Продолжаем цикл статей, посвященных задаче изменения человеческого голоса, над решением которой мы работаем в компании i-Free. В предыдущей статье я попытался кратко рассказать о математическом аппарате, применяемом для описания сложных физических процессов, происходящих в речевом тракте человека при произнесении звуков. Были затронуты вопросы, связанные с моделированием акустики речевого тракта. Были описаны допустимые во многих случаях упрощения и аппроксимации. Итогом статьи было приведение физической модели распространения звука в речевом тракте к простому дискретному фильтру.
В данной статье хочется с одной стороны продолжить предыдущие начинания, а с другой — немного отойти от фундаментальной теории и поговорить о более практических (более «инженерных») вещах. Кратко будет рассмотрена одна из прикладных моделей, часто применяемая при работе с речевым сигналом. Математическая база этого подхода, как это часто бывает, изначально была заложена в рамках исследований совершенно другой направленности. Тем не менее физические особенности речевого сигнала позволили применить данные идеи именно для его эффективного анализа и модификации.
Предыдущая статья, в силу специфики рассматриваемого вопроса, была перенасыщена научными терминами и формулами. В данной — мы постараемся вместо детального описания математических построений сделать акцент на идеологическую концепцию и качественные характеристики описываемой модели.
Далее будет более подробно рассмотрена теория модели LPC (Linear Prediction Coding) – замечательный стройных подход к описанию речевого сигнала, в прошлом определивший направление развития речевых технологий на несколько десятилетий и до сих пор часто применяемый, как один из базовых инструментов при анализе и описании речевого сигнала.
Упрощенная дискретная модель речевого сигнала
В данном пункте мы сделаем переход от дискретной модели речевого тракта из прошлой статьи, (та модель описывала только распространение звука в трубах с постоянной площадью поперечного сечения), к более полной модели, описывающей весь артикуляционный процесс. Основная идея модели формулируется достаточно просто — представим себе, что анализируемый нами дискретный сигнал y(n)* является выходом линейного цифрового фильтра** h, через который проходит некоторый «возбуждающий» сигнал x(n):
_____________________________
* — здесь и далее мы будет говорить только о дискретных сигналах и переменную времени t будем заменять на индекс дискретного отсчета n
** — сразу приносим извинения за некоторые ссылки на англоязычные источники, но нередко в них требуемый вопрос раскрыт более полно и в одном месте, надеемся языковой барьер не будет большой преградой.
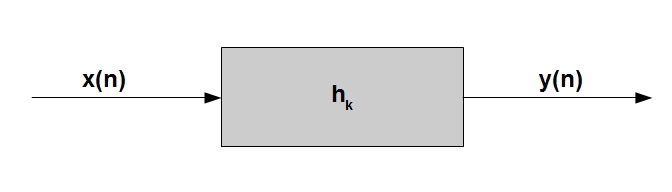
Логично предположить, что, изменяя коэффициенты фильтра h_k, а, возможно, в некоторых случаях сам «возбуждающий» сигнал, можно добиться другого звучания выходного звука*. На словах все весьма просто, но теперь попробуем разобраться, какое отношение эта совершенно абстрактная обобщенная идея может иметь к речевому сигналу.
_____________________________
* — как и в предыдущей статье, символом « _ » мы будем обозначать операцию индексирования, а символом « ^ » — операцию возведения в степень.
Кратко напомним, а заодно немного обобщим рассказанное в самой первой статье. Формирование звуков речи можно, с небольшими оговорками, описать следующим образом:
1) голосовая щель в гортани является «базовым» источником звука (здесь с участием голосовых связок порождается тот самый вокализованный или невокализованный сигнала возбуждения из 1-й статьи)
2) органы речевого тракта выше гортани являются одним сложным акустическим фильтром, усиливающим одни и ослабляющим другие частоты
3) «последний штрих» к конечному звуку добавляет процесс излучения звуковых волн ртом или носом
Последний пунктом можно в некотором роде пренебречь, т.к. данное преобразование над сигналом можно аппроксимировать дифференцированием и, соответственно, сравнительно просто обратить его воздействие на сигнал. С первыми двумя история несколько сложнее. Оба данных процесса не стационарны во времени. При генерации вокализованного сигнала возбуждения, период смыкания и степень смыкания складок голосовой щели в гортани непрерывно меняется, что порождает изменение в длительности и в форме «гортанных» воздушных импульсов: как следствие, меняется интонация и интенсивность звука, эмоциональный окрас речи. Речевой тракт выше гортани является одним большим подвижным акустическим фильтром, его камеры и смычки, изменяя свою геометрию, меняют положение резонансных (формантных) и антирезонансных частот — меняется тип произносимого вокализованного звука с точки зрения фонетики. При произнесении невокализованного звука голосовые складки не работают, и гортань является источником шумового сигнала. Работа остального речевого тракта при этом принципиально не меняется и, как следствие, спектр шумных звуков речи также имеет формантную структуру, хоть и несколько менее «заметную». Сказанное выше можно проиллюстрировать следующей упрощенной схемой:
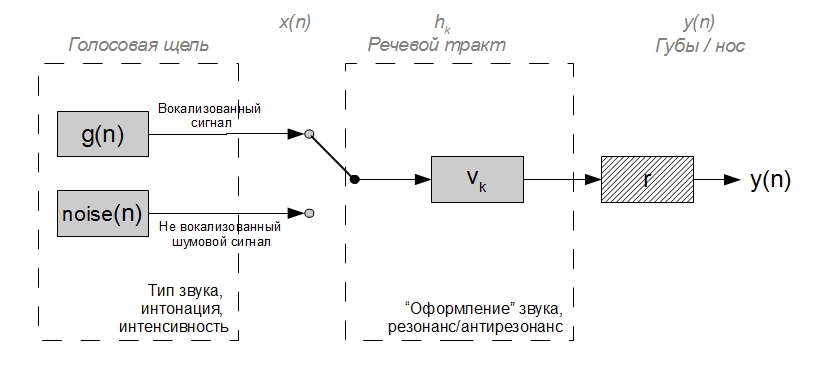
Соответствующие элементы из 1-го рисунка обозначены серым шрифтом вверху.
В реальной жизни существует масса нюансов и механизмов взаимного влияния речевого тракта на гортань и наоборот, а также дыхательного аппарата на всю аккустику речевого тракта в момент, когда речевая щель разомкнута. Однако рассматривая несколько «идеализированные» процессы, можно сказать, что данный рисунок адаптирует предыдущую абстрактную идею «возбуждающий сигнал — фильтр — звук» к артикуляции звуков речи и при этом достаточно хорошо учитывает основные свойства реального речевого сигнала.
Преимущества, которые дает данный взгляд на процесс звукообразования:
— возможность рассматривать сигнал возбуждения речевого тракта и его дальнейшее распространение по речевому тракту независимо друг от друга (в действительности они все-таки взаимосвязаны, однако данная взаимосвязь не всегда ярко выражена и в некоторых случаях ей можно пренебречь)
— возможность анализа речевого тракта как линейной стационарной (на коротких временных интервалах) системы
— возможность хорошо аппроксимировать большинство звуков в речевом сигнале
Конечно, как это всегда бывает в реальной жизни, данный упрощенный подход не так прост для практического применения. Множество неопределенностей возникает даже на этапе разбиения анализируемого сигнала на вокализованные/невокализованные сегменты. Только для этой задачи в общем случае требуется непростая обработка сигнала с привлечением серьезного мат. аппарата. Следующим сложным моментом является нестационарность рассматриваемых процессов, и при этом x(n) меняется гораздо более стремительно, нежели h(n). Для получения достоверных оценок параметров данной модели наиболее оптимальной является обработка сигнала на временных сегментах, длительность которых кратна периоду основного тона, что не просто, с учетом того, что этот период постоянно меняется. Также стоит упомянуть ограниченную применимость данной модели для описания некоторых согласных звуков, в частности фрикативных и «взрывных». При произнесении звонкого фрикативного звука, вокализованный возбуждающий сигнал проходит через значительное сужение в той или иной части речевого тракта, что приводит к формированию сильного турбулентного шума. Глухой фрикативный произносится аналогично, с тем различием, что возбуждающий сигнал изначально шумовой. Таким образом, шумовая составляющая фрикативных звуков в значительной мере формируется уже в речевом тракте, а не только в гортани, что не учитывается данной моделью. «Взрывные» звуки — особый случай, рассмотрение которого мы пока что опустим.
