Вместо введения
Решил немного дополнить отчет, который составлял еще будучи студентом. Прошло время и, как говорится, прогресс не стоит на месте. Технологии распознавания речи динамически развиваются. Что-то появляется, что-то исчезает. Вашему вниманию представляю самые известные речевые движки, которые может использовать разработчик в своем продукте на основе лицензионного соглашения. Буду рад замечаниям и дополнениям.
Содержание:
1. Поиск и анализ цветового пространства оптимального для построения выделяющихся объектов на заданном классе изображений
2. Определение доминирующих признаков классификации и разработка математической модели изображений мимики"
3. Синтез оптимального алгоритма распознавания мимики
4. Реализация и апробация алгоритма распознавания мимики
5. Создание тестовой базы данных изображений губ пользователей в различных состояниях для увеличения точности работы системы
6. Поиск оптимальной аудио-системы распознавания речи на базе открытого исходного кода
7. Поиск оптимальной системы аудио распознавания речи с закрытым исходным кодом, но имеющими открытые API, для возможности интеграции
8. Эксперимент интеграции видео расширения в систему аудио-распознавания речи с протоколом испытаний
Цели:
Определить наиболее оптимальную аудио-систему распознавания речи (речевой движок) на базе закрытого исходного кода, то есть лицензии которой не подходит под определение открытого ПО.
Задачи:
Определить аудио-системы распознавания речи, которые попадают под понятие закрытого исходного кода. Рассмотреть наиболее известные варианта речевых систем преобразования голоса в текст, для перспектив интеграции видео-модуля в наиболее оптимальную голосовую библиотеку, которая имеет открытое API для совершения данной операции. Сделать выводы целесообразности использования аудио-систем распознавания речи на базе закрытого исходного кода под наши цели и задачи.

Введение
Реализация своей собственной системы распознавания речи является очень сложной, трудоемкой и ресурсозатратной задачей, которую сложно выполнить в рамках данной работы. Поэтому предполагается интегрировать представленную технологию видео-идентификации в системы распознавания речи, которые имеют для этого специальные возможности. Так как системы распознавания речи с закрытым исходным кодом реализованы более качественно и точность распознавания речи в них выше, то поэтому интеграция нашей видео-разработки в их работу следует считать более перспективным направлением, по сравнению с аудио системами распознавания речи на базе открытого исходного кода. Однако же необходимо иметь в виду тот факт, что системы распознавания речи с закрытым исходным кодом часто не имеют должной документации для возможности интеграции сторонних решений в их работу или же это направление является платным, то есть необходимо покупать специальную лицензию на использование речевых технологий, представленных лицензиантом.
Закрытый исходный код (Proprietary software)
Что касается определения — закрытый исходный код, то необходимо сказать – оно означает, что распространяются только бинарные (откомпилированные) версии программы и лицензия подразумевает отсутствие доступа к исходному коду программы, что затрудняет создание модификаций программы. Доступ к исходному коду третьим лицам обычно предоставляется при подписании соглашения о неразглашении. [1].
ПО с закрытым исходным кодом является проприетарным (собственническим) ПО. Однако необходимо иметь в виду, что фраза «закрытый исходный код» можно трактовать по-разному. Так как она может подразумевать лицензии, в которых исходный код программ недоступен. Однако если считать ее антонимом открытого кода, то она относится к программному обеспечению, не подходящему под определение лицензии открытого ПО, что имеет несколько другой смысл. Одним из таковых спорных моментов стало то, как трактовать понятия интерфейса программирования приложений.
Интерфейс программирования приложений (API)
С 24 марта 2004 года на основании решения Европейской комиссии для программ с закрытым исходным кодом в результате судебного процесса появилось определение API, которое расшифровывается как интерфейс программирования приложений или как интерфейс прикладного программирования (с англ. яз. — application programming interface). API — набор готовых классов, процедур, функций, структур и констант, предоставляемых приложением (библиотекой, сервисом) для использования во внешних программных продуктах. Используется программистами для написания всевозможных приложений.
