(Окончание статьи от Марины Ильиных virtualtomato, старшего менеджера проектов в All Correct Localization)
В прошлый раз мы рассказывали о том, как наши менеджеры работают с файлами, которые попадают к нам на локализацию. Это статья оказалась для нас очень полезной, так как один из читателей показал нам отличный фильтр подгрузки, которым мы раньше мало пользовались. Надеюсь, в этот раз мы опять узнаем что-нибудь новенькое.

Когда проект подгружен, правильно обработан, а переводчики уже назначены на все документы, начинается самая главная работа, с которой очень часто и отождествляется локализация. Перевод.
Так почему же, даже отбросив в сторону технические удобства, переводить в программе memoQ лучше, чем без нее? Давайте разберемся.
Это окно работы с текстом. Тут работают переводчики и редакторы. Менеджеры тоже заглядывают сюда, чтобы проверить, все ли идет по плану.

Окно работы с текстом можно условно разделить на три части:
1) Область перевода.
2) Окно предварительного просмотра.
3) Окно работы с базами и глоссариями.
Здесь, казалось бы, все просто: есть оригинальный текст, есть место для перевода. Самое интересное, что у каждой ячейки есть статус. Основные статусы:
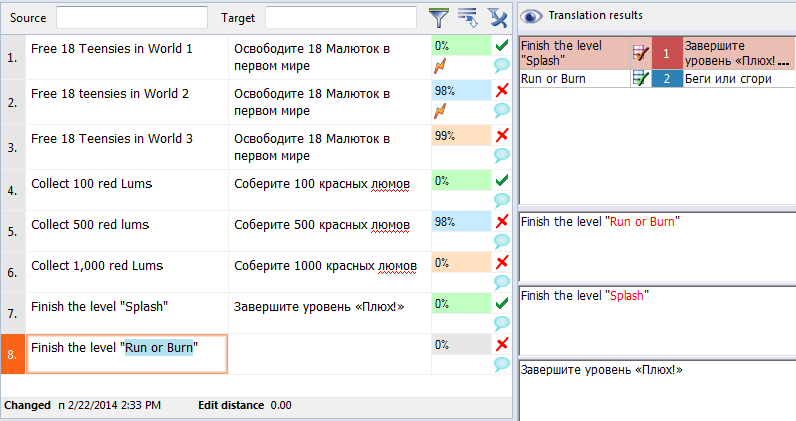
Это помогает переводчику более эффективно управлять своей работой. Возвращаться к ячейкам, над которыми он хотел бы еще подумать, отфильтровывать пустые ячейки, добавлять в базу готовый перевод.
Около каждой ячейки указана степень совпадения сегмента с ТМ в процентах. Обратите внимание на ячейки с цифрами 98 %, 99 %. Это означает, что исходный текст очень похож на текст, который ранее уже был переведен. Чаще всего отличие заключается в цифрах, тегах, знаках препинания. Здесь уже не нужно переводить заново, достаточно просто поправить имеющийся перевод в соответствии с данным исходным текстом. Чем ниже степень совпадения, тем сильнее текст отличается от сегмента, сохраненного в базе, и тем большая редактура ему требуется. Мы, как правило, считаем, что ячейки со степенью совпадения ниже 85 % уже не подлежат редактуре, так как по степени затраченных исполнителем усилий работа с такими сегментами ближе к переводу.
К каждой ячейке можно добавить комментарий. Очень удобно, что данные о том, какой пользователь добавил комментарий, сохраняются, и иногда там разворачиваются целые дискуссии.
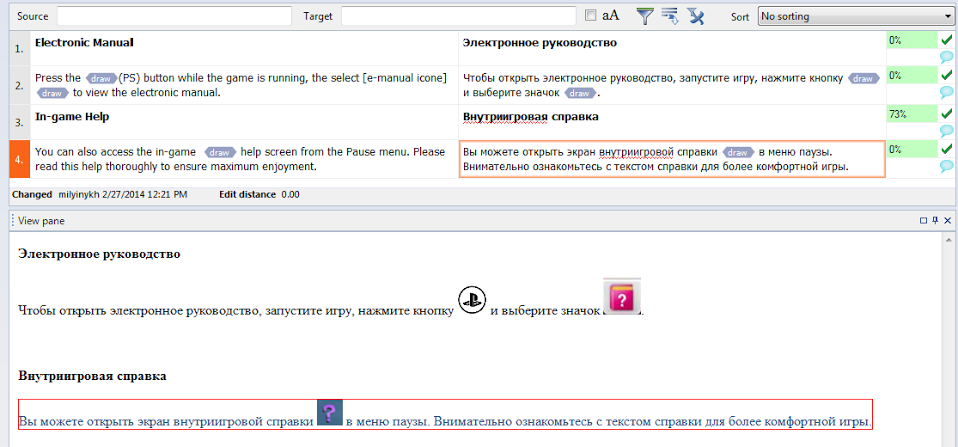
Здесь переводчик видит, как выглядит исходный файл. Это особенно важно, если в файле было много графической информации, которая в memoQ не подгружается, но в окне предпросмотра ее прекрасно видно.
