6-7 ноября 2014 года в Перми будет проведен конкурс «Открытый регион. Хакатон» по разработке приложений и сервисов на основе открытых данных Пермского края.
На сайте opendata.permkrai.ru опубликовано примерно 1400 статистических показателей по различным областям жизнедеятельности края. Что можно сделать с этими данными? Первая мысль, которая пришла мне в голову, — создать аналог сайта Spurious Correlations (ложные корреляции).
TL; DR:
Исходники: github.com/yakov-bakhmatov/odpr
Приложение: odpr.bakhmatov.ru
Способы получения и форматы данных описаны на странице для разработчиков. Кратко говоря, веб-сервис отдает описание метаданных (список показателей, список «кубов» — дополнительных параметров показателей, таких как ОКАТО, ОКВЭД, страны мира и т. д., список пар показатель-куб) в формате xml и сами данные (по паре идентификаторов показателя и куба) в форматах xml и csv.
Для упрощения первичного анализа «глазами» я выбрал формат csv. В этом формате записи имеют вид
Уровень календаря — это число от 1 до 5 (1 — год, 2 — полугодие, 3 — квартал, 4 — месяц, 5 — день).
Беглый анализ показал следующие проблемы:
Все эти проблемы так или иначе решаются, приступим к реализации задумки.
Для каждой пары показателей, имеющих одинаковый уровень календаря и пересекающиеся диапазоны дат, вычислим коэффициент корреляции Пирсона. Отберем те пары, модуль коэффициента корреляции которых больше 0.9 (| r | > 0.9). При открытии (или обновлении) страницы веб-приложения покажем графики случайной пары, построенные в одной системе координат.
Также нужен список всех доступных пар с поиском или фильтром.
Приложение я хотел создать быстро, стараясь оставаться во временных рамках хакатона. Вот мой выбор инструментов:
Во-первых, данные нужно загрузить из источника. Тут поджидала первая неприятность — после выкачивания нескольких десятков файлов с данными сайт opendata.permkrai.ru начинал отдавать 500-ую ошибку. Пришлось этот этап растянуть на несколько подходов.
Во-вторых, я решил ограничиться «кубом» ОКАТО.
Всего был загружен 1151 файл общим объемом 256 МиБ.
Далее каждый файл разбирался, строки группировались по набору (уровень календаря; показатель; ОКАТО).
Строки, не относящиеся к Пермскому краю, отбрасывались.
Удалялись дубли, пропущенные периоды. Значения показателей «нормализовывались».
После этого этапа осталось 11468 рядов данных.
Тут ничего сложного. Вычисляем коэффициент корреляции между двумя рядами, если эти ряды относятся к разным показателям, имеют одинаковый уровень календаря, имеют не менее 8 точек в пересечении диапазонов дат.
Получилось 129507 пар с коэффициентом корреляции более 0.9 (или менее -0.9).
Вообще говоря, почти 130 тысяч пар — это очень много. За разумное время такое количество графиков просто не отсмотреть.
Но дело в том, что внутри показателя между рядами может быть очень небольшая разница (а коэффициент корреляции, наоборот, большой — близкий к 1). Если показатель X содержит n рядов, а показатель Y содержит m рядов, то коррелирующих пар будет n * m, хотя для иллюстрации зависимости достаточно одной пары.
Исправляем. Группируем все пары по набору (показатель первого члена пары; показатель второго члена пары; знак коэффициента корреляции) и оставляем из каждой группы одного представителя.
После этого осталось 19390 пар по 11278 рядам из 501 показателя.
