Задача распознавания физической активности пользователей (Human activity Recognition или HAR) попадалась мне раньше только в качестве учебных заданий. Открыв для себя возможности Caret R Package, удобной обертки для более 100 алгоритмов машинного обучения, я решил попробовать его и для HAR. В UCI Machine Learning Repository есть несколько наборов данных для таких экспериментов. Так как тема с гантелями для меня не очень близка, я выбрал распознавание активности пользователей смартфонов.
Данные в наборе получены от тридцати добровольцев с закрепленным на поясе Samsung Galaxy S II. Сигналы с гироскопа и акселерометра были специальным образом обработаны и преобразованы в 561 признак. Для этого использовалась многоступенчатая фильтрация, преобразование Фурье и некоторые стандартные статистические преобразования, всего 17 функций: от математического ожидания до расчета угла между векторами. Подробности обработки я упускаю, их можно найти в репозитории. Обучающая выборка содержит 7352 кейса, тестовая – 2947. Обе выборки размечены метками, соответствующими шести активностям: walking, walking_up, walking_down, sitting, standing и laying.
В качестве базового алгоритма для экспериментов я выбрал Random Forest. Выбор был основан на том, что у RF есть встроенный механизм оценки важности переменных, который я хотел испытать, так как перспектива самостоятельно выбирать признаки из 561 переменной меня несколько пугала. Также я решил попробовать машину опорных векторов (SVM). Знаю, что это классика, но ранее мне её использовать не приходилось, было интересно сравнить качество моделей для обоих алгоритмов.
Скачав и распаковав архив с данными, я понял что с ними придется повозиться. Все части набора, имена признаков, метки активностей были в разных файлах. Для загрузки файлов в среду R использовал функцию read.table(). Пришлось запретить автоматическое преобразование строк в факторные переменные, так как оказалось, что есть дубли имен переменных. Кроме того, имена содержали некорректные символы. Эту проблему решил следующей конструкцией с функцией sapply(), которая в R часто заменяет стандартный цикл for:
Склеил все части наборов при помощи функций rbind() и cbind(). Первая соединяет строки одинаковой структуