Этим постом я хочу привлечь внимание к интересной области прикладного программирования, бурно развивающейся в последние годы — компьютерной лингвистике. А именно — системам, способным к разбору и пониманию текста на русском языке. Но основной фокус внимания я хочу сместить с академических и промышленных систем, в которые вложены десятки и тысячи человеко-часов, к описанию тех способов, какими успехов на этом поприще могут добиться любители.
Для успеха нам потребуется несколько составляющих: умение разбирать текст на слова и леммы, умение проводить морфологический и синтаксический анализ, и, самое пожалуй интересное, умение искать в тексте смысл.
В русском сегменте интернета существуют свободные для некоммерческого использования синтаксические движки, с хорошим качеством решающие задачи морфологического и синтаксического анализа. Я хочу отметить два из них.
Первый, который я использую с большой пользой сам — SDK грамматического словаря русского языка.
Второй — это томита-парсер от Яндекс.
Они содержат словарь, тезаурус, функции разбора текста и обладают достаточно низким порогом вхождения.
Синтаксические движки позволяют превратить любой текст в пригодный для машинной обработки формат. Это может быть дерево синтаксического разбора, по которому можно проследить отношения слов во фразе:
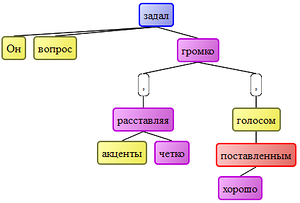
для фразы «Он задал вопрос громко, четко расставляя акценты, хорошо поставленным голосом.» источник
Так и просто вектор индексов нормальных форм слов.
К сожалению, для русского языка в настоящий момент не представлены мощные сети уровня FreeBase (1.9 млрд. связей) да и русский сегмент ДБПедии намного беднее англоязычного. Коммерческие источники, такие, как выверенная вручную сеть, использующаяся в Compreno от ABBYY, любителям также недоступны. Поэтому, сеть придётся формировать самостоятельно.
Нам необходимы — словари, грамматические и смысловые связи между словами.
Я использовал два основных источника:
Викисловарь и набор словарей с сайта Академик.
Викисловарь даёт нам семантические свойства большинства распространённых слов и связи слов с родственными словами. Позже будет описано, каким образом можно это использовать. На Академике представлены словари синонимов и антонимов — прекрасно дополняющих Викисловарь.
С этим сложнее. Смысловые связи определяются в тезаурусах, в том числе — в открывшемся недавно в публичный доступ тезаурусе RuThes, но общая проблема всех тезаурусов — их ограниченность. Слишком мало слов, слишком мало связей. Поэтому связи между словами можно накапливать и самостоятельно — занимаясь набором статистики согласованных и несогласованных нграмм по библиотекам художественной литературы, новостным лентам.
Процесс обработки больших объёмов текста, тем не менее, относительно быстр — 1 Гигабайт текста в однобайтовой кодировке можно обработать менее чем за неделю.
Сеть, объединяющая большую часть сейчас употребляемых слов русского языка, с 32-мя типами связей между словами. Связи, такие как «синоним», «антоним», «характеристика», «определение» и т.д. Для сравнения, в FreeBase типов связей — более 14-ти тысяч. Но даже эта скромная сеть позволяет получать нетривиальные результаты.
Представим себе, что на вход системы, в качестве обучающего образца, поступила пара вопрос-ответ:
Какого цвета огурец? Огурец зелёного цвета.
и мы желаем, что-бы система правильно ответила на вопрос Какого цвета апельсин?
Как это сделать? Необходимо найти такой путь по сети, который связывает «огурец» и «зелёный». И который можно применить к «апельсину». И сделать это необходимо автоматически. Обилие связей между словами в сети позволяет решить эту задачу следующим образом:
1. зелёный является гипонимом цвета (Викисловарь).
2. Огурец имеет высокочастотную связь с зелёным (согласованные нграммы. Это означает, что в обработанной литературе часто встречалась связь зелёного и огурца «на столе лежали зелёные огурцы»).
3. Следовательно, путь по сети определяется как «огурец <нграмма „характеристика“> ЦЕЛЬ <гипероним (обратный к гипониму)> цвет».
Собственно, задача поиска пути по сети является классической задачей поиска пути по ненаправленному графу. Понятно, что таких путей может быть несколько, и каждый из них приводит не только к нужной нам цели — «зелёный», но и к другим аналогичным словам. Например — жёлтый. Жёлтые огурцы (перезрелые) также встречаются в литературе, хотя и реже, чем зелёные. И жёлтый, разумеется, точно так-же связан со словом «цвет», как и зелёный. Поэтому, приходится проводить взвешивание каждого из путей весовыми коэффициентами так, что-бы цель поиска имела наибольший рейтинг. Немного переформулируя, можно сказать, что мы формируем самообучающуюся сеть, которая в качестве входных сигналов воспринимает не числовые значения, а слова.
Итак, попробуем применить найденный путь к другим аргументам:
Апельсин оказывается оранжевым, море — синим, тучи серыми, а облака — белыми. Трава обычно оказывается зелёной, хотя иногда прорывается и лиловый цвет. Видимо, при накоплении нграмм попались несколько фантастических рассказов.
Но также, океан оказывается глубоким, лужа — мелкой, а семечка — маленькой. Путь универсален, и работает не только для цвета. Путь работает для большинства вопросов, ориентированных на получение значения характеристики «какого цвета/размера/глубины...».
Мы можем использовать нашу сеть для формирования метрики — вычисления степени подобия между различными словами. Что общего между травой и огурцом? Они оба имеют связь со словом «зелёный». Но ещё они имеют связи со словами «кушать», «расти» и многими другими. Следовательно, если вычислить количество совпадающих у двух разных слов связей, можно вычислить степень подобия между этими словами. Даже если в словарях эти слова не представлены и все связи между словами получены в результате накопления статистики.
Как мы можем использовать числовое значение степени подобия между словами? Например, для определения кореферентных связей. Слова «мэр» и «чиновник» часто упоминаются в одинаковом контексте, и поэтому имеют близкую друг-другу структуру связей с другими словами. Мы можем обосновано предположить, что в анализируемом тексте за словами «мэр» и «чиновник» скрывается один и тот-же человек. То есть — установить между ними связь.
Аналогично, встретив в тексте «он пошёл» можно вычислить, что речь идёт об объекте, который ходит — человек, или животное. Или чиновник, потому что чиновник сильно подобен человеку. А встретив в тексте «его закрыли» можно вычислить, что речь идёт о предприятии, или подобных предприятию объектах.
Таким образом, вычисление подобия позволяет проводить отнесение слова с учётом его контекста к одному из известных классов «человек», «предприятие», «место» и т.д., что приближает нас к выделению смысла текста.
Например, такой подход позволяет разделить такие тексты и правильно определить значение слова «она»:
На собрании выступила директор фабрики Соколова. Напоминаем, она открылась в начале мая. и На собрании выступила директор фабрики Соколова. Она сообщила о планах по увеличению продукции.
В рамках проходившей недавно международной конференции по машинной лингвистике «Диалог» проводился смотр систем компьютерной лингвистики, в котором я принимал участие. Моя система разрабатывалась специально под конкурс в течении 1.5 месяцев и была основана на описанной технологии вычисления подобия между словами. В ближайшее время результаты конкурса будут опубликованы.
В любом случае, я хочу обратить особое внимание, что «технологии созрели» и любой интересующийся может буквально за несколько месяцев подойти вплотную к вопросам понимания текста, извлечения смысла. То есть — к экспериментам в области искусственного интеллекта, ранее доступным лишь в академических кругах.
Для успеха нам потребуется несколько составляющих: умение разбирать текст на слова и леммы, умение проводить морфологический и синтаксический анализ, и, самое пожалуй интересное, умение искать в тексте смысл.
Разбор текста
В русском сегменте интернета существуют свободные для некоммерческого использования синтаксические движки, с хорошим качеством решающие задачи морфологического и синтаксического анализа. Я хочу отметить два из них.
Первый, который я использую с большой пользой сам — SDK грамматического словаря русского языка.
Второй — это томита-парсер от Яндекс.
Они содержат словарь, тезаурус, функции разбора текста и обладают достаточно низким порогом вхождения.
Синтаксические движки позволяют превратить любой текст в пригодный для машинной обработки формат. Это может быть дерево синтаксического разбора, по которому можно проследить отношения слов во фразе:
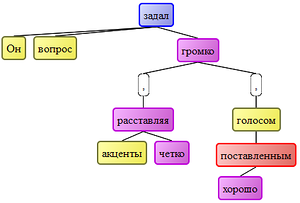
для фразы «Он задал вопрос громко, четко расставляя акценты, хорошо поставленным голосом.» источник
Так и просто вектор индексов нормальных форм слов.
Построение собственной семантической сети
К сожалению, для русского языка в настоящий момент не представлены мощные сети уровня FreeBase (1.9 млрд. связей) да и русский сегмент ДБПедии намного беднее англоязычного. Коммерческие источники, такие, как выверенная вручную сеть, использующаяся в Compreno от ABBYY, любителям также недоступны. Поэтому, сеть придётся формировать самостоятельно.
Нам необходимы — словари, грамматические и смысловые связи между словами.
Словари
Я использовал два основных источника:
Викисловарь и набор словарей с сайта Академик.
Викисловарь даёт нам семантические свойства большинства распространённых слов и связи слов с родственными словами. Позже будет описано, каким образом можно это использовать. На Академике представлены словари синонимов и антонимов — прекрасно дополняющих Викисловарь.
Смысловые связи
С этим сложнее. Смысловые связи определяются в тезаурусах, в том числе — в открывшемся недавно в публичный доступ тезаурусе RuThes, но общая проблема всех тезаурусов — их ограниченность. Слишком мало слов, слишком мало связей. Поэтому связи между словами можно накапливать и самостоятельно — занимаясь набором статистики согласованных и несогласованных нграмм по библиотекам художественной литературы, новостным лентам.
Процесс обработки больших объёмов текста, тем не менее, относительно быстр — 1 Гигабайт текста в однобайтовой кодировке можно обработать менее чем за неделю.
Что получилось в результате?
Сеть, объединяющая большую часть сейчас употребляемых слов русского языка, с 32-мя типами связей между словами. Связи, такие как «синоним», «антоним», «характеристика», «определение» и т.д. Для сравнения, в FreeBase типов связей — более 14-ти тысяч. Но даже эта скромная сеть позволяет получать нетривиальные результаты.
Вывод по аналогии
Представим себе, что на вход системы, в качестве обучающего образца, поступила пара вопрос-ответ:
Какого цвета огурец? Огурец зелёного цвета.
и мы желаем, что-бы система правильно ответила на вопрос Какого цвета апельсин?
Как это сделать? Необходимо найти такой путь по сети, который связывает «огурец» и «зелёный». И который можно применить к «апельсину». И сделать это необходимо автоматически. Обилие связей между словами в сети позволяет решить эту задачу следующим образом:
1. зелёный является гипонимом цвета (Викисловарь).
2. Огурец имеет высокочастотную связь с зелёным (согласованные нграммы. Это означает, что в обработанной литературе часто встречалась связь зелёного и огурца «на столе лежали зелёные огурцы»).
3. Следовательно, путь по сети определяется как «огурец <нграмма „характеристика“> ЦЕЛЬ <гипероним (обратный к гипониму)> цвет».
Собственно, задача поиска пути по сети является классической задачей поиска пути по ненаправленному графу. Понятно, что таких путей может быть несколько, и каждый из них приводит не только к нужной нам цели — «зелёный», но и к другим аналогичным словам. Например — жёлтый. Жёлтые огурцы (перезрелые) также встречаются в литературе, хотя и реже, чем зелёные. И жёлтый, разумеется, точно так-же связан со словом «цвет», как и зелёный. Поэтому, приходится проводить взвешивание каждого из путей весовыми коэффициентами так, что-бы цель поиска имела наибольший рейтинг. Немного переформулируя, можно сказать, что мы формируем самообучающуюся сеть, которая в качестве входных сигналов воспринимает не числовые значения, а слова.
Итак, попробуем применить найденный путь к другим аргументам:
Апельсин оказывается оранжевым, море — синим, тучи серыми, а облака — белыми. Трава обычно оказывается зелёной, хотя иногда прорывается и лиловый цвет. Видимо, при накоплении нграмм попались несколько фантастических рассказов.
Но также, океан оказывается глубоким, лужа — мелкой, а семечка — маленькой. Путь универсален, и работает не только для цвета. Путь работает для большинства вопросов, ориентированных на получение значения характеристики «какого цвета/размера/глубины...».
Вычисление подобия
Мы можем использовать нашу сеть для формирования метрики — вычисления степени подобия между различными словами. Что общего между травой и огурцом? Они оба имеют связь со словом «зелёный». Но ещё они имеют связи со словами «кушать», «расти» и многими другими. Следовательно, если вычислить количество совпадающих у двух разных слов связей, можно вычислить степень подобия между этими словами. Даже если в словарях эти слова не представлены и все связи между словами получены в результате накопления статистики.
Как мы можем использовать числовое значение степени подобия между словами? Например, для определения кореферентных связей. Слова «мэр» и «чиновник» часто упоминаются в одинаковом контексте, и поэтому имеют близкую друг-другу структуру связей с другими словами. Мы можем обосновано предположить, что в анализируемом тексте за словами «мэр» и «чиновник» скрывается один и тот-же человек. То есть — установить между ними связь.
Аналогично, встретив в тексте «он пошёл» можно вычислить, что речь идёт об объекте, который ходит — человек, или животное. Или чиновник, потому что чиновник сильно подобен человеку. А встретив в тексте «его закрыли» можно вычислить, что речь идёт о предприятии, или подобных предприятию объектах.
Таким образом, вычисление подобия позволяет проводить отнесение слова с учётом его контекста к одному из известных классов «человек», «предприятие», «место» и т.д., что приближает нас к выделению смысла текста.
Например, такой подход позволяет разделить такие тексты и правильно определить значение слова «она»:
На собрании выступила директор фабрики Соколова. Напоминаем, она открылась в начале мая. и На собрании выступила директор фабрики Соколова. Она сообщила о планах по увеличению продукции.
Заключительная часть
В рамках проходившей недавно международной конференции по машинной лингвистике «Диалог» проводился смотр систем компьютерной лингвистики, в котором я принимал участие. Моя система разрабатывалась специально под конкурс в течении 1.5 месяцев и была основана на описанной технологии вычисления подобия между словами. В ближайшее время результаты конкурса будут опубликованы.
В любом случае, я хочу обратить особое внимание, что «технологии созрели» и любой интересующийся может буквально за несколько месяцев подойти вплотную к вопросам понимания текста, извлечения смысла. То есть — к экспериментам в области искусственного интеллекта, ранее доступным лишь в академических кругах.










