Комментарии 27
У меня тоже есть свой велосипед, так что несколько каверзных вопросов:
1. Что с поддержкой асинхронных тестов?
2. Что с возможностью останавливать дебаггер в месте падения?
3. Как отключить вывод в отчёте информации о пройденных тестах? Это бесполезная информация, которая захламляет отчёт.
4. Как быстро найти код упавшего теста? Желательно сразу в IDE.
5. Как посмотреть стектрейс упавшего теста?
1. Что с поддержкой асинхронных тестов?
2. Что с возможностью останавливать дебаггер в месте падения?
3. Как отключить вывод в отчёте информации о пройденных тестах? Это бесполезная информация, которая захламляет отчёт.
4. Как быстро найти код упавшего теста? Желательно сразу в IDE.
5. Как посмотреть стектрейс упавшего теста?
1. Поддержки асинхронных тестов на данный момент корректной нет. Можно использовать асинхронный запрос и тестирование результата в методе библиотеки.
В будущем думаю добавить возможность тестирования асинхронных запросов с помощью promises
2. Не задумывался на данной возможностью, но реализовать такую поддержку можно добавив дополнительный параметр в конфигурацию. Спасибо =)
3. Информация о пройденных тестах на данный момент не отключается
4. Код упавшего теста можно найти, например по его описанию + группе
5. Аналогично не занимался данной проблемой. При необходимости можно немного модифицировать логику работы библиотеки следующим образом —
Здесь github.com/xnimorz/YATS/blob/master/yats.js#L120 добавляем создание переменной Error и забираем его stackTrace — При необходимости можем удалить ненужные вызовы и представить для пользования корректный stackTrace.
В будущем думаю добавить возможность тестирования асинхронных запросов с помощью promises
2. Не задумывался на данной возможностью, но реализовать такую поддержку можно добавив дополнительный параметр в конфигурацию. Спасибо =)
3. Информация о пройденных тестах на данный момент не отключается
4. Код упавшего теста можно найти, например по его описанию + группе
5. Аналогично не занимался данной проблемой. При необходимости можно немного модифицировать логику работы библиотеки следующим образом —
Здесь github.com/xnimorz/YATS/blob/master/yats.js#L120 добавляем создание переменной Error и забираем его stackTrace — При необходимости можем удалить ненужные вызовы и представить для пользования корректный stackTrace.
1. Не очень понятно как тут помогут promises.
2. Типа как в QUnit, где отключаются все try-catch и все тесты валятся после первого же исключения? Лучше запускать каждый тест отдельным событием — тогда падение теста не будет сказываться на общем цикле запуска тестов. Пример, такого запуска можно глянуть тут
3. Группировку тоже было бы не плохо иметь возможность отключать. Потому что прокликивать группы после каждого падения тестов — не очень удобно.
4. Было бы куда удобнее просто кликнуть по гиперссылке:

5. Многие тестовые фреймворки используют отдельные библиотеки ассертов, которые просто кидают исключение. Это позволяет использовать единый код для обработки падения теста — ведь не важно, возникло ли исключение из-за вызова несуществующего метода или из-за того, что значение возвращённого ею результата не равно ожидаемому.
2. Типа как в QUnit, где отключаются все try-catch и все тесты валятся после первого же исключения? Лучше запускать каждый тест отдельным событием — тогда падение теста не будет сказываться на общем цикле запуска тестов. Пример, такого запуска можно глянуть тут
3. Группировку тоже было бы не плохо иметь возможность отключать. Потому что прокликивать группы после каждого падения тестов — не очень удобно.
4. Было бы куда удобнее просто кликнуть по гиперссылке:
5. Многие тестовые фреймворки используют отдельные библиотеки ассертов, которые просто кидают исключение. Это позволяет использовать единый код для обработки падения теста — ведь не важно, возникло ли исключение из-за вызова несуществующего метода или из-за того, что значение возвращённого ею результата не равно ожидаемому.
1. — Как можно решить задачу с использованием promises — Перед запуском теста создаем объект промиса и запускаем таймер (нам нужно знать — может быть наш запрос отвалится по таймауту). И далее терпеливо ждем, что произойдет далее — либо асинхронный запрос завершится и мы резолвим промис, попутно проверяя данные с которыми произошел резолв (собираем данные теста)
Либо падаем по reject по таймауту.
