Комментарии 50
А с производительностью что? Как-то можно сравнить?
Можно написать две программы, по одной из задач benchmarksgame.alioth.debian.org/. Я пытаюсь специализироваться в D, нужен еще спец. по Rust. Тогда можем и сравнить.
Реализации этих программ лежат в репозитории Rust и постоянно обновляются и тестируются (вот, к примеру, n-body). Я помню видел их своими глазами на BenchmarksGame, но сейчас там какие-то проблемы с лицензией выясняются, и их временно убрали с сайта. Языка D на этом сайте вообще почему-то нет. Если не боитесь установить (а лучше собрать) Rust, то всё в Ваших руках ;)
Rust (Исходник):
Все файлы, относящиеся к бенчмарку D лежат на гитхабе.
DMD:
GDC (один из последних коммитов):
LDC2:
Замерял следующим образом (далее таблица по 10 замеров для каждого билда):
Таблица замеров (время в секундах):
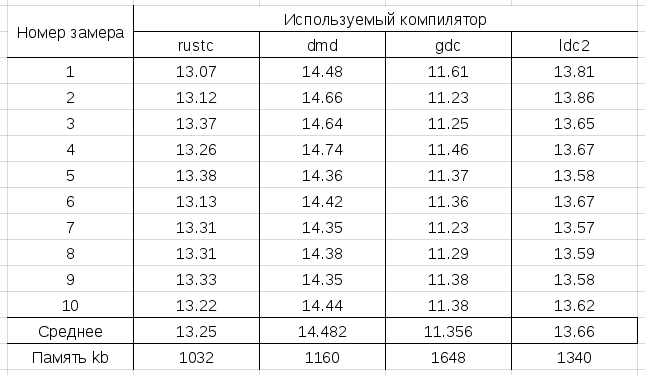
Выводы: Rust и D примерно одинаковы по производительности. Для D лучше использовать GDC, когда важна скорость.
Конфигурация машины:
Intel® Core(TM)2 Quad CPU Q9400 @ 2.66GHz
3.14.4-200.fc20.x86_64
$ rustc --version
rustc 0.11.0-pre (6266f64 2014-06-06 23:06:35 -0700)
host: x86_64-unknown-linux-gnu
$ rustc nbody.rs --opt-level 3
Все файлы, относящиеся к бенчмарку D лежат на гитхабе.
DMD:
$ dmd --help
DMD64 D Compiler v2.065
$ dmd -ofnbody source/nbody.d -release -inline -noboundscheck -O
GDC (один из последних коммитов):
$ gdc --version
gdc (GCC) 4.8.2
$ gdc -onbody source/nbody.d -O3 -frelease
LDC2:
$ ldc2 --version
LDC - the LLVM D compiler (0.13.0-beta1):
based on DMD v2.064 and LLVM 3.4.1
Default target: x86_64-unknown-linux-gnu
$ ldc2 -ofnbody source/nbody.d -release -O3
Замерял следующим образом (далее таблица по 10 замеров для каждого билда):
/usr/bin/time --verbose ./nbody 50000000
Таблица замеров (время в секундах):

Выводы: Rust и D примерно одинаковы по производительности. Для D лучше использовать GDC, когда важна скорость.
Конфигурация машины:
Intel® Core(TM)2 Quad CPU Q9400 @ 2.66GHz
3.14.4-200.fc20.x86_64
Странно, ожидал увидеть много комментариев и обсуждений…
Господа, а можно сделать что-то вроде «Rust для программиста на PHP».
Я понимаю, это выглядит смешно, но писать быстро и интуитивно понятно — это весьма важно.
Просмотрев несколько статей про Rust не нашел там простого способа сделать ассоциативный массив.
Я понимаю, это выглядит смешно, но писать быстро и интуитивно понятно — это весьма важно.
Просмотрев несколько статей про Rust не нашел там простого способа сделать ассоциативный массив.
Смотрите doc.rust-lang.org/std/container/trait.MutableMap.html
Если вы имеете ввиду ассоциативный массив, который вроде и массив, и мапа, да еще и с какими угодно ключами, это своего рода фишка PHP, которая мало где еще есть, по крайней мере в стандартных библиотеках. И такой синтаксической поддержки нет нигде.
Если вы имеете ввиду ассоциативный массив, который вроде и массив, и мапа, да еще и с какими угодно ключами, это своего рода фишка PHP, которая мало где еще есть, по крайней мере в стандартных библиотеках. И такой синтаксической поддержки нет нигде.
Забавно, что Вы спрашиваете об этом здесь, под постом о D :)
Есть неплохой материал на это тему в Rust For Rubyists, однако я не вижу там ассоцииативных массивов… Про них неплохо написано в официальной документации HashMap. Что же касается полноценной статьи «Rust для программиста на PHP», то тут я, извините, пасс.
Есть неплохой материал на это тему в Rust For Rubyists, однако я не вижу там ассоцииативных массивов… Про них неплохо написано в официальной документации HashMap. Что же касается полноценной статьи «Rust для программиста на PHP», то тут я, извините, пасс.
Ну, я в курсе что и Rust, и в D, нечто подобное есть. Вот тут как раз привели пример на D.
Просто хотелось бы получить примеры простого кода как это делать правильно на Rust. А потом сравнить их и понять. Также не плохо было бы обсудить как эти массивы освобождаются из памяти и требуются ли для этого какие-то специальные действия. В PHP это все выглядит очень просто. А насколько просто это можно сделать в этих языках?
Просто хотелось бы получить примеры простого кода как это делать правильно на Rust. А потом сравнить их и понять. Также не плохо было бы обсудить как эти массивы освобождаются из памяти и требуются ли для этого какие-то специальные действия. В PHP это все выглядит очень просто. А насколько просто это можно сделать в этих языках?
В D ассоциативные массивы встроены в рантайм и полагаются на GC. Реализованы они как объекты, т.е. чтобы освободить память ассоциативного массива нужно обнулить все ссылки на него, а также можно вызывать метод clear для очистки внутренностей а.массива.
Я было попробовал то же самое сдалать на Rust, но тут же упёрся в тот факт, что числа с плавающей точкой не могут быть ключами деревьев (как
Интересно, а как с этим (NaN) обходится D? В целом, судя по примеру, он сейчас намного более дружелюбен PHP разработчикам…
TreeMap, так и HashMap). Длинная дискуссия тут, но основной смысл — что NaN не вписывается. В Rust пока консенсус таков, чтобы сделать обёркти для f32 и f64, которые реализуют способности Ord и Hash, так что могут быть и ключами.Интересно, а как с этим (NaN) обходится D? В целом, судя по примеру, он сейчас намного более дружелюбен PHP разработчикам…
D REPL:
Для хеширования используется TypeInfo (TypeInfo для классов переопределяет поведение getHash), соответственно:
D> bool[double] map;
=> map
D> map[0.0/0.0] = true;
D> map.keys
=> [-nan]
D> map[-double.nan]
=> true
Для хеширования используется TypeInfo (TypeInfo для классов переопределяет поведение getHash), соответственно:
D> auto val = double.nan;
=> val
D> typeid(double).getHash(&val)
=> 360911136610280172
Вот что сказал один из спецов по поводу использования
По его словам, решение в D не самое удачное, хотя я согласен, что это может быть удобно. Он утверждает, что бесконечно пихая некорректные числа в этот ассоциативный массив, каждая следующая операция будет линейно медленнее, что может стать орудием для атаки. Есть и такое мнение:
С этим трудно не согласиться. Может быть, поддержка float в таком контексте — излишество, которое может стать и проблемой безопасности (упомянутый DoS vector)?
float как ключей в D:10:02 SiegeLord: So I checked, D associative arrays in the current release treat NaN's as equal, and in the master they treat them as unequal (i.e. they do the bad thing)
10:02 SiegeLord: The bad thing being, I think you can insert key NaNs, but not get them back
10:03 SiegeLord: So… essentially… that code example is nothing to be proud of
10:04 kvark: SiegeLord: so it works in 99.9% of cases, where we don't have a NaN key, and the rest of the cases are simply unable to get the key back? That sounds like a win to me
10:04 SiegeLord: It's a DoS vector
10:04 pczarn: why?
10:05 SiegeLord: You make insertion operation be O(n)
10:05 SiegeLord: Keep inserting NaN, and it keeps making the bucket longer and longer
10:05 SiegeLord: And it has to check them all by equality before determining that its a 'new' key
По его словам, решение в D не самое удачное, хотя я согласен, что это может быть удобно. Он утверждает, что бесконечно пихая некорректные числа в этот ассоциативный массив, каждая следующая операция будет линейно медленнее, что может стать орудием для атаки. Есть и такое мнение:
10:09 pyon Why would anyone want to compare floats for equality? This is a data type invented for scientific computations with inexact numbers. :-|
С этим трудно не согласиться. Может быть, поддержка float в таком контексте — излишество, которое может стать и проблемой безопасности (упомянутый DoS vector)?
Хм, я такого поведения в 2.065 не обнаружил (а если оно есть в ~master, то определенно нужен regression issue):
import std.stdio;
import std.datetime;
void dos(bool[float] array)
{
array[double.nan] = true;
}
void main()
{
bool[float] array;
auto test1 = benchmark!(() => dos(array))(100_000); array.clear;
auto test2 = benchmark!(() => dos(array))(1000_000); array.clear;
auto test3 = benchmark!(() => dos(array))(10000_000);
writeln(test1[0].msecs / cast(double) 100_000); // 0.00038
writeln(test2[0].msecs / cast(double) 1000_000); // 0.000307
writeln(test3[0].msecs / cast(double) 10000_000); // 0.0002816
}
Ну, числа с плавающей точкой как ключи, я вообще-то ни разу не использовал. В доке по PHP написано, что они приводятся к целому ключу.
Но создание — это ещё относительно просто в обоих языках, а вот например вернуть из функции такой ассоциативный массив целиком — это уже похоже на нетривиальную задачу. Хотя может я зря поднимаю эту тему, и GC в обоих языках работает аккуратно и всегда? В PHP об этом вообще не думаешь. Оно просто работает:
Но создание — это ещё относительно просто в обоих языках, а вот например вернуть из функции такой ассоциативный массив целиком — это уже похоже на нетривиальную задачу. Хотя может я зря поднимаю эту тему, и GC в обоих языках работает аккуратно и всегда? В PHP об этом вообще не думаешь. Оно просто работает:
<?php
function a($a) {
$a["add"]=1;
return $a;
}
var_dump(a(array("o"=>2)));
var_dump(a(array("c"=>4)));
?>array(2) { ["o"]=> int(2) ["add"]=> int(1) } array(2) { ["c"]=> int(4) ["add"]=> int(1) }С этим как-раз таки проблем быть не должно. Пример без использования сборщика мусора:
use std::collections::hashmap::HashMap;
type MyMap = HashMap<String,int>;
fn a(mut map: MyMap) -> MyMap {
map.insert("add".to_string(), 1);
map
}
fn main() {
let mut x: MyMap = HashMap::new();
x.insert("o".to_string(), 2);
println!("{}", a(x));
x = HashMap::new();
x.insert("c".to_string(), 4);
println!("{}", a(x));
}
Р-р-р.
За такой синтаксис надо бить по голове, учебником по… (эргономике?)
Зачем там
Почему
И вообще, квадратные скобки скорее соответствуют replace. Что будет, если там уже есть ключ
Про чистку памяти возникают еще интересные вопросы. Cначала просто: я правильно понимаю, что вот на этой строчке
За такой синтаксис надо бить по голове, учебником по… (эргономике?)
