В одной из наших статей мы рассказывали о том, как можно использовать функции входящей почты в SharePoint 2010 для приема и обработки документов, содержащих отсканированные талоны. При выполнении этого проекта нам пришлось решить несколько интересных задач. И сейчас мы хотим подробнее остановиться на одном моменте.

Итак, одна из задач сводилась к распознаванию номеров на листе скана талонов. Стоит обратить внимание, что талонов может быть несколько, и располагаться на листе они могут как вертикально, так и горизонтально.
То, что мы увидели на сканах талонов, сильно напоминало штрих-код Codabar, с которым нам уже приходилось сталкиваться на других проектах.

Codabar – это линейный штрих-код. Каждый символ кодируется 7 элементами: 4 линиями и 3 пробелами между ними. Между собой символы разделяются дополнительным пространством. Начинается Codabar со стартового символа, и заканчивается стоповым. Стартовыми или стоповыми символами служат, как правило, символы ABCD. Информативными: 0-9, -, $.
Таким образом, для данного штрих-кода существует алфавит, где каждому символу соответствует определённая последовательность линий и пробелов.
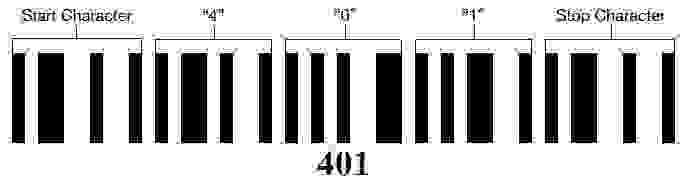
На картине показан пример Codabar’a, содержащий значение «401».
При работе со штрих-кодами в .NET мы используем портированную версию библиотеки Zxing. Библиотека умеет генерировать и распознавать всевозможные 1D и 2D баркоды: QR-Code, PDF 417, EAN, UPC, Aztec, Data Matrix. И главное, она умеет работать с Codabar. Применение библиотеки Zxing обычно не вызывает проблем, мы использовали ее на разных платформах. Но наш штрих-код Zxing сходу распознать не удалось. Всё оказалось не так просто… При внимательном изучении оказалось, что коды заказчика хоть и очень похожи на Codabar, но всё же отличаются, а именно:
Возможно, этот формат тоже «стандартен», хотя мы не нашли его детального описания и информации о нём. Возможно, существуют реализации библиотек для автоматизации распознавания этого кода, но нам не посчастливилось их найти… В итоге, было решено попытаться продолжить работу с Zxing, и сделать следующее: взять исходники кода и изменить алгоритм распознавания под собственные нужды.
В Zxing у каждого класса, реализующего логику распознавания конкретного кода (например, CodabarReader.cs), есть своя реализация абстрактного метода decodeRow, объявленного в классе OneDReader.cs.
На вход подаётся номер строки изображения и собственно массив, содержащий значения пикселей строки (тёмный — светлый).
Далее при помощи метода setCounters(BitArray row) инициируется массив int[] counters по следующему алгоритму: начиная с темного пикселя первый элемент массива начинает инкрементироваться, пока в массиве row не встретится белый пиксель. После этого происходит переход ко второму элементу массива counters, и он тоже инкрементируется, пока не появится черный пиксель. И так до конца строки. В итоге массив counters будет иметь например следующий вид:
15 7 10 3 4 8 16…
т.е.: 15 чёрных пикселей, 7 белых, 10 чёрных, 3 белых и т.д. (первый элемент в данной реализации соответствует черным пикселям).
Далее ищем последовательность, соответствующую стартовому символу (в нашем случае это символ «А», в оригинальном Codabar – один из символов «A», «B», «C» или «D»). Ищем с помощью метода findStartPattern(out int charOffset, int globalOffset). Пока непоследовательность не найдена, увеличиваем значение globalOffset (определяет текущее положение в строке изображения) и переходим к следующему символу массива counters. В методе findStartPattern вызывается метод:
Он принимает номер текущего элемента массива counters и длину символа (3 – для стартового или стопового символа; 9 – для остальных символов). Возвращает -1 если символ не найден. Если символ найден – возвращает эту позицию в массиве CHARACTER_ENCODINGS.
Алфавит кода определяется следующими полями:
Немного слов о значениях, хранящихся в массиве CHARACTER_ENCODINGS и вообще о том, как кодируется Codabar. Например, цифра «0» кодируется следующей последовательностью полосок и пробелов:

Записывается это следующим образом: 101010011 (barcode encoding). Одиночный 0/1 кодирует короткий пробел/полосу, сдвоенный 00/11 кодирует длинный пробел/полосу. Далее эта последовательность преобразуется в код 0000011 (width encoding), или в шестнадцатеричном виде: 0х03. Т.е. одиночные символы записываются нулём, сдвоенные – единицей. В нашем случае каждый символ кодируется не 7, а 9 символами, но логика создания цифрового кода та же.
Нам пришлось потратить некоторое время на изучение примеров талонов. Мы внимательно вглядывались в штрих-коды и выписывали последовательности, которые соответствуют тому или иному символу. В результате получился наш собственный алфавит:
Итак, процесс обработки кода выглядит следующим образом: как только находим стартовый символ – ищем информационные, используя всё тот же метод toNarrowWidePattern. Длина последовательности фиксированная, т.е. на определённом шаге нам надо проверить, не является ли символ стоповым. Если да – формируем результат и переходим к следующему элементу массива counters, продолжая поиск штрих-кодов в строке.
В итоге, просканировав строку, имеем (или не имеем) один и более кодов, которые сохраняем в глобальный массив результатов. И переходим к следующей строке изображения.
Также была добавлена возможность включать поворот изображения по часовой стрелке на 90 градусов, если необходимо проверить документ на наличие кодов во всех четырёх положениях. В библиотеке Zxing изображение, которое необходимо обработать, содержится в классе BinaryBitmap, который имеет метод rotateCounterClockwise(). Повернуть изображение не составляет труда.
Таким образом, немного подумав и потрудившись, мы смогли доработать библиотеку под новый формат кода. Кому интересно, код можно найти тут
Итак, у нас получилось распознавать один или несколько кодов на странице. Но на этом наши проблемы не закончились. Так как по условиям у нас может быть несколько кодов плюс необходимо сканировать 4 различных положения листа, алгоритм стал существенно «тормозить». Пришлось покопаться ещё, в результате чего обнаружилась следующая особенность:
Zxing на основании изображения создаёт экземпляр класса RGBLuminanceSource. В нём имеется массив байт, содержащий информацию о яркости каждого пиксела исходного изображения. Затем, на основании этой информации и порогового значения получается битовый массив.
Вот пример части кода конструктора класса RGBLuminanceSource:
То есть в циклах используется медленная bitmap.GetPixel(x, y) для каждого пикселя изображения! Для небольших изображений с разрешением 200х300 пикселей (или близких к тому) такой подход вполне уместен и не вызывает задержек (учитывая, что распознаётся как правило только один код). Но в нашем случае изображение имеет высокое разрешение (до 3000 х 5000 пикселей), что еще и следует умножить на количество вариантов ориентации, и умножить на обработку множества страниц. Все это приводит к неприемлемым задержкам. Например, для одной страницы вышеуказанного разрешения объект класса RGBLuminanceSource создавался секунд за 8. Это, конечно, очень долго.
Пришлось дополнительно модифицировать этот код, забыть про GetPixel и перейти на работу по сканлиниям.
Этот шаг значительно ускорил алгоритм и позволил получить приемлемое время обработки.
Как уже было сказано выше, сканы купонов могут поступать как в виде файлов изображений, так и в PDF документе. Для превращения страниц pdf в изображения мы воспользовались библиотекой itextsharp.
Основной класс для работы с этой библиотекой — PdfReader. Экземпляр данного класса можно получить, например, следующим образом:
Кусочки кода ищите под спойлером.
Так получилось, что сейчас в мире существует множество разновидностей баркодов. Распознавание и генерация большинства из них реализована в библиотеках, доступных для разработчиков. Тем не менее, иногда можно наткнуться на оригинальный тип баркода, распознать который сходу не получится.
И тогда метод тщательного всматривания и использования хорошо спроектированной библиотеки с открытым исходным кодом помогает быстро получить результат.

Итак, одна из задач сводилась к распознаванию номеров на листе скана талонов. Стоит обратить внимание, что талонов может быть несколько, и располагаться на листе они могут как вертикально, так и горизонтально.
То, что мы увидели на сканах талонов, сильно напоминало штрих-код Codabar, с которым нам уже приходилось сталкиваться на других проектах.

Codabar – это линейный штрих-код. Каждый символ кодируется 7 элементами: 4 линиями и 3 пробелами между ними. Между собой символы разделяются дополнительным пространством. Начинается Codabar со стартового символа, и заканчивается стоповым. Стартовыми или стоповыми символами служат, как правило, символы ABCD. Информативными: 0-9, -, $.
Таким образом, для данного штрих-кода существует алфавит, где каждому символу соответствует определённая последовательность линий и пробелов.

На картине показан пример Codabar’a, содержащий значение «401».
ZXing
При работе со штрих-кодами в .NET мы используем портированную версию библиотеки Zxing. Библиотека умеет генерировать и распознавать всевозможные 1D и 2D баркоды: QR-Code, PDF 417, EAN, UPC, Aztec, Data Matrix. И главное, она умеет работать с Codabar. Применение библиотеки Zxing обычно не вызывает проблем, мы использовали ее на разных платформах. Но наш штрих-код Zxing сходу распознать не удалось. Всё оказалось не так просто… При внимательном изучении оказалось, что коды заказчика хоть и очень похожи на Codabar, но всё же отличаются, а именно:
- имеют другие стартовые и стоповые символы;
- каждый информативный символ состоит не из стандартных 7 элементов (4 линии и 3 пробела), а из 9 (5 линий, 4 пробела);
- стартовый и стоповый символы также состоят не из 7 элементов, а из 3 (2 линии, 1 пробел).
Возможно, этот формат тоже «стандартен», хотя мы не нашли его детального описания и информации о нём. Возможно, существуют реализации библиотек для автоматизации распознавания этого кода, но нам не посчастливилось их найти… В итоге, было решено попытаться продолжить работу с Zxing, и сделать следующее: взять исходники кода и изменить алгоритм распознавания под собственные нужды.
Алгоритм
В Zxing у каждого класса, реализующего логику распознавания конкретного кода (например, CodabarReader.cs), есть своя реализация абстрактного метода decodeRow, объявленного в классе OneDReader.cs.
override public List<Result> decodeRow(int rowNumber, BitArray row, Hashtable hints)
На вход подаётся номер строки изображения и собственно массив, содержащий значения пикселей строки (тёмный — светлый).
Далее при помощи метода setCounters(BitArray row) инициируется массив int[] counters по следующему алгоритму: начиная с темного пикселя первый элемент массива начинает инкрементироваться, пока в массиве row не встретится белый пиксель. После этого происходит переход ко второму элементу массива counters, и он тоже инкрементируется, пока не появится черный пиксель. И так до конца строки. В итоге массив counters будет иметь например следующий вид:
15 7 10 3 4 8 16…
т.е.: 15 чёрных пикселей, 7 белых, 10 чёрных, 3 белых и т.д. (первый элемент в данной реализации соответствует черным пикселям).
Далее ищем последовательность, соответствующую стартовому символу (в нашем случае это символ «А», в оригинальном Codabar – один из символов «A», «B», «C» или «D»). Ищем с помощью метода findStartPattern(out int charOffset, int globalOffset). Пока непоследовательность не найдена, увеличиваем значение globalOffset (определяет текущее положение в строке изображения) и переходим к следующему символу массива counters. В методе findStartPattern вызывается метод:
int toNarrowWidePattern(int position, int offset)
Он принимает номер текущего элемента массива counters и длину символа (3 – для стартового или стопового символа; 9 – для остальных символов). Возвращает -1 если символ не найден. Если символ найден – возвращает эту позицию в массиве CHARACTER_ENCODINGS.
Алфавит
Алфавит кода определяется следующими полями:
- char[] ALPHABET_STRING – содержит все символы, используемые в коде.
- int[] CHARACTER_ENCODINGS – содержит цифру, определяющую кодовую последовательность, характерную для каждого символа кода.
Немного слов о значениях, хранящихся в массиве CHARACTER_ENCODINGS и вообще о том, как кодируется Codabar. Например, цифра «0» кодируется следующей последовательностью полосок и пробелов:

Записывается это следующим образом: 101010011 (barcode encoding). Одиночный 0/1 кодирует короткий пробел/полосу, сдвоенный 00/11 кодирует длинный пробел/полосу. Далее эта последовательность преобразуется в код 0000011 (width encoding), или в шестнадцатеричном виде: 0х03. Т.е. одиночные символы записываются нулём, сдвоенные – единицей. В нашем случае каждый символ кодируется не 7, а 9 символами, но логика создания цифрового кода та же.