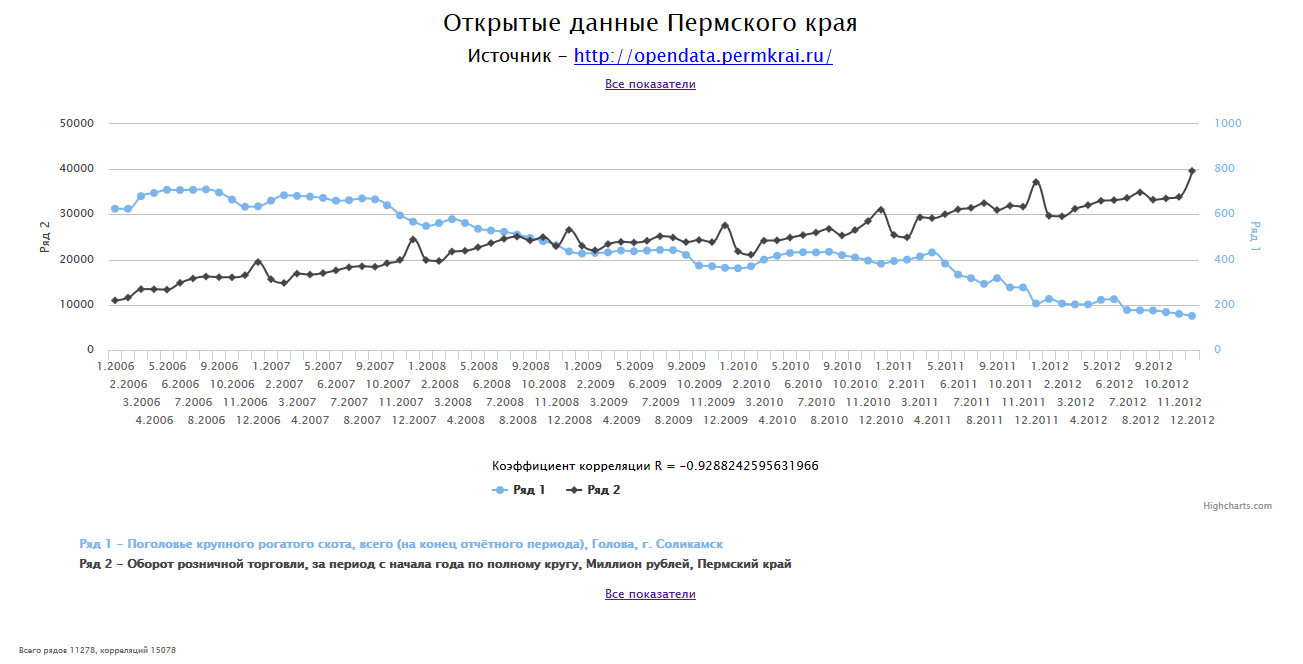
Полученные графики можно посмотреть двумя способами. Можно обновлять страницу и каждый раз получать случайный график. Можно перейти к списку всех показателей и выбрать интересующий.
Сайт будет доступен, пока не кончатся отведенные на него пара сотен рублей. Исходники доступны на github-е, при желании каждый сможет развернуть приложение у себя и поэкспериментировать с данными.
Приложение создавалось just for fun в течении трех вечеров. Еще вечер потрачен на написание этой статьи. Можно считать, что в сутки я уложился. Хакатон удался!
На сайте opendata.permkrai.ru опубликовано примерно 1400 статистических показателей по различным областям жизнедеятельности края. Что можно сделать с этими данными? Первая мысль, которая пришла мне в голову, — создать аналог сайта Spurious Correlations (ложные корреляции).
TL; DR:
Исходники: github.com/yakov-bakhmatov/odpr
Приложение: odpr.bakhmatov.ru
Исходные данные
Способы получения и форматы данных описаны на странице для разработчиков. Кратко говоря, веб-сервис отдает описание метаданных (список показателей, список «кубов» — дополнительных параметров показателей, таких как ОКАТО, ОКВЭД, страны мира и т. д., список пар показатель-куб) в формате xml и сами данные (по паре идентификаторов показателя и куба) в форматах xml и csv.
Для упрощения первичного анализа «глазами» я выбрал формат csv. В этом формате записи имеют вид
Уровень календаря;Дата;Название показателя;Дополнительные параметры "куба";Значение
Уровень календаря — это число от 1 до 5 (1 — год, 2 — полугодие, 3 — квартал, 4 — месяц, 5 — день).
Беглый анализ показал следующие проблемы:
- По некоторым показателям мало данных — одна-две записи. Такие показатели нужно просто отбросить.
- Есть данные, относящиеся к другим регионам России. Такие строки нужно отфильтровывать.
- Большое количество значений идет по нарастанию с начала года. Если отобразить их на графике, получится «пила». Лучше эти значения «отнормировать» так, чтобы каждое из них содержало числа, относящиеся к указанному кварталу/месяцу, а не к периоду с начала года.
- Есть пропуски в данных — информация есть не по всем месяцам/кварталам в году и не по всем годам подряд. Годы с пропущенными месяцами/кварталами я отбрасывал, показатели с пропущенными годами исключал.
- Дублирующиеся показатели.
Все эти проблемы так или иначе решаются, приступим к реализации задумки.
Идея приложения
Для каждой пары показателей, имеющих одинаковый уровень календаря и пересекающиеся диапазоны дат, вычислим коэффициент корреляции Пирсона. Отберем те пары, модуль коэффициента корреляции которых больше 0.9 (| r | > 0.9). При открытии (или обновлении) страницы веб-приложения покажем графики случайной пары, построенные в одной системе координат.
Также нужен список всех доступных пар с поиском или фильтром.
Инструменты
Приложение я хотел создать быстро, стараясь оставаться во временных рамках хакатона. Вот мой выбор инструментов:
- серверная часть — clojure + http-kit;
- клиентская часть — clojurescript для списка показателей, библиотека highcharts для отображения графиков;
- самое лучшее и проверенное временем nosql хранилище — простые файлы в «родном» для clojure формате edn.
Процесс
Загрузка данных
Во-первых, данные нужно загрузить из источника. Тут поджидала первая неприятность — после выкачивания нескольких десятков файлов с данными сайт opendata.permkrai.ru начинал отдавать 500-ую ошибку. Пришлось этот этап растянуть на несколько подходов.
Во-вторых, я решил ограничиться «кубом» ОКАТО.
Всего был загружен 1151 файл общим объемом 256 МиБ.
Подготовка данных
Далее каждый файл разбирался, строки группировались по набору (уровень календаря; показатель; ОКАТО).
Строки, не относящиеся к Пермскому краю, отбрасывались.
Удалялись дубли, пропущенные периоды. Значения показателей «нормализовывались».
После этого этапа осталось 11468 рядов данных.
Вычисление корреляций
Тут ничего сложного. Вычисляем коэффициент корреляции между двумя рядами, если эти ряды относятся к разным показателям, имеют одинаковый уровень календаря, имеют не менее 8 точек в пересечении диапазонов дат.
Получилось 129507 пар с коэффициентом корреляции более 0.9 (или менее -0.9).
Постобработка
Вообще говоря, почти 130 тысяч пар — это очень много. За разумное время такое количество графиков просто не отсмотреть.
Но дело в том, что внутри показателя между рядами может быть очень небольшая разница (а коэффициент корреляции, наоборот, большой — близкий к 1). Если показатель X содержит n рядов, а показатель Y содержит m рядов, то коррелирующих пар будет n * m, хотя для иллюстрации зависимости достаточно одной пары.
Исправляем. Группируем все пары по набору (показатель первого члена пары; показатель второго члена пары; знак коэффициента корреляции) и оставляем из каждой группы одного представителя.
После этого осталось 19390 пар по 11278 рядам из 501 показателя.
Веб-приложение
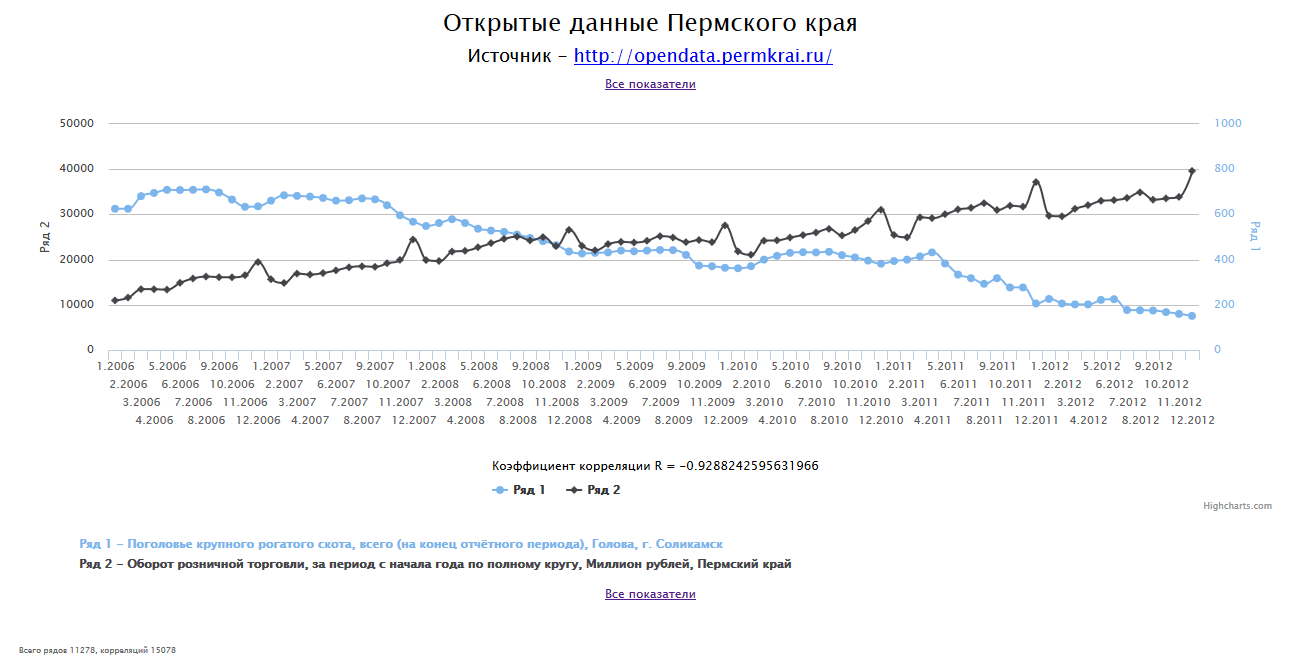
Полученные графики можно посмотреть двумя способами. Можно обновлять страницу и каждый раз получать случайный график. Можно перейти к списку всех показателей и выбрать интересующий.
Заключение
Сайт будет доступен, пока не кончатся отведенные на него пара сотен рублей. Исходники доступны на github-е, при желании каждый сможет развернуть приложение у себя и поэкспериментировать с данными.
Приложение создавалось just for fun в течении трех вечеров. Еще вечер потрачен на написание этой статьи. Можно считать, что в сутки я уложился. Хакатон удался!