Перейдем теперь от обобщенной дискретной модели к конкретным прикладным моделям, позволяющим оценить те или иные параметры речевого сигнала.
Коэффициенты линейного предсказания (Linear Prediction Coding Coefficients или просто LPC)
Метод LPC бесхитростно подходит к описанной выше обобщенной дискретной модели речевого сигнала. А именно — LPC-коэффициенты непосредственно описывают речевой тракт V (см. предыдущий рисунок). Данное описание конечно же не является исчерпывающим и является некой аппроксимацией реальной акустической системы. Однако, как утверждается теорией, и как многократно доказано практикой (взять хотя бы алгоритмы CELP, применяемые в современных сетях сотовой связи), эта аппроксимация является вполне достаточной для многих и многих случаев. Белым пятном в LPC-модели остается сигнал возбуждения речевого тракта, который на практике либо никак существенно не меняется, либо, например, заменяется на какой-либо заранее рассчитанный, как в CELP.
Опишем более формально, какое именно место занимают LPC-коэффициенты в рассматриваемой системе. Cигнал на входе речевого тракта (на выходе голосовой щели) будем далее обозначать как g[n]. Пока что не будем заострять внимание на природе этого сигнала – шумовой или гармонической. Сигнал на выходе дискретного фильтра, которым мы аппроксимируем речевой тракт будем обозначать v[n]. LPC-модель таким образом решает обратную задачу — мы будем искать g[n], а также параметры фильтра, который превратил g[n] в v[n], имея в своем распоряжении только v[n].
Вспомним предыдущую статью, и описываемую в ней идею представления речевого тракта последовательностью соединенных труб. Главным результатом подобного подхода является удобное представление речевого тракта в виде дискретного фильтра (системы, состоящей из операций сложения/умножения/задержки). С помощью алгебраических преобразований возможно вывести из разностных уравнений, описывающих подобную модель, ее передаточную характеристику вида:
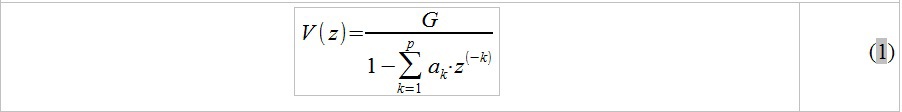
где G – некоторый сложный многочлен, зависящий от коэффициентов отражения r_k, a_k — некоторые действительные коэффициенты, также зависящие от r_k, P – количество труб в рассматриваемой модели. Поскольку мы рассматриваем сигнал на коротких временных интервалах, справедливо предположить «неподвижность» речевого тракта во время анализа, и, соответственно, постоянные значения площадей сочлененных труб, которыми мы аппроксимируем речевой тракт (см. предыдущую статью). Исходя из этого, коэффициенты отражения r_k мы полагаем постоянными, что, в частности, приводит к постоянному значению многочленов G и a_k на анализируемом сегменте речи.
Алгебру приведения разностных уравнений, описывающих состояние каждой трубы в составе речевого тракта (см. предыдущую статью), к данному простому на вид уравнению мы приводить не будем по понятным причинам. Само же данное уравнение представляет собой важный фундаментальный результат — при рассмотрении речевого тракта как системы сочлененных труб возможно привести его к виду линейной стационарной системы (ЛТС), а именно к БИХ-фильтру, содержащему только полюсы (забегая вперед сразу скажем, что эти полюсы и соответствуют так «горячо любимым» нами формантным частотам). Схема работы подобной системы изображена ниже:
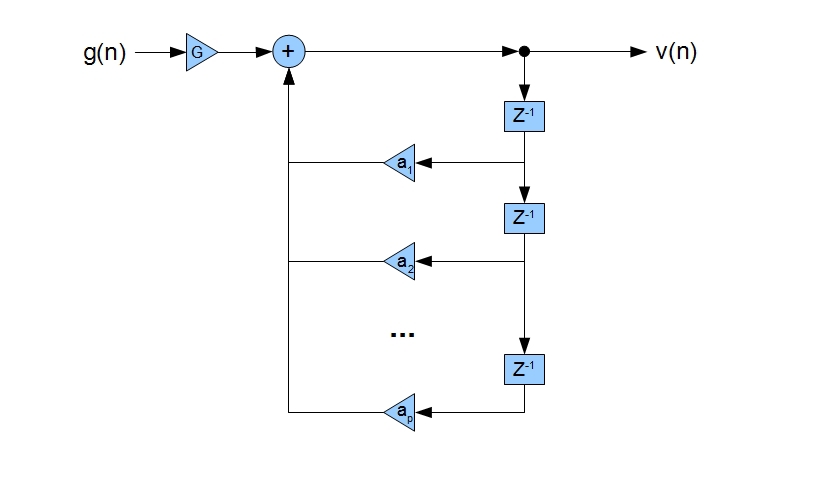
Используя указанную выше передаточную характеристику речевого тракта, можно показать, что сигнал на выходе системы имеет нижеследующий вид во временной области:

Весьма интересный результат: сложный процесс звукообразования в речевом тракте сводится к тому, сигнал на выходе системы в момент времени n является суперпозицией входного сигнала в момент n, домноженного на константу, и линейной комбинации предыдущих выходных отсчетов в моменты n — 1, n — 2 … n — p. Но не будем забывать, что это конечно же всего лишь аппроксимация, игнорирующая многие детали.
Чтобы получить описание состояния речевого тракта на анализируемом сегменте речи, необходимо решить задачу оценки коэффициентов a_k и G. Теория адаптивной фильтрации в целом, и модель LPC в частности, позволяют решить данную задачу сравнительно просто и вычислительно эффективно. Полученное описание речевого тракта будет далеко не исчерпывающим, но достаточным для многих задач.
Нахождение LPC-коэффициентов
Для решения задачи оценки коэффициентов a_k удобно ввести понятие фильтра линейного предсказания, задача которого получить достоверные оценки искомых коэффициентов (оценки будем далее обозначать как a'_k). Выход фильтра предсказания (v'(n)) можно вычесть из сигнала на выходе речевого тракта (полученную разность будем далее называть «сигнал-ошибка»):

e(n) — сигнал-ошибка. Коэффициенты a'_k вместе с G и называют коэффициентами линейного предсказания, LPC-коэффициентами. В случае, когда оценки a'_k близки к истинным значениям a_k, e(n) будет стремиться к G∙g(n). Отметим, что фильтр линейного предсказания является в данной задаче обратным фильтром к нашей аппроксимации речевого тракта. Если оценки a'_k близки к истинным a_k, то данный фильтр (обозначим как v^(-1)_k) способен обратить воздействие речевого тракта на сигнал g(n) с точностью до константы G:

Вернемся к оценкам a'_k. Выбрав некий сегмент сигнала для анализа (предположим длины M), с помощью выражения (3) можно получить вектор сигнала-ошибки аналогичной длины. Вопрос — как теперь имея данный вектор сформировать состоятельные оценки a'_k? Данную задачу можно решить, применяя метод наименьших квадратов. Для этого производится поиск минимума функции E_n, значение которой равно среднему от суммы квадратов значений сигнала-ошибки на некотором анализируемом временном интервале (функция E_n является ничем иным, как среднеквадратическай ошибкой). Другими словами — ищутся такие параметры a'_k, при которых функция среднеквадратической ошибки E_n принимает минимальное значение. Сама среднеквадратическая ошибка в нашем случае выражается формулой:

Нахождение среднего подразумевает деление на количество элементов (умножение на 1/М), однако данный множитель никак не повлияет на решение искомой системы, поэтому его можно опустить.
