Вступление
Существует множество игр, где игроку необходимо искать слова из определенного набора букв. Вот две наиболее популярные из них.
1. 4 фото 1 слов (4 Pics 1 Word) AppStore, Google Play
У этой игры довольно много реализаций, но идея у всех одна.
2. Словомания (Wordsmania) AppStore, Google Play
Суть первой игры: даны 4 картинки, длина угадываемого слова и набор букв, выбирать буквы можно в любом порядке.

Суть второй сводится к тому, что на поле 4х4, заполненном буквами, необходимо найти как можно больше слов, из каждой клетки можно передвигаться в следующую по вертикали, горизонтали и диагоналям.

Меня заинтересовала идея по программному решению задач, которые ставят эти игры. Я не ставлю цели сделать игру нечестной, это скорее чисто спортивный интерес к поставленной самому себе задаче. Пик популярности этих игр уже прошёл, поэтому не так страшно, если кто-то немного поиграет нечестно.
Постановка задачи
Если рассматривать задачу более формально, то необходимо реализовать перебор возможных комбинаций, исходя из правил игры. Будет реализовано два алгоритма перебора для каждой игры. Далее необходимо проверять наличие этих комбинаций в словаре, для этого нужно реализовать структуру, которая сможет эффективно отвечать на запрос о наличии слова в словаре. Будет использоваться бор.
Почему бор
В стандартных библиотеках C++ уже реализованы структуры, которые умеют быстро отвечать на единичные запросы, это map и unordered_map (hash map). Но реализация задачи с помощью этих структур будет уступать по асимптотике бору, так как в нём будут учитываться особенности поставленной задачи. Перебор значений будет представлять из себя дерево, так как рекурсивно из каждой буквы будет пытаться найти следующую. Бор — тоже дерево, поэтому поиск слов будет проходить в худшем случае за суммарную длину всех найденных слов, плюс то количество итераций, пока алгоритм не дойдёт до несуществующего перехода в словаре, на практике такой переход достигается довольно быстро. Эффективнее алгоритм будет работать, когда есть строка S, содержащая в себе в качестве префикса строку P, принадлежащую словарю, в таком случае поиск будет проходить за длину S, а все остальные P добавятся в ответ по ходу поиска S.
Далее необходимо вывести полученные слова в отсортированном виде.
Реализация
Рассмотрим реализацию решения задачи по частям.
Включения
Необходимо обеспечить консольный и файловый ввод-вывод, iostream, fstream. Нужны стандартные шаблоны STL: vector — для построения бора, string и set — для хранения результатов и отсечения одинаковых найденных слов, algorithm для сортировки.
Включения
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <set>
#include <algorithm>
Объявления
Для того, чтобы использовать русские символы, без включения локализации, чтобы такой код можно было легко подогнать под другие кодировки, решено использовать простой образец строки для ввода и вывода. Это образец, получаемый при вводе в консоль русского алфавита ConsoleSample и образец, получаемый при чтении из файла FstreamSample.
Далее идёт описание структуры для каждой вершины бора, она будет хранить переходы по каждой букве, либо 0, если перехода нет, также с помощью переменной isLeaf в структуре указывается, что в данной вершине оканчивается какое-либо слово.
Объявляем контейнеры для хранения бора, буфера для результатов и отформатированного вывода.
Объявления
#define ALPHABET_SIZE 33
const char ConsoleSample[ALPHABET_SIZE] = { -96, -95, -94, -93, -92, -91, -15, -90, -89, -88, -87, -86, -85, -84, -83, -82, -81, -32, -31, -30, -29, -28, -27, -26, -25, -24, -23, -20, -21, -22, -19, -18, -17 };
const char FstreamSample[ALPHABET_SIZE] = { -32, -31, -30, -29, -28, -27, -72, -26, -25, -24, -23, -22, -21, -20, -19, -18, -17, -16, -15, -14, -13, -12, -11, -10, -9, -8, -7, -4, -5, -6, -3, -2, -1 };
typedef struct {
unsigned child[ALPHABET_SIZE];
bool isLeaf;
} node;
node NullNode = {NULL};
vector<node> Trie;
set<string> Res;
vector<string> Output;
Добавление слов в бор
Функция получает на вход строку, проходится по ней, одновременно продвигается по бору, если из вершины нет перехода, в бор добавляется новая вершина, а в текущую вершину записывается переход на добавленную вершину с помощью индекса. После добавления последнего перехода, значение переменной isLeaf у последней вершины меняется на true, здесь слово заканчивается.
Добавление слов
void TrieAddWord(string &S) {
unsigned CurrentNode(0);
for (auto i(S.begin()); i != S.end(); ++i) {
if (Trie[CurrentNode].child[*i] == 0) {
Trie.push_back(NullNode);
Trie[CurrentNode].child[*i] = Trie.size() - 1;
CurrentNode = Trie.size() - 1;
}
else {
CurrentNode = Trie[CurrentNode].child[*i];
}
}
Trie[CurrentNode].isLeaf = true;
}
Загрузка словаря
Для удобства, у всех слов на время обработки запроса номера символов будут сдвинуты, то есть символу 'а' будет соответствовать значение 0, а символу 'я', значение 32. Функция Encode будет производить это с помощью тривиального поиска символа в образце и заменять его. Такая реализация проста, но требует лишнего времени для подгрузки словаря, но это не так важно, словарь подгружается единоразово, а потом уже можно подавать запросы программе многократно.
Кодирование строки
void EncodeString(string &S, const char Sample[]) {
for (auto i(S.begin()); i != S.end(); ++i) {
for (char j(0); j != ALPHABET_SIZE; ++j) {
if (*i == Sample[j]) {
*i = j;
break;
}
}
}
}
Функция загрузки словаря получает имя файла и считывает все слова из него, кодируя строки и далее добавляет их в бор. Функция может загрузить сразу несколько словарей, если запустить её для всех файлов.
Загрузка словаря
void LoadDictonary(char *Filename) {
ifstream in(Filename);
string Buff;
while (!in.eof()) {
in >> Buff;
EncodeString(Buff, FstreamSample);
TrieAddWord(Buff);
}
in.close();
}
Сортировка вывода
Для получения в первую очередь самых длинных слов в игре Словомания, необходимо отсортировать строки по длинам в обратном порядке, так как при выводе в консоль, текст пролистывается снизу вверх, поэтому самые длинные слова нужно вывести в конце. В игре чем больше слово, тем, очевидно, за него дают больше очков. Для этого надо написать простейшую функцию-компаратор для передачи её sort из algorithm.
Компаратор
bool cmp(string A, string B) {
if (A.size() >= B.size()) {
return false;
}
else return true;
}
Реализация решения для игры «угадай слово»
Так как реализаций и названий этой игры много, то назовем её просто «угадай слово».
Для начала функция обхода по бору. Здесь используется обычный рекурсивный алгоритм DFS, просто из каждой буквы, мы переходим в любую не использованную ранее из заданой строки, одновременно с этим, мы проверяем наличие такого перехода в боре, если переход существует, то продолжаем дальше, если нет, то прекращаем дальнейшее продвижение по данной ветке. Важно заметить, что в игре надо отгадать слово определенной длины, поэтому спускаемся только до глубины, равной длине строки, дальше спускаться смысла нет. Не забываем на каждой итерации проверить переменную isLeaf, если она равна true и длина найденного слова равна указанному значению, то добавляем слово в set Res.
Обход
void GuessWordBypass(unsigned N, __int8 X, bool Used[], string &S, string W, short &L) {
if (W.size() > L) return;
for (__int8 i(0); i != S.size(); ++i) {
if (i == X) continue;
if (!Used[i]) {
if (Trie[N].child[S[i]] != 0) {
Used[i] = true;
GuessWordBypass(Trie[N].child[S[i]], i, Used, S, W + S[i], L);
Used[i] = false;
}
}
if (Trie[N].isLeaf && W.size() == L) {
Res.insert(W);
}
}
}
И далее функция, реализующая начальный запуск обхода из всех букв слова.
Запуск
void GuessWord(string &S, short &L) {
bool *Used = new bool [S.size()];
memset(Used, 0, S.size());
for (__int8 i(0); i != S.size(); ++i) {
if (Trie[0].child[S[i]] != 0) {
Used[i] = true;
GuessWordBypass(Trie[0].child[S[i]], i, Used, S, S.substr(i, 1), L);
Used[i] = false;
}
}
delete [] Used;
}
Реализация решения для игры Словомания
В целом сам обход не будет ничем отличаться, но отличия будут в том, что тут можно перемещаться только в соседние клетки, а не в любые, также поиск должен находить слова любой длины. Так как поле размером 4х4 представленно одномерным массивом, то не очевидно как переходить в соседние клетки, рассмотрим как это реализовать.
