Комментарии 44
Интересно, какие есть свежие веяния в методиках управления памятью, которые могут воплотиться в хардварном исполнении в новых процессорах?
Подумал, дежавю, оказывается авторы разные habrahabr.ru/company/yandex/blog/231957/
У нас есть stack, который растет вниз; у него есть лимит дальше котрого он расти не может.
В линуксе ведь через ulimit можно выставить в том числе неограниченный размер стека (ulimit -s unlimited), как в этом случае память организуется, и как оно работает?
Кроме того, как это все соотносится например с segmented stacks реализованном в gcc? И вообще, зачем само понятие стек существует на уровне операционки? Ей не все равно как прикладная программа распоряжается памятью которую под нее выделили? (может у меня будет много стеков, а может мне не нужен стек вообще?)
И вообще, зачем само понятие стек существует на уровне операционки?
Начнем с того, что оно существует на уровне x86, стековый регистр, все дела.
А закончим тем, что linux работает далеко не только на x86 :-) И этот регистр есть далеко не во всех архитектурах.
Кроме того, да, регистр допустим есть, и что дальше? Операционке нужно только знать, что при сохранении контекста данного потока нужно вот этот стек тоже сохранить (он входит в контекст), а уж что с ним делать, как изменять и так далее — решает уже прикладная программа. В ходе работы оной программы расположение «стека» может прыгать по всему адресному пространству приложения хоть через каждые 4 инструкции.
Зачем операционке знать про стек как область памяти, которая должна быть «непрерывной и ограниченной»?
Кроме того, да, регистр допустим есть, и что дальше? Операционке нужно только знать, что при сохранении контекста данного потока нужно вот этот стек тоже сохранить (он входит в контекст), а уж что с ним делать, как изменять и так далее — решает уже прикладная программа. В ходе работы оной программы расположение «стека» может прыгать по всему адресному пространству приложения хоть через каждые 4 инструкции.
Зачем операционке знать про стек как область памяти, которая должна быть «непрерывной и ограниченной»?
Непрерывной — потому что segmented stack это всякие новомодные штучки-дрючки, которых не был когда Linux начинался, да и сейчас же далеко не все его реализуют… банально сложнее с таким подходом и компилятор писать, и систему, и выполнение программы чуть замедляется
Ограниченной — потому что неограниченный рост стека это 100% ошибка программиста, зачем наворачивать всю систему при этом?
Кажется что этот стек вам лично чем-то насолил, ну есть и есть :)
Ограниченной — потому что неограниченный рост стека это 100% ошибка программиста, зачем наворачивать всю систему при этом?
Кажется что этот стек вам лично чем-то насолил, ну есть и есть :)
Да не стек мне насолил, я просто не понимаю зачем стек — это сущность уровня операционки, а не уровня приложения. Зачем операционке знать про то какой там «стек» у данного конкретного приложения?
Ну как самый минимум ядро должно выделить память под область стека. В некоторых продвинутых вариантах можно запретить выполнять код со стека, опять же ядру нужно знать об этом чтоб снять битик исполнения со страницы.
Зачем ядру выделять память под область стека для приложения? (про память/структуры под конкретный процесс в адресном пространстве самого ядра мы сейчас не говорим)
А в продвинутых вариантах вообще можно запретить выполнять код из области данных/кучи, и разрешено выполнять код только из секций texts (вроде так оно зовется), то есть область адресного пространства куда мапится машкод из исполняемого файла.
Но при чем тут стек? Чем стек тут принципиально отличается от кучи, и зачем операционке про него знать отдельно? Я прошу операционку выделить мне еще немного памяти через тот же mmap, и уж под что эту память использовать (стек, куча, что-то еще) — уже мое дело.
А в продвинутых вариантах вообще можно запретить выполнять код из области данных/кучи, и разрешено выполнять код только из секций texts (вроде так оно зовется), то есть область адресного пространства куда мапится машкод из исполняемого файла.
Но при чем тут стек? Чем стек тут принципиально отличается от кучи, и зачем операционке про него знать отдельно? Я прошу операционку выделить мне еще немного памяти через тот же mmap, и уж под что эту память использовать (стек, куча, что-то еще) — уже мое дело.
стек может (и обычно так и происходит) выделяться неявно. Грубо говоря, ядро проверяет как далеко от rsp произошел page fault и при необходимости отображает еще память. Мы же о платформах с mmu говорим?
Да, пусть будет с mmu.
Так вот, насколько я понимаю, это не только стек так выделяется. То есть если я говорю через тот же mmap что вот хочу кусок памяти, то да, мне выделяется кусок адресного пространства, но физически память не выделяется. И только когда я туда обращусь, только тогда операционка словит свой page fault и реально таки выделит кусок физической памяти под этот сегмент для моего приложения.
То есть опять таки я тут не вижу ничего специфичного для тека — тут без разницы для чего будет использована данная память — под стек вызовов, под кучу, или под какую-то еще пользовательскую структуру. Все на усмотрение приложения.
Зачем операционке что-то знать про то что у моего приложения есть стек вообще?
Так вот, насколько я понимаю, это не только стек так выделяется. То есть если я говорю через тот же mmap что вот хочу кусок памяти, то да, мне выделяется кусок адресного пространства, но физически память не выделяется. И только когда я туда обращусь, только тогда операционка словит свой page fault и реально таки выделит кусок физической памяти под этот сегмент для моего приложения.
То есть опять таки я тут не вижу ничего специфичного для тека — тут без разницы для чего будет использована данная память — под стек вызовов, под кучу, или под какую-то еще пользовательскую структуру. Все на усмотрение приложения.
Зачем операционке что-то знать про то что у моего приложения есть стек вообще?
Когда вы вызвали mmap вы по сути сказали ядру, что вам нужен какой то диапазон виртуальных адресов. И если вы попробуете обратиться за пределами страниц этого диапазона, вы получите Segmentation Fault. Если же обратитесь внутрь диапазона и страница еще не отображена то — minor page fault и как результат отображенную страницу.
Для выделения памяти для стека, приложение mmap может не вызывать, вообще. Есть только знание ядра о том что адрес принадлежит стековой области, что адреса стека растут вниз и что можно отступить на сколько то байт от указателя на вершину стека — этого достаточно чтобы ядро отобразило страницу. Если не попали — Segmentation Fault.
Т.е. еще раз, выделения памяти на стеке вообще не приводят к mmap`ам. Это полностью прозрачный механизм для вашего приложения.
Если сильно пофантазировать, то наверно можно придумать некую архитектуру, где память для стека будет просить компилятор, но встаёт вопрос — а что если я хочу писать на ассемблере? Да и не дело это компилятора вставлять системные вызовы в код, и к тому же это завязка компилятор + ос, сразу минус в переносимости.
Для выделения памяти для стека, приложение mmap может не вызывать, вообще. Есть только знание ядра о том что адрес принадлежит стековой области, что адреса стека растут вниз и что можно отступить на сколько то байт от указателя на вершину стека — этого достаточно чтобы ядро отобразило страницу. Если не попали — Segmentation Fault.
Т.е. еще раз, выделения памяти на стеке вообще не приводят к mmap`ам. Это полностью прозрачный механизм для вашего приложения.
Если сильно пофантазировать, то наверно можно придумать некую архитектуру, где память для стека будет просить компилятор, но встаёт вопрос — а что если я хочу писать на ассемблере? Да и не дело это компилятора вставлять системные вызовы в код, и к тому же это завязка компилятор + ос, сразу минус в переносимости.
Совсем запретить выполнение из области heap/mmap нельзя, потому что тогда не будут работать системы с JIT компиляцией, динамической загрузкой кода и т. д.
Зачем ядру выделять память под область стека для приложения?А некому больше. Стек появляется до того, как появляется приложение. Иначе некуда будет класть
envp и argv. И потому хоть какая-то поддержка стека но ядру нужна. А поскольку эти самые envp и argv могут быть многогигабайтными (в современных Linux'ах до ¼ оперативной памяти, если ничего не путаю), то ограничиться фиксированными несколькими страничками нельзя, нужно делать стек, который умеет «расти».Ну а дальше — приложение может этим стеком не пользоваться после того, как «заберёт себе» свои параметры, это его дело.
Могу ошибаться, но слышал, что бывают ситуации, когда ядро использует стек юзерспейс-программы. Интересно было бы про это почитать.
Да, в принципе это могло бы быть ответом на вопрос зачем операционке навязывать приложению какой-то там ограниченный стек прибитый гвоздями и по расположению и по размеру.
Ядро не использует стек юзерспейс-программы. Тут вам не Windows. Но оно может показывать кусочки из него в
/proc. Файлы /proc/.../cmdline и /proc/.../environ оно как раз оттуда выдёргивает.Спасибо, хороший материал, командочки. Если читать только транскрипцию, ничего понять нельзя. Надо смотреть презентацию/видео. Только для поисковых систем разве что имеет смысл, чтобы этот пост потом искался.
Вот эта картинка:
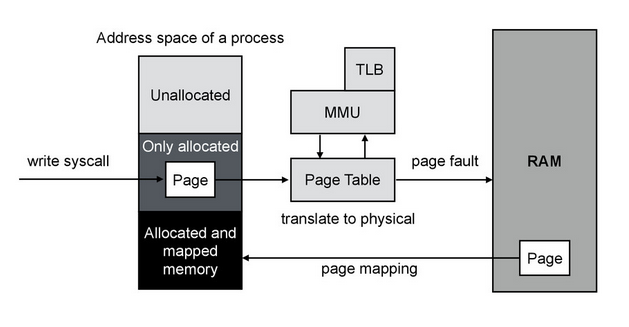
вводит в заблуждение, потому что физически аллоцированная память точно так же идет через таблицу, а не «напрямую».
Почему чтения в кучу — больше переключений контекста? Или я чего-то не понимаю, или имелись ввиду переключения режима (user/kernel mode switch), что не одно и то же с context switch и близко.
Если mmap() такой распрекрасный, желательно вербализировать, зачем же кто-то все таки читает в юзер-спейс буффера. В моем понимании, это:
— Предсказуемый порядок чтения/записи с диска/на диск, например сбросить лог на диск до основных страниц базы.
— Какие-то эвристики по вытеснению, более продвинутые чем LRU/2, или что там, имея на руках логику того, что конкретная страница представляет из себя для базы. + Возможность конфигурации этого дела.
Зачем говорить, что чтение в кучу это плохо, используем в 2 раза больше памяти, если тут же говориться, что кеш страниц можно и отключить, что собственно все базы и делают.
Вот эта картинка:
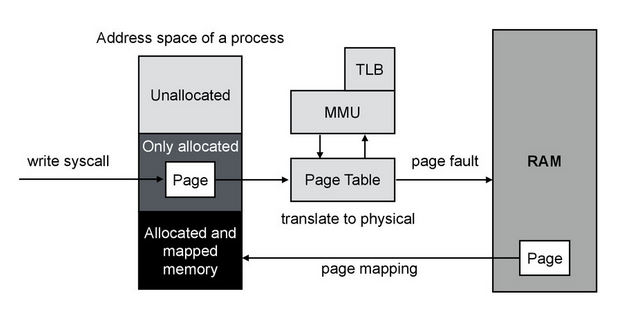
вводит в заблуждение, потому что физически аллоцированная память точно так же идет через таблицу, а не «напрямую».
Почему чтения в кучу — больше переключений контекста? Или я чего-то не понимаю, или имелись ввиду переключения режима (user/kernel mode switch), что не одно и то же с context switch и близко.
Если mmap() такой распрекрасный, желательно вербализировать, зачем же кто-то все таки читает в юзер-спейс буффера. В моем понимании, это:
— Предсказуемый порядок чтения/записи с диска/на диск, например сбросить лог на диск до основных страниц базы.
— Какие-то эвристики по вытеснению, более продвинутые чем LRU/2, или что там, имея на руках логику того, что конкретная страница представляет из себя для базы. + Возможность конфигурации этого дела.
Зачем говорить, что чтение в кучу это плохо, используем в 2 раза больше памяти, если тут же говориться, что кеш страниц можно и отключить, что собственно все базы и делают.
Только для поисковых систем разве что имеет смысл, чтобы этот пост потом искался.У текста есть, как минимум, ещё одно преимущество — поиск. Причём, искать можно как браузером, так и глазами — скажем, выбирая интересную тебе часть статьи.
вводит в заблуждение, потому что физически аллоцированная память точно так же идет через таблицу, а не «напрямую».
Да, вы правы, идёт через таблицу. Здесь идея была показать как и когда срабатывает page fault и demand paging и не усложнить картинку.