Ещё раз для ясности опишем, что выражает формула (4):
1) в окрестности момента времени 'n' берется M отсчетов сигнала (как правило, от n до n + M – 1).Число М зависит от частоты дискретизации сигнала и о наших предположениях о длине интервала стационарности этого сигнала.
2) Для выбранных отсчетов составляется выражение, соответствующее ошибке предсказания e(m), m = n: n+M-1
3) Находится среднее от квадратов e(m) (в выражении для среднего опускаем деление на количество членов суммы).
4) Полученное среднее E_n (являющееся функцией от номера отсчета n) мы и будем минимизировать.
Почему в качестве меры достоверности нашего фильтра предсказания применяется именно среднеквадратическая ошибка? Во-первых, она является неплохой численной аппроксимацией дисперсии случайного процесса в некоторых случаях. Если предположить, что наша ошибка распределена нормально и наш фильтр предсказания не сильно смещен, то среднеквадратическая ошибка будет стремиться к дисперсии D[e(m)] и мы, таким образом, ищем минимум дисперсии нашего сигнала-ошибки. Во-вторых (правда, это скорее не причина, а удобное следствие), данную функцию весьма удобно дифференцировать по искомым a'_k, а именно с помощью дифференцирования удобно искать минимум функции.
Раскрыв знак квадрата под суммой в (4) и приравняв нулю значения производных E_n по каждому a'_k, возможно получить систему из P линейных уравнений вида:

Подробный вывод (5) из (4) приводить также не будем — для этого нужно применить несколько формул из школьной алгебры и некоторые формулы для преобразования определенных сумм. Система уравнений (5) является «основным ядром» в алгоритме LPC. Индекс i соответствует номеру уравнения в системе (номеру a'_k, по которому брали производную) и, так же, как и индекс k, проходит все значения от 1 до P. Напомним, что P соответствует числу труб в модели, аппроксимирующей речевой тракт. Это же число называют порядком линейного предсказания. Решение систем линейных алгебраических уравнений — отдельная прикладная область со своим математическим аппаратом, поэтому в данную задачу углубляться мы не будем. Скажем лишь, что для решения конкретно системы (5) с учетом её свойств как правило применяют разложение Холецкого или рекурсию Левинсона-Дарбина
Решив систему из P уравнений от P неизвестных, мы получаем оценки a'_k, и остается только найти коэффициент усиления G. В методе LPC оценка G находится после оценки a'_k, исходя из предположения, что сигнала на входе фильтра V является либо смещенной в момент времени n дискретной дельта-функцией (единичный импульс в момент n), либо белым шумом. В обоих случаях G можно найти из соотношения:

Сам вывод этой формулы исключительно математический (что в случае дельта-функции, что в случае белого шума) и как объяснить популярно физический смысл данной формулы автор статьи не представляет — оставим её как есть. Однако само предположение, что входной сигнал вдруг стал единичным импульсом или белым шумом стоит объяснить более подробно.
Строго говоря, на выходе голосовой щели в гортани — на входе речевого тракта, мы имеем либо «гортанный» импульс, либо окрашенный шумовой сигнал, но никак не дельта-функцию или белый шум. И вот тут в теории LPC делается весьма хитрый «финт ушами». Мы воображаемо представляем гортань частью речевого тракта и говорим, что вот именно в гортань-то якобы входил как раз либо единичный импульс, либо белый шум. Понятие речевого тракта, таким образом, несколько расширяется в рамках нашей модели, и чтобы учесть новой моделью эффекты, которые делают из единичного импульса «гортанный» импульс, а из белого шума окрашенный шум, мы увеличиваем порядок линейного предсказания P. Более того, мы идем дальше и включаем в наш «LPC-фильтр» эффекты, связанные с излучением сигнала, что также компенсируем добавлением дополнительных коэффициентов. Данные операции соответствуют увеличению длины нашего полюсного фильтра, которым мы аппроксимируем речевой тракт, что приведет к росту числа его полюсов, и именно эти дополнительные полюсы отвечают за означенное выше воображаемое превращение. Очевидно, что в таком случае модель LPC уже не вполне соответствует изначальному дискретному фильтру, аппроксимирующему речевой тракт. Однако идеологически эти два подхода остаются весьма близкими, если не сказать «родственными». Восстановить с помощью LPC сигнал возбуждения речевого тракта g[n], в том виде, как мы этого хотели вначале, не представляется возможным. Тем не менее, итоговая аппроксимация частотной характеристики речевого тракта (коэффициенты a'_k), полученная с помощью LPC, достаточно точна для многих задач.
Раз заговорили о выборе порядка P, логично дать какие-то общие рекомендации по его выбору. Считается, что в среднем формантные частоты в речевом сигнале располагаются с плотностью примерно 1 форманта на килогерц. Тогда, поскольку каждый комплексный полюс нашего модельного фильтра соответствует одной формантной частоте, удобно выбирать порядок, как:

где [] — округление до ближайшего целого числа, Fs — частота дискретизации сигнала в герцах. Для компенсации эффекта совмещения гортани и речевого тракта, а также для учета в модели эффекта излучения сигнала губами/носом, различные источники рекомендуют увеличить P дополнительно на 2-4 коэффициента. Т. е. для работы, например, с 10 КГц сигналом, порядок P можно выбрать равным 12-14 коэффициентов. Некоторые авторы также советуют применять плотность «1 форманта на 1200-1300 Гц», когда анализируется женский голос. Это связано с меньшей длиной речевого тракта у женщин и, как следствие, более высокими значениями формантных частот в женских голосах.
Краткий итог по модели LPC
Что в итоге нам дает расчет LPC-коэффициентов для некоторого сигнала:
1) Выходом алгоритма расчета LPC является набор числовых коэффициентов, которые описывают полюсный фильтр. Данные коэффициенты в чистом виде позволяют получить выражение для выхода данного фильтра во временной области (выражение (2)), а также общий вид его z-характеристики (выражение (1)). Поскольку данный фильтр является полюсным, то в его основе лежит рекурсия и выразить импульсную характеристику для такого фильтра не представляется возможным. С помощью z-характеристики, тем не менее, возможен полноценный анализ полученного фильтра как во временной, так и в частотной областях.
2) Если разложить на множители знаменатель полученной z-характеристики, становится возможным найти численные значения частот, соответствующих полюсам данного фильтра. Эти же значения хорошо аппроксимируют формантные частоты речевого тракта на анализируемом сегменте речи. (Правда стоит добавить, что точность аппроксимации зависит от грамотного выбора базовых параметров LPC — порядка P, длительности анализируемого интервала M, времени начала анализа n. Для общего случая автоматизировать этот выбор не так просто.)
3) Полученный с помощью LPC сигнал-ошибка (сигнал возбуждения дискретного фильтра, которым мы аппроксимируем процесс звукообразования) выходит похожим либо на белый шум, либо на смещенную во времени дельта-функцию. (данный пункт наиболее активно эксплуатируется при сжатии речи)
Ниже для примера приведен логарифмический спектр сигнала, полученный обычным БПФ, и с помощью LPC. Обрабатывалась гласная «А», произнесенная мужским голосом.