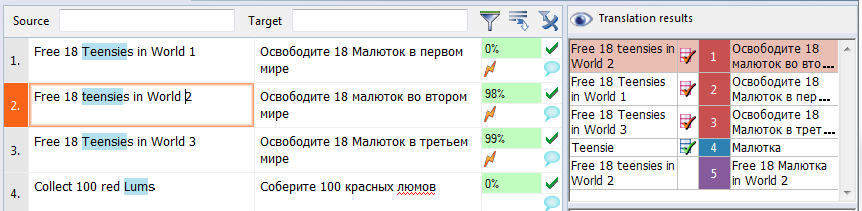
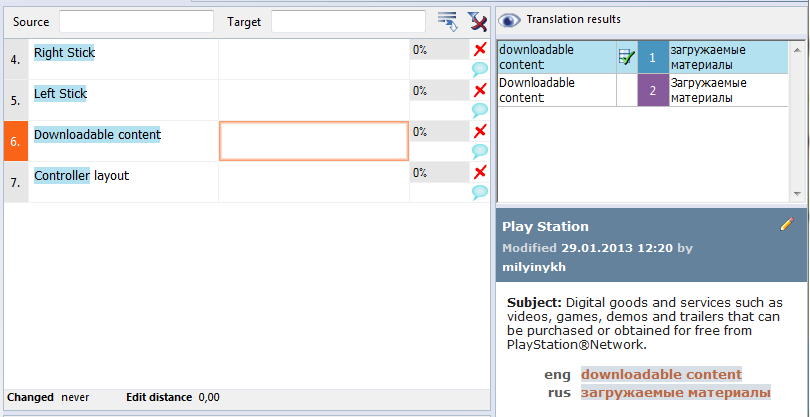
Ну и наконец самое главное: работа с базами. В этом окне переводчик видит полные и частичные совпадения с Translation Memory (оранжевые сегменты) и совпадения с глоссарием проекта (темно-синие сегменты).
Для нашего демонстрационного файла я внесла в глоссарий три термина: Малютка, люм и название уровня Беги или сгори. На картинке ниже вы можете увидеть, что занесение термина в глоссарий, хоть дело и легкое, но требующее определенного навыка.
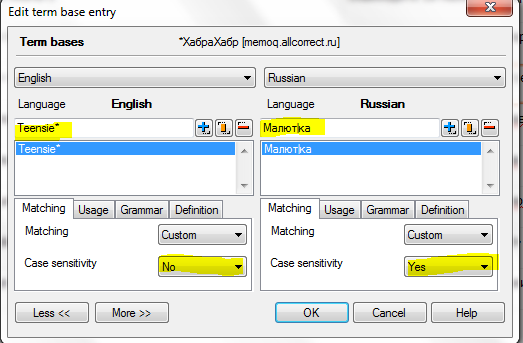
Мы знаем, что слово может употребляться в тексте в разных формах, в зависимости от числа, падежа, времени и уймы разных параметров. Поэтому при внесении термина в глоссарий мы обязательно добавляем технические символы:
* — заменяет любое количество символов (Teensie, Teensies)
| — отделяет изменяемую часть слова (Малютка, Малютки, Малюток…)
Второй важный аспект — это правила капитализации. Мы решили для себя, что Малютки у нас будут писаться с большой буквы, а люмы — с маленькой. Очень важно, однажды приняв это решение, всегда ему следовать, иначе в переводе будет неряшливая, неединообразная капитализация. Поэтому для русского языка мы ставим Case sensitivity — Yes, а для английского — No. Потому что мы знаем, что в исходном тексте бывают ошибки, а нам нужно, чтобы глоссарий всегда срабатывал. И на teensies, и на Teensies. Позже вы поймете, почему это важно.
К проекту можно подключать несколько глоссариев. Когда это может пригодиться? К игре FIFA 14 можно подключить глоссарий от FIFA 13, так как преемственность терминологии между играми в рамках одной франшизы — это важно. К проекту по переводу игры, скажем, на PlayStation 3 можно подключить глоссарий с терминологией PlayStation 3. Все это работает на качество локализации, а также делает труд переводчиков более приятным.
Представим, что мы наконец-то все перевели. И даже сделали Spell Check, о котором рассказывать нет особой нужды, так как он похож на проверку орфографии в Word. Теперь настало время автоматической проверки перевода. Чтобы было веселее, я внесла в наш перевод «немного» ошибок.
Ошибки:
А еще я добавила условие, что все строки должны быть не длиннее 35 символов.
Запускаем автопроверку и смотрим, что memoQ нам показывает.
Все ошибки найдены. Есть, правда, несколько невалидных предупреждений: программа не видит в переводе сегментов 1-3 цифры, поэтому думает, что есть ошибка, хотя в двух случаях из трех ее нет.
Что было бы если бы глоссарий был бы обработан не столь тщательно? Если бы мы не позаботились о капитализации и специальных символах? Было бы вот так:

Появилась бы одна лишняя невалидная ошибка, так как для memoQ термины «Малютка» и «Малюток» уже будут разными. А также вообще исчезли две ошибки с капитализацией слова «люм». И это проект всего лишь на восемь ячеек. На крупном проекте такое небрежное отношение к базам, приводит к огромному количеству ложных срабатываний Auto QA, а также к большому числу незамеченных мелких ошибок.
Переводить можно и на тетрадном листке. И, скорее всего, переводчик, который не ограничен во времени, бюджете и обладает всеми необходимыми навыками для выполнения задания, может довести перевод до совершенства и в таких условиях. Но когда тебе не нужно держать в голове все термины, когда ты знаешь, что мелкие помарки программа найдет сама и предложит тебе их исправить, когда в твоих руках куча дополнительного материала в виде глоссариев и баз, когда ничего не нужно переводить по два раза, тебе остается только расслабиться и делать то, с чем машина никогда не справится: отличный перевод.
Часть 2
В прошлый раз мы рассказывали о том, как наши менеджеры работают с файлами, которые попадают к нам на локализацию. Это статья оказалась для нас очень полезной, так как один из читателей показал нам отличный фильтр подгрузки, которым мы раньше мало пользовались. Надеюсь, в этот раз мы опять узнаем что-нибудь новенькое.

Когда проект подгружен, правильно обработан, а переводчики уже назначены на все документы, начинается самая главная работа, с которой очень часто и отождествляется локализация. Перевод.
Так почему же, даже отбросив в сторону технические удобства, переводить в программе memoQ лучше, чем без нее? Давайте разберемся.
Это окно работы с текстом. Тут работают переводчики и редакторы. Менеджеры тоже заглядывают сюда, чтобы проверить, все ли идет по плану.
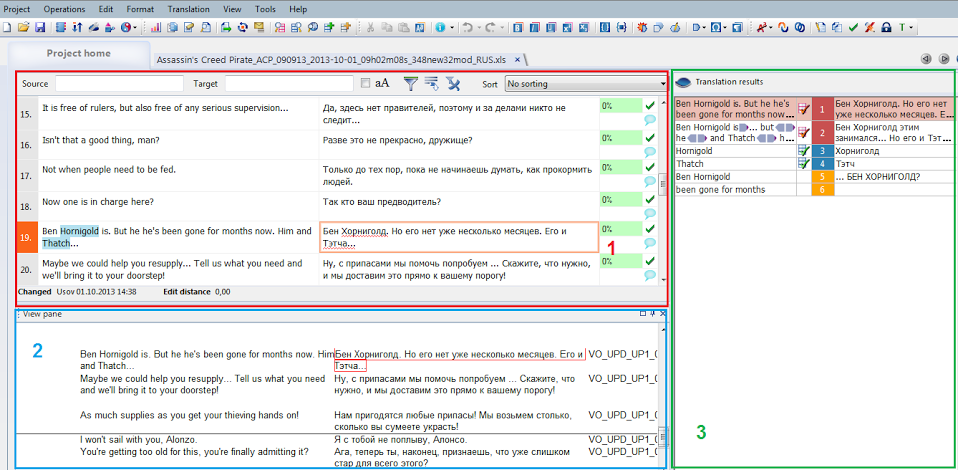
Окно работы с текстом можно условно разделить на три части:
1) Область перевода.
