В деле познания SAN столкнулся с определённым препятствием — труднодоступностью базовой информации. В вопросе изучения прочих инфраструктурных продуктов, с которыми доводилось сталкиваться, проще — есть пробные версии ПО, возможность установить их на вирутальной машине, есть куча учебников, референс гайдов и блогов по теме. Cisco и Microsoft клепают очень качественные учебники, MS вдобавок худо-бедно причесал свою адскую чердачную кладовку под названием technet, даже по VMware есть книга, пусть и одна (и даже на русском языке!), причём с КПД около 100%. Уже и по самим устройствам хранения данных можно получить информацию с семинаров, маркетинговых мероприятий и документов, форумов. По сети же хранения — тишина и мёртвые с косами стоять. Я нашёл два учебника, но купить не решился. Это "Storage Area Networks For Dummies" (есть и такое, оказывается. Очень любознательные англоговорящие «чайники» в целевой аудитории, видимо) за полторы тысячи рублей и "Distributed Storage Networks: Architecture, Protocols and Management" — выглядит более надёжно, но 8200р при скидке 40%. Вместе с этой книгой Ozon рекомендует также книгу «Искусство кирпичной кладки».
Что посоветовать человеку, который решит с нуля изучить хотя бы теорию организации сети хранения данных, я не знаю. Как показала практика, даже дорогостоящие курсы могут дать на выходе ноль. Люди, применительно к SAN делятся на три категории: те, кто вообще не знает что это, кто знает, что такое явление просто есть и те, кто на вопрос «зачем в сети хранения делать две и более фабрики» смотрят с таким недоумением, будто их спросили что-то вроде «зачем квадрату четыре угла?».
Попробую восполнить пробел, которого не хватало мне — описать базу и описать просто. Рассматривать буду SAN на базе её классического протокола — Fibre Channel.
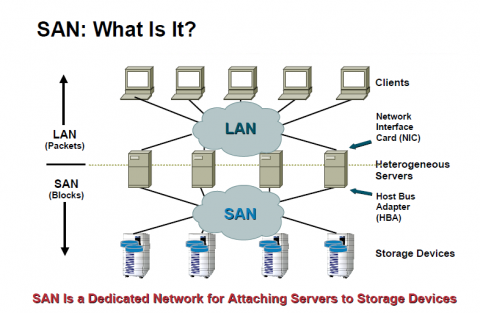
Итак, SAN — Storage Area Network — предназначена для консолидации дискового пространства серверов на специально выделенных дисковых хранилищах. Суть в том, что так дисковые ресурсы экономнее используются, легче управляются и имеют большую производительность. А в вопросах виртуализации и кластеризации, когда нескольким серверам нужен доступ к одному дисковому пространству, подобные системы хранения данных вообще незаменимая штука.
Кстати, в терминологиях SAN, благодаря переводу на русский, возникает некоторая путаница. SAN в переводе означает «сеть хранения данных» — СХД. Однако классически в России под СХД понимается термин «система хранения данных», то есть именно дисковый массив (Storage Array), который в свою очередь состоит из Управляющего блока (Storage Processor, Storage Controller) и дисковых полок (Disk Enclosure). Однако, в оригинале Storage Array является лишь частью SAN, хотя порой и самой значимой. В России получаем, что СХД (система хранения данных) является частью СХД (сети хранения данных). Поэтому устройства хранения обычно называют СХД, а сеть хранения — SAN (и путают с «Sun», но это уже мелочи).
Компоненты и термины
Технологически SAN состоит из следующих компонентов:
1. Узлы, ноды (nodes)
- Дисковые массивы (системы хранения данных) — хранилища (таргеты [targets])
- Серверы — потребители дисковых ресурсов (инициаторы [initiators]).
2. Сетевая инфраструктура
- Коммутаторы (и маршрутизаторы в сложных и распределённых системах)
- Кабели
Особенности
Если не вдаваться в детали, протокол FC похож на протокол Ethernet с WWN-адресами вместо MAC-адресов. Только, вместо двух уровней Ethernet имеет пять (из которых четвёртый пока не определён, а пятый — это маппинг между транспортом FC и высокоуровневыми протоколами, которые по этому FC передаются — SCSI-3, IP). Кроме того, в коммутаторах FC используются специализированные сервисы, аналоги которых для IP сетей обычно размещаются на серверах. Например: Domain Address Manager (отвечает за назначение Domain ID коммутаторам), Name Server (хранит информацию о подключенных устройствах, эдакий аналог WINS в пределах коммутатора) и т.д.
Для SAN ключевыми параметрами являются не только производительность, но и надёжность. Ведь если у сервера БД пропадёт сеть на пару секунд (или даже минут) — ну неприятно будет, но пережить можно. А если на это же время отвалится жёсткий диск с базой или с ОС, эффект будет куда более серьёзным. Поэтому все компоненты SAN обычно дублируются — порты в устройствах хранения и серверах, коммутаторы, линки между коммутаторами и, ключевая особенность SAN, по сравнению с LAN — дублирование на уровне всей инфраструктуры сетевых устройств — фабрики.
Фабрика (fabric — что вообще-то в переводе с английского ткань, т.к. термин символизирует переплетённую схему подключения сетевых и конечных устройств, но термин уже устоялся) — совокупность коммутаторов, соединённых между собой межкоммутаторными линками (ISL — InterSwitch Link).
Высоконадёжные SAN обязательно включают две (а иногда и более) фабрики, поскольку фабрика сама по себе — единая точка отказа. Те, кто хоть раз наблюдал последствия кольца в сети или ловкого движения клавиатуры, вводящего в кому коммутатор уровня ядра или распределения неудачной прошивкой или командой, понимают о чём речь.
Фабрики могут иметь идентичную (зеркальную) топологию или различаться. Например одна фабрика может состоять из четырёх коммутаторов, а другая — из одного, и к ней могут быть подключены только высококритичные узлы.
Топология
Различают следующие виды топологий фабрики:
Каскад — коммутаторы соединяются последовательно. Если их больше двух, то ненадёжно и непроизводительно.
Кольцо — замкнутый каскад. Надёжнее просто каскада, хотя при большом количестве участников (больше 4) производительность будет страдать. А единичный сбой ISL или одного из коммутаторов превращает схему в каскад со всеми вытекающими.
Сетка (mesh). Бывает Full Mesh — когда каждый коммутатор соединяется с каждым. Характерно высокой надёжностью, производительностью и ценой. Количество портов, требуемое под межкоммутаторные связи, с добавлением каждого нового коммутатора в схему растёт экспоненциально. При определённой конфигурации просто не останется портов под узлы — все будут заняты под ISL. Partial Mesh — любое хаотическое объединение коммутаторов.
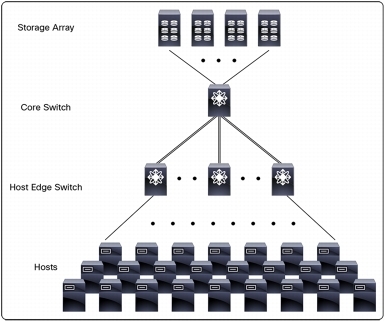
Центр/периферия (Core/Edge) — близкая к классической топологии LAN, но без уровня распределения. Нередко хранилища подключаются к Core-коммутаторам, а серверы — к Edge. Хотя для хранилищ может быть выделен дополнительный слой (tier) Edge-коммутаторов. Также и хранилища и серверы могут быть подключены в один коммутатор для повышения производительности и снижения времени отклика (это называется локализацией). Такая топология характеризуется хорошей масштабируемостью и управляемостью.
Зонинг (зонирование, zoning)
Ещё одна характерная для SAN технология. Это определение пар инициатор-таргет. То есть каким серверам к каким дисковым ресурсам можно иметь доступ, дабы не получилось, что все серверы видят все возможные диски. Достигается это следующим образом:
- выбранные пары добавляются в предварительно созданные на коммутаторе зоны (zones);
- зоны помещаются в наборы зон (zone set, zone config), созданные там же;
- наборы зон активируются в фабрике.
Для первоначального поста по теме SAN, думаю, достаточно. Прошу прощения за разномастные картинки — самому нарисовать на работе пока нет возможности, а дома некогда. Была мысль нарисовать на бумаге и сфотографировать, но решил, что лучше так.
Напоследок, в качестве постскриптума, перечислю базовые рекомендации по проектированию фабрики SAN.
- Проектировать структуру так, чтобы между двумя конечными устройствами было не более трёх коммутаторов.
- Желательно чтобы фабрика состояла не более чем из 31 коммутатора.
- Стоит задавать Domain ID вручную перед вводом нового коммутатора в фабрику — улучшает управляемость и помогает избежать проблем одинаковых Domain ID, в случаях, например, переподключения коммутатора из одной фабрики в другую.
- Иметь несколько равноценных маршрутов между каждым устройством хранения и инициатором.
- В случаях неопределённых требований к производительности исходить из соотношения количества Nx-портов (для конечных устройств) к количеству ISL-портов как 6:1 (рекомендация EMC) или 7:1 (рекомендация Brocade). Данное соотношение называется переподпиской (oversubscription).
- Рекомендации по зонингу:
— использовать информативные имена зон и зон-сетов;
— использовать WWPN-зонинг, а не Port-based (основанный на адресах устройств, а не физических портов конкретного коммутатора);
— каждая зона — один инициатор;
— чистить фабрику от «мёртвых» зон. - Иметь резерв свободных портов и кабелей.
- Иметь резерв оборудования (коммутаторы). На уровне сайта — обязательно, возможно на уровне фабрики.