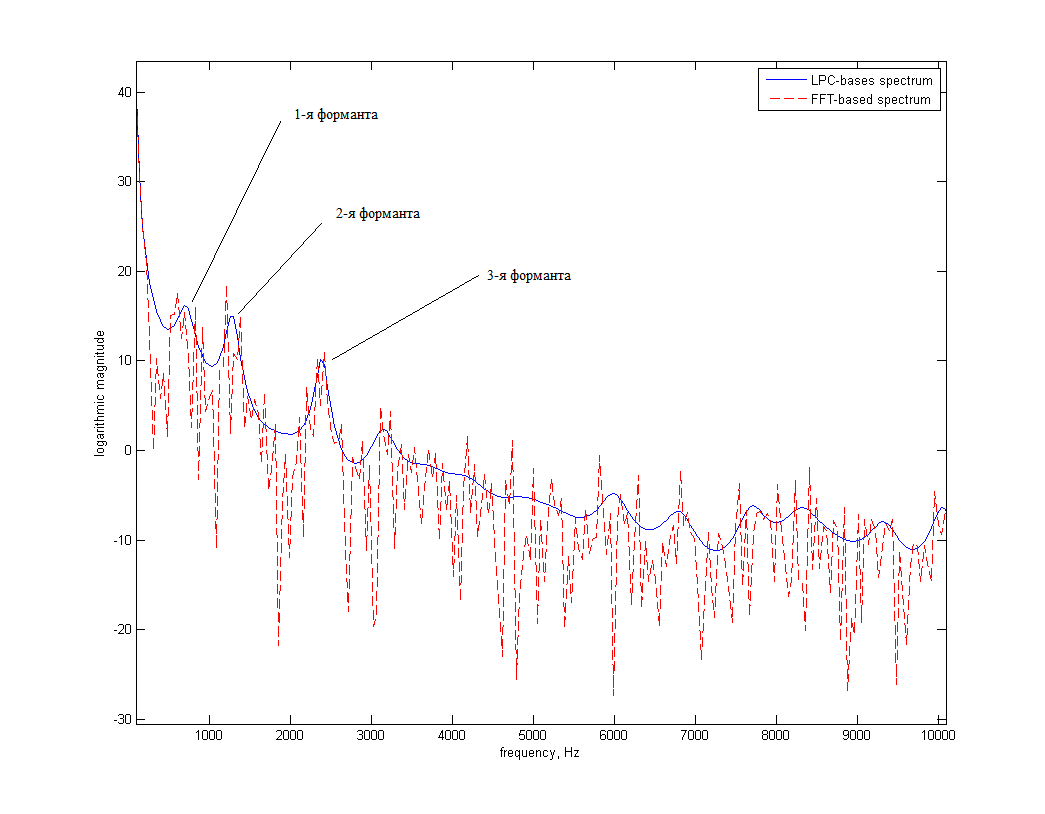
Как видно, «LPC-спектр» является некоторой сглаженной версией обычного «БПФ-спектра». При этом формантные частоты проявляются «яркими» локальными максимумами, что является хорошим «стартом» для их обнаружения и слежения за ними.
Применение LPC для анализа речевого тракта
Как было сказано в предыдущей статье, при представлении речевого тракта в виде сочлененных труб фиксированного диаметра возможно аппроксимировать процессы, происходящие внутри каждой трубы при распространении по тракту звука, с помощью разностных уравнений. При этом уравнения будут зависеть от коэффициентов отражения r_k, где k – номер рассматриваемой трубы. Данные коэффициенты в свою очередь зависят от отношения площади рассматриваемой трубы к площади следующей за ней трубы. Граничные условия (первая труба после гортани и последняя перед губами) берутся из особых формул, зависящих от соответствующих акустических импедансов, которые в свою очередь могут в большинстве случаев быть табличными функциями. Ранее в статье без доказательства приводился тот факт, что из совокупности дискретных разностных уравнений, описывающих такую систему, можно вывести соотношение (1), которое можно принять удобной отправной точкой LPC-анализа.
Сам по-себе LPC-анализ – достаточно «прямолинейный» и эффективный метод. Сразу может появиться вопрос, а возможно ли, рассчитав LPC-коэффициенты некоторого сигнала, каким-то образом восстановить параметры речевого тракта? На данный вопрос нельзя дать на 100% положительный ответ. С одной стороны, LPC-коэффициенты являются многочленами от r_k, и практически возможно проделать обратную операцию – восстановить r_k из a'_k. Для этого можно применить переходный этап в виде PARCOR (partial correlation) коэффициентов. Т. е. из LPC-коэффициентов рассчитать PARCOR-коэффициенты, а уже из них r_k. Однако есть одно осложняющее обстоятельство: в модель LPC включаются эффекты, связанные с прохождением сигнала через гортань и его излучением в районе губ, что никак не соответствует модели речевого тракта в виде дискретного фильтра из предыдущей статьи (число труб в модели речевого тракта уже не равно порядку линейного предсказания P). В случае, если каким-то образом обратить воздействие на сигнал гортани и излучения, и проводить LPC-анализ этого модифицированного сигнала, то возможно получить более состоятельные оценки коэффициентов отражения на основе LPC. Опять же стоит помнить, что даже в таком случае, коэффициенты отражения могут показать лишь отношения площадей соседствующих труб в модели речевого тракта — не имея никаких начальных приближений, не удастся восстановить абсолютные значения площадей. Т. е. мы сможем восстановить некоторую функцию, повторяющую площадь речевого тракта, однако отличающуюся от неё на некоторый масштабирующий множитель.
Существует немало работ, авторы которых решают задачу восстановления функции площади речевого тракта, и в данных работах LPC-коэффициенты занимают не последнее место в используемом математическом инструментарии. В частности, LPC нередко применяется в качестве базового метода для определения значений формантных частот, с помощью которых уже восстанавливается функция площади речевого тракта.
Сам по себе подход к анализу площади речевого тракта с помощью LPC имеет множество погрешностей, связанных с допущениями, которые мы изначально делаем, полагая в качестве модели речевого тракта линейный дискретный фильтр — об этом много было сказано в предыдущей статье. Исследования на данную тему велись и ведутся, неплохие результаты достигнуты, но действительно точно восстановить функцию площади речевого тракта на сегодняшний день в общем случае невозможно, ни с применением LPC, ни с помощью каких-либо принципиально иных подходов.
Выводы
В данной статье кратко описаны основные идеи и идеология LPC-модели представления речевого сигнала. Данная модель является одной из наиболее часто применяемых в области обработки речи и, несмотря на свои фундаментальные ограничения, дает весьма неплохие оценки реальных физических феноменов. Наиболее часто данная модель применяется для задач:
— сжатия речи
— анализа формантных частот
— анализа речевого тракта (в качестве вспомогательного инструмента)
В следующей статье мы расскажем про HPN-модель (Harmonics-plus-noise) речевого сигнала, в рамках которой речевой сигнал в явном виде разделяется на вокализованную и невокализованную составляющие.
Использованная литература:
[1] J.L. Flanagan. Speech Analysis, Synthesis and Perception.
[2] L.R. Rabiner, R.W. Schafer, Digital Processing of Speech Signals // (основной первоисточник данной статьи)
[3] Солонина И.А. Основы цифровой обработки сигналов, 2-е издание // (хорошее краткое, но немного «сухое» объяснение, как инструкция к применению )
[4] Mark Hasegawa-Johnson, Lecture Notes in Speech Production, Speech Coding, and Speech Recognition
[5] G. Fant. Speech Acoustics and Phonetics. Selected Writings.