Зачем там
.to_string()?Почему
insert(), а не []?И вообще, квадратные скобки скорее соответствуют replace. Что будет, если там уже есть ключ
add?Про чистку памяти возникают еще интересные вопросы. Cначала просто: я правильно понимаю, что вот на этой строчке
x = HashMap::new() память первого массива полностью освобождается? А в конце main освобождается и второй? А теперь хитрее: представим, что мы копируем из одного массива данные в другой. И ключи у них ну очень длинные, мегабайты длинной. Как будет работать такая процедура? Ключи будут дублироваться в памяти, или будет вестись счетчик ссылок на одинаковые строки и удалятся эти строки будут только когда их более никто не использует?Ваше возмущение понятно. Строки и оператор индексирования — это одни из тех вещей, над которыми идёт работа сейчас, так что этот пример может измениться ближе к выпуску версии 1.0.
> Зачем там .to_string()?
Потому что голая строковая константа имеет тип
> Почему insert(), а не []?
Работа над этим ведётся.
> И вообще, квадратные скобки скорее соответствуют replace. Что будет, если там уже есть ключ add?
insert() замещает существующий элемент. Интерфейс MutableMap.
> я правильно понимаю, что вот на этой строчке x = HashMap::new() память первого массива полностью освобождается? А в конце main освобождается и второй?
Правильно.
> А теперь хитрее:…
В Rust никто за Вашей спиной не будет подсчитывать ссылки. Если Ваша программа копирует большие объекты, то можете использовать подсчёт ссылок для них, обернув в
> Зачем там .to_string()?
Потому что голая строковая константа имеет тип
&str, а ассоциативному массиву нужен String. Фактически to_string() выделяет память в куче и копирует туда строку. Не всегда нужно иметь строку в куче, поэтому по умолчанию Rust не делает ничего лишнего.> Почему insert(), а не []?
Работа над этим ведётся.
> И вообще, квадратные скобки скорее соответствуют replace. Что будет, если там уже есть ключ add?
insert() замещает существующий элемент. Интерфейс MutableMap.
> я правильно понимаю, что вот на этой строчке x = HashMap::new() память первого массива полностью освобождается? А в конце main освобождается и второй?
Правильно.
> А теперь хитрее:…
В Rust никто за Вашей спиной не будет подсчитывать ссылки. Если Ваша программа копирует большие объекты, то можете использовать подсчёт ссылок для них, обернув в
Rc:use std::rc::Rc;
fn foo(_x: Rc<String>) {}
fn main() {
let x = Rc::new("my long string".to_string());
foo(x.clone());
}
Иногда мне кажется что обычные плюсы сейчас намного читабельнее, сравним:
почти дословно пхпшный вариант
auto& a(const std::unordered_map<std::string, int>& arr)
{
arr["add"] = 1;
return arr;
}
for(auto& el: a({{"o", 2}}))
std::cout << el.first << " => " << el.second;
for(auto& el: a({{"c", 4}}))
std::cout << el.first << " => " << el.second;
почти дословно пхпшный вариант
В D ассоциативные массивы ведут себя как объекты:
Проблем с GC быть не должно, если ссылок на ассоциативны массив больше нет, то он удаляется.
import std.stdio;
// Возврат из функции
int[string] add(int[string] array)
{
array["add"] = 1;
return array;
}
// Измененение будет видно вне функции
void add2(int[string] array)
{
array["add"] = 1;
}
void main()
{
writeln(add(["o": 2])); // ["add":1, "o":2]
writeln(add(["c": 4])); // ["c":4, "add":1]
// еще вариант записи
writeln(["o": 2].add); // ["add":1, "o":2]
// или даже так
["o": 2].add.writeln; // ["add":1, "o":2]
// Демонстрация поведения by-reference
int[string] arr = ["o": 2];
add2(arr);
writeln(arr); // ["add":1, "o":2]
}
Проблем с GC быть не должно, если ссылок на ассоциативны массив больше нет, то он удаляется.
Мда, в D всё по-человечески.
Но вот разница by-reference — как то не совсем уловима. Вроде и в функции add массив-аргумент тоже правится?
Но вот разница by-reference — как то не совсем уловима. Вроде и в функции add массив-аргумент тоже правится?
Если ассоциативные массивы копировались бы при передаче в функцию, то последний writeln вывел
Если для статических массивов нужно ссылочное поведение, то к типу аргумента добавляют ref. Также важный момент
["o":2], изменялся бы локальный ассоциативный массив внутри функции. Такое поведение имеют статические массивы:// статический массив
void add(int[5] array)
{
// заполним весь массив значением 42
array[] = 42;
}
// динамический массив
void add(int[] array)
{
// заполним весь массив значением 42
array[] = 42;
}
void main()
{
int[5] array = [1, 2, 3, 4, 5];
add(array);
writeln(array); // [1, 2, 3, 4, 5]
add(array[]);
writeln(array); // [42, 42, 42, 42, 42]
}
Если для статических массивов нужно ссылочное поведение, то к типу аргумента добавляют ref. Также важный момент
add(array[]), через оператор [ ] (оператор для slicing) мы получаем динамический массив, который внутри ссылается на данные статического массива.Простите, я слоупок, случайно набрел на это обсуждение. У меня вопрос. Вот в этом месте
получается, что объект создается в куче, а не на стеке? Это стандартное поведение или компилятор делает так потому, что ссылка на объект «утекает» из функции в качестве возвращаемого значения?
add(["o": 2])
получается, что объект создается в куче, а не на стеке? Это стандартное поведение или компилятор делает так потому, что ссылка на объект «утекает» из функции в качестве возвращаемого значения?
Стандартное поведение, ассоциативные массивы, реализованные в рантайме, всегда размещается в куче.
Да. Можно было не спрашивать. Когда-то давно интересовался D и для общего развития прочитал книгу Александреску и даже что-то для себя попробовал написать. Сейчас нашел книгу, посмотрел снова, действительно, память подо все объекты выделяется в куче и способа создать объект на стеке не существует. Это и сейчас верно или с тех пор что-то поменялось?
Сейчас можно создавать объекты на стеке с помощью scope, также используется библиотечное unsafe решение std.typecons.scoped.
Книга Александреску немного устарела и многие новые фичи и изменения в языке там просто не отражены. Из свежих могу посоветовать D Cookbook.
Книга Александреску немного устарела и многие новые фичи и изменения в языке там просто не отражены. Из свежих могу посоветовать D Cookbook.
Мне тоже нравится язык. Но я предпочитаю дождаться хотя бы первого релиза, потому что сейчас язык меняется каждый месяц, примеры, работающие год назад, сейчас уже не компилируются. Судя по слухам, что в ближайшие 2 года спецификация уже будет, то ждать осталось недолго.
В D есть такие ассоциативные мапы:
Также можно в качестве ключей использовать свои типы, для этого нужно перегрузить операторы:
Полные доки: dlang.org/hash-map.html
string[float] map0;
double[string][string] map1;
bool[bool][string][float] map2;
map0[42.0] = "foo";
assert(42.0 in map0);
map1["foo"]["bar"] = 42.0;
foreach(k1, submap; map1)
foreach(k2, val; submap)
std.stdio.writeln(k1, " ", k2, " ", val);
assert(map0.keys == [42.0]);
assert(map0.values == ["foo"]);
Также можно в качестве ключей использовать свои типы, для этого нужно перегрузить операторы:
const hash_t toHash();
const bool opEquals(ref const KeyType s);
const int opCmp(ref const KeyType s);
Полные доки: dlang.org/hash-map.html
Мне синтаксис D нравится больше всего, но использовать его в real-world проектах сложно: сырой компилятор (одни только невнятные ошибки чего стоят), обширная, но бесполезная документация, мало примеров кода. Жаль, что гугл с его административным ресурсом пиарит свой убогий Go (язык без классов и с обработкой ошибок по значению функции), а не интересный D =)
А можно вас попросить, пожалуйста, пример(ы) таких невнятных ошибок и ссылок на баги в компиляторе? Пока использую D по мелочи, один раз только в проекте до 1000 строк, и явных проблем не испытывал. Интересно просто, особенно после C++ на MSVC, с чем можно столкнуться.