Почему чтения в кучу — больше переключений контекста? Или я чего-то не понимаю, или имелись ввиду переключения режима (user/kernel mode switch), что не одно и то же с context switch и близко.
Имелось ввиду переключение ядро-юзерспейс. Таких переключений становится просто больше и при определённых маштабах это начинает быть проблемой.
Если mmap() такой распрекрасный, желательно вербализировать, зачем же кто-то все таки читает в юзер-спейс буффера. В моем понимании, это:
mmap() и впрямь распрекрасный =). Однако с ним есть тонкости. Невозможно, к примеру, отдебажить повторное обращение к данным, если они уже есть в pagecache и не вытеснились. С read'ами делается легко через I/O counter (/proc/self/io).
— Предсказуемый порядок чтения/записи с диска/на диск, например сбросить лог на диск до основных страниц базы.
Да, так и есть, запись усложняется. Нам необходимо обновить журнал/лог_транзакций заранее и в append режиме (чтобы облегчить запись на диск). Но, кажется, что с переходом на SSD это становится меньшей проблемой. Посмотрите как это решили разработчики MongoDB: www.youtube.com/watch?feature=player_embedded&v=8TmmEzm50cw
Из минусов работы с mmap() я бы ещё добавил необходимость преаллоцировать файлы (опять же пример MongoDB) и дополнительные/ненужные page falts при записи в пустые области.
— Какие-то эвристики по вытеснению, более продвинутые чем LRU/2, или что там, имея на руках логику того, что конкретная страница представляет из себя для базы. + Возможность конфигурации этого дела.
Да это как раз то, что делают ребяза из InnoDB в MySQL: открывают файлы через O_DIRECT и реализуют всю эвристику под свои структуры данных.
Вообще этот аглоритм с LRU/2 и mmap() не позволяет иметь ваш Working set больше чем, грубо говоря, половина памяти. Есть различные идеи в ядре как это чинить. У нас это делается при помощи cgroup и патчей на ядро.
Зачем говорить, что чтение в кучу это плохо, используем в 2 раза больше памяти, если тут же говориться, что кеш страниц можно и отключить, что собственно все базы и делают.
Не все. Отключать page cache плохо хотя бы потому, что это затрудняет деплой/обновление программы базы данных. Так у вас все данные в памяти и о ней знает ядро. А при выключенном кеше память приложения анонимна и потеряется при рестарте. Ну или придумываем вот такие штуки www.percona.com/doc/percona-server/5.5/management/innodb_lru_dump_restore.html
Из минусов работы с mmap() я бы ещё добавил необходимость преаллоцировать файлы (опять же пример MongoDB) и дополнительные/ненужные page falts при записи в пустые области.
У меня есть идеи насчет оптимизации этого, используя маленькие (практически, одностраничные) mmap()-ы. Если сервер будет работать долго, само количество системных вызовов не должно быть большой проблемой. Насколько я понимаю, долгосрочная цена — много VMA/чуть более долгий поиск в дереве при major page fault, вроде не страшно. Но это все чисто теория, я ничего не проверял.
Не все. Отключать page cache плохо хотя бы потому, что это затрудняет деплой/обновление программы базы данных. Так у вас все данные в памяти и о ней знает ядро. А при выключенном кеше память приложения анонимна и потеряется при рестарте. Ну или придумываем вот такие штуки www.percona.com/doc/percona-server/5.5/management/innodb_lru_dump_restore.html
Ну это понятно. Юзер-спейс он на то и юзер-спейс, чтобы теряться при рестарте.
malloc() использует больше памяти: происходит копирование в user space. Также потребляется больше CPU, и мы получаем больше переключений контекста, чем если бы мы работали с файлом через mmap().
Наверно имелось в виду не malloc, а read/write.
Кстати, опущен интересный момент с реализацией мапинга физической памяти на виртуальную. Помнится, на Линуксе подход в лоб — тупо при инициализации вся физическая память мапится на адресное пространство ядра (про распределение адресов в виртуальном адресном пространстве тоже нет), что стало проблемой, когда объёмы RAM стали значительными, появилось разделение на замапленную постоянно (какие-то 768мб по умолчанию), и остальное через плавающее окно. В общем, эпичный костыль в стиле «64кб хватит всем». Речь, конечно, только о 32 битной платформе. На BSD было сделано гораздо умней и хитрей — рекурсивный мапинг страниц, когда страница, содержащая page directory, мапит сама себя, одновременно являясь ещё и page table и рядовой страницей в иерархии таблиц трансляции.
А где почитать как это во FreeBSD было? Просто интересно.
Конкретно про BSD доступного описания не нашёл. Но нашёл упрощённое описание самого принципа рекурсивного мапинга: www.thomasloven.com/blog/2012/06/Recursive-Page-Directory/
Я в своё время непосредственно по коду со всем этим разбирался. Нужно было на работе реализовать поддержку PAE в форке FreeBSD.
Конечно, у этих двух подходов есть свои плюсы и минусы (если отбросить изначально 32-битные архитектуры). Вот тут я когда-то сравнивал (баловался давно написанием своих ОС, куда ж без этого :) ):
ast-phoenix.sourceforge.net/doc/doku.php?id=athena:product:phoenix:components:vm#phoenix_virtual_memory_subsystem
Пример реализации рекурсивного мапинга можно посмотреть в этом проекте: xp-dev.com/trac/phobos_root/browser/phobos_root/mainline. Он был первым и результат более существенный — полноценный юзер спейс, бинарники приложений с динамическими библиотеками и своей реализацией рантайм-линкера. Хотя в предыдущем тоже можно кое-что почерпнуть, например, как загрузить своё ядро в EFI BIOS, причём используя только GNU toolchain для разработки.
Я в своё время непосредственно по коду со всем этим разбирался. Нужно было на работе реализовать поддержку PAE в форке FreeBSD.
Конечно, у этих двух подходов есть свои плюсы и минусы (если отбросить изначально 32-битные архитектуры). Вот тут я когда-то сравнивал (баловался давно написанием своих ОС, куда ж без этого :) ):
ast-phoenix.sourceforge.net/doc/doku.php?id=athena:product:phoenix:components:vm#phoenix_virtual_memory_subsystem
Пример реализации рекурсивного мапинга можно посмотреть в этом проекте: xp-dev.com/trac/phobos_root/browser/phobos_root/mainline. Он был первым и результат более существенный — полноценный юзер спейс, бинарники приложений с динамическими библиотеками и своей реализацией рантайм-линкера. Хотя в предыдущем тоже можно кое-что почерпнуть, например, как загрузить своё ядро в EFI BIOS, причём используя только GNU toolchain для разработки.
Как в Linux сделаны стеки потоков? Если после fork родительский потом освободил свой стек, то в дочерних останется копия — я правильно понимаю? А куча? Она общая или нет?
В Linux (имеется в виду ядро) нет потоков… ну… почти нет. Есть процессы с общим адресным пространством и всё. Относительно недавно (лет 10 назад) было добавлены кой-какие костыли, для того, чтобы имитировать полноценные POSIX'ные потоки, но даже сегодня это — на 99% дело GLibC, а не ядра.
Соответственно с точки зрения ядра у всех потоков только один стек — вот тот самый, который был у родительского процесса. А что %rsp в других процессах GLibC куда-то переставляет — ну так это ядро ни разу не волнует. Это личное дело GLibC :-)
Соответственно с точки зрения ядра у всех потоков только один стек — вот тот самый, который был у родительского процесса. А что %rsp в других процессах GLibC куда-то переставляет — ну так это ядро ни разу не волнует. Это личное дело GLibC :-)
Т.е. запустив процесс мы даём ему возможность видеть весь родительский стек? Это же какая дыра в безопасности ;)
Шутю. Потоками, я называю то, что запущено непосредственно через fork/clone. Не совсем понятно, как там динамическая память в этих случаях работает.
Шутю. Потоками, я называю то, что запущено непосредственно через fork/clone. Не совсем понятно, как там динамическая память в этих случаях работает.
А чего тут не понимать? Когда вы вызываете clone(2) с опцией CLONE_VM то новый процесс разделяет адресное пространство со старым, там не только стек можно видеть, а и вообще всю память.