2. — да, можно подумать в этом направлении
3. — думаю, стоит создать единый конфиг для тестов, куда включить — — отображение стектрейса для падения теста или exception
— скрывать пройденные тесты (соответсвенно, если группа прошла — не показываем группу)
4 — картинка не отобразилась =( Но это можно решить, воспользовавшись выводом со стектрейса (например выводить первый элемент, не относящийся к библиотеки)
5 — мне кажется, что стоит различать два варианта развития событий — 1) падение теста, так как вернулось неожиданное значение
2) внештатное поведение кода, которое привело к исключению
Либо падаем по reject по таймауту.
2. — да, можно подумать в этом направлении
3. — думаю, стоит создать единый конфиг для тестов, куда включить — — отображение стектрейса для падения теста или exception
— скрывать пройденные тесты (соответсвенно, если группа прошла — не показываем группу)
4 — картинка не отобразилась =( Но это можно решить, воспользовавшись выводом со стектрейса (например выводить первый элемент, не относящийся к библиотеки)
5 — мне кажется, что стоит различать два варианта развития событий — 1) падение теста, так как вернулось неожиданное значение
2) внештатное поведение кода, которое привело к исключению
1. А, понятно. Ну в принципе тут хватило бы и простого метода done()
3. Не очень понимаю за чем стектрейс может потребоваться скрывать. Ну и зачем показывать пройденные тесты — тоже.
4. Извиняюсь, вот правильные ссылки:
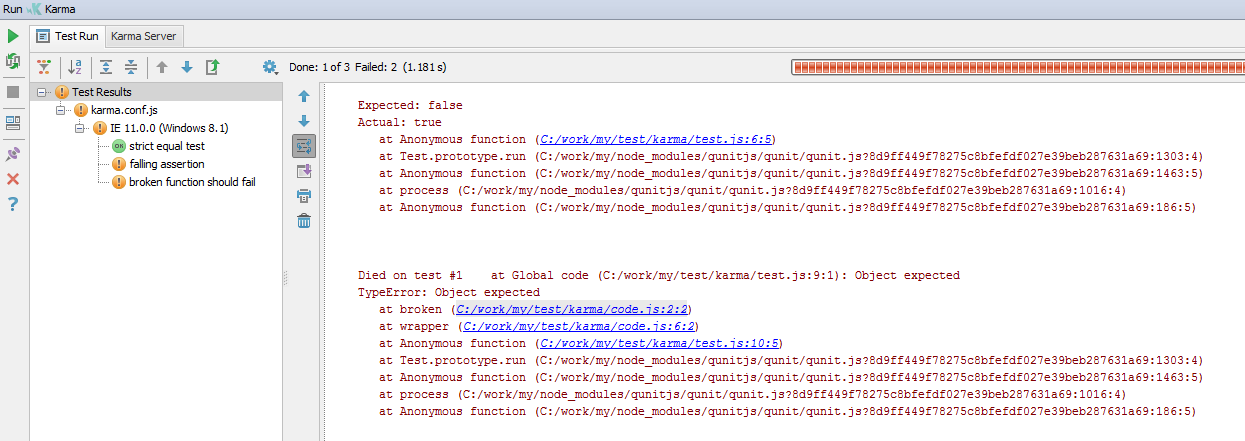
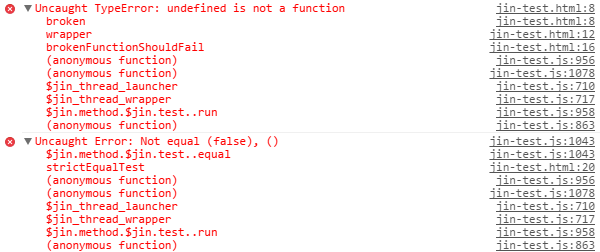
5. А зачем?
3. Не очень понимаю за чем стектрейс может потребоваться скрывать. Ну и зачем показывать пройденные тесты — тоже.
4. Извиняюсь, вот правильные ссылки:


5. А зачем?
1. Метода done() хватило бы, но promises несут большую гибкость
3. По идее, да, стектрейс желателен бы всегда. Согласен
4. О чем, в принципе я и говорил. Для большей гибкости вывод теста при запуске в node.js можно сохранять в файл -> получаем доступ к файлам одним кликом. Для работы с DOM в node.js можно прикрутить phantomjs, но это уже вопрос не тестовой системы
5. Мне все таки кажется, что падение с Exception !== падение, если функция вернула неверные данные.
