Комментарии 120
Итак, девушка быстро превращается в парня. :)
Вы сделали мой день. Ализар перепутал мужика и девушку :D
Гугл кеш помнит.
(Промахнулся уровнем, ну да ладно)
Гугл кеш помнит.
(Промахнулся уровнем, ну да ладно)
НЛО прилетело и опубликовало эту надпись здесь
Зато есть руны с ларца Фрэнкса: ru.wikipedia.org/wiki/%D0%9B%D0%B0%D1%80%D0%B5%D1%86_%D0%A4%D1%80%D1%8D%D0%BD%D0%BA%D1%81%D0%B0
И символы фестского диска: unicode-table.com/ru/blocks/phaistos-disc/
А уж «чёрных треугольников, повёрнутых влево» и подобной чепухи навалом.
И символы фестского диска: unicode-table.com/ru/blocks/phaistos-disc/
А уж «чёрных треугольников, повёрнутых влево» и подобной чепухи навалом.
Дерзость можно понять: он как продвинутый пользователь цифровой техники немало уже натерпелся за свою жизнь из-за «неудачного» имени.
Это он ещё в России не пробовал с этим именем по различным гос.учреждениям походить.
Помню, был китаец Ю, которого нельзя было записать в больницу. В фамилии не должно быть меньше двух букв.
Йу не подошло бы? :)
Неравенство строгое. Он стал, вроде, Йуэ, но точно не вспомню уже.
>> Неравенство строгое
Тогда не меньше трех букв.
Тогда не меньше трех букв.
Да, больше двух букв, простите.
А что делают сотни Ли из России, которые легко гуглятся в контакте, когда приходят в больницу?
Ох.
О да! В России не каждый чиновник способон правильно написать имя, даже при полном наличии символов и четкой подсказки перед глазами!
Переходите, уже, что ли, на латиницу. А то невозможно.
А индейцы майя еще не возбухали с требованием включить узелковое письмо в юникод?
Особенный цимес в том, что смысловую нагрузку в нем несёт не только форма, но и цвет «символов».
(А может быть и запах тоже?)
Особенный цимес в том, что смысловую нагрузку в нем несёт не только форма, но и цвет «символов».
(А может быть и запах тоже?)

Кстати, в консорциум Unicode можно писать предложения? Есть у них какой-то форум для обсуждений типа как isocpp.org для стандарта С++?
Вполне можно. Кому надо — составляют списки, отправляют в Юникод и нужные символы постепенно там появляются. Вот можно например почитать Проект: Внесение символов алфавитов народов России в Юникод
Да ладно какая-то странная индийская буква, вы попробуйте поиметь много лет существующую во всех используемых в России кодировках букву «Ё» в имени или фамилии — вот где проблем не оберётесь.
Да, подтверждаю. У моей девушки «ё» в фамилии, проблем — куча (начиная с той, что при смене паспорта «ё» превратилась в «е»).
А вы попробуйте жить с фамилией, где «е» читается как «о»
Я так и живу. У меня несколько букв читаются не так, как пишутся. Я даже официально менял имя, чтобы избавиться от части проблем. А когда у меня закончился первый загранпаспорт, я получил второй и стал новым человеком — имя и фамилия неожиданно поменялись, так как в ОВИРе поменялась транслитерация с как бы французской на как бы английскую.
У меня нет в имени и фамилии Ё, но 100% людей делают ошибку.
Моя фамилия похожа на Романов, но отличается, ударение на первый слог, но все ставят на второй и постоянно норовят в конце "о" на "е" поменять. Это если повезет. Люди имеют очень развитую фантазию. Про транслитерацию на английские буквы я вообще молчу.
У меня Ё и в имени и в фамилии. Подтверждаю — тяжело. И не только мне. Все документы — с разными комбинациями (свидетельство о рождении — ёё, паспорт — ёе, ВУ — ее, диплом — её). Когда наследство оформлял — было проще написать отказ, чем доказать, что я сын своей матери (разное написание в моем свидетельстве и ее паспорте). И у моих детей проблемы из-за моего паспорта — они по-отчеству получились Артемовичи, а не Артёмовичи.
