Комментарии 46
Также во многих формулах, где встречаются факториалы, они встречаются в виде частного. Если имеем N!/M!, при близких M и N, частное может быть не очень большим по абсолютной величине и содержать мало множителей, даже если m и n по отдельности большие и требуют длинной арифметики для их вычисления.
static BigInteger FactFast(int n) {
int p=0,c=0;
while((n >> p) > 1) {
p++; c += n >> p;
}
BigInteger r=1;
int k=1;
for(;p>=0;p--){
int n1=n >> p;
BigInteger x=1;
int a=1;
for(;k<=n1;k+=2){
if((long)a*k < int.MaxValue) a*=k;
else{
x*=a; a=k;
}
}
r*=BigInteger.Pow(x*a,p+1);
}
return r << c;
}
Там для каждого нечётного k считается наибольшее p, для которого k*2^p <= n, перемножаются все k, для которых p одинаковы, и произведение возводится в степень p+1. Потом всё это перемножается, и в конце умножается на нужную степень двойки (показатель равен n/2+n/4+n/8+....)
У меня еще была мысль вычислять n! как n! = ((n / 2)!)2 * d, где d — множители, потерянные при целочисленном делении, но до алгоритма дело не дошло
— Берётся FactFactor
— перемножаются все простые числа, которые надо возводить в одну и ту же степень
— каждое из этих произведений возводится в нужную степень
— и результаты перемножаются.
При этом получается меньше всего повторных умножений, дающих длинные результаты (если A и B — числа длины N, то на подсчёт (A*B)^4 мы затратим 21*N^2 операций, а на A^4*B^4 — 26*N^2)
Правда, на 50000! я выигрыша не увидел, но на 100000! он составил уже около 2%.
stackoverflow.com/questions/9815252/why-is-math-factorial-much-slower-in-python-2-x-than-3-x
В абсолютных значениях в Python3 факториал от 50000 на стареньком Q6600 считается за ~97 мс.
static BigInteger FactNaiveTuned(int n)
{
if (n <= 1)
return 1;
BigInteger r1 = 1, r2 = 1, r3 = 1, r4 = 1;
int i;
for (i = n; i > 4; i -= 4)
{
r1 *= i;
r2 *= i - 1;
r3 *= i - 2;
r4 *= i - 3;
}
int mult = i == 4 ? 24 : i == 3 ? 6 : i == 2 ? 2 : 1;
return (r1*r2)*(r3*r4)*mult;
}
const int threadCount = 2; static Task<BigInteger> AsyncProdTree(int l, int r) { return Task<BigInteger>.Run(() => ProdTree(l, r)); } static BigInteger FactThreadingTree(int n) { if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; if (n < threadCount+1) return ProdTree(2, n); Task<BigInteger>[] tasks = new Task<BigInteger>[threadCount]; tasks[0] = AsyncProdTree(2, n / threadCount); for (int i = 1; i < threadCount; i++) { tasks[i] = AsyncProdTree(((n / threadCount) * i) + 1, (n / threadCount) * (i + 1)); } Task<BigInteger>.WaitAll(tasks); BigInteger result = 1; for (int i = 0; i < threadCount; i++) { result *= tasks[i].Result; } return result; }
FactNaive: 2.2
FactTree: 1.1
FactFactor: 1.1
FactThreadingTree: 0.9
2-25000: 00:00:00.2458574
25001-50000: 00:00:00.3246583
finalizing: 00:00:00.5395141
total: 00:00:00.8882113
И быстрее 0.54 получить не получится ну никак.
1. Считаешь факториал до предельного числа и записываешь данные в файл.
2. Из файла переносишь данные в массив в коде программы, и по когда нужно значение факториала, просто выводить значение массива, на нужно позиции.
Скорость не засекал.
Подобный пример, кажется у кнута был с поиском номеров телефонов за очень быстрое время. Где номер ячейки памяти был равен номеру телефона. Создавая по такому принципу все будет ок.

Идея проста, в цикле с шагом 2 считаем произведения i * (i+1) в обычной арифметике, а потом в длинной арифметике добавляем произведение к результату.
package main
import (
«fmt»
«math/big»
«os»
«strconv»
«time»
)
func main() {
fmt.Print(«введите N >»)
bufer := make([]byte, 80)
length, err := os.Stdin.Read(bufer)
if err != nil {
os.Exit(1)
}
razmern, err := strconv.Atoi(string(bufer[:length-2]))
if err != nil {
os.Exit(2)
}
MMM := int32(razmern)
factor1(MMM)
factor2(MMM)
}
func factor1(NN int32) {
var ii int32
rez := big.NewInt(1)
START := time.Now()
for ii = 2; ii <= NN; ii++ {
temp := new(big.Int)
temp.Mul(rez, big.NewInt(int64(ii)))
rez = temp
}
fmt.Printf(«время расчета %v сек\n», time.Since(START).Seconds())
//fmt.Println(«N=», NN, " N!=", rez)
return
}
func factor2(NN int32) {
// только для четных NN
var ii int64
var wsp int64
rez := big.NewInt(2)
START := time.Now()
for ii = 3; ii <= int64(NN); ii = ii + 2 {
wsp = ii * (ii + 1)
temp := new(big.Int)
temp.Mul(rez, big.NewInt(int64(wsp)))
rez = temp
}
fmt.Printf(«время расчета %v сек\n», time.Since(START).Seconds())
//fmt.Println(«N=», NN, " N!=", rez)
return
}
Базовый вариант для 50000! отработал за 1.58 сек, ускоренный за 0.781
второй вариант работает только для четных чисел, но его легко подправить и для нечетных.
golang я только пробую, поэтому качество кода возможно не ах.
The time to compute 20,000! using gmaxfact or gkg and pentium-4 (Пентиум-4, Карл!) GMP arithmetic is about 0.021 seconds.
А если применить разложение на простые множители, получится 15 мс: By intertwining a prime-number sieve with the computation, we can beat the split-recursive idea as embodied in programs kg and gkg also using GMP, by about 25 percent, for numbers of the size of 20,000!..
Основной вывод — используйте GMP. И вот почему: A simple profiling of factorial of 20,000 shows that most of these algorithms use 98 percent or more of their time in bignumber multiplication.
Сейчас попробовал C++ и GMP, получил такие результаты:
n = 50000
Naive: 271 ms
Tree: 23 ms
Factor: 81 ms
Check: ok
Получается, у Майкрософта квадратичное умножение, но довольно странно оптимизированное для умножения на «короткое число» (которое помещается в одну «ячейку» длинного). Наверное добавлю этот момент в статью.
from timeit import timeit
def naive_factorial(n):
res = 1
for i in range(2, n + 1):
res *= i
return res
def bin_pow_factorial(n):
def eratosthenes(N):
simp = [2]
nonsimp = set()
for i in range(3, N + 1, 2):
if i not in nonsimp:
nonsimp |= {j for j in range(i * i, N + 1, 2 * i)}
simp.append(i)
return simp
def calc_pow_in_factorial(a, b):
res = 0
while a:
a //= b
res += a
return res
fact_pows = [(x, calc_pow_in_factorial(n, x)) for x in reversed(eratosthenes(n+1))]
if len(fact_pows) % 2 == 1:
fact_pows.append((1, 1))
mul = [fact_pows[i][0] ** fact_pows[i][1] * fact_pows[-i-1][0] ** fact_pows[-i-1][1] for i in range(len(fact_pows)//2)]
while len(mul) > 1:
if len(mul) % 2 == 1:
mul.append(1)
mul = [mul[i] * mul[-i-1] for i in range(len(mul)//2)]
return mul[0]
N = 50000
REPEATS = 10
setup = 'from __main__ import N, naive_factorial, bin_pow_factorial'
print(timeit(stmt = 'naive_factorial(N)', setup=setup, number=REPEATS)/REPEATS)
print(timeit(stmt = 'bin_pow_factorial(N)', setup=setup, number=REPEATS)/REPEATS)
>>>
3.6880629397247233
0.45309165938008744
Результат тестирования функции Factorial:

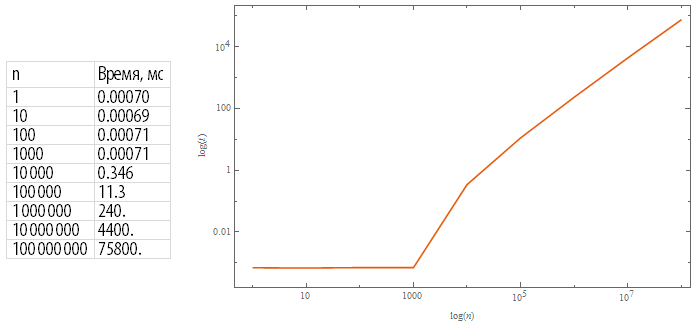
times=Table[{10^n,1000RepeatedTiming[(10^n)!;,5][[1]]},{n,0,8}];
Row@{Grid[{{n,"Время, мс"}}~Join~({#[[1]],NumberForm[#[[2]],5]}&/@times),ItemStyle->Directive[FontSize -> 20,FontFamily->"Myriad Pro Cond"],Alignment->{Left,Center},Frame->All,FrameStyle->LightGray]," ",ListLogLogPlot[times,Joined->True,PlotRange->All,FrameLabel->{Log[n],Log[t]},ImageSize->500,PlotTheme->"Scientific"]}Например сделать два цикла:
первый от 2 до N/2 — как есть,
второй от N/2 + 1 до N — оставить только решето Эратосфена
from timeit import timeit
def ProdTree(l,r):
if (l > r):
return 1
if (l == r):
return l
if (r - l == 1):
return l * r
m = int((l + r) / 2)
return ProdTree(l, m) * ProdTree(m + 1, r)
def factorial(n):
if (n < 0):
print ("Значение должно быть положительным целым числом, а не %s %s" %(n, type(n)))
if (n == 0):
return 1
if (n == 1 or n == 2):
return n
return ProdTree(2, n)
n = 10
REPEATS = 5
print(str(n) + '! = ' + str(factorial(n)))
setup = 'from __main__ import n, factorial'
print(timeit(stmt = 'factorial(n)', setup=setup, number=REPEATS)/REPEATS)
Время вышло 1.4532455200833196e-05
при n= 50000 не дождалась, не хватило терпения
Вчера на собесе была задача (1 час на решение, гуглить нельзя):
Написать код на C# рассчитывающий факториал числа 2000 и вывести результат в консоль в десятичной системе счисления.
Из стандартных типов разрешается использовать только int32.
Нагуглил ответ для проверки:
https://zeptomath.com/calculators/factorial.php?number=2000&hl=ru
Факториал 2000 содержит 5 736 цифр. Количество нулей в конце - 499.
Т.е. все алгоритмы где есть хоть какое-то, собственно, умножение в стандартные типы данных не подходят. Мне пришел в голову только алгоритм который оперирует числами хранящихся в строках и делать в них умножение в столбик. Но представил сколько это займет времени и решил слиться с собеса. Т.к. это две различные профессии -
1) придумать алгоритм или знать и применить один из известных - тут нужен человек уровня Кнута или крутого олимпиадника из топового мат вуза, т.е. матан, дифуры и прочая "Нобелевка" по математике.
2) Нагуглить алгоритм и реализовать его оптимально с т.з. языка и ограничений - стандартная задача для программиста уровня выше джуниор.
1 - это точно не для меня, а 2 могу сделать, но т.к. гуглить нельзя, то пас.
PS: собес в Москве на Разработчик C# / Python (от 300 000 до 500 000 руб. на руки)
FinTech компания, специализирующаяся на разработке программного обеспечения для финансовых организаций, применяющих в своей деятельности алгоритмические и высокочастотные стратегии (HFT) на биржевых и внебиржевых рынках.
На самом деле от вас требовалось не реализовать очень быстрый алгоритм, наивный вариант решения вероятно подошел бы по времени. Идея данной задачи именно в том, чтобы вы реализовали упрощенный класс BigInt.
Да, гуглится много статей как использовать самописный BigInt и умножать очень длинные числа, например, методом Карацубы: https://habr.com/ru/post/124258/
Но, думаю, 1) придумать алгоритм 2) реализовать его 3) отладить код и проверить на основных кейсах
.... За 1 час ОЧЕНЬ проблематично... конечно, если ты не безумный олимпиадник :)
Решить эту задачу за час вполне реально, у меня получилось за минут 15-20
Достаточно додуматься или знать заранее несколько вещей:
Если хранить несколько цифр в одной переменной (в нашем случае достаточно 4, т. к. 2000 < 10000, и 9999 * 9999 + 9999 влезает в int32), то задача значительно упрощается. Вместо умножения двух многозначных чисел, нам требуется умножать многозначное число на цифру (цифра от 0 до 9999). То есть вместо 10-ной, мы работаем в 10000-ной системе счисления.
Хранить цифры лучше в обратном порядке, чтобы было удобнее добавлять новые. Перед выводом число нужно развернуть и не забыть вывести лидирующие нули перед всеми цифрами, кроме первой.
Вот решение на плюсах, на шарпе скорее всего будет что-то похожее
#include <iostream>
#include <vector>
#include <algorithm>
#include <iomanip>
using namespace std;
int main() {
vector<int> d = {1};
d.reserve(2000);
for (int i = 2; i <= 2000; ++i) {
int o = 0;
for (int j = 0; j < d.size(); ++j) {
o += d[j] * i;
d[j] = o % 10000;
o /= 10000;
}
if (o > 0) {
d.push_back(o);
}
}
reverse(d.begin(), d.end());
cout << d[0];
for (int i = 1; i < d.size(); ++i) {
cout << setw(4) << setfill('0') << d[i];
}
cout << endl;
return 0;
}
p.s. Олимпиадник в прошлом
p.p.s. На практике эти знания вряд ли пригодятся
Алгоритмы быстрого вычисления факториала