В первом случае — это внештатная ситуация, во второй — неверный расчет
3. По идее, да, стектрейс желателен бы всегда. Согласен
4. О чем, в принципе я и говорил. Для большей гибкости вывод теста при запуске в node.js можно сохранять в файл -> получаем доступ к файлам одним кликом. Для работы с DOM в node.js можно прикрутить phantomjs, но это уже вопрос не тестовой системы
5. Мне все таки кажется, что падение с Exception !== падение, если функция вернула неверные данные.
В первом случае — это внештатная ситуация, во второй — неверный расчет
5. Функция вернула не тот тип параметра из-за чего у него не оказалось нужного метода — это «неверный расчёт» или «внештатная ситуация»?
Причем тут node.js?
Если оценивать по возможностям и функциональности — ничем.
Для чего была создана данная библиотека?
До создания этой библиотеки я работал с QUnit и Jasmine.
Для своих задач было решено создать небольшую библиотеку, которая будет организована интерфейсно и возможностями под текущие задачи. Так и родилась затея с данной библиотекой.
В нее были включены небольшие фичи, которых мне не хватало в QUnit (отдаю должное разработчикам — это прекрасный фреймворк для тестирования).
К ним можно отнести вывод результатов, создание иерархии тестов, цепочные вызовы.
Mocha для проектов никогда не применял, но знаком с их документацией.
Для чего была создана данная библиотека?
До создания этой библиотеки я работал с QUnit и Jasmine.
Для своих задач было решено создать небольшую библиотеку, которая будет организована интерфейсно и возможностями под текущие задачи. Так и родилась затея с данной библиотекой.
В нее были включены небольшие фичи, которых мне не хватало в QUnit (отдаю должное разработчикам — это прекрасный фреймворк для тестирования).
К ним можно отнести вывод результатов, создание иерархии тестов, цепочные вызовы.
Mocha для проектов никогда не применял, но знаком с их документацией.
Ну не скажите, сейчас mocha умеет гораздо больше чем ваша библиотека. Н-р минимум: вывод стека, разные репортеры. Все эти финтефлющечки и подсветки, на практике, нафиг не нужны.
Только вывод стека без гиперссылок — сомнительное удовольствие. И разные репортеры — это именно, что финтифлюшечки.
Не сказал бы что разные репортеры это финтефлюшечки. Разные репортеры позволяют адаптировать mocha к всему (есть вывод в xml для jenkins, отдельный вывод для консоли, отдельно для браузера, отдельно html вывод и тп — sauce labs, coveralls). Вы пробовали прикручивать ci к node.js проекту?
Тут не нужна куча репортов — достаточно одного-двух. В моче же это именно что финтифлюшки: visionmedia.github.io/mocha/#reporters
Давайте наоборот =), назовите те репортеры которые вы считаете нужны. Мне вот лично нужно и что я использую: xUnit, spec (чуть переделанный), html
Адаптер к Karma и больше ничего не надо.
Как мне карма поможет, если у меня нет машин со всеми поддерживаемыми браузерами?
Использовать виртуалки.
Не всегда это работает, проблем появляется больше чем решается. Возьмите любой OS проект и не каждый автор будет тратится на отдельные лицензии для винды, macosx не особо весел живет в virtualbox, запуск мобильных браузеров вообще отдельная песня.
У вас есть живые примеры когда хватает одной кармы (естественно поддерживаются все распространненые браузеры)?
У вас есть живые примеры когда хватает одной кармы (естественно поддерживаются все распространненые браузеры)?
Что-то мне кажется, что и про Karma вы ничего не слышали.
Полагаю, что если бы вы вовремя попробовали Mocha+Chai+Karma, то писать велосипед бы не пришлось.
Полагаю, что если бы вы вовремя попробовали Mocha+Chai+Karma, то писать велосипед бы не пришлось.
mocha+chai/jasmine = успех;
Я считаю, что эти библиотеки полностью покрывают ваши потребности, новым людям на проекте будет проще читать их документацию, к тому же они имеют хороший задел в функциональности на будущее.
В общем, мне кажется это тот случай, когда велосипед — во зло.
Оче хорошо что вы написали его сами написали и поняли принцип работы фреймворков для тестирования изнутри, но не стоит призывать его использовать, вдруг кто то начнет :)
Я считаю, что эти библиотеки полностью покрывают ваши потребности, новым людям на проекте будет проще читать их документацию, к тому же они имеют хороший задел в функциональности на будущее.
В общем, мне кажется это тот случай, когда велосипед — во зло.
Оче хорошо что вы написали его сами написали и поняли принцип работы фреймворков для тестирования изнутри, но не стоит призывать его использовать, вдруг кто то начнет :)
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Unit тестирование в js. YATS — поделка для написания юнит тестов