Если клетка стоит не на границах поля, то с помощью добавления чисел от -5 до 5, исключая из них -2, 0 и 2.
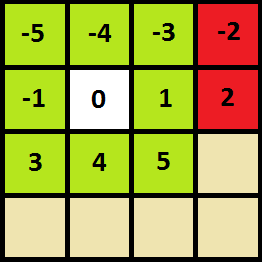
Если же клетка стоит на границе, то необходимо также запретить переходы в другие клетки, выходящие за границу.

Обход
void WordsmaniaCheatBypass(unsigned N, __int8 X, bool Used[], string &S, string W) {
__int8 TransitDenied[11] = {0};
for (__int8 i(-2); i <= 2; i += 2)
TransitDenied[i + 5] = true;
if (X % 4 == 0)
for (__int8 i(-5); i <= 3; i += 4)
TransitDenied[i + 5] = true;
if (X < 4)
for (__int8 i(-5); i <= -3; ++i)
TransitDenied[i + 5] = true;
if (X % 4 == 3)
for (__int8 i(-3); i <= 5; i += 4)
TransitDenied[i + 5] = true;
if (X >= 12)
for (__int8 i(3); i <= 5; ++i)
TransitDenied[i + 5] = true;
for (__int8 i(-5); i <= 5; ++i) {
if(TransitDenied[i + 5]) continue;
__int8 tmp = X + i;
if (!Used[tmp]) {
if (Trie[N].child[S[tmp]] != 0) {
Used[tmp] = true;
WordsmaniaCheatBypass(Trie[N].child[S[tmp]], tmp, Used, S, W + S[tmp]);
Used[tmp] = false;
}
}
if (Trie[N].isLeaf) {
Res.insert(W);
}
}
}
Запуск
void WordsmaniaCheat(string &S) {
bool Used[16] = {0};
for (__int8 i(0); i != 16; ++i) {
if (Trie[0].child[S[i]] != 0) {
Used[i] = true;
WordsmaniaCheatBypass(Trie[0].child[S[i]], i, Used, S, S.substr(i, 1));
Used[i] = false;
}
}
}
Функция main
В главной функции инициализируется бор и выполняется главный цикл, в котором обрабатываются запросы. '1' или '2' первым аргументом, в зависимости от того, какой алгоритм использовать, далее параметры для алгоритма. После обработки сортировка и вывод результатов. Для первого алгоритма надо ввести последовательность символов и далее длину слова, для второго только последовательность, она записывается по строчкам поля, то есть для такого поля надо ввести строку «сгщатрлпнжилеыйг» (без кавычек).
Main
int main() {
Trie.push_back(NullNode);
LoadDictonary("Dictonary.txt");
string Word;
char mode;
while (true) {
cin >> mode;
switch (mode) {
case '1':
short L;
cin >> Word >> L;
EncodeString(Word, ConsoleSample);
GuessWord(Word, L);
break;
case '2':
cin >> Word;
EncodeString(Word, ConsoleSample);
WordsmaniaCheat(Word);
break;
}
cout << "==================" << endl;
for (auto i(Res.begin()); i != Res.end(); ++i) {
Output.push_back(*i);
}
Res.clear();
if(mode == '2') sort(Output.begin(), Output.end(), cmp);
for (auto i(Output.begin()); i != Output.end(); ++i) {
for (auto j((*i).begin()); j != (*i).end(); ++j) {
cout << ConsoleSample[*j];
}
cout << endl;
}
cout << "==================" << endl << endl;
Output.clear();
}
return 0;
}
Что дальше
Вот полный код, он проверен под Windows, для других платформ, возможно, придётся заменить образцы ввода и вывода.
А вот словарь малый и большой словарь (не забудьте убрать в конце имени цифру 2, если будете использовать большой словарь). Большой словарь содержит не только начальные формы, он подойдёт для игры Wordament от Microsoft, но там не всегда на поле стоит по одной букве в клетке. В большинстве случаев хватает малого словаря для двух описанных игр, чтобы быть вверху турнирной таблицы.
Надеюсь, никто не будет много играть таким образом, все же большинство игроков продолжают играть честно.







