:
1. Не всегда строение лент у всех пользователей имеет одинаковую структуру.
2. Не всегда посты являются однородными соподчинёнными элементами.
3. Не всегда у них есть классические идентификаторы.
4. Не всегда на текущей странице с самого начала чтения находится уже некогда прочитанный пост.
5. Некоторые сайты агрессивно настроены к самому удобному на текущий момент кроссбраузерному средству хранения информации.
Примеры этих проблем будем приводить по ходу дальнейшего описания. Но для начала представим в первом приближении реализацию самого оптимистичного варианта.
Оценка четырёх упомянутых в заголовке сетей (перечисленных в порядке усложнения диагноза) показывает, что отсутствие идентификаторов сообщений можно восполнить ссылками на эти сообщения внутри самих сообщений: ссылки эти по определению уникальны и постоянны. Вот где они прячутся в сетях, взятых за образец (подчёркнуто красным):
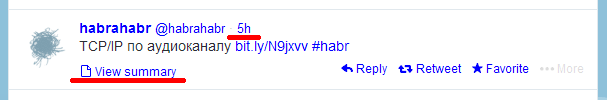
VK

LiveJournal
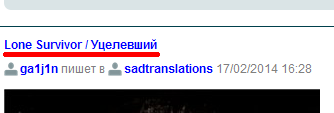
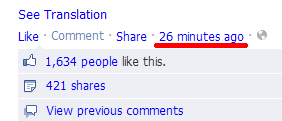
Чтобы указать скрипту в букмарклете на нужную ссылку, мы прямо перед запуском скрипта мышкой выделяем часть ссылки (так чтобы курсор/фокус оставались внутри ссылки). Скрипт запоминает адрес ссылки в localStorage на будущее, поднимается по цепочке элементов до главного контейнера поста и назначает ему особый класс. Скрипт создаёт стиль для этого класса и всех последующих соподчинённых элементов, чтобы весь прочитанный сегмент был выделен, например, особым цветом.
Если на странице ничего не выделено, скрипт считает, что мы только начинаем чтение после перерыва, поэтому он сразу обращается в localStorage, извлекает из него ссылку на прочитанный ранее пост, пытается её найти, а затем повторяет путь до верхнего контейнера и все операции со стилями.
Скрипту необходимо будет совершить как минимум три проверки с сообщением о возможных неудачных результатах: является ли открытая страница сайтом, на который рассчитан скрипт и которому отведён нужный отдел в localStorage; выделил ли пользователь правильную ссылку (или не вышло ли выделение случайно за её границы); есть ли на странице прежде прочитанный пост, если пользователь ничего не выделял.
В ближайшем будущем, если у нас будет родительский селектор, можно будет вообще не иметь дела с localStorage, но создавать стили по цепочке для прадедушек просмотренных ссылок (если, конечно, ограничения стилей для просмотренных ссылок не станут ещё более строгими для их родительских и прародительских элементов). Правда, тогда придётся открывать-таки последний пост отдельно, чтобы он попал в историю.
III. Частные особенности анализируемых сайтов
Тут нам повезло со структурой ленты (твиты однородны и соподчинены). Но вот принцип малого дозирования твитов с бесконечной прокруткой приводит к тому, что нам, возможно, придётся несколько раз прокрутить страницу вниз, пока на ней физически появится прочитанный до перерыва пост. Впрочем, несколько нажатий клавиши «End» поочерёдно с букмарклетом — не такое уж утомительное занятие. Такая же проблема сохранится для VK и Facebook: если прочитанный сегмент успел уйти вглубь ленты, скрипт несколько раз сообщит о том, что последний пост не найден, прежде чем сможет пометить границу.
VK
Тут со структурой тоже всё в порядке, но есть небольшое предостережение: при спешке легко перепутать ссылку на оригинал чужого поста со ссылкой на его репост в нашей стене (нам нужен второй тип ссылок) — обе разновидности есть внутри поста и очень похожи. Также похожи ссылки на сам пост и на комментарии к нему. Скрипт пытается проверить, не спутал ли пользователь все эти ссылки. На текущий момент скрипт рассчитан на посты стены и новостей.
LiveJournal
Тут мы сталкиваемся с разнообразием строения лент друзей у разных пользователей. Чтобы как-то всё унифицировать, мы возьмём за основание мобильную ленту, ведь у неё единая для всех структура (на скриншоте выше как раз виден заголовок-ссылка к посту такой ленты). При этом потребность в нескольких прокрутках заменится потребностью в нескольких загрузках предыдущих страниц. Но и это не конец особенностей: не все посты в ленте одинаково соподчинены, потому что группы постов одного дня заключаются в отдельный контейнер, выйти за который нам не позволят особенности правил CSS3. Поэтому скрипт может пометить не весь прочитанный сегмент до конца, а лишь посты, одновременные по дню с последним прочитанным.
