Эта статья иллюстрирует т. н. компромисс скорости и памяти — правило, которое выполняется во многих областях CS, — на примере разных реализаций хеш-таблиц на Java. Чем больше памяти занимает хеш-таблица, тем быстрее выполняются операции над ней (например, взятие значения по ключу).
Тестировались хеш-мапы с интовыми ключами и значениями.
Мера использования памяти — относительное количество дополнительно занимаемой памяти сверх теоретического минимума для мапы заданного размера. Например, 1000 интовых пар ключ-значение занимают (4 (размер инта) + 4) * 1000 = 8000 байт. Если мапа такого размера занимает 20 000 байт, ее мера использования памяти будет равняться (20 000 — 8000) / 8000 = 1,5.
Каждая реализация была протестирована на 9 уровнях загруженности (load factors). Каждая реализация на каждом уровне прогонялась на 10 размерах, логарифмически равномерно распределенных между 1000 и 10 000 000. Потом показатели использования памяти и средние времена выполнения операций независимо усреднялись: по трем наименьшим размерам («small sizes» на графиках), трем наибольшим (large sizes) и всем десяти от 1000 до 10 000 000 (all sizes).
Реализации:
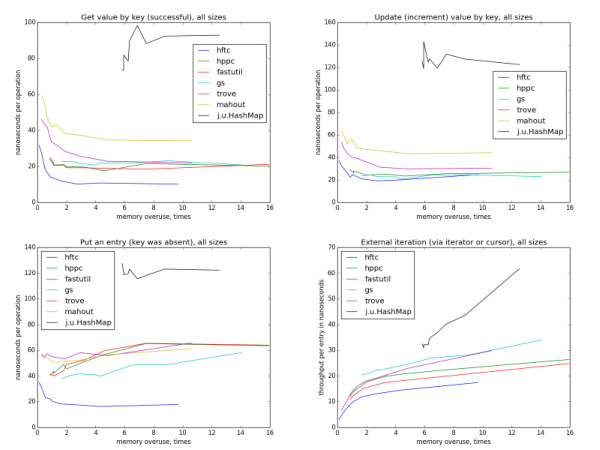
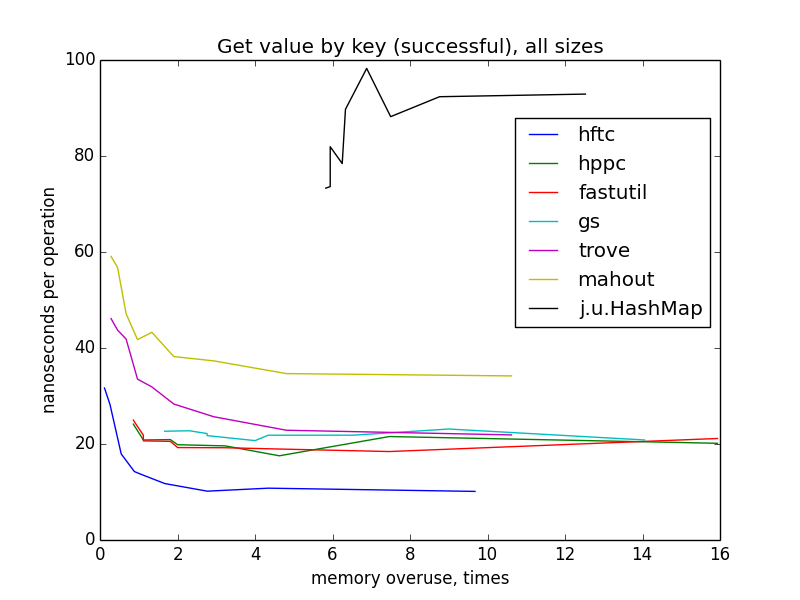
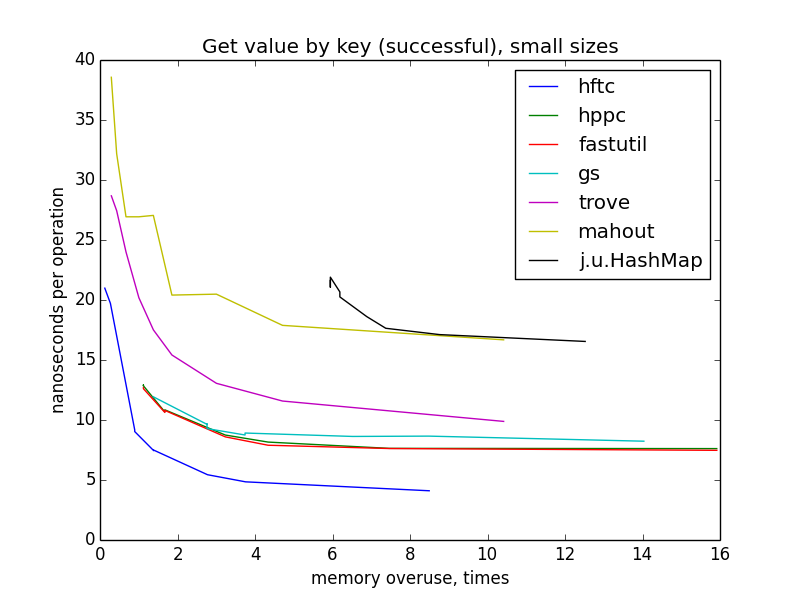
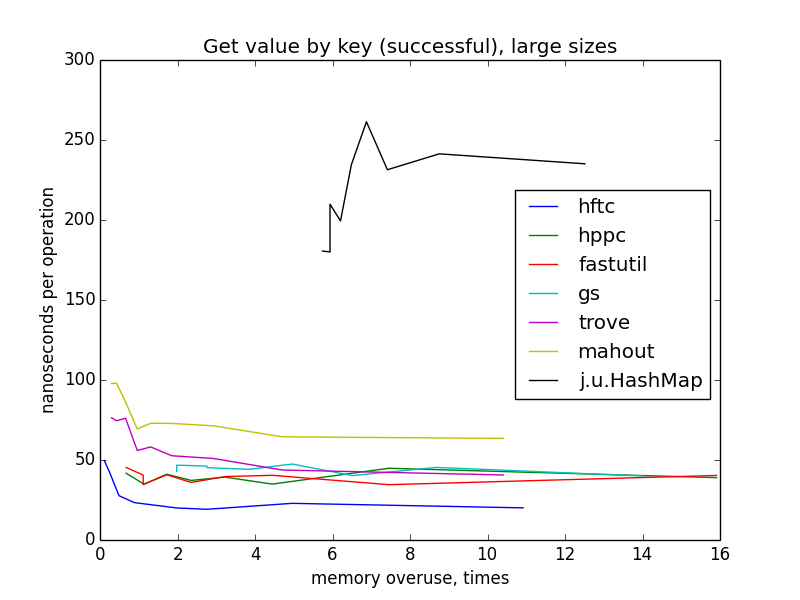
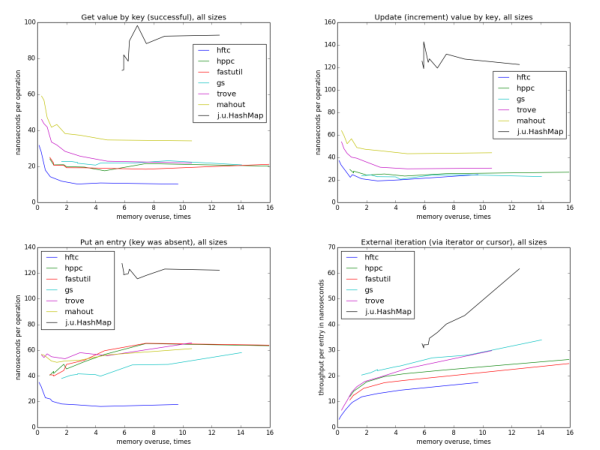
Только глядя на эти картинки, можно предположить, что HFTC, Trove и Mahout с одной стороны, fastutil, HPPC и GS с другой используют один алгоритм хеширования. (На самом деле это не совсем так.) Более разреженные хеш-таблицы в среднем проверяют меньше слотов, прежде чем найти ключ, поэтому происходит меньше чтений из памяти, поэтому операция выполняется быстрее. Можно заметить, что на маленьких размерах самые разгруженные мапы — они же и самые быстрые для всех шести реализаций, но на больших размерах и при усреднении по всем размерам начиная с показателя переиспользования памяти ~4 ускорения не видно. Это происходит потому, что если общий размер мапы превышает вместимость кеша какого-нибудь уровня, кеш-промахи учащаются по мере дальнейшего роста размера мапы. Этот эффект компенсирует теоретический выигрыш от меньшего количества проверяемых слотов.
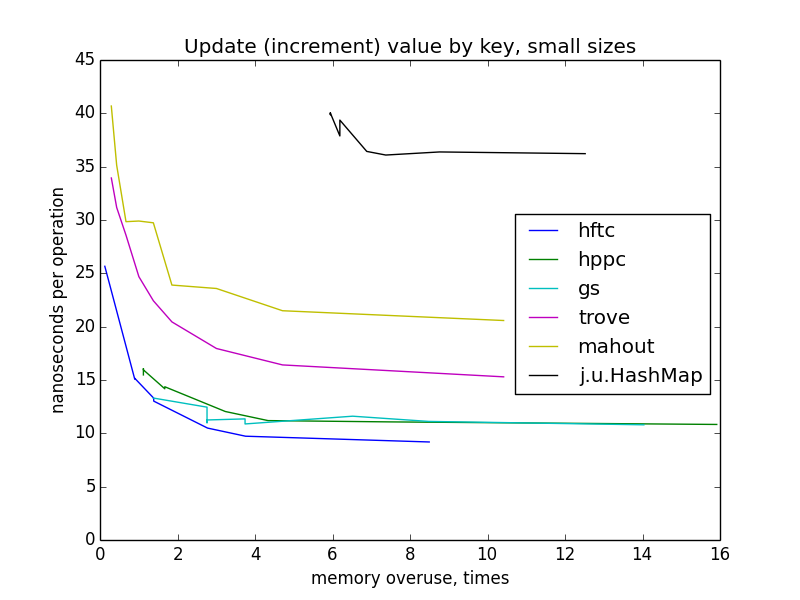
Обновление довольно похоже на взятие по ключу. Реализация fastutil не тестировалась, потому что в ней нет специального оптимизированного метода для этой операции (по этой же причине некоторые реализации отсутствуют при тестировании других операций).
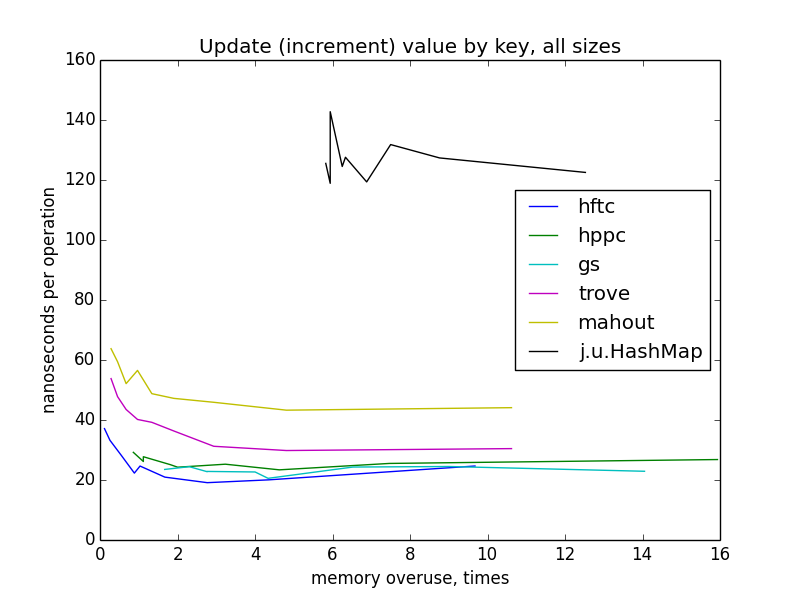
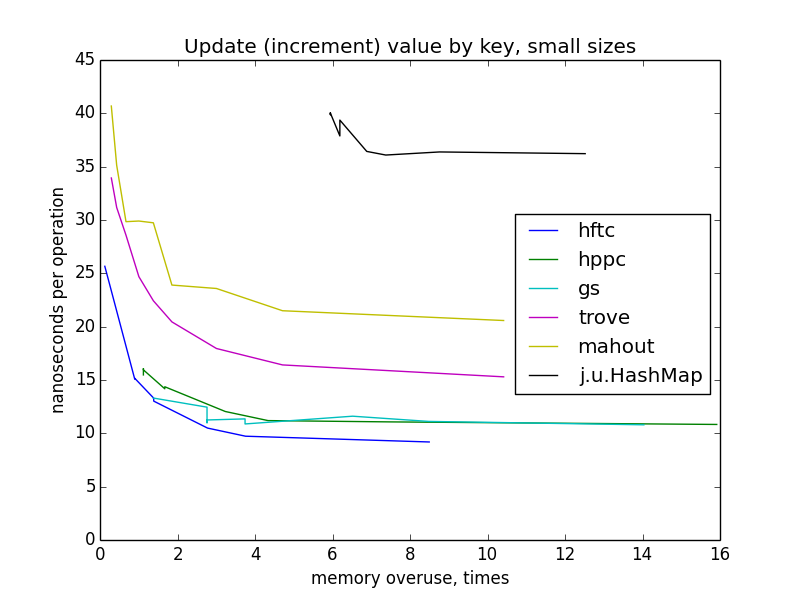
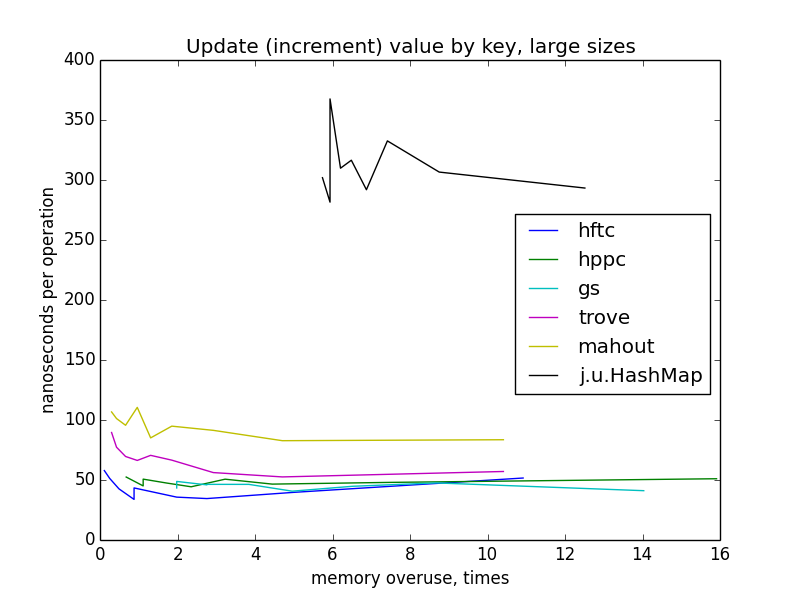
Для замеров этой операции, мапы заполнялись с нуля до целевого размера (1000 — 10 000 000). Перестроения хеш-таблиц не должны были случаться, потому что мапы были инициализированы целевым размером в конструкторах.
На маленьких размерах графики по-прежнему похожи на гиперболы, но у меня нет четкого объяснения такого резкого изменения картинки при переходе к большим размерам и разницы между HFTC и другими примитивными реализациями.
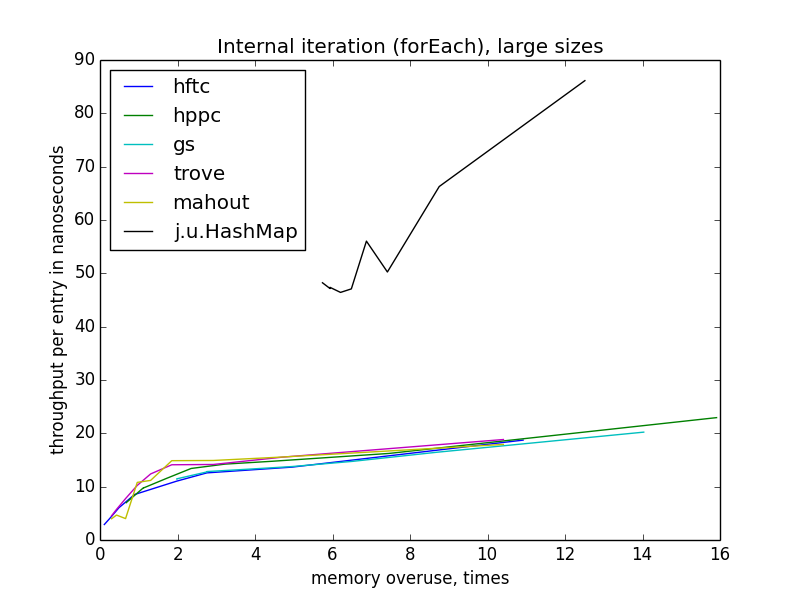
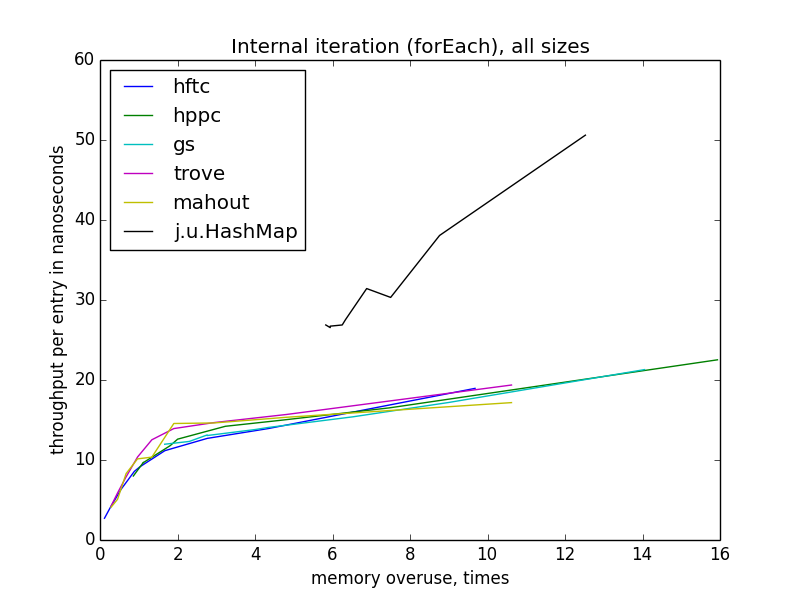
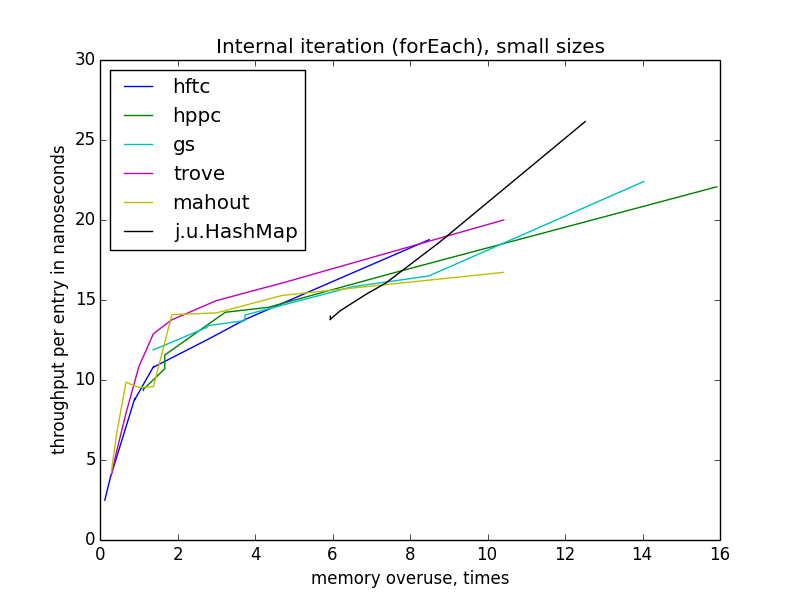
Итерация становится медленнее с уменьшением эффективности использования памяти, в отличие от операций по отдельным ключам. Еще интересно, что для всех реализаций с открытым хешированием скорость зависит только от показателя переиспользования памяти, а не теоретической загруженности таблицы, потому что она различается для разных реализаций на одном уровне переиспользования. Также, в отличие от других операций, скорость forEach практически не зависит от размера таблицы.