Нам пришлось потратить некоторое время на изучение примеров талонов. Мы внимательно вглядывались в штрих-коды и выписывали последовательности, которые соответствуют тому или иному символу. В результате получился наш собственный алфавит:
private const String ALPHABET_STRING = "0123456789AE";
static int[] CHARACTER_ENCODINGS = {
0x014, 0x101, 0x041, 0x140, 0x011, 0x110, 0x050, 0x005, 0x104, 0x044, // 0-9
0x000, 0x004, // AE};
Итак, процесс обработки кода выглядит следующим образом: как только находим стартовый символ – ищем информационные, используя всё тот же метод toNarrowWidePattern. Длина последовательности фиксированная, т.е. на определённом шаге нам надо проверить, не является ли символ стоповым. Если да – формируем результат и переходим к следующему элементу массива counters, продолжая поиск штрих-кодов в строке.
В итоге, просканировав строку, имеем (или не имеем) один и более кодов, которые сохраняем в глобальный массив результатов. И переходим к следующей строке изображения.
Также была добавлена возможность включать поворот изображения по часовой стрелке на 90 градусов, если необходимо проверить документ на наличие кодов во всех четырёх положениях. В библиотеке Zxing изображение, которое необходимо обработать, содержится в классе BinaryBitmap, который имеет метод rotateCounterClockwise(). Повернуть изображение не составляет труда.
Таким образом, немного подумав и потрудившись, мы смогли доработать библиотеку под новый формат кода. Кому интересно, код можно найти тут
Скрытый текст
using System;
using System.Collections;
using System.Collections.Generic;
using System.Text;
using BitArray = ETR.REBT.BarcodeReader.common.BitArray;
namespace ETR.REBT.BarcodeReader.oned
{
public sealed class MyCodeReader : OneDReader
{
// These values are critical for determining how permissive the decoding
// will be. All stripe sizes must be within the window these define, as
// compared to the average stripe size.
private static readonly int MAX_ACCEPTABLE = (int)(PATTERN_MATCH_RESULT_SCALE_FACTOR * 2.0f);
private static readonly int PADDING = (int)(PATTERN_MATCH_RESULT_SCALE_FACTOR * 1.5f);
private static readonly int STARTEND_LENGTH = 3;
private static readonly int SYMBOL_LENGTH = 9;
private static readonly int DATA_LENGTH = 15; // 15 symbols + 2 start/stop symbols
private static readonly int All_LENGHT = (16 + DATA_LENGTH * SYMBOL_LENGTH + 2 * STARTEND_LENGTH);
private const String ALPHABET_STRING = "0123456789AE";
internal static readonly char[] ALPHABET = ALPHABET_STRING.ToCharArray();
/**
* These represent the encodings of characters, as patterns of wide and narrow bars. The 7 least-significant bits of
* each int correspond to the pattern of wide and narrow, with 1s representing "wide" and 0s representing narrow.
*/
internal static int[] CHARACTER_ENCODINGS = {
0x014, 0x101, 0x041, 0x140, 0x011, 0x110, 0x050, 0x005, 0x104, 0x044, // 0-9
0x000, 0x004, // AE
};
// minimal number of characters that should be present (inclusing start and stop characters)
// under normal circumstances this should be set to 3, but can be set higher
// as a last-ditch attempt to reduce false positives.
private const int MIN_CHARACTER_LENGTH = 3;
// Start and end patterns
private static readonly char[] START_ENCODING = { 'A' };
private static readonly char[] END_ENCODING = { 'E' };
private static readonly char[] DATA_ENCODING = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9' };
// some codabar generator allow the codabar string to be closed by every
// character. This will cause lots of false positives!
// some industries use a checksum standard but this is not part of the original codabar standard
// for more information see : http://www.mecsw.com/specs/codabar.html
// Keep some instance variables to avoid reallocations
private readonly StringBuilder decodeRowResult;
private int[] counters;
private int counterLength;
public MyCodeReader()
{
decodeRowResult = new StringBuilder(40);
counters = new int[500];
counterLength = 0;
}
override public List<Result> decodeRow(int rowNumber, BitArray row, Hashtable hints)
{
List<Result> returnList = null;
if (!setCounters(row))
return null;
int globalOffset = 0;
while (globalOffset < counterLength)
{
int startSymbolPos = -1;
int startOffset = findStartPattern(out startSymbolPos, globalOffset);
if (startOffset < 0)
return returnList; // we can't find start char in the whole row -> so, exit
decodeRowResult.Length = 0;
decodeRowResult.Append((char)startSymbolPos);
int nextStart = startOffset;
nextStart += (STARTEND_LENGTH + 1/*space between symbols*/);
bool findNextStart = false;
do
{
int charOffset = toNarrowWidePattern(nextStart, SYMBOL_LENGTH);
if (charOffset == -1 || !arrayContains(DATA_ENCODING, ALPHABET[charOffset]))
{
findNextStart = true;
break;
}
decodeRowResult.Append((char)charOffset);
nextStart += (SYMBOL_LENGTH + 1);
// Stop as soon as length of data symbols equals to corresponding number
if (decodeRowResult.Length == DATA_LENGTH + 1/*start symbol*/)
{
int endOffset = toNarrowWidePattern(nextStart, STARTEND_LENGTH);
if (endOffset == -1 || !arrayContains(END_ENCODING, ALPHABET[endOffset]))
{
findNextStart = true;
break;
}
globalOffset = nextStart + STARTEND_LENGTH;
decodeRowResult.Append((char)endOffset);
break;
}
} while (nextStart < counterLength); // no fixed end pattern so keep on reading while data is available
if (findNextStart)
{
globalOffset = ++startOffset;
continue;
}
if (!validatePattern())
{
globalOffset = ++startOffset;
continue;
}
// remove stop/start characters character
decodeRowResult.Remove(decodeRowResult.Length - 1, 1);
decodeRowResult.Remove(0, 1);
int runningCount = 0;
for (int i = 0; i < startOffset; i++)
{
runningCount += counters[i];
}
float left = (float)runningCount;
for (int i = startOffset; i < nextStart - 1; i++)
{
runningCount += counters[i];
}
float right = (float)runningCount;
Result result = new Result(
decodeRowResult.ToString(),
null,
new ResultPoint[]
{
new ResultPoint(left, (float) rowNumber),
new ResultPoint(right, (float) rowNumber)
},
BarcodeFormat.CODABAR);
if (returnList == null)
returnList = new List<Result>();
returnList.Add(result);
}
return returnList;
}
private bool validatePattern()
{
if (decodeRowResult.Length != DATA_LENGTH + 2)
{
return false;
}
// Translate character table offsets to actual characters.
for (int i = 0; i < decodeRowResult.Length; i++)
{
decodeRowResult[i] = ALPHABET[decodeRowResult[i]];
}
// Ensure a valid start character
char startchar = decodeRowResult[0];
if (!arrayContains(START_ENCODING, startchar))
{
return false;
}
// Ensure a valid end character
char endchar = decodeRowResult[decodeRowResult.Length - 1];
if (!arrayContains(END_ENCODING, endchar))
{
return false;
}
// Ensure a valid data symbols
for (int i = 1; i < decodeRowResult.Length - 1; i++)
{
if (!arrayContains(DATA_ENCODING, decodeRowResult[i]))
{
return false;
}
}
return true;
}
/// <summary>
/// Records the size of all runs of white and black pixels, starting with white.
/// This is just like recordPattern, except it records all the counters, and
/// uses our builtin "counters" member for storage.
/// </summary>
/// <param name="row">row to count from</param>
private bool setCounters(BitArray row)
{
counterLength = 0;
// Start from the first white bit.
int i = row.getNextUnset(0);
int end = row.Size;
if (i >= end)
{
return false;
}
bool isWhite = true;
int count = 0;
for (; i < end; i++)
{
if (row[i] ^ isWhite)
{
// that is, exactly one is true
count++;
}
else
{
counterAppend(count);
count = 1;
isWhite = !isWhite;
}
}
counterAppend(count);
return true;
}
private void counterAppend(int e)
{
counters[counterLength] = e;
counterLength++;
if (counterLength >= counters.Length)
{
int[] temp = new int[counterLength * 2];
Array.Copy(counters, 0, temp, 0, counterLength);
counters = temp;
}
}
private int findStartPattern(out int charOffset, int globalOffset)
{
charOffset = -1;
//
// Assume that first (i = 0) set of pixels is white,
// so we start find symbols from second set (i = 1).
// And next we step over white set ('i += 2').
//
for (int i = 1 + globalOffset; i < counterLength; i += 2)
{
if (counters[i - 1] < counters[i] * 5) // before start char must be a long space
continue;
charOffset = toNarrowWidePattern(i, 3);
if (charOffset != -1 && arrayContains(START_ENCODING, ALPHABET[charOffset]))
{
return i;
}
}
return -1;
}
internal static bool arrayContains(char[] array, char key)
{
if (array != null)
{
foreach (char c in array)
{
if (c == key)
{
return true;
}
}
}
return false;
}
// Assumes that counters[position] is a bar.
private int toNarrowWidePattern(int position, int offset)
{
int end = position + offset;
if (end >= counterLength)
return -1;
// First element is for bars, second is for spaces.
int[] maxes = { 0, 0 };
int[] mins = { Int32.MaxValue, Int32.MaxValue };
int[] thresholds = { 0, 0 };
for (int i = 0; i < 2; i++)
{
for (int j = position + i; j < end; j += 2)
{
if (counters[j] < mins[i])
{
mins[i] = counters[j];
}
if (counters[j] > maxes[i])
{
maxes[i] = counters[j];
}
}
double tr = ((double)mins[i] + (double)maxes[i]) / 2;
thresholds[i] = (int)Math.Ceiling(tr);
}
// There are no big spaces in the barcode -> only small spaces
thresholds[1] = Int32.MaxValue;
// For start and end symbols defined empirically threshold equals to 5
if (offset == STARTEND_LENGTH)
thresholds[0] = 5;
int bitmask = 1 << offset;
int pattern = 0;
for (int i = 0; i < offset; i++)
{
int barOrSpace = i & 1;
bitmask >>= 1;
if (counters[position + i] >= thresholds[barOrSpace])
{
pattern |= bitmask;
}
}
for (int i = 0; i < CHARACTER_ENCODINGS.Length; i++)
{
if (CHARACTER_ENCODINGS[i] == pattern)
{
return i;
}
}
return -1;
}
}
}
«Оптимизация» Zxing
Итак, у нас получилось распознавать один или несколько кодов на странице. Но на этом наши проблемы не закончились. Так как по условиям у нас может быть несколько кодов плюс необходимо сканировать 4 различных положения листа, алгоритм стал существенно «тормозить». Пришлось покопаться ещё, в результате чего обнаружилась следующая особенность:
Zxing на основании изображения создаёт экземпляр класса RGBLuminanceSource. В нём имеется массив байт, содержащий информацию о яркости каждого пиксела исходного изображения. Затем, на основании этой информации и порогового значения получается битовый массив.
Вот пример части кода конструктора класса RGBLuminanceSource:
Color c;
for (int y = 0; y < height; y++)
{
int offset = y * width;
for (int x = 0; x < width; x++)
{
c = bitmap.GetPixel(x, y);
var r = ColorUtility.GetRValue(c);
var g = ColorUtility.GetGValue(c);
var b = ColorUtility.GetBValue(c);
luminances[offset + x] = (byte)(0.3 * r + 0.59 * g + 0.11 * b + 0.01);
}
}
То есть в циклах используется медленная bitmap.GetPixel(x, y) для каждого пикселя изображения! Для небольших изображений с разрешением 200х300 пикселей (или близких к тому) такой подход вполне уместен и не вызывает задержек (учитывая, что распознаётся как правило только один код). Но в нашем случае изображение имеет высокое разрешение (до 3000 х 5000 пикселей), что еще и следует умножить на количество вариантов ориентации, и умножить на обработку множества страниц. Все это приводит к неприемлемым задержкам. Например, для одной страницы вышеуказанного разрешения объект класса RGBLuminanceSource создавался секунд за 8. Это, конечно, очень долго.