Самый проблемный вариант. Посты имеют очень сложную систему подчинения, распределены в нескольких динамичных контейнерах, имеют сложную систему нечитабельных классов. Поэтому однородности цветового выделения прочитанного не всегда можно достигнуть, разве что мы долго читаем ленту, не закрывая и не перезагружая вкладку. Вдобавок сайт отличается странным обращением с localStorage: периодически записи нашего скрипта пропадают оттуда, как будто скрипты самого сайта время от времени вычищают весь сегмент сайта в хранилище, считая себя исключительным хозяином в этой области (возможно, это и правильно?). К тому же при максимально дотошном слежении за друзьями и журналами, на которые подписан пользователь, в ленту попадают сообщения о комментариях друзей в других постах, и сообщения эти могут постоянно сдвигаться вверх ленты, сохраняя при этом единую ключевую ссылку, что разрушает последовательность постов и механизма слежения. Поэтому в такие постах лучше выделять ссылку на последний комментарий (к счастью, все XPath при этом работают, как и с ссылками на сам пост), чтобы не возникало путаницы при повторных комментированиях и сдвигах таких постов вверх ленты, в том числе перед непрочитанными постами.
Ещё небольшое общее предупреждение: отображаемый текст нужных нам ссылок в большинстве сетей автоматически обновляется где-то раз в минуту, подстраиваясь под прошедшее время, поэтому иногда наше выделение успевает слететь до нажатия на букмарклет — ведь после обновления ссылка уже как бы становится новым элементом интерфейса; никакого вреда этот сбой не приносит, скрипт просто заново отметит прежний прочитанный пост по данным в localStorage (так, будто мы ничего не выделяли), и нужно лишь выделить ссылку заново и ещё раз нажать на закладку.
IV. Реализация.
По идее, она должна работать во всех последних версиях браузеров, потому что использованы стандартные, хоть и относительно новые средства. Прошу прощения за неуклюжий дилетантский код.
Читабельный вариант:
javascript:(function(xpaths, doc, hst, stl, sel, lnks, i, a_lnk, the_lnk, post) {
xpaths = {
'twitter.com': {
'lnk': './ancestor-or-self::a[contains(@class, "tweet-timestamp") or contains(@class, "details")]',
'post': './ancestor::li[contains(@class, "stream-item")]'
},
'vk.com': {
'lnk': './ancestor-or-self::a[descendant::span[contains(@class, "rel_date")] and not(contains(@class, "wd_lnk"))]',
'post': './ancestor::div[contains(@class, "feed_row") or contains(@class, "post") and not(@id="page_wall_posts")]'
},
'm.livejournal.com': {
'lnk': './ancestor-or-self::a[ancestor::h3[contains(@class, "item-header")]]',
'post': './ancestor::li[contains(@class, "post-list-item")]'
},
'www.facebook.com': {
'lnk': './ancestor-or-self::a[descendant::abbr[@data-utime]]',
'post': './ancestor::div[contains(@class, "_5jmm") and contains(@class, "_5pat") and contains(@class, "_5uch")]'
}
};
doc = document;
hst = doc.location.hostname;
if(xpaths[hst]) {
if(!doc.querySelector('style#usernameReadPost')) {
stl = doc.querySelector('head').appendChild(doc.createElement('style'));
stl.id = 'usernameReadPost';
stl.innerHTML = '.usernameReadPost, .usernameReadPost ~ * {background-color: silver !important;}';
}
sel = doc.getSelection();
if(sel.isCollapsed) {
lnks = doc.querySelectorAll('a[href$="' + localStorage.getItem('usernameReadPost') + '"]');
for (i = 0, a_lnk; a_lnk = lnks[i]; i++) {
the_lnk = doc.evaluate(xpaths[hst].lnk, a_lnk, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
if(the_lnk) {
post = doc.evaluate(xpaths[hst].post, the_lnk, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
break;
}
}
if(post) {
post.className += ' usernameReadPost';
}
else {
alert('Read post not found.');
}
}
else {
the_lnk = doc.evaluate(xpaths[hst].lnk, sel.focusNode, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
if(the_lnk) {
post = doc.evaluate(xpaths[hst].post, the_lnk, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
post.className += ' usernameReadPost';
localStorage.setItem('usernameReadPost', the_lnk.getAttribute('href'));
}
else {
alert('Wrong link.');
}
}
}
else {
alert('Wrong hostname.');
}
})()
Сокращённый вариант:
Версия с удалёнными форматирующими пробелами и переводами строки (в Firefox можно просто перетащить в закладки и заменить потом название на что-то читабельное; этот код укладывается в два килобайта, на случай если такое ограничение для последних версий IE ещё действует).