Дело ядра — создать новый процесс. Если задали CLONE_VM, то с той же таблицей страниц, если задали CLONE_FILES, то с теми же файловыми дескрипторами и т.п. Остальное — дело библиотеки ptherads (или аналогичной). В частности после вызова clone(2) возврат происходит без смены стека. Ну то есть совсем. Тот же стек, та же память, та же исполняемая инструкция. Отличие только в коде возврата. Разумеется если оба процесса начнут после этого использовать один и тот же стек «по настоящему», то ничего хорошего из этого не выйдет: они друг другу, образно говоря «все ноги оттопчут». Потому один из процессов обычно переключает свой
Дело ядра — создать новый процесс. Если задали CLONE_VM, то с той же таблицей страниц, если задали CLONE_FILES, то с теми же файловыми дескрипторами и т.п. Остальное — дело библиотеки ptherads (или аналогичной). В частности после вызова clone(2) возврат происходит без смены стека. Ну то есть совсем. Тот же стек, та же память, та же исполняемая инструкция. Отличие только в коде возврата. Разумеется если оба процесса начнут после этого использовать один и тот же стек «по настоящему», то ничего хорошего из этого не выйдет: они друг другу, образно говоря «все ноги оттопчут». Потому один из процессов обычно переключает свой
%rsp в другое место. Но ядро это, в общем, не волнует.Да, но стеки, на сколько я понимаю, перескаются в адресном пространстве — т.е. там copy-on-write должен работать. В связи с чем возникают вопрос:
1) На сколько тяжелы накладные расходы на переключение таблицы страниц для каждого потока, которых могут быть тысячи. Винда, например, для потоков таблицы страниц не переключает, как я понимаю.
2) Вся остальная пямять, кроме стека должна быть по настоящему общей. Иначе можно забыть про всякие атомарые счётчики и т.п.
3) Куча у них общая получается? И рост кучи должен отображаться на адресные пространства обоих процессов.
1) На сколько тяжелы накладные расходы на переключение таблицы страниц для каждого потока, которых могут быть тысячи. Винда, например, для потоков таблицы страниц не переключает, как я понимаю.
2) Вся остальная пямять, кроме стека должна быть по настоящему общей. Иначе можно забыть про всякие атомарые счётчики и т.п.
3) Куча у них общая получается? И рост кучи должен отображаться на адресные пространства обоих процессов.
Да, но стеки, на сколько я понимаю, перескаются в адресном пространстве — т.е. там copy-on-write должен работать.Это вы каких-то док по Солярису обкурились, не иначе. В Linux всё проще: либо адресное пространство одно (флаг
CLONE_VM установлен), либо они разные (CLONE_VM сброшен). Всё. Никаких других вариантов нету. Потому, разумеется, никто не переключает таблицы страниц при переключении потоков.Ещё раз: после вызова
clone в обоих процессах возврат происходит в ту же самую точку, в тот же самый (совсем тот же самый!) стек. Как там процессы будут эту ситуацию разруливать — ядро не волнует от слова вообще. Могут по чётности (один поток использует чётные байты в стеке, другой — нечётные), могут ещё как-нибудь, но обычно один из потоков тут же (то есть буквально в следующие несколько инструкций после возврата из clone(2)) переставляет %rsp. Так что у него после этого стек указывает не в то место, где находится стек с точки зрения ядра, а куда-то ещё. Ядро это не волнует: оно предоставило минимальный механизм, достаточный, для того, чтобы программа стартовала и умыло руки. Использовать ли этот механизм всегда или переключиться на что-то другое — это личное дело программы. Практически использовать его совместно с многопоточными программами не получается и его так и не использует никто.Вот, именно это я и хотел спросить. Большое спасибо. А стеки с каким шагом разносятся по адресному пространству? Ведь стек растёт и новый стек тоже должен расти.
Новый стек просто выделяется mmap'ом и никуда не растёт. Какой закажите — такой и будет. На большинстве архитектур — 2MB, но, скажем, на SPARC64 — 4MB.
Совсем не растёт?! Вы уверены? Т.е. я не могу, например, создать на стеке массив 2 МБайт? Под виндой под него довольно много места резервируется (стеки распределяются с некоторым шагом в адресом пространстве) и стек растёт по мере заполнения.
Абсолютно уверен, так как ровно с этим кодом я несколько лет назад интимно общался. Если хотите заводить массивы в 2 мегабайта — закажите перед созданием потока больше, вам дадут.