Но тут, думаю, проблема не с кодировками, а с головами.
Но тут, думаю, проблема не с кодировками, а с головами.
У меня Ё в фамилии.
Где-то пару лет назад затеял квест по унификации всего и вся под один стандарт. За основу взял свидетельство о рождении где как раз Ё и планомерно обновил все документы.
Теперь жить стало сильно проще. Просто слежу за новыми документами и требую не ошибаться.
Жена когда меняла фамилию сразу всё контролировала и проблем нет совсем.
Где-то пару лет назад затеял квест по унификации всего и вся под один стандарт. За основу взял свидетельство о рождении где как раз Ё и планомерно обновил все документы.
Теперь жить стало сильно проще. Просто слежу за новыми документами и требую не ошибаться.
Жена когда меняла фамилию сразу всё контролировала и проблем нет совсем.
Гос. учреждения перешли с рукописных на печатные документы в конце девяностых — начале нулевых. При этом года до 2007 буква Ё не входила в их «кодировки», т.е. они физически не могли ее напечатать (интересно, что заглавную, в принципе, могли, а вот строчную — никак). И в итоге было два пути — либо не получать документ, либо получать, но с Е.
А квест по унификации доступен к прохождению для одного человека. Я выше привел пример с наследством, -чтобы там было все гладко квест надо проходить для трех поколений (чтобы документы моих родителей и моих детей «бились» с моими)
А квест по унификации доступен к прохождению для одного человека. Я выше привел пример с наследством, -чтобы там было все гладко квест надо проходить для трех поколений (чтобы документы моих родителей и моих детей «бились» с моими)
Вот что им так трудно ё напечатать?
У моего деда фамилия в паспорте была с последовательностью букв «оао», хотя у всех, кто унаследовал его фамилию включая бабушку, последовательность была «ооа». Когда пришла пора смены паспорта решил восстановить справедливость и нашли записи при рождении: «ааа». Пришлось менять фамилию по своему желанию.
Это для вас эта «тья» — странная индийская буква, а для Мукерджи «ё» странная русская буква.
Даже в регулярных выражениях (JavaScript) "ё" не попадает в диапазон [а-я].
Надо писать вот так: [а-яё], чтобы букву "ё" включить в диапазон...
НЛО прилетело и опубликовало эту надпись здесь
А мне кажется, что ничего расистского нет. Говорят же в америке «он черный», «он белый», плюс есть даже официальные документы(в Америке), обязывающие работодателей иметь на работе и черных и белых и женщие и мужчик в определенных минимальных пропорциях.
Это называется "позитивная дискриминация". То же самое, что и «негативная», только в профиль.
Для закрывающей кавычки „лапки“ (предназначено для использования внутри кавычек «ёлочек») в русском языке тоже нет отдельного символа, из-за чего приходится использовать открывающую кавычку из английского и других языков. В результате во многих шрифтах это выглядит неправильно. Очень забавно это выглядит даже здесь на Хабре — в поле ввода сообщения выглядит правильно ( ), а в самом сообщении — нет (
), а в самом сообщении — нет (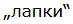 ).
).
 ), а в самом сообщении — нет (
), а в самом сообщении — нет ( ).
).Японцы еще веселее поступают. При рождении чада стараются извернуться и использовать как можно более элитные® иероглифы, чтобы их ребенок был не такой как все™. Например, имя, содержащее цифры или ★ это вообще нормально и ничего особенного.
Чтобы добавить головной боли, читаться они тоже могут нестандартно. Чтобы совсем уничтожить бюрократов, они сочиняют свои собственные иероглифы (хоть это и не очень поощряется).
Например, вот захотели назвать девочку сакурой. Из стандартного на выбор можно взять обычное написание 桜, или его устаревший вариант 櫻. Не интересно? Ну ладно, запишем хираганой, типа подчеркнув женственность: さくら. Или катаканой: サクラ. Все равно не интересно? Тогда мама придумывает записывать имя дочки как 桜, но одним штрихом меньше. Такая вот утонченность и необычность.