Уже честно сказать не вспомню, дело было полгода назад. Выбирали язык, уж больно понравился D, но все-таки показался сыроватым. Там еще на этапе компиляции вылезали какие-то малоинформативные ошибки, мы побороли часть, потом поняли, что дальше так разработку вести нельзя — к сожалению или счастью, тот проект надо было делать быстро и нужен был «реальный результат» (как любит говорить один знакомый PM), а не игры с языками.
Уже использовал его в реальных проектах (сильно больше 1к строк), на серьезные баги не натыкался. Были проблемы с контрактами, они просто во многих случаях не вызывались, а должны были. Еще довольно жестокие грабли — __gshared модификатор, лучше его не использовать. Неаккуратное его использование может приводить к утечкам памяти и боли при синхронизации (ну это его назначение).
А мне нравится Go, мне нравится Plan9, я читал и правил для себя код Plan9 и компилятора Go и мне нравится как написан этот код, я на нем учусь. Мне по человечески симпатичны авторы этого кода. Я считаю идею классов никакой, я считаю концепцию исключений тупиковой. Я полагаю называть Go убогим скоропалительным.
Мне нравится, каким позитивным у Вас получился комментарий. По-больше бы добра в наши языковые войны ;)
Я очень искренне хотел бы любить и Go, я согласен про классы (вопрос о том, хорошо ли неявное совпадение с интерфейсами, оставим на сладкое), и исключений не хочу касаться за милю. Убогим Go назвать ну никак нельзя. Объясните мне только, когда, наконец, можно будет самому написать такие же обобщённые контейнеры, которые предоставляет стандартная библиотека? Версия 1.2 уже вышла, что явно не располагает к масшабным изменениям в будущем.
Я очень искренне хотел бы любить и Go, я согласен про классы (вопрос о том, хорошо ли неявное совпадение с интерфейсами, оставим на сладкое), и исключений не хочу касаться за милю. Убогим Go назвать ну никак нельзя. Объясните мне только, когда, наконец, можно будет самому написать такие же обобщённые контейнеры, которые предоставляет стандартная библиотека? Версия 1.2 уже вышла, что явно не располагает к масшабным изменениям в будущем.
Видимо никогда. Это решение Роба (командора) Пайка, которое не разделяет часть коммьюнити включая меня, но с которым мы будем мириться, потому что Пайку мы обязаны например unicode, редактором acme и серьезным куском Plan9 codebase.
Жаль… А потом говорят, что Rust сложный. Там хотя бы вся стандартная библиотека написана на самом языке и ничем не лучше частного кода.
А Роб прикольный чувак. Видел его в битве с Страуструпом, Александреску и Максакисом на LangNext.
А Роб прикольный чувак. Видел его в битве с Страуструпом, Александреску и Максакисом на LangNext.
НЛО прилетело и опубликовало эту надпись здесь
Может кому будет интересно сравнение Scala, C#, D и C dlang.ru/forum/218-subektivnoe-sravnenie-scala-csharp-d-i-c
я не знаю ни один подобный язык, в который был встроен такой мощный анализатор времени жизни переменных.
Регионы появились Cyclone. Но успеха этот язык не имел.
Регионы появились Cyclone. Но успеха этот язык не имел.
int minval(int[] A)
{
return A.reduce!"a < b ? a : b";
// или
//return A.reduce!((a,b) => a < b ? a : b);
}Лучше так:
int minval(int[] A)
{
return A.reduce!q{ a < b ? a : b };
}#[deriving(Clone, Eq, Hash, PartialEq, PartialOrd, Ord, Show)]
struct A{
x: Box<int>
}Аналога данного механизма в D нет.
Есть же:
struct A {
mixin Clone!A;
mixin Eq!A;
mixin Hash!A;
mixin PartialEq!A;
mixin PartialOrd!A;
mixin Ord!A;
mixin Show!A;
int x;
}Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Сравнение D и C++ и Rust на примерах