API определяет функциональность, которую предоставляет программа (модуль, библиотека), при этом API позволяет абстрагироваться от того, как именно эта функциональность реализована.
Если программу (модуль, библиотеку) рассматривать как чёрный ящик, то API — это множество «ручек», которые доступны пользователю данного ящика, которые он может вертеть и дёргать.
Программные компоненты взаимодействуют друг с другом посредством API. При этом обычно компоненты образуют иерархию — высокоуровневые компоненты используют API низкоуровневых компонентов, а те, в свою очередь, используют API ещё более низкоуровневых компонентов.
По такому принципу построены протоколы передачи данных по Интернет. Стандартный стек протоколов (сетевая модель OSI) содержит 7 уровней (от физического уровня передачи бит до уровня протоколов приложений, подобных протоколам HTTP и IMAP). Каждый уровень пользуется функциональностью предыдущего уровня передачи данных и, в свою очередь, предоставляет нужную функциональность следующему уровню.
Важно заметить, что понятие протокола близко по смыслу к понятию API. И то и другое является абстракцией функциональности, только в первом случае речь идёт о передаче данных, а во втором — о взаимодействии приложений. [2].
Dragon Mobile SDK
Сам инструментарий называется NDEV. Чтоб получить необходимый код и документацию, надо зарегистрироваться на сайте в «программе сотрудничества». Сайт:
dragonmobile.nuancemobiledeveloper.com/public/index.php [5].
Инструментарий (SDK) содержит в себе компоненты и клиента, и сервера. Диаграмма иллюстрирует их взаимодействие на верхнем уровне:
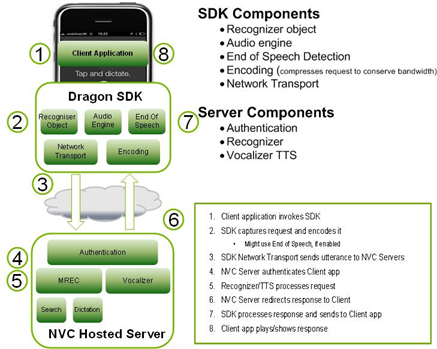
Рис. 1. Принцип работы технологии Dragon Mobile SDK
Комплект Dragon Mobile SDK состоит из различных примеров кода и шаблонов проектов, документации, а также программной платформы (фреймворка), упрощающей интеграцию речевых сервисов в любое приложение.
Платформа Speech Kit framework позволяет легко и быстро добавлять в приложения сервисы распознавания и синтеза (TTS, Text-to-Speech) речи. Данная платформа также обеспечивает доступ к компонентам обработки речи, находящимся на сервере, через асинхронные «чистые» сетевые API, сводя к минимуму накладные расходы и потребляемые ресурсы.
Платформа Speech Kit является полнофункциональным высокоуровневым «фреймворком», который автоматически управляет всеми низкоуровневыми сервисами.
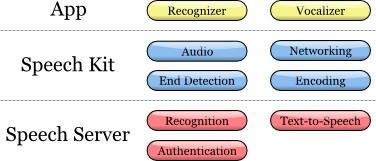
Рис. 2. Архитектура Speech Kit
Платформа выполняет несколько согласованных процессов:
1. Осуществляет полное управление аудио системой для записи и воспроизведения
2. Сетевой компонент управляет подключениями к серверу и автоматически восстанавливает соединения с истекшим временем ожидания при каждом новом запросе
3. Детектор окончания речи определяет, когда пользователь закончил говорить, и при необходимости автоматически останавливает запись
4. Кодирующий компонент сжимает и распаковывает потоковую аудиозапись, снижая требования к полосе пропускания и уменьшая среднее время задержки.
Система серверов отвечает за большинство операций, входящих в цикл обработки речи. Процесс распознавания или синтеза речи выполняется целиком на сервере, обрабатывая или синтезируя аудио-поток. Кроме того, сервер осуществляет аутентификацию в соответствии с конфигурацией разработчика.
Платформа Speech Kit является сетевым сервисом и нуждается в некоторых базовых настройках перед началом использования классов распознавания или синтеза речи.
Данная установка выполняет две основные операции:
Во-первых, она определяет и авторизует ваше приложение.
Во-вторых, — устанавливает соединение с речевым сервером, — это позволяет производить быстрые запросы на речевую обработку и, следовательно, повышает качество обслуживания пользователей.
Распознавание речи
Технология распознавания позволяет пользователям диктовать вместо того, чтобы печатать там, где обычно требуется ввод текста. Распознаватель речи выдает список текстовых результатов. Он никак не привязан к какому-либо объекту пользовательского интерфейса (UI), поэтому отбор наиболее подходящего результата и выборка альтернативных результатов остается на усмотрение пользовательского интерфейса каждого приложения.

Рис. 3. Процесс распознавания речи
В работе нашего приложения на ОС Android нам удалось интегрировать решение от Dragon Mobile SDK. Пионер отрасли распознавания речи показал отличные результаты, особенно на английском языке. Однако большим его недостатком следует считать ограниченный бесплатный функционал: только 10 тысяч запросов в сутки — которых для работы нашего приложения очень скоро стало недостаточно. За больший доступ следует платить.
Google Speech Recognition API

Рис. 4. Логотип Google Voice Search
Это продукт компании Google, который позволяет вводить голосовой поиск с помощью технологии распознавания речи. Технология интегрирована в мобильные телефоны и компьютеры, где можно ввести информация с помощью голоса. С 14 июня 2011 года Google объявила об интеграции речевого движка в Google Search и с тех пор он работает в стабильном режиме с этого времени. Эта технология на персональных компьютерах поддерживается только браузером Google Chrome. Функция включена по умолчанию в сборках dev-канала, но может быть включена вручную добавлением командного флага. Есть также функция голосового управления для введения речевых команд на телефонах с ОС Android.
Первоначально Google Voice Search — поддерживал короткие поисковые запросы длиной 35-40 слов. Необходимо было для отправки запроса включать и выключать микрофон, что было очень не естественно для использования (такая функция еще осталось в строке поиска Google, нужно нажать лишь на микрофон). Однако, в конце февраля 2013 года в браузер Chrome была добавлена возможность распознавания непрерывной речи и фактически Google Voice Search трансформировался в Speech Input (можно попробовать технологию на примере набора текста в Google Translate). Технологию можно экспериментально протестировать например также здесь. Ознакомиться с полной документацией можно здесь. Заметим лишь, что если раньше многие разработчики грешили тем, что незаконно с помощью различных уловок вклинивались в канал распознавания Google Speech API, то сейчас во время частых изменений API с мая 2014 года процесс доступа к API фактически стал легализован, так как для работы с базой данных системы распознавания речи достаточно зарегистрировать учетную запись в Google Developers и потом можно работать с системой в рамках правового поля.
Voice Search по умолчанию поставляется со следующими сервисами: Google, Википедия, YouTube, Bing, Yahoo, DuckDuckGo и Wolfram|Alpha и другими. Вы также можете добавить собственные поисковые системы. Расширение также добавляет кнопку голосового ввода для всех сайтов с использованием поисковых форм HTML5. Для работы расширения необходим микрофон. Речевой ввод весьма экспериментальный, так что не удивляйтесь, если он не сработает. [3].
Для этого, чтобы использовать технологию Google Voice Search необходимо сделать следующее:
Необходимо сделать POST запрос на адрес (сейчас он часто меняется — например, в мае месяце было три изменения и поэтому к этому надо быть готовым) со звуковыми данными в формате FLAC или Speex. Реализовывали демонстрацию распознавания WAVE-файлов с помощью C#. Количество ограничений запросов в сутки не замечали. Был риск с 10 000 знаками, как у многих других систем распознавания речи, но такие значения экспериментальным образом было нами доказано, можно преодолевать ежедневно.