javascript:(function(xpaths,doc,hst,stl,sel,lnks,i,a_lnk,the_lnk,post){xpaths={'twitter.com':{'lnk':'./ancestor-or-self::a[contains(@class,"tweet-timestamp")or contains(@class,"details")]','post':'./ancestor::li[contains(@class,"stream-item")]'},'vk.com':{'lnk':'./ancestor-or-self::a[descendant::span[contains(@class,"rel_date")]and not(contains(@class,"wd_lnk"))]','post':'./ancestor::div[contains(@class,"feed_row")or contains(@class,"post")and not(@id="page_wall_posts")]'},'m.livejournal.com':{'lnk':'./ancestor-or-self::a[ancestor::h3[contains(@class,"item-header")]]','post':'./ancestor::li[contains(@class,"post-list-item")]'},'www.facebook.com':{'lnk':'./ancestor-or-self::a[descendant::abbr[@data-utime]]','post':'./ancestor::div[contains(@class,"_5jmm")and contains(@class,"_5pat")and contains(@class,"_5uch")]'}};doc=document;hst=doc.location.hostname;if(xpaths[hst]){if(!doc.querySelector('style#usernameReadPost')){stl=doc.querySelector('head').appendChild(doc.createElement('style'));stl.id='usernameReadPost';stl.innerHTML='.usernameReadPost,.usernameReadPost~*{background-color:silver !important;}';}sel=doc.getSelection();if(sel.isCollapsed){lnks=doc.querySelectorAll('a[href$="'+localStorage.getItem('usernameReadPost')+'"]');for(i=0,a_lnk;a_lnk=lnks[i];i++){the_lnk=doc.evaluate(xpaths[hst].lnk,a_lnk,null,XPathResult.FIRST_ORDERED_NODE_TYPE,null).singleNodeValue;if(the_lnk){post=doc.evaluate(xpaths[hst].post,the_lnk,null,XPathResult.FIRST_ORDERED_NODE_TYPE,null).singleNodeValue;break;}}if(post){post.className+=' usernameReadPost';}else{alert('Read post not found.');}}else{the_lnk=doc.evaluate(xpaths[hst].lnk,sel.focusNode,null,XPathResult.FIRST_ORDERED_NODE_TYPE,null).singleNodeValue;if(the_lnk){post=doc.evaluate(xpaths[hst].post,the_lnk,null,XPathResult.FIRST_ORDERED_NODE_TYPE,null).singleNodeValue;post.className+=' usernameReadPost';localStorage.setItem('usernameReadPost',the_lnk.getAttribute('href'));}else{alert('Wrong link.');}}}else{alert('Wrong hostname.');}})()
Можно также перетащить готовую ссылку отсюда (она там одноименна этому посту).
Краткое пояснение к коду
Чтобы можно было использовать один букмарклет ко всем нужным сайтам, вначале мы создаём базу путей XPath для двух нужных элементов: ссылки на пост и верхнего контейнера поста. Особая громоздкость и странность путей обусловлена как минимум двумя причинами: при выделении ссылки элементом фокуса часто оказывается то сама ссылка, то подчинённый ей элемент, то конечный текстовый узел; не всегда ссылки и контейнеры имеют уникальное сочетание имени тега и класса, приходится подключать параметры содержащих или подчинённых элементов.
Первым делом скрипт проверяет страницу на принадлежность к нужному сайту. Если есть совпадение, создаётся нужный стиль (если он уже не был создан запуском скрипта на этой же странице): пока всё просто, мы всего лишь помечаем прочитанное серым.
Далее скрипт проверяет, есть ли на странице выделенный пользователем участок. Если нет, значит, это первое чтение страницы после перерыва, поэтому начинать нужно с восстановления старой границы: скрипт перебирает все подходящие под заданный XPath ссылки и сопоставляет их с сохранённым адресом из localStorage. Если нужная ссылка найдена, она становится отправной точкой для поиска по XPath верхнего контейнера всего поста. Если и ссылка, и пост найдены, добавляется класс и применяется стиль. Иначе пользователь оповещается о необходимости прокручивать страницу или загружать другие страницы вглубь ленты.
Если на странице есть выделение сегмента, скрипт проверяет элемент, посреди которого выделение завершается. Если это нужная ссылка, повторяются операции с поиском и пометкой постов, а затем адрес ссылки помещается в localStorage. Если это не та ссылка (или пользователь промахнулся с окончанием выделения), об этом выдаётся сообщение.
Желающие могут ещё более сократить названия переменных, заменить название-заглушку ключевого класса прочитанных постов и идентификатора дополнительного стиля согласно своим никам для пущей уникальности, отказаться от использования мобильной ленты в ЖЖ и подогнать параметры под структуру своей ленты, не говоря уже о более существенных усовершенствованиях (можно, например, навесить на страницу обработчик событий выделения ссылки, чтобы не приходилось каждый раз нажимать на букмарклет во время беспрерывного чтения автоматически обновляющейся ленты).
Если кто-то посчитает способ хоть немного достойным улучшения, идеями и кодом можно делиться в комментариях. Буду благодарен за дополнения, исправления и информацию о поддержке в браузерах (сам тестировал только на последних ночных сборках Firefox).