Бывает еще веселее: мама берет свой любимый иероглиф, например 愛, папа берет свой: 強. Они их ставят рядом 強愛 и говорят, что это будет теперь читаться как сакура. Как так? Ну вот так… нанори потому что. Мало того что у обычных иероглифов бывают десятки чтений, надо добавить еще…
Так что проблемы парня из статьи это мелочь :D
Чтобы добавить головной боли, читаться они тоже могут нестандартно. Чтобы совсем уничтожить бюрократов, они сочиняют свои собственные иероглифы (хоть это и не очень поощряется).
Например, вот захотели назвать девочку сакурой. Из стандартного на выбор можно взять обычное написание 桜, или его устаревший вариант 櫻. Не интересно? Ну ладно, запишем хираганой, типа подчеркнув женственность: さくら. Или катаканой: サクラ. Все равно не интересно? Тогда мама придумывает записывать имя дочки как 桜, но одним штрихом меньше. Такая вот утонченность и необычность.
Бывает еще веселее: мама берет свой любимый иероглиф, например 愛, папа берет свой: 強. Они их ставят рядом 強愛 и говорят, что это будет теперь читаться как сакура. Как так? Ну вот так… нанори потому что. Мало того что у обычных иероглифов бывают десятки чтений, надо добавить еще…
Так что проблемы парня из статьи это мелочь :D
Меня удивляет как у иероглифоговорящих глаза не устают читать «лохматые» символы с монитора. Особенно китайцы.
Это не символы, это своего рода хэши или QR коды для понятий. Они не читаются «по одной палочке». По своему опыту могу сказать, что это не сложнее чтения букв. Процесс очень быстро получает «аппаратную» поддержку от зрительной подсистемы а дальше все то же самое, даже проще, поскольку визуальной информации меньше. Существуют устоявшиеся иероглифические сочетания, которые легко выхватываются взглядом и уже не требуется вчитываться в каждый отдельный иероглиф. Китайцы вообще не читают, а тупо сканируют взглядом страницы целиком.
Потом, при разборе длинного слова вы наблюдаете больше штрихов, чем есть в самом сложном иероглифе.
Потом, при разборе длинного слова вы наблюдаете больше штрихов, чем есть в самом сложном иероглифе.

{kind=link}
У них при представлении принято говорить, какими кандзи записывается имя (на слух не поймешь), куда уж до автоматических систем.
Хотя встречал в MS Word функцию в поиске по тексту как «читается как:». Так что возможно специалисты из страны восходящего солнца эти проблемы для себя уже почти решили.
А фуригана в Unicode поддерживается?
Хотя встречал в MS Word функцию в поиске по тексту как «читается как:». Так что возможно специалисты из страны восходящего солнца эти проблемы для себя уже почти решили.
А фуригана в Unicode поддерживается?
А в чем, собственно, проблема-то? В том же английском вон тоже каждое второе-третье слово надо просто знать, как читается, систематики никакой. Угадать можно, но не с 100% вероятностью.
Зачем в юникоде поддерживать фуригану? Это же не какой-то специальный алфавит, а просто способ оформления. В HTML, например, есть чудесный тэг ruby и т.д.
Зачем в юникоде поддерживать фуригану? Это же не какой-то специальный алфавит, а просто способ оформления. В HTML, например, есть чудесный тэг ruby и т.д.
Про чтения-то понятно — это как раз легитимно и даже понятно, почему делается — в 出生証明書 (свидетельстве о рождении) записывают имя только с помощью kanji (вот, например), а в жизни человека будут звать все равно так, как нравится / удобнее. Какого нибудь 道根彦 (Мичинехико) все равно будут звать Ми-кун или Михи-кун и не будут извращаться. Клички и сокращения повсеместны.
А вот официальных имен с цифрами или всякими hoshi / emoji — еще ни разу не встречал. Да и придумывание новых kanji я могу представить разве что в какой-нибудь совсем дикой глубинке, где народ живет технологиями а ля 19-го века.