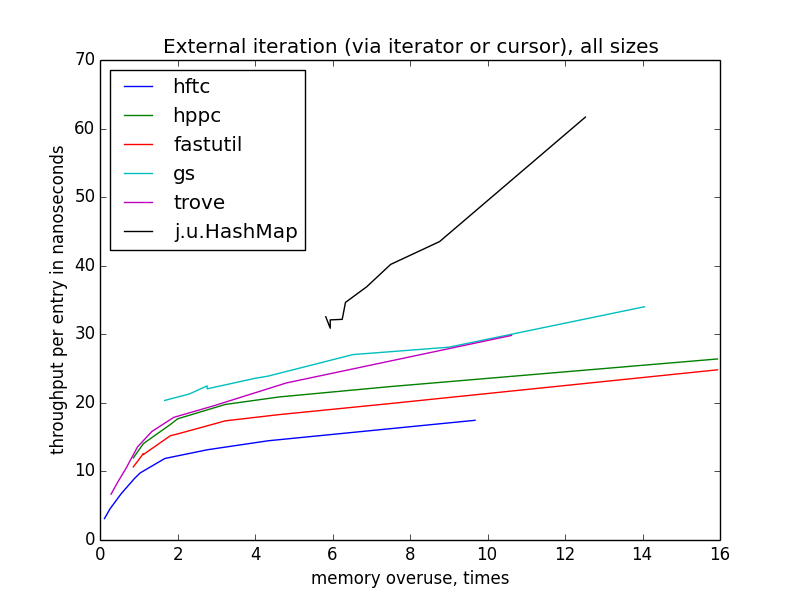
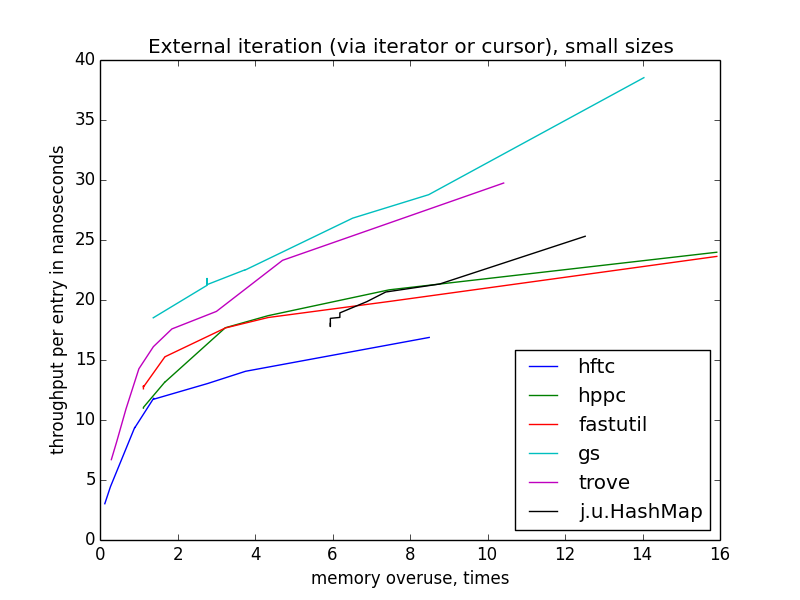
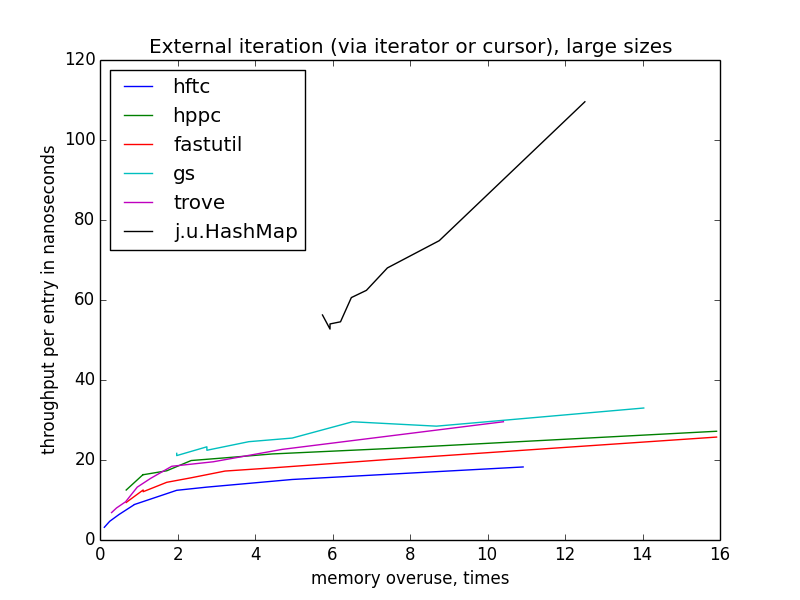
Скорость внешней итерации пляшет куда больше, чем внутренней, потому что тут больше пространства для оптимизаций (точнее сказать, больше возможностей сделать что-то неоптимально). HFTC и Trove используют собственные интерфейсы, другие реализации — обычный
Сырые результаты замеров, по которым были построены картинки в этом посте. Там же, в описании, есть ссылка на код бенчмарков и информация о среде выполнения.
P. S. Эта статья на английском.
Как мерялось
Тестировались хеш-мапы с интовыми ключами и значениями.
Мера использования памяти — относительное количество дополнительно занимаемой памяти сверх теоретического минимума для мапы заданного размера. Например, 1000 интовых пар ключ-значение занимают (4 (размер инта) + 4) * 1000 = 8000 байт. Если мапа такого размера занимает 20 000 байт, ее мера использования памяти будет равняться (20 000 — 8000) / 8000 = 1,5.
Каждая реализация была протестирована на 9 уровнях загруженности (load factors). Каждая реализация на каждом уровне прогонялась на 10 размерах, логарифмически равномерно распределенных между 1000 и 10 000 000. Потом показатели использования памяти и средние времена выполнения операций независимо усреднялись: по трем наименьшим размерам («small sizes» на графиках), трем наибольшим (large sizes) и всем десяти от 1000 до 10 000 000 (all sizes).
Реализации:
- Higher Frequency Trading Collections (HFTC)
- High Performance Primitive Collections (HPPC)
- fastutil collections
- Goldman Sachs Collections (GS)
- Trove Collections
- Mahout Collections
java.util.HashMapдля сравнения. Все остальные реализации — примитивные специализации, аHashMapбоксит значения, поэтому сравнение заведомо нечестное, но тем не менее.
Взятие значения по ключу (успешный поиск)
Только глядя на эти картинки, можно предположить, что HFTC, Trove и Mahout с одной стороны, fastutil, HPPC и GS с другой используют один алгоритм хеширования. (На самом деле это не совсем так.) Более разреженные хеш-таблицы в среднем проверяют меньше слотов, прежде чем найти ключ, поэтому происходит меньше чтений из памяти, поэтому операция выполняется быстрее. Можно заметить, что на маленьких размерах самые разгруженные мапы — они же и самые быстрые для всех шести реализаций, но на больших