P.S. Разумеется 2MB или сколько уж вы там закажете — это аллокация адресного пространства. Туда мапируется одна, «выделенная» нулевая страница вначале, а уж когда вы начнёте туда писать — тогда только выделится память. Но это не какая-то особенность стеков: точно также ведёт себя и
P.S. Разумеется 2MB или сколько уж вы там закажете — это аллокация адресного пространства. Туда мапируется одна, «выделенная» нулевая страница вначале, а уж когда вы начнёте туда писать — тогда только выделится память. Но это не какая-то особенность стеков: точно также ведёт себя и
mmap и даже самый обычный malloc! Если им аллоцировать куски больше 128KiB, конечно. Стеки тут не являются чем-то особенным. Особенным является только «основной» стек выделенный при выполнении системного вызова exec.Кстати, а не изучали вопрос «почему так»? Кажется создать еще один стек при вызове clone(), указать туда %rsp и затем обслуживать его так же как и «основной стек», т.е. разрешить расти, не очень сложно.
Одна проблема видна сразу — на архитектурах с 32битными VA сложно определить на сколько отступить от предыдущего стека. Но может еще есть причины?
Одна проблема видна сразу — на архитектурах с 32битными VA сложно определить на сколько отступить от предыдущего стека. Но может еще есть причины?
А просто не нужно это никому. С основным стеком приходится возится, так как программа начинает его использовать прямо сразу (в этот момент в адресном пространстве процесса ещё никакой другой записываемой памяти нет) и «на первых порах» его некому поддерживать «в рабочем состоянии». На x86 можно, в принципе, выкрутится, работая какое-то время только с регистрами, но могут быть архитектуры, где это в принципе «не прокатит». А когда процесс почкуется — то это делает уже вполне полноценный процесс и он может «ко всему подготовиться».
В Linux принцип: в ядре делается не то, что там сделать можно, а то, что там делать нужно — то есть то, что либо очень сложно, либо попросту невозможно сделать не в ядре. Первый стек вне ядра сделать сложно (проблема «курицы и яйца»), все остальные — просто.
В Linux принцип: в ядре делается не то, что там сделать можно, а то, что там делать нужно — то есть то, что либо очень сложно, либо попросту невозможно сделать не в ядре. Первый стек вне ядра сделать сложно (проблема «курицы и яйца»), все остальные — просто.
Если мы говорим о glibc malloc(), то он выделяет анонимную память таким интересным способом: использует heap для аллокации маленьких объемов (менее 128 KБ) и mmap() для больших объемов.
А где он эти файл(ы), в которые делает mmap размещает?
А где он эти файл(ы), в которые делает mmap размещает?
Либо у меня Firefox сломался, либо буквы «й» и «ё» в этой статье какие-то пьяные
Большое спасибо, хотел бы отметить пару моментов:
1. Про термины: анонимная память это как раз наоборот та память которая не ассоциирована с областями на диске — страницы процесса в куче или стек режима пользователя. (ну и дальше по тексту вы сами их разделяете — «являются разделение на анонимную память и ту, у которая связана с файлом на диске.»).
2. Резидентная память если имеется ввиду RSS тоже не совсем точное определение.
3. Про зоны, разделение на зоны вообще никак не связано с NUMA и появилось задолго до NUMA архитекуры. И кстати вы не упомянули про ZONE_NORMAL — память выше 4-го гигабайта.
4. mmap() может создавать и незамапленные на диск области
5. Copy-On-Write упомянули, но не раскрыли совсем)))
Еще раз спасибо, пишите еще!
1. Про термины: анонимная память это как раз наоборот та память которая не ассоциирована с областями на диске — страницы процесса в куче или стек режима пользователя. (ну и дальше по тексту вы сами их разделяете — «являются разделение на анонимную память и ту, у которая связана с файлом на диске.»).
2. Резидентная память если имеется ввиду RSS тоже не совсем точное определение.
3. Про зоны, разделение на зоны вообще никак не связано с NUMA и появилось задолго до NUMA архитекуры. И кстати вы не упомянули про ZONE_NORMAL — память выше 4-го гигабайта.
4. mmap() может создавать и незамапленные на диск области
5. Copy-On-Write упомянули, но не раскрыли совсем)))
Еще раз спасибо, пишите еще!
sed -e 's/фай /фай/g'
А в чем сакральный смысл разделения LRU/2 на два листа (active/inactive) если по сути это один лист?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Deleted