{kind=link}
А вот официальных имен с цифрами или всякими hoshi / emoji — еще ни разу не встречал. Да и придумывание новых kanji я могу представить разве что в какой-нибудь совсем дикой глубинке, где народ живет технологиями а ля 19-го века.
Про то, что веселее, это точно.
Вот простой иероглиф: 愛 переводится как любовь и читается «ай».
Все имена, которые записываются этим иероглифом: Азуми, Ааи, Аика, Аису, Аки, Ако, Амика, Аои, Ариса, Айа, Айу, Чигири, Чика, Чикаси, Эрина, Хаато, Хикари, Ито, Итоши, Итсуми, Идзуми, Кана, Канаэ, Канаса, Кидзуна, Кокоро, Коному, Мадока, Манабу, Манами, Медзуру, Мего, Мегу, Мегуми, Мегуму, Мей, Нару, Наруко, Нозоми, Рабу, Руи, Сара, Саран, Тсугуми, Тсукуми, Уи, Йоси, Йосики, Йосими, Йуки
Вот простой иероглиф: 愛 переводится как любовь и читается «ай».
Все имена, которые записываются этим иероглифом: Азуми, Ааи, Аика, Аису, Аки, Ако, Амика, Аои, Ариса, Айа, Айу, Чигири, Чика, Чикаси, Эрина, Хаато, Хикари, Ито, Итоши, Итсуми, Идзуми, Кана, Канаэ, Канаса, Кидзуна, Кокоро, Коному, Мадока, Манабу, Манами, Медзуру, Мего, Мегу, Мегуми, Мегуму, Мей, Нару, Наруко, Нозоми, Рабу, Руи, Сара, Саран, Тсугуми, Тсукуми, Уи, Йоси, Йосики, Йосими, Йуки
А как понять тогда по написанному иероглифу, какое это из имён? Дополнительно указывается что-то наподобие транслита? При произношении этого «ай» тоже что-то добавляется?
QR-код придумали именно для визиток, емнип
А так есть фуригана
А так есть фуригана
Пусть пишут пиньинем ромадзи и не выпендриваются. Двадцать первый век уже, нафига финикийцы придумали алфавитное письмо?
Не надо всех ровнять под одну гребенку. Письменность отражает особенность языка и адаптируется под его требования. В японском языке очень много омонимов, поэтому иероглифы носят смыслоразличающую роль, тогда как слоговая азбука давно используется для грамматических конструкций и устоявшихся выражений.
Слово можно записать азбукой, но тогда останется только догадываться, какое именно значение вкладывал автор.
В китайском то же самое: Ши Ши ши ши ши.
Слово можно записать азбукой, но тогда останется только догадываться, какое именно значение вкладывал автор.
В китайском то же самое: Ши Ши ши ши ши.
Только это (ши ши ши…) не китайский. То есть не современный китайский.
Значит переходите на английский. Зачем язык, если на нем нельзя даже различить смысл фразы без подсказки? А в устной речи как различают омонимы?
Ну, слава богу, что мозг человека понимает оммонимы. Фиг его знает — может быть ему так проще даже. Или это просто эволюционно развившаяся система опознавания «свой-чужой». Свои — это те, кто понимают язык. К ним больше доверия, чем к тем, кто не понимает «кодовую фразу», некий пароль. Сумел уловить тайный смысл фразы с оммонимом — свой. А если «перевел» по неполному словарю — чужак.
Запер замок на замок чтобы замок не замок.
Запер замок на замок чтобы замок не замок.
Там масса особенностей. Самый простой аспект — интонация, которая не отображается на письме.
примером того, что современные технологии могут не только упростить жизнь, но и осложнить её
Это как? Пришли белые люди, запретили исконо-посконую теплую ламповую бенгальскую письменность и заставили пользоваться расистским юникодом и твиттером? Не нравится — создайте свой юникод с ♠ и ☃.
Я чёт так и не понял проблему. Он вместо того чтоб печатать букву своего имени — печатает их двумя, но в итоге получает правильное графическое отображение? Это проблема? Или эту букву существующими символами Юникода вообще никак нельзя выразить?
Я так понял, он взял похожую по написанию букву из другого языка. Ну это типа как латинское i и украинское/белорусское і
Наверное, я единственный не вижу в этом проблемы. :) По мне что та i, что вторая і абсолютно одинаковы.
И всё-таки они разные :) Проблемы могут возникнуть, например, если шрифт чисто кириллический (да, это практически невероятно, но всё же). Тогда если подменить украинское і на латинское, у вас будут квадратики. Более частый случай: шрифт разработан только для латиницы, а для кириллицы подставляет какой-нибудь стандартный Arial, тогда неправильно написанная буква будет заметно выделяться.
Возможно, могут быть какие-то проблемы с привязкой символов к клавиатуре.
Ну и просто не всем приятно осознавать — что это другая буква :) К тому же в примере с бенгальским буква более сложная, чем i, и там может быть какая-то неуловимая для нас деталь, которая важна носителю языка.
Возможно, могут быть какие-то проблемы с привязкой символов к клавиатуре.
Ну и просто не всем приятно осознавать — что это другая буква :) К тому же в примере с бенгальским буква более сложная, чем i, и там может быть какая-то неуловимая для нас деталь, которая важна носителю языка.
Более частый случай: шрифт разработан только для латиницы, а для кириллицы подставляет какой-нибудь стандартный Arial, тогда неправильно написанная буква будет заметно выделяться.Вы имеете ввиду, что автор шрифта скопировал символы из какого‐то другого шрифта или библиотека, использующаяся для отображения шрифта, подставляет символы из другого шрифта? Я вроде видел и то, и то, но не скажу, какой вариант чаще — kcharselect (который я использую, в том числе, для просмотра шрифтов) не запрещает fallback на другие шрифты, а использовать fontforge (один из двух вариантов, который я знаю, который гарантированно не будет брать символы из другого шрифта (второй — rxvt-unicode, для просмотра шрифтов не годен)) мне не хочется.
Второй вариант не имеет абсолютно никакого отношения к шрифту — подстановка производится рендером и определяется его настройками (настройки могут поставляться со шрифтом, но не в самом файле шрифта).
На самом деле сколько думаю о том, как делали собственно таблицы символов — чем больше вдумываюсь, тем больше склоняюсь к мысли о том, что у подхода «один графический символ — одна и та же буква» дикое количество плюсов и почти никаких минусов. Почти все аргументы, которые типично выводятся оппонентами («тяжело сортировать», «тяжело переводить в нижний/верхний регистр» и т.п.) в итоге все равно оказываются нерелевантны.
В свое время обрадовались, что в новую кодировку можно упихнуть все символы всех языков мира, вот теперь и мучаются — впихивают невпихуемое.
Лично пользовался шрифтом, в котором толщина глифов латинского и кириллического алфавита несколько различались. Это было очень удобно.
Кроме того, что есть «один графический символ» мнения могут разниться. Есть, например, чешская/словацкая буква "č", и латышско/литовская буква "č". Они никак не различаются в юникоде. Но типографские традиции различаются, и чешская буква может выглядить так, как в Прибалтике её никогда не напишут. Но символ один, и разных шрифтов не сделать.
Ну и уж точно прекрасный пример порочности такого подхода показало чудное решение под названием Han unification. Японцы, в общем, поэтому и относятся к юникоду скептически по сей день.
Кроме того, что есть «один графический символ» мнения могут разниться. Есть, например, чешская/словацкая буква "č", и латышско/литовская буква "č". Они никак не различаются в юникоде. Но типографские традиции различаются, и чешская буква может выглядить так, как в Прибалтике её никогда не напишут. Но символ один, и разных шрифтов не сделать.
Ну и уж точно прекрасный пример порочности такого подхода показало чудное решение под названием Han unification. Японцы, в общем, поэтому и относятся к юникоду скептически по сей день.
Лично пользовался шрифтом, в котором толщина глифов латинского и кириллического алфавита несколько различались. Это было очень удобно.
С точки зрения типографских традиций — это, как минимум, нетрадиционно и по сути это 2 разных шрифта (примерно то же, что писать иностранные слова курсивом). Раз так — что мешает явно в тексте выделять другой шрифт? Все равно большинству инструментов работы с текстом нужна информация о том, на каком языке слово (для проверки правописания, расстановки переносов и т.д.)
Кроме того, что есть «один графический символ» мнения могут разниться.
На самом деле это не аргумент за или против текущего подхода формирование Unicode — вы сами же приводите контрпример, что в ряде случаев будут проблемы.
Ну и уж точно прекрасный пример порочности такого подхода показало чудное решение под названием Han unification. Японцы, в общем, поэтому и относятся к юникоду скептически по сей день.
Вы, вероятно, имели в виду китайцев. У японцев ShiftJIS и там все относительно неплохо (главная проблема с тем, что когда-то давно Microsoft решила, что можно творчески трактовать ASCII и вместо "\" показывать "¥" — и до сих пор в ряде случаев так делает, что создает некоторые проблемы с интероперабельностью).
Проблемы китайцев же условно делятся на (1) проблемы с GB/Big5, (2) проблемы с упрощенной vs традиционной записью, (3) и проблемы с тем, что язык дико фрагментирован и куча народа не могут в целом договориться о том, сколько и чего им нужно для отображения их символов на компьютерах. Проблемы (1) большей частью надуманные — ну, есть в Big5 штук 10 различных вариаций циферок-в-кружочках, циферок-в-квадратиках, -в-ромбиках — и, о ужас, юникод не прогнулся и не добавил их все, часть из них будет идти через combining. Проблемы (2) не специфичны для юникода в целом (они есть и в старых GB/Big5) и упираются по сути в то же, что и выше — для работы с текстом надо знать, на каком он языке. Проблема (3) вообще общая для всех и, субъективно, властям Китая как раз надо памятник поставить за волевое загоняние страны в светлое будущее — иначе бы так и сидели с папирусами и бамбуковыми кисточками при свете лучины.
Нет, именно японцев. Думаю, имелось в виду это: en.wikipedia.org/wiki/Han_unification#Examples_of_language-independent_characters
По ссылке — констатация того, что если кому-то сильно нужно, чтобы 与 в китайском языке и 与 в японском брались из разных шрифтов — в HTML есть соответствующий механизм. Для обывателя на самом деле проблема на уровне проблемы с одно- и двухэтажной буквой a в латинице, которая в разных шрифтах выглядит по-разному. Причем здесь *именно* японцы и где обещанные «японцы [...] относятся к юникоду скептически» — непонятно.
Из того, что я вижу чисто исторически — CJK продавливали во многом именно японцы, куда они тупо слили JIS (в форме ShiftJIS), стандартизированный по сути аж с 1969 года. Китайцы в этом плане имели отставание лет на 25-30, плюс дикий плюрализм на тему того, сколько же у нас языков-диалектов — естественно, что какое-то количество недовольных при этом всегда останется…
{kind=link}
Из того, что я вижу чисто исторически — CJK продавливали во многом именно японцы, куда они тупо слили JIS (в форме ShiftJIS), стандартизированный по сути аж с 1969 года. Китайцы в этом плане имели отставание лет на 25-30, плюс дикий плюрализм на тему того, сколько же у нас языков-диалектов — естественно, что какое-то количество недовольных при этом всегда останется…
И как решить проблему сортировки, когда схожие по начертанию буквы должны различаются по порядку?
«один графический символ — одна и та же буква»«В» и «B» — в верхнем регистре графический символ примерно одинаковый (я не отличаю на глаз), а в нижнем — это вдруг два разных: «в» и «b». Как быть?
А «Ьl» — это один графический символ"? Я напечатал там два, в моём браузере их практически не отличишь от «Ы» одной буквой.
А у буквы «I» в латинском алфавите может быть два варианта в нижнем регистре: «i» и неожиданно "ı", а для строчной «i» прописным вариантом может быть "İ", если у вас турецкая локаль.
В моём браузере в поле ввода комментария буквы «I» и «l» выглядят одинаково — это один графический символ? Но если нажать «Предпросмотр», то становится видно, что это разные буквы, так как Хабр использует другой шрифт для предпросмотра комментариев, но после отправки это снова «один графический символ».
«l» «I» "|" — палочка чуть длиннее, но это же не критично, написание можно считать одинаковым.
Грубо говоря — все сводится к двум вещам:
1) Для массы операций с текстами надо знать, на каком он языке; собственно, даже эту задачу Unicode сейчас не решает. Приведенный вами пример с турецкой I как раз очень показателен, как раз почему без этой информации жить нельзя даже в том разрезе, что получился сейчас.
2) Как определять схожесть графических символов и что признавать отдельной буквой. Вопрос в целом сложный, но решаемый. Можно смотреть на преемственность языков, можно смотреть на многообразие сложившихся шрифтовых практик и т.д. Понятно, что те же Il| объединять на основании того, что все это отдаленно «вертикальная палочка» смысла никакого.
С другой стороны — представьте, насколько легче было бы жить, если бы любой, кто вводит какой-нибудь «PECTOPAH» вводил бы эти буквы одинаково, вне зависимости от того, в какой раскладке, на какой клавиатуре и какими знаниями о языках он обладает.
1) Для массы операций с текстами надо знать, на каком он языке; собственно, даже эту задачу Unicode сейчас не решает. Приведенный вами пример с турецкой I как раз очень показателен, как раз почему без этой информации жить нельзя даже в том разрезе, что получился сейчас.
2) Как определять схожесть графических символов и что признавать отдельной буквой. Вопрос в целом сложный, но решаемый. Можно смотреть на преемственность языков, можно смотреть на многообразие сложившихся шрифтовых практик и т.д. Понятно, что те же Il| объединять на основании того, что все это отдаленно «вертикальная палочка» смысла никакого.
С другой стороны — представьте, насколько легче было бы жить, если бы любой, кто вводит какой-нибудь «PECTOPAH» вводил бы эти буквы одинаково, вне зависимости от того, в какой раскладке, на какой клавиатуре и какими знаниями о языках он обладает.
Тут всё сводится к вопросу, что считать «одним графическим символом». Для меня русская «Р» и латинская «P» — это не «один графический символ», а два похожих друг на друга символа. Да, они похожи друг на друга больше, чем «к» на «k», и ещё больше похожи, чем «k» на «ж», но где кончается похожесть и начинается идентичность?
например переменные item и іtem - это две совсем разные переменные. попробуйте найдите это в коде)))
НЛО прилетело и опубликовало эту надпись здесь
Да, это проблема. Всё должно быть максимально удобно. Не нужно заставлять людей лазить по всем таблицам Юникода в поисках букв.
Учитывая, что к консорциуму имеют непосредственное отношение правительство Бангладеш, Индии целиком и Тамил Наду отдельно, а также куча индивидуумов с именами типа Vinodh Rajan Sampath и Shriramana Sharma, заявления о дискриминации звучат просто бредово. Если все так плохо, так взяли бы и заслали своего представителя туда.
Да парень или девушка ( запутался ) просто пиар себе наводит. Все в Индии грамотные люди английский знают, и знают как свое имя латиницей вводить. Если такой вариант не подходит, то по моему есть давно бенгальская кодировка, пусть ее использует.
Зачем нужна кириллица? Одни проблемы от неё — и кодировок разных уже куча, и раскладку клавиатуры надо переключать, и самих кириллических раскладок несколько штук, да и сами пользователи некоторые буквы ленятся писать.
Перешли бы на латиницу, причём в самом минималистичном её варианте — английском, и проблем бы не было. И знаки препинания заодно отменить — всё равно мало кто знает, как ими пользоваться.