размерах и при усреднении по всем размерам начиная с показателя переиспользования памяти ~4 ускорения не видно. Это происходит потому, что если общий размер мапы превышает вместимость кеша какого-нибудь уровня, кеш-промахи учащаются по мере дальнейшего роста размера мапы. Этот эффект компенсирует теоретический выигрыш от меньшего количества проверяемых слотов.



Обновление (инкремент) значения по ключу
Обновление довольно похоже на взятие по ключу. Реализация fastutil не тестировалась, потому что в ней нет специального оптимизированного метода для этой операции (по этой же причине некоторые реализации отсутствуют при тестировании других операций).


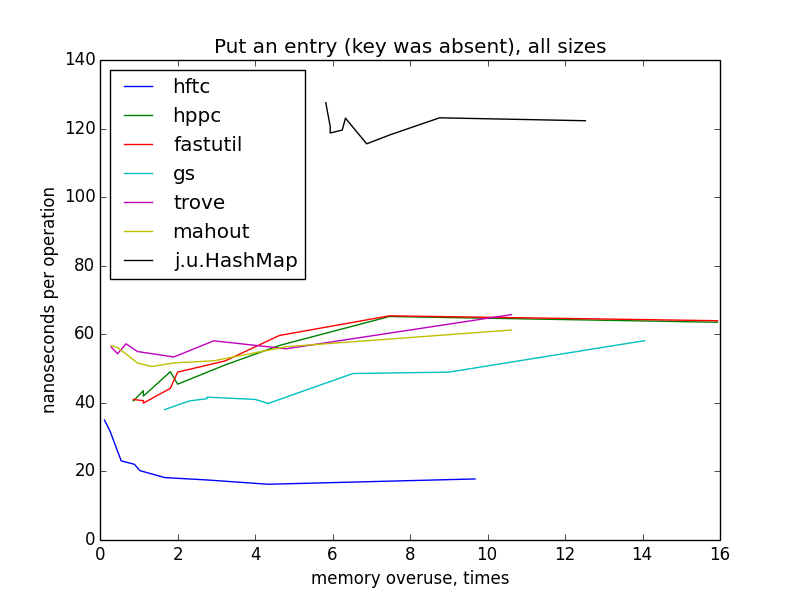
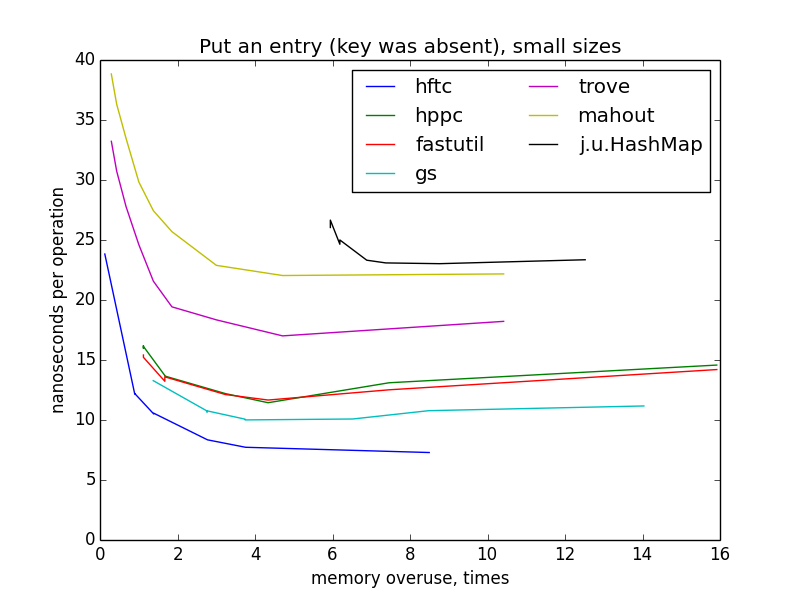
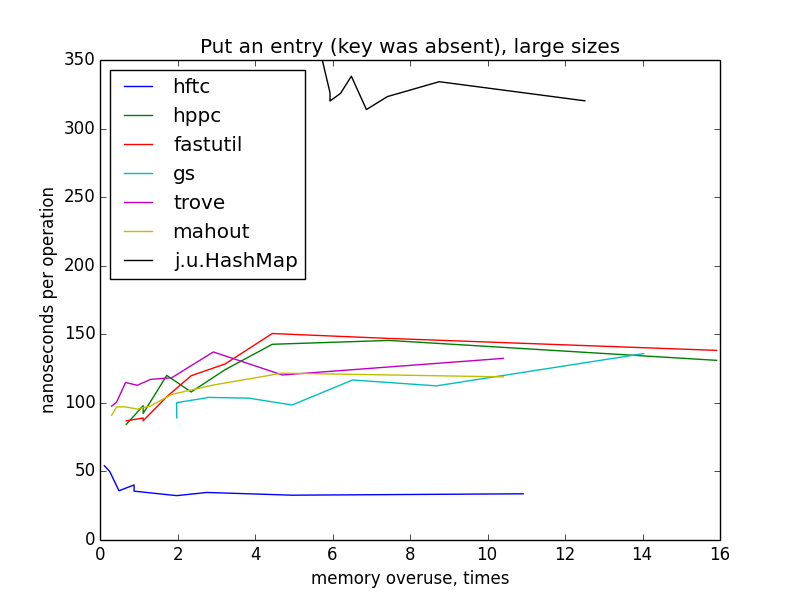
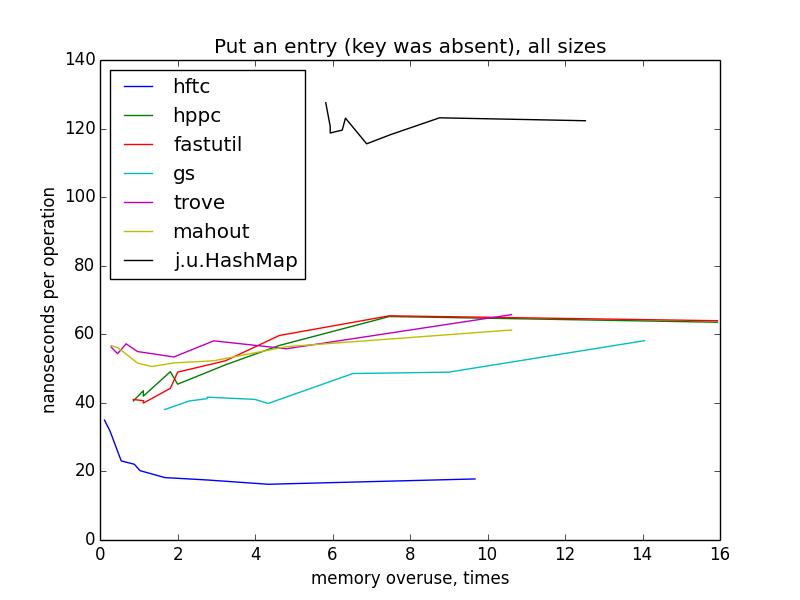
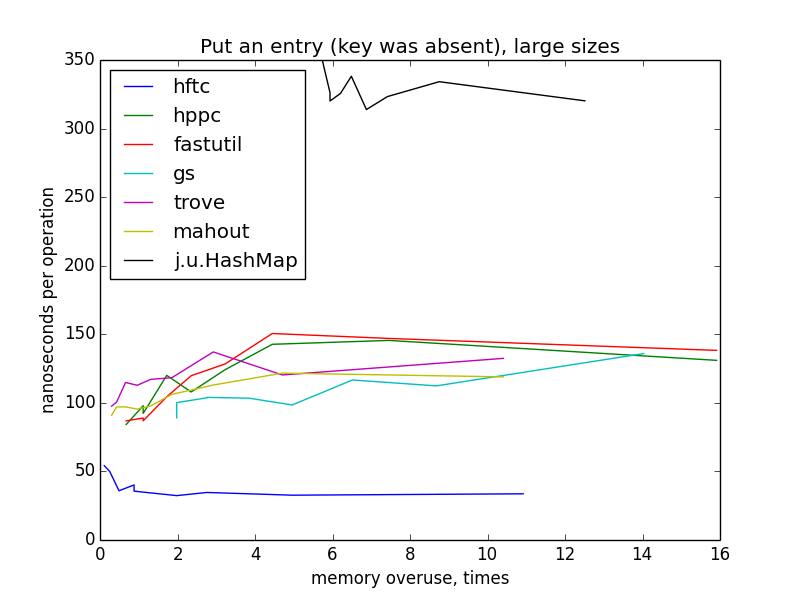
Запись пары ключ-значение (ключ отсутствовал в мапе)
Для замеров этой операции, мапы заполнялись с нуля до целевого размера (1000 — 10 000 000). Перестроения хеш-таблиц не должны были случаться, потому что мапы были инициализированы целевым размером в конструкторах.
На маленьких размерах графики по-прежнему похожи на гиперболы, но у меня нет четкого объяснения такого резкого изменения картинки при переходе к большим размерам и разницы между HFTC и другими примитивными реализациями.