Пришлось дополнительно модифицировать этот код, забыть про GetPixel и перейти на работу по сканлиниям.
bmp = bitmap.LockBits(new Rectangle(0, 0, width, height), ImageLockMode.ReadOnly, bitmap.PixelFormat);
for (var y = 0; y < bmp.Height; y++)
{
var row = (byte*)bmp.Scan0 + (y * bmp.Stride);
int offset = y * width;
for (var x = 0; x < bmp.Width; x++)
{
var b = row[(x * pixelSize)];
var g = row[(x * pixelSize) + 1];
var r = row[(x * pixelSize) + 2];
luminances[offset + x] = (byte)(0.3 * r + 0.59 * g + 0.11 * b + 0.01);
}
}
Этот шаг значительно ускорил алгоритм и позволил получить приемлемое время обработки.
Работа с PDF
Как уже было сказано выше, сканы купонов могут поступать как в виде файлов изображений, так и в PDF документе. Для превращения страниц pdf в изображения мы воспользовались библиотекой itextsharp.
Основной класс для работы с этой библиотекой — PdfReader. Экземпляр данного класса можно получить, например, следующим образом:
Кусочки кода ищите под спойлером.
Скрытый текст
После этого можно использовать его в коде:
С помощью этой функции ищем изображения на странице PDF документа
Получаем объект типа Bitmap из объекта класса ImageRenderInfo
В методе ImageDecoder.Decode реализуется логика нахождения кода в картинке.
var reader = new PdfReader(filePath)
После этого можно использовать его в коде:
for (var pageNumber = 1; pageNumber <= reader.NumberOfPages; pageNumber++)
{
var page = reader.GetPageN(pageNumber);
List<ImageRenderInfo> images;
try
{
images = FindImageInPDFDictionary(page);
}
catch (Exception)
{
// Переходим к следующей странице PDF документа
continue;
}
finally
{
reader.ReleasePage(pageNumber);
}
foreach (var img in images)
{
var image = RenderImage(img);
var result = ImageDecoder.Decode(image, allRotations);
if (result != null && result.Count > 0)
{
// Страница распозналась, можно использовать результат сканирования
}
}
}
С помощью этой функции ищем изображения на странице PDF документа
private static List<ImageRenderInfo> FindImageInPDFDictionary(PdfDictionary pg)
{
var result = new List<ImageRenderInfo>();
var res = (PdfDictionary)PdfReader.GetPdfObject(pg.Get(PdfName.RESOURCES));
var xobj = (PdfDictionary)PdfReader.GetPdfObject(res.Get(PdfName.XOBJECT));
if (xobj == null) return null;
foreach (var name in xobj.Keys)
{
var obj = xobj.Get(name);
if (!obj.IsIndirect()) continue;
var tg = (PdfDictionary)PdfReader.GetPdfObject(obj);
var type = (PdfName)PdfReader.GetPdfObject(tg.Get(PdfName.SUBTYPE));
if (PdfName.IMAGE.Equals(type))
{
var width = float.Parse(tg.Get(PdfName.WIDTH).ToString());
var height = float.Parse(tg.Get(PdfName.HEIGHT).ToString());
if (width > ImageDecoder.MinimalSideResolution || height >= ImageDecoder.MinimalSideResolution)
{
var imgRi = ImageRenderInfo.CreateForXObject(new Matrix(width, height), (PRIndirectReference)obj, tg);
result.Add(imgRi);
}
}
if (PdfName.FORM.Equals(type))
{
result.AddRange(FindImageInPDFDictionary(tg));
}
if (PdfName.GROUP.Equals(type))
{
result.AddRange(FindImageInPDFDictionary(tg));
}
}
return result;
}
Получаем объект типа Bitmap из объекта класса ImageRenderInfo
private static Bitmap RenderImage(ImageRenderInfo renderInfo)
{
try
{
var image = renderInfo.GetImage();
using (var dotnetImg = image.GetDrawingImage())
{
if (dotnetImg != null)
{
using (var ms = new MemoryStream())
{
dotnetImg.Save(ms, ImageFormat.Png);
return new Bitmap(dotnetImg);
}
}
}
}
catch (Exception)
{
}
return null;
}
В методе ImageDecoder.Decode реализуется логика нахождения кода в картинке.
Так получилось, что сейчас в мире существует множество разновидностей баркодов. Распознавание и генерация большинства из них реализована в библиотеках, доступных для разработчиков. Тем не менее, иногда можно наткнуться на оригинальный тип баркода, распознать который сходу не получится.
И тогда метод тщательного всматривания и использования хорошо спроектированной библиотеки с открытым исходным кодом помогает быстро получить результат.