Останавливаться на том, как работает данная технология специально не буду. Очень много статей имеется в сети, в том числе на хабре. Замечу лишь, что системы распознавания речи имеют практически схожий принцип работы, который был представлен в пункте выше на примере Nuance.
Yandex Speech Kit

Рис. 5. Лого Yandex Speech Kit
Сразу замечу, что сам лично я с данной библиотекой не работал. Расскажу лишь об опыте программиста, который работал с нами. Он говорил, что очень тяжелая для его восприятия документация и система имеет ограничение по количеству запросов: 10 000 в сутки, поэтому в итоге мы не стали использовать базу данных от Яндекса. Хотя по уверению разработчиков — этот инструментарий является номером 1 для русского языка и, что исследовательская группа компании, которая работала одна в Швейцарии, другая в Москве смогла сделать технологический прорыв в этой области. Однако с таким решением достаточно тяжело выходить на международный рынок по словам Григория Бакунова, так как «многое в области распознавания речи с точки зрения патентования принадлежит известной Nuance и Яндекс одним из последних сумел зацепиться за вагон уходящего вперед поезда развития систем распознавания речи.»
Краткое описание технологии: api.yandex.ru/speechkit/
Документация для Android: api.yandex.ru/speechkit/generated/android/html/index.html
Документация для iOS: api.yandex.ru/speechkit/generated/ios/html/index.html
Скачать же библиотеки можно на портале Технологий «Яндекса»: api.yandex.ru/speechkit/downloads/
Microsoft Speech API

Рис. 6. Лого Microsoft Speech API
Майкрософт тоже в последнее время стал активно развивать речевые технологии. Особенно после анонсирования голосового ассистента Cortana и разработки автоматический технологии синхронного теле-перевода с английского на немецкий язык и наоборот для Skype
На текущий момент существуют 4 варианта использования:
1. Для Windows и Windows Server 2008. Можно добавить речевой движок для Windows приложения используя управляемый или нативный код, который можно взять с API и управлять речевым движком, который встроен в Windows и Windows Server 2008.
2. Speech Platforms. Встраивание платформы в приложения, которые используют распространяемые Microsoft диструбутивы (языковые пакеты с функцией распознавания речи или же средства перевода текста в речь).
3. Embedded. Встроенные решения, которые позволяют человеку взаимодействовать с устройствами используя голосовые команды. Например управление автомобилями Форд с помощью голосовых команд в ОС WIndows Automotive
4. Services. Разработка приложения с речевыми функциями, которые можно использовать в реальном времени, тем самым освобождая себя от создания, обслуживания и модернизации инфраструктуры речевых решений.
Microsoft Speech Platform (есть SDK)
После установки – можно посмотреть справку по следующему пути
И также нужно ставить еще Runtime (ссылка)
а также Runtime Languages (Version 11). Т.е. для каждого языка нужно скачать и установить словарь. Я видел 2 версии словаря для английского и русского языков.
Системные требования (для SDK)
Поддержка ОС
Windows 7, Windows Server 2008, Windows Server 2008 R2, Windows Vista
Разработка и поддержка
• Windows Vista или позднее
• Windows 2003 Server или позднее
• Windows 2008 Server или позднее
Развертывание поддерживается на:
• Windows 2003 Server или позднее
• Windows 2008 Server или позднее
Плюсы:
1) Готовая технология, бери и пользуйся! (есть SDK)
2) Поддержка от Майкрософт
Минусы:
1) нет отрыва от потенциальных конкурентов
2) как я понял – можно развернуть только на серверной Виндоус (Windows 2003 Server, Windows 2008 Server or later)
3) разработка под Виндоус 8 не анонсирована, только Виндоус 7 пока и ранние версии Виндоус
Использование Microsoft Speech API 5.1 для синтеза и распознавания речи
Статья как работать с АПИ
Установка (только для Windows XP), я так понимаю Speech API 5.1 он теперь входит в Microsoft Speech Platform (v 11), поэтому имеет смысл ознакомиться со статьей.
Примеры проектов по работе с Microsoft Speech API
MSDN ссылки про работу с Microsoft.Speech.dll
1. Как начать работать с системой распознавания речи (Microsoft.Speech)
2. Речевой движок распознавания речи. Загрузка грамматики. Методы.
Примеры:
C#, Разговоры с компом или System.Speech
Краткая статья как юзать System.Speech. Автор указывает на необходимость наличия английской версии Windows Vista или 7.
Распознавание речи с C# – Диктовка и пользовательская грамматика
Туториал, как использовать системные классы Майкрософт для задач аудио-распознавания (голос в текст), автор также сделал в своем блоге пост для обратной задачи речь в текст.
Проект (WinForms) по туториалу запускается и собирается. Там есть распознавание 20 секундного интервала. И распознавание по узкому словарю для управления софтом — Choices(«Calculator», «Notepad», «Internet Explorer», «Paint»); Если говорить фразы «start calculator» и т.п. то запускается соответствующий софт.
C# Speech to Text
Клиент на WPF.
Цель этой статьи дать Вам небольшое представление о способностях системы. В деталях рассмотреть как работают классы речевого движка. Также можно найти всю документацию MSDN здесь.
Создание грамматики в .NET
Примеры работы с классом GrammarBuilder
Microsoft .NET Speech API позволяет быстро и легко создать приложения, которые дадут преимущества для взаимодействия с исследовательским центром Майкрософт, который специализируется на распознавании речи. Можно построить грамматические процессы и формы для работы. В этой статье пример как можно все это реализовать. на языке программирования C#.
Speech for Windows Phone 8
Здесь рассматриваются аспекты программирования аудио-распознавания под Windows Phone 8.
Заключение
Таким образом, рассмотрев самые распространенные системы распознавания речи с закрытым исходным кодом необходимо заметить, что по своей библиотеке данных наиболее точным следует считать продукт на базе Dragon NaturallySpeaking. Он более всего подходит для задач распознавания на базе нашего визуального мобильного расширения (так как имеет хорошую документацию и простой код API для встраивания). Однако необходимо заметить, что данный инструментарий отличается очень сложной системой лицензирования, порядком и правилами использования данной технологии. Поэтому возникает сложность реализации на Dragon Mobile SDK пользовательского продукта.
Следовательно, в таком случае более правильным, для наших целей и задач следует считать использование речевого инструментария Google, который более встраиваемый и быстрый за счет больших вычислительных мощностей по сравнению с Dragon Mobile SDK. Также преимуществом распознавания речи от Google стало отсутствие ограничений по количеству запросов в сутки (у многих систем распознавания речи с закрытым исходным кодом есть ограничение 10 000 запросов). Также данная компания стала активно стремиться развивать свой речевой движок на базе лицензионного соглашения. Еще раз напомню в мае месяце 2014 года началась чехарда частой смены API от корпорации и для того, чтобы координировать процесс необходимо иметь статус GoogleDevelopers.
Большим достоинством систем распознавания с закрытым исходным кодом (но открытым API для разработчиков), по сравнению с аудио-системами распознавания речи с открытым исходным кодом является высокая точность (за счет огромных библиотек баз данных) и скорость распознавания речи, поэтому их использование для решения нашей задачи является актуальным направлением.
Список литературы
1) Frequently Asked Questions (and Answers) about Copyright: www.chillingeffects.org/copyright/faq.cgi#QID805
2) Stoughton, Nick (April 2005). «Update on Standards» (PDF). USENIX. Retrieved 2009-06-04.
3) Kai Fu Li, Speech Input API Specification. Editor's Draft 18 October 2010 Latest Editor's Draft: dev.w3.org… Editors: Satish Sampath, Google Inc. Bjorn Bringert, Google Inc.
4) Голосовой поиск в Google Chrome: habrahabr.ru/post/111201
5) Официальная страница Dragon Mobile SDK: dragonmobile.nuancemobiledeveloper.com/public/index.php
Продолжение следует