Перешли бы на латиницу, причём в самом минималистичном её варианте — английском, и проблем бы не было. И знаки препинания заодно отменить — всё равно мало кто знает, как ими пользоваться.
Кириллица ну очень не удачный пример. Уже лет 15 если не больше она есть даже в utf-8 Другое дело, что не нужно усложнять технологии из за каких то мелочей. А то так скоро будет UTF-256
Вы правы, кириллица — не нужна. Давно пора плавно всему миру переходить на унифицированные символы.
Кириллица не нужна от слова совсем.
Нужно вернуть глаголицу!
Нет, нужно писать на латинице.
Заменить латиницу на кириллицу было бы логичнее.
Кому логичнее? Сколько человек в мире пишут на латинице и сколько — на кириллице?
Даже если мы придем к едином языку для всего человечества — юникод все равно будет нужен.
Потому что «говорить/писать на одном языке» не означает «забыть всю историю и языки».
Потому что «говорить/писать на одном языке» не означает «забыть всю историю и языки».
Так не кто не запрещает писать людям на родном языке. Для этого у всех свои кодировки есть. А UTF- это как бы структура над всей пирамидой языков.
И если бенгальцы не могут свою кодировку даже настроить правильно, то причем тут UTF?
И если бенгальцы не могут свою кодировку даже настроить правильно, то причем тут UTF?
Помнить о них будет только парочка историков, которые могут использовать хоть по килобайту на символ.
Я пока на Шри-Ланке жил, попытался закрепить знания сингальского небольшой веб-страничкой. Не смог: символы-то вроде все есть, а вот порядок применения гласных к согласным как-то не очень определён и разнится от редактора к редактору. Рисовать же, само собой, поленился.
А письменность сингальского сильно проще того же бенгальского.
А письменность сингальского сильно проще того же бенгальского.
Даже я страдаю, так как в моей фамилии есть буква ё, но раньше её не было на печатных машинках и в свидетельстве о рождении, буква е, потом и в паспорт перекочевала, но самое ужасное это попало в загранпаспорт где теперь транскрибируется во, что то непотребное.
ЗЫ по этому я наверное так ратую за запрет написания буквы е вместо ё.
ЗЫ по этому я наверное так ратую за запрет написания буквы е вместо ё.
Это были совсем неправильные печатные машинки, в правильных машинках буква «Ё» следовала за «Ю».
Я даже не уверен, что «неправильные» существовали вообще.
Я даже не уверен, что «неправильные» существовали вообще.
1. Мне так в паспортном столе объяснили, может быть и выдумали.
2. ru.wikipedia.org/wiki/%D0%9F%D0%B8%D1%88%D1%83%D1%89%D0%B0%D1%8F_%D0%BC%D0%B0%D1%88%D0%B8%D0%BD%D0%BA%D0%B0:
Ну и там есть ещё и картинки. ЗЫ когда я ещё пользовался машинкой, у неё то же не было Ё. :( Модель не вспомню.
2. ru.wikipedia.org/wiki/%D0%9F%D0%B8%D1%88%D1%83%D1%89%D0%B0%D1%8F_%D0%BC%D0%B0%D1%88%D0%B8%D0%BD%D0%BA%D0%B0:
Портативные машинки помещались в небольшом чемоданчике и предназначались для людей «творческих профессий» (журналистов, писателей и т. д.). Некоторые портативные машинки имели более мелкий шрифт, чем на канцелярских машинках. Канцелярские и пишущие машинки отличались также числом клавиш, которое у русских пишущих машинок могло составлять от 42 до 46. Уменьшение числа клавиш достигалось за счёт отказа от клавиши с буквой «Ё», использования омографии некоторых букв и цифр (вместо цифры «0» могла использоваться буква «О», вместо «3» — «З»), и некоторых других сокращений.
Ну и там есть ещё и картинки. ЗЫ когда я ещё пользовался машинкой, у неё то же не было Ё. :( Модель не вспомню.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Не каждый человек может написать своё имя в Юникоде