Для дотошных
В последнее время в среде разработчиков серверных приложений часто возникают споры о том, как лучше управлять фалами и какая технология обеспечивает более быстрые чтение/запись файлов. В сети стали появляться статьи и статейки о сравнительной производительность локальной файловой системы и GridFS. Или о хранении файлов в реляционной базе как BLOB против хранения на жёстком диске в файловой системе. Вот и я решил ввязаться в этот противостояние. Сегодня мы будем сравнивать производительность и накладные расходы MongoDB 2.6.7 x64 GridFS против MS SQL Server Express 2012 v11.0.5058.0 x64 против NTFS. Для эксперимента была использована платформа Windows 7 x64 SP1 на AMD Athlon(tm) II X2 250 Processor 3.00 GHz c 4ГБ ОЗУ 1033 MHz и HDD 600 Gb SATA 6Gb/s Western Digital VelociRaptor 10000rpm 32Mb. После каждого теста компьютер перезапускался, а базы обнулялись. Производительность будем рассматривать на примере файлового сервера на C# под .NET 4.5, код которого прикреплён к статье.
Ближе к делу
В ходе теста попробуем сохранить 1000 файлов по 10000000 байт. Каждый загруженный файл будет регистрироваться в таблице “Files”: “Hash” используется для проверки, был ли уже такой файл загружен, “NewName” связывает информацию о файле с его битовым образом на сервере в таблице “FileMapping”. Схема базы данных файлового сервера:
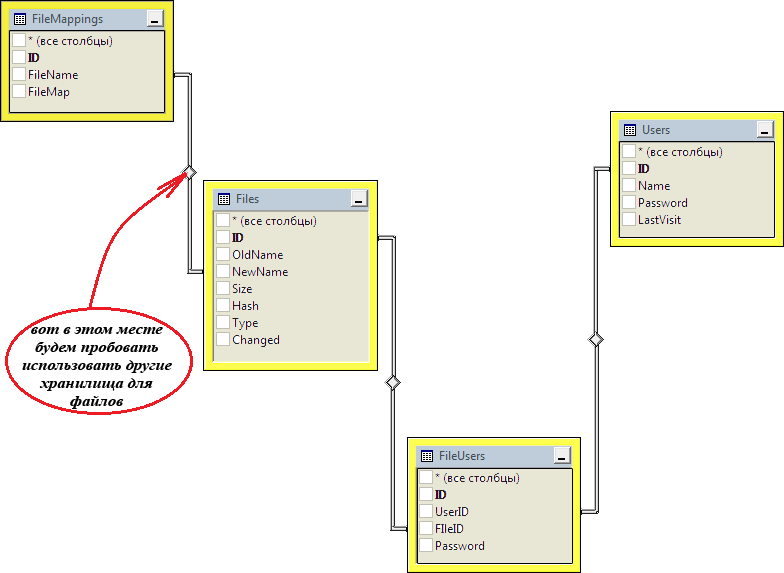
Вместе с этим будем пробовать хранить файлы в GridFS, используя официальный драйвер MongoDB и просто на жёстком диске с помощью класса FileInfo из библиотеки классов .NET. Для получения возможности удобного построения «человекупонятных» запросов к SQL Server с помощью технологии LINQ и лямбда-выражений будем использовать Entity Framework 6.0:

Однопоточная запись
Для начала, протестируем сохранение просто на диск, загружая фалы в однопоточном режиме. По итогам пяти запусков, на проведение операций потребовалось: 164751, 165095, 164611, 165937 и 166296 миллисекунд. Максимальная разница между результатами составила около 1%. Значит, в среднем процесс работал 165338 миллисекунд из которых 52966 – время на регистрацию файла, 12685 – время на запись файла:
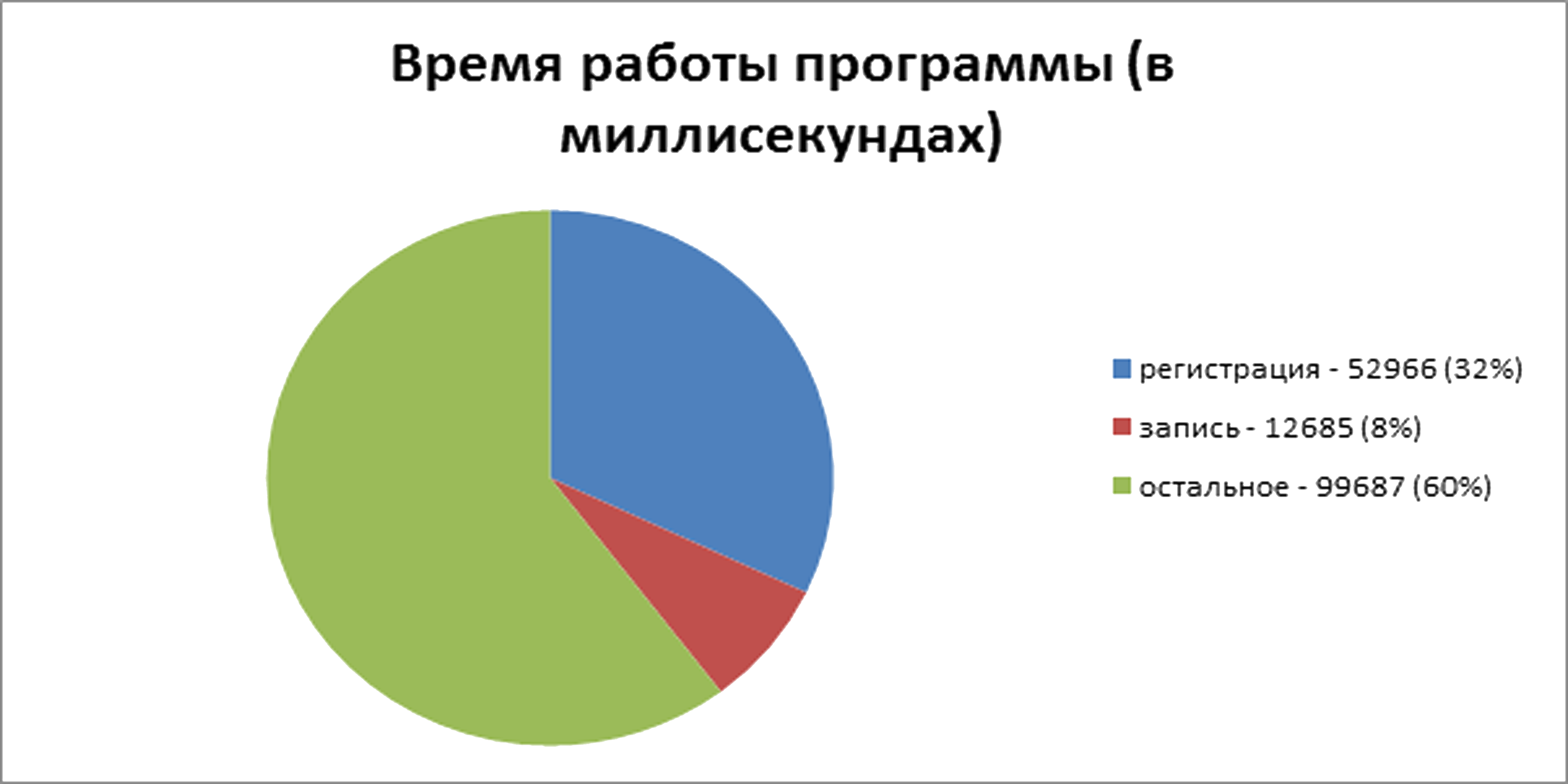
Запуск программы с измерением времени работы её частей и без измерения не привёл к получению разных результатов. Запуск программы с браузером потоков показал, что максимальный занимаемый размер оперативной памяти составил 59796 KB. Объём занятый на диске: примерно 9,3 ГБ. Для простоты далее буду приводить сразу средний результат времени выполнения операций и в секундах.