2) Окно предварительного просмотра.
3) Окно работы с базами и глоссариями.
Область перевода
Здесь, казалось бы, все просто: есть оригинальный текст, есть место для перевода. Самое интересное, что у каждой ячейки есть статус. Основные статусы:
- Not translated (серый) — к переводу ячейки не приступали.
- Edited (оранжевый) — с ячейкой работали, но перевод не завершен.
- Pre-translated (голубой) — ячейка подставила из базы во время выполнения операции «Предперевод».
- Confirmed (зеленый) — перевод ячейки завершен.

Это помогает переводчику более эффективно управлять своей работой. Возвращаться к ячейкам, над которыми он хотел бы еще подумать, отфильтровывать пустые ячейки, добавлять в базу готовый перевод.
Около каждой ячейки указана степень совпадения сегмента с ТМ в процентах. Обратите внимание на ячейки с цифрами 98 %, 99 %. Это означает, что исходный текст очень похож на текст, который ранее уже был переведен. Чаще всего отличие заключается в цифрах, тегах, знаках препинания. Здесь уже не нужно переводить заново, достаточно просто поправить имеющийся перевод в соответствии с данным исходным текстом. Чем ниже степень совпадения, тем сильнее текст отличается от сегмента, сохраненного в базе, и тем большая редактура ему требуется. Мы, как правило, считаем, что ячейки со степенью совпадения ниже 85 % уже не подлежат редактуре, так как по степени затраченных исполнителем усилий работа с такими сегментами ближе к переводу.
К каждой ячейке можно добавить комментарий. Очень удобно, что данные о том, какой пользователь добавил комментарий, сохраняются, и иногда там разворачиваются целые дискуссии.
Окно предварительного просмотра
Здесь переводчик видит, как выглядит исходный файл. Это особенно важно, если в файле было много графической информации, которая в memoQ не подгружается, но в окне предпросмотра ее прекрасно видно.
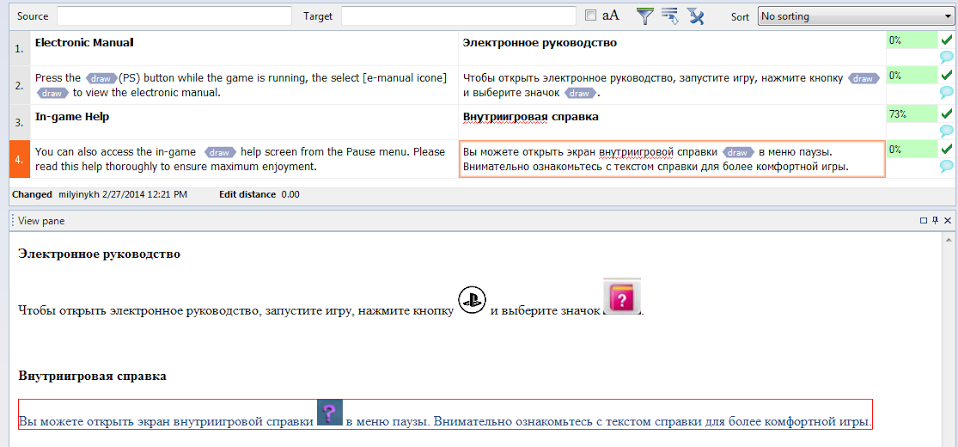
Окно работы с базами и глоссариями
Ну и наконец самое главное: работа с базами. В этом окне переводчик видит полные и частичные совпадения с Translation Memory (оранжевые сегменты) и совпадения с глоссарием проекта (темно-синие сегменты).
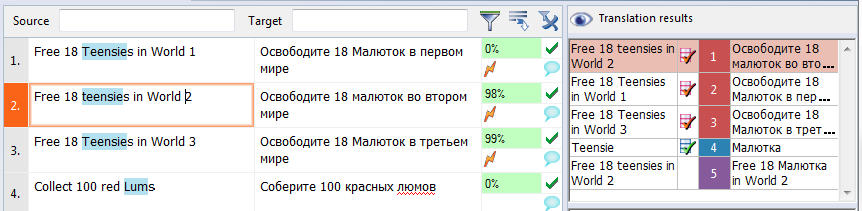
Для нашего демонстрационного файла я внесла в глоссарий три термина: Малютка, люм и название уровня Беги или сгори. На картинке ниже вы можете увидеть, что занесение термина в глоссарий, хоть дело и легкое, но требующее определенного навыка.
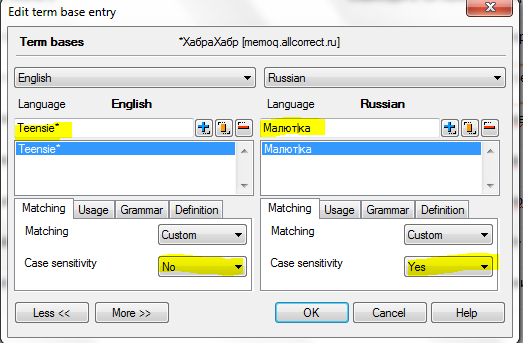
Мы знаем, что слово может употребляться в тексте в разных формах, в зависимости от числа, падежа, времени и уймы разных параметров. Поэтому при внесении термина в глоссарий мы обязательно добавляем технические символы:
* — заменяет любое количество символов (Teensie, Teensies)
| — отделяет изменяемую часть слова (Малютка, Малютки, Малюток…)
Второй важный аспект — это правила капитализации. Мы решили для себя, что Малютки у нас будут писаться с большой буквы, а люмы — с маленькой. Очень важно, однажды приняв это решение, всегда ему следовать, иначе в переводе будет неряшливая, неединообразная капитализация. Поэтому для русского языка мы ставим Case sensitivity — Yes, а для английского — No. Потому что мы знаем, что в исходном тексте бывают ошибки, а нам нужно, чтобы глоссарий всегда срабатывал. И на teensies, и на Teensies. Позже вы поймете, почему это важно.
К проекту можно подключать несколько глоссариев. Когда это может пригодиться? К игре FIFA 14 можно подключить глоссарий от FIFA 13, так как преемственность терминологии между играми в рамках одной франшизы — это важно. К проекту по переводу игры, скажем, на PlayStation 3 можно подключить глоссарий с терминологией PlayStation 3. Все это работает на качество локализации, а также делает труд переводчиков более приятным.

Auto QA
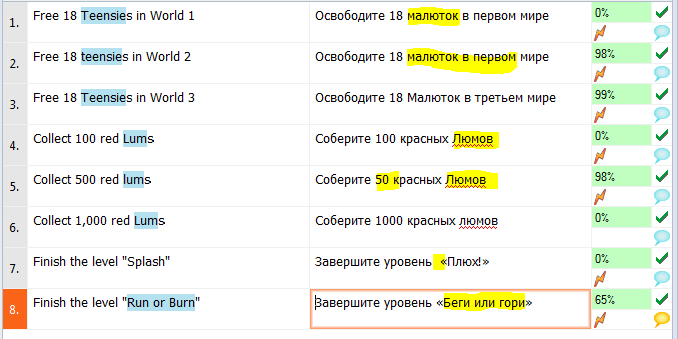
Представим, что мы наконец-то все перевели. И даже сделали Spell Check, о котором рассказывать нет особой нужды, так как он похож на проверку орфографии в Word. Теперь настало время автоматической проверки перевода. Чтобы было веселее, я внесла в наш перевод «немного» ошибок.
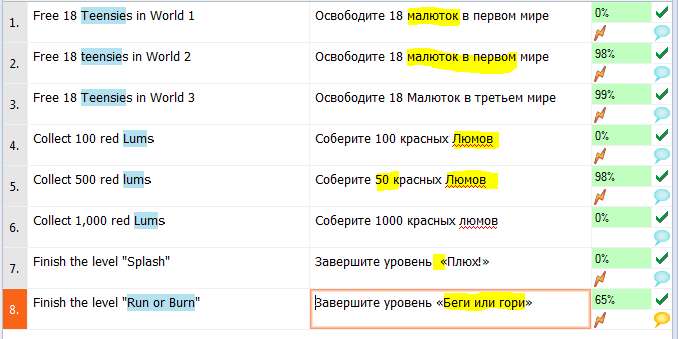
Ошибки:
- Неверная капитализация слова «Малютка»
- Неверный перевод цифрового значения в сегментах 2 и 5
- Неверная капитализация слова «люм»
- Двойной пробел в сегменте 7
- Неверный перевод термина Run or Burn
А еще я добавила условие, что все строки должны быть не длиннее 35 символов.
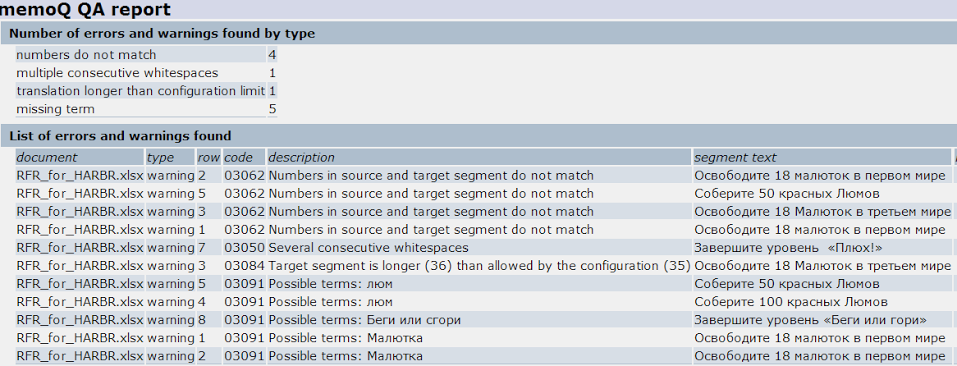
Запускаем автопроверку и смотрим, что memoQ нам показывает.
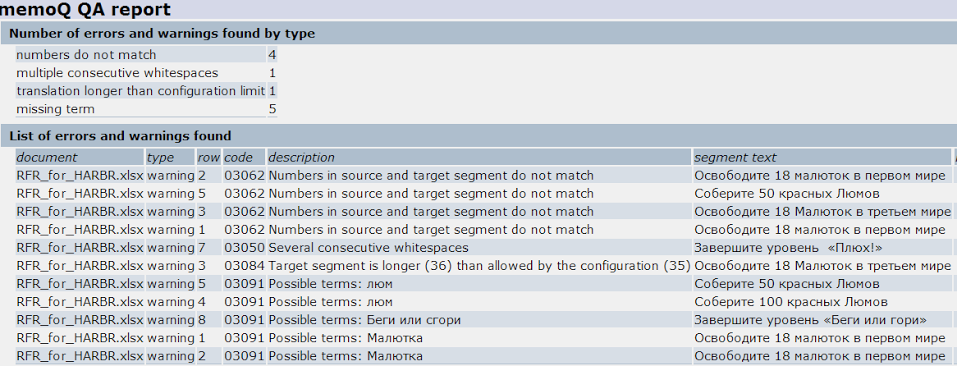
Все ошибки найдены. Есть, правда, несколько невалидных предупреждений: программа не видит в переводе сегментов 1-3 цифры, поэтому думает, что есть ошибка, хотя в двух случаях из трех ее нет.
Что было бы если бы глоссарий был бы обработан не столь тщательно? Если бы мы не позаботились о капитализации и специальных символах? Было бы вот так:

Появилась бы одна лишняя невалидная ошибка, так как для memoQ термины «Малютка» и «Малюток» уже будут разными. А также вообще исчезли две ошибки с капитализацией слова «люм». И это проект всего лишь на восемь ячеек. На крупном проекте такое небрежное отношение к базам, приводит к огромному количеству ложных срабатываний Auto QA, а также к большому числу незамеченных мелких ошибок.
Эпилог
Переводить можно и на тетрадном листке. И, скорее всего, переводчик, который не ограничен во времени, бюджете и обладает всеми необходимыми навыками для выполнения задания, может довести перевод до совершенства и в таких условиях. Но когда тебе не нужно держать в голове все термины, когда ты знаешь, что мелкие помарки программа найдет сама и предложит тебе их исправить, когда в твоих руках куча дополнительного материала в виде глоссариев и баз, когда ничего не нужно переводить по два раза, тебе остается только расслабиться и делать то, с чем машина никогда не справится: отличный перевод.