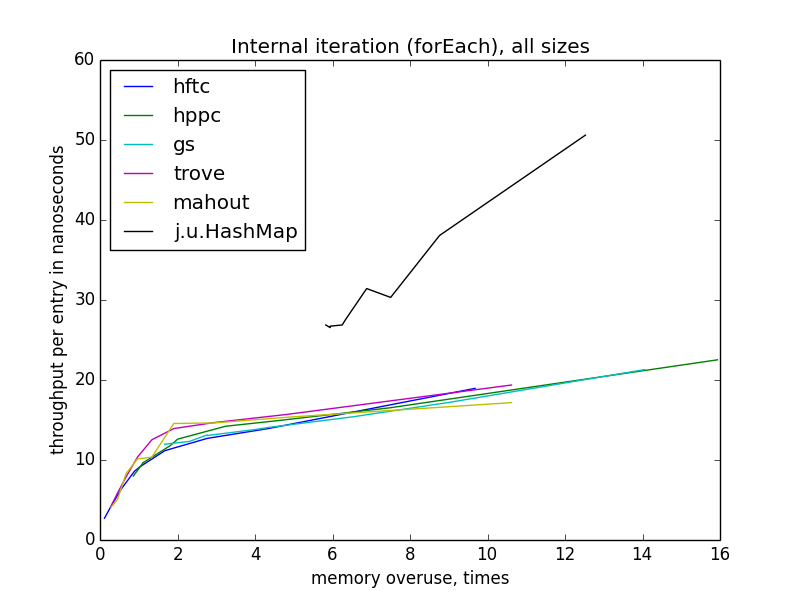
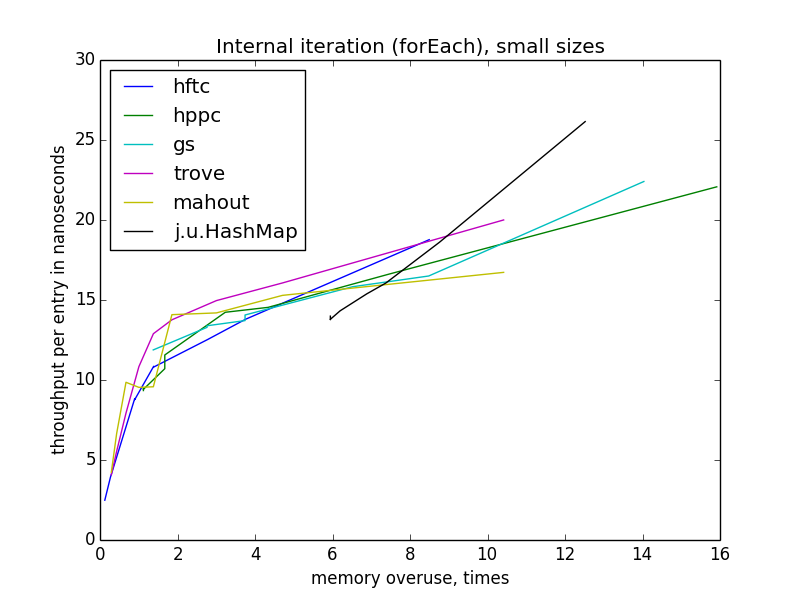
Внутренняя итерация (forEach)
Итерация становится медленнее с уменьшением эффективности использования памяти, в отличие от операций по отдельным ключам. Еще интересно, что для всех реализаций с открытым хешированием скорость зависит только от показателя переиспользования памяти, а не теоретической загруженности таблицы, потому что она различается для разных реализаций на одном уровне переиспользования. Также, в отличие от других операций, скорость forEach практически не зависит от размера таблицы.

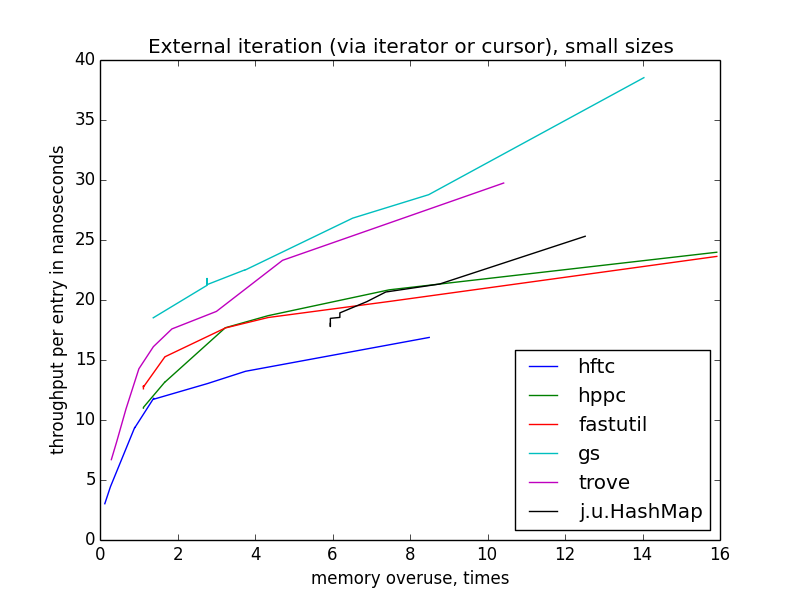
Внешняя итерация (через итератор или курсор)
Скорость внешней итерации пляшет куда больше, чем внутренней, потому что тут больше пространства для оптимизаций (точнее сказать, больше возможностей сделать что-то неоптимально). HFTC и Trove используют собственные интерфейсы, другие реализации — обычный
java.util.Iterator.

Сырые результаты замеров, по которым были построены картинки в этом посте. Там же, в описании, есть ссылка на код бенчмарков и информация о среде выполнения.
P. S. Эта статья на английском.