Теперь протестируем запись файлов в базу данных SQL Server. Размер получившейся БД на диске составил примерно 9,8 ГБ. В пике программа заняла 233432 KB, а СУБД – 1627048 KB. Программа работала в среднем 998 секунд. Из них 34 секунды на регистрацию файла и 823 секунды на запись:

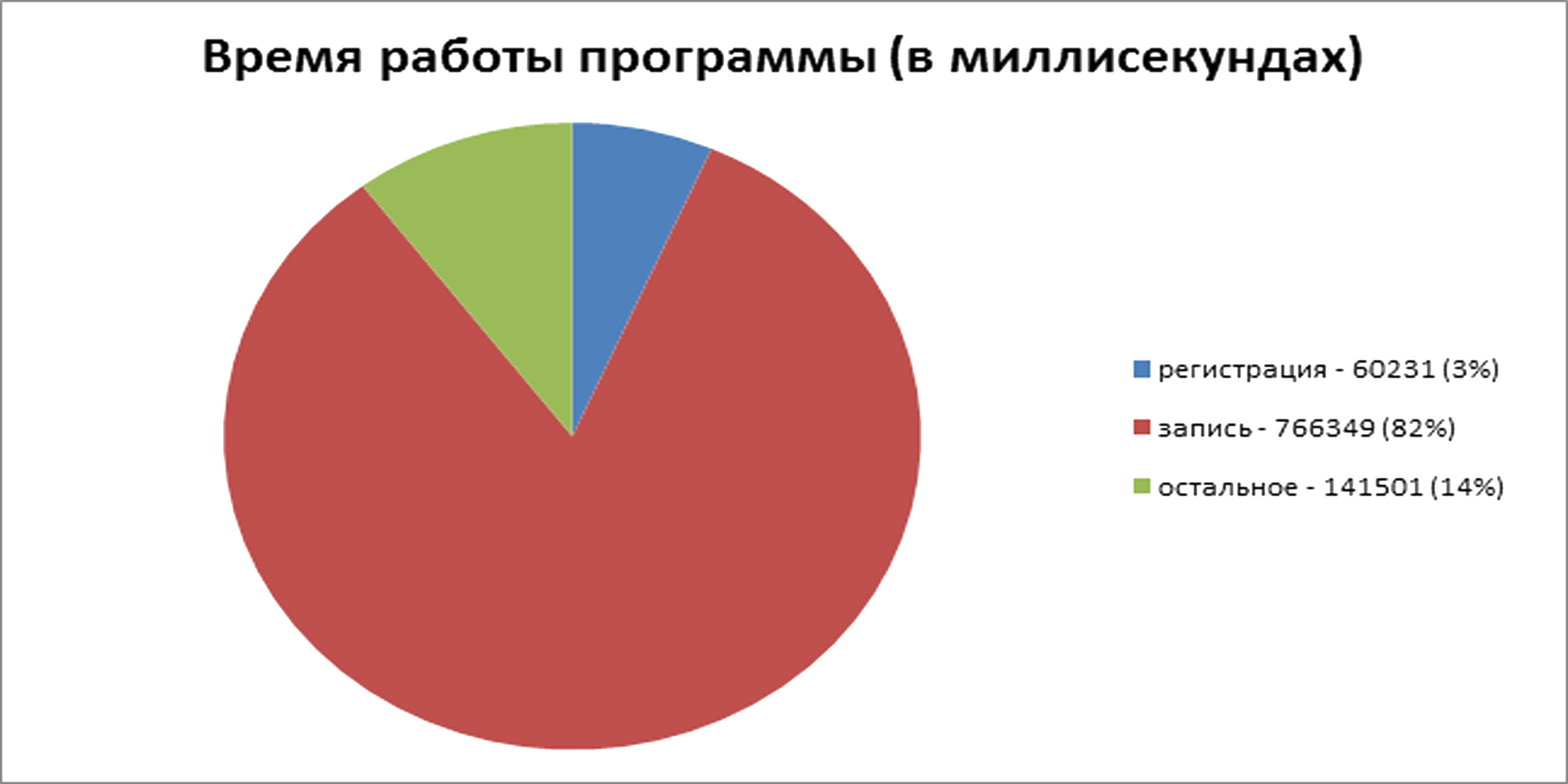
Далее пришла очередь GridFS. Занятое место на диске – примерно 12 ГБ. Израсходовала MongoDB всю оперативную память, до которой добралась. При этом потребление памяти SQL Server и нашим сервером осталось в пределах обычных значений, которыми можно, в данной ситуации, пренебречь. Всё выполнилось примерно за 921 секунду. На регистрацию – 60 секунд, на запись – 766 секунд:
Многопоточная запись
Здесь мы столкнулись с первыми трудностями: когда несколько потоков вытаются установить соединение с СУБД одновременно, возникают ошибки. И если работа с MongoDB идёт «без подтверждения» — драйвер не выдаёт ошибку и продолжает работу и всё проходит гладко, то EF при одновременном вызове «CreateIfNotExists» показывает кучу отладочной информации, выдаёт ошибку, не отлавливающуюся с помощью try-catch и завершает процесс с ошибкой. При этом, ошибка не появляется если скомпилировать и запустить вместе с отладчиком из среды разработки. Проблема решилась синхронизацией потоков и установлением соединений с СУБД поочерёдно.
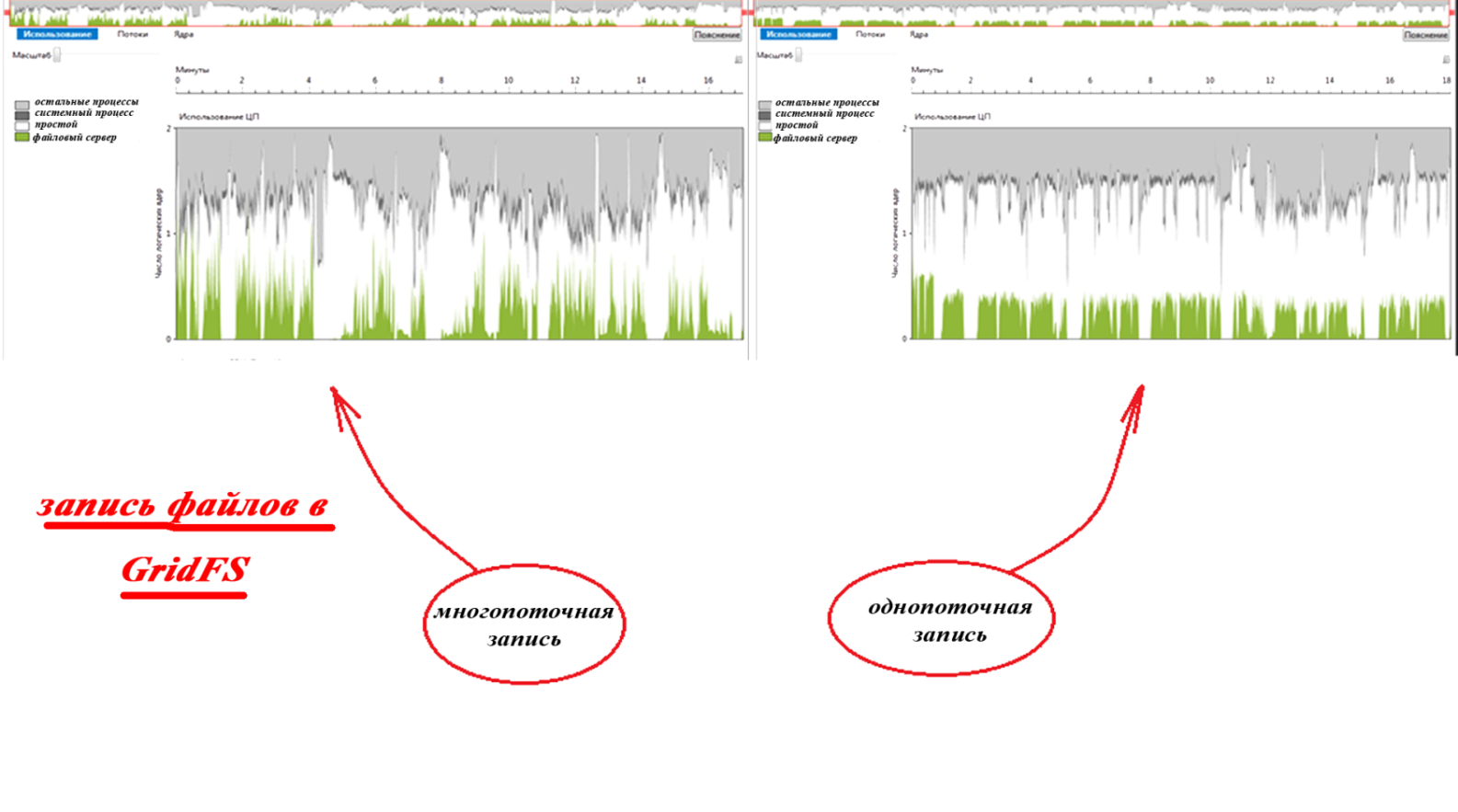
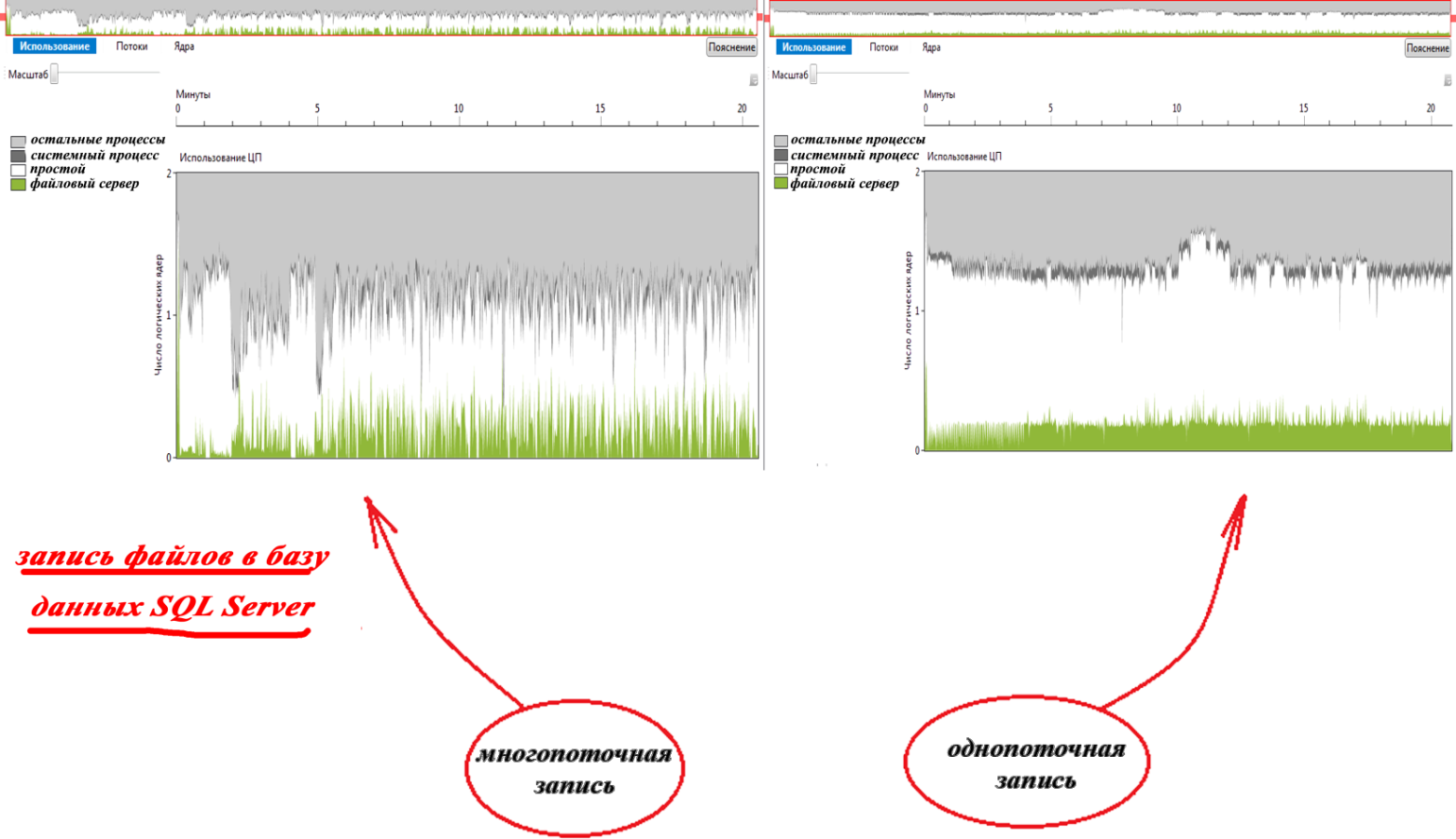
Проведём операции записи используя для записи 20 потоков по 50 файлов на каждый. Тестирование GridFS показало сильный разброс: 716259, 623205, 675829, 583331 и 739815 миллисекунд, что в среднем составило 668 секунд. Как видно, при тех же накладных расходах, времени на выполнение потребовалось меньше. Это объясняется меньшим временем простоя, что показано визуализатором параллелизма на графиках использования вычислительных ядер ЦП (выполнение с использованием визуализатора параллелизма заняло значительно больше времени):
При записи файлов напряму в файловую систему разброс полученных тестовых значений был не большой и среднее значение составило 170 секунд. Как видно, разница между однопоточной и многопоточной записью на диск составила менее 3%. Потому графики использования ЦП для данного случая считаю целесообразным опустить.
Многопоточная запись файлов Базу данных SQL Server привела к дополнительным проблемам: При нагрузке происходила ошибка в некоторых потоках из-за выхода таймаута ожидания. В результате чего соединение обрывалось, процесс завершался с ошибкой а база данных приводилась к несогласованному состоянию. На тысячу запросов первая попытка заканчивалась неудачей примерно в 40 случаях. Из них около двух заканчивались неудачей и при второй попытке. Проблема решилась увеличением таймаута до 30 секунд и повторными попытками соединения при неудаче.
При многопоточном сохранении 1000 файлов с использованием SQL Server разброс по времени был менее 5%, а результат составил в среднем 840 секунд. Это почти на 16% быстрее, чем в однопоточном режиме:
Чтение файлов
Теперь протестируем чтение файлов из разных хранилищ. В однопоточном режиме мы считаем все файлы подряд, а в многопоточном – в 20 потоков по 50 случайных файлов каждый. Традиционно по 5 попыток каждого типа:

Чтение файлов из базы SQL Server не прошла гладко с первого раза. Entity Framework при каждом запросе к базе на выборку данных кеширует результат на стороне клиентского приложения. И, хотя CLR подразумевает автоматическую «сборку мусора», память быстро расходуется, что приводит к ошибке «OutOfMemory» и аварийному завершению процесса. Это происходит из-за того, что EF самостоятельно не обрабатывает данный тип исключений и не удаляет данные из «кеша» даже при израсходовании всей памяти. А выполняя запросы к таблицам, хранящим файлы, это становится критически важным. Проблема разрешилась отключением в кеширования в коллекциях сущностей «FileMapping» с помощью установки «AsNoTracking».
Итого
Мы имеем изнасилованный жёсткий диск и следующую сводную таблицу:
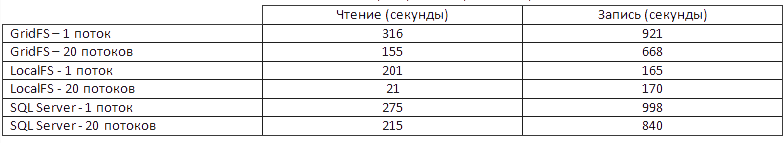
Бонус
Стараясь предвосхитить возможную критику и заранее ответить на пока незаданные вопросы, немного погодя, дополняю статью некоторыми интересными (я надеюсь) и быть может полезными замечаниями. Первое: если базу не сбрасывать перед каждым новым тестом, то производительность сколько-либо ощутимо не изменится. По крайней мере, ни при втором, ни при третьем и ни при повторных многократных (в разумных приделах) прогонах разницы в результатах получить не удалось. А потому опустим подробное описание этой части работы, как самое скучное.
Второе: многие наверняка скажут, что при работе с СУБД через сокеты, данные для передачи должны будут пройти по всему стеку протоколов сетевого взаимодействия туда и обратно. Поэтому мы рассмотрим ещё один вариант. На самом деле тот же вариант с классом FileInfo, только обраться к нему теперь будем с помощью .NET Remouting, если вы понимаете о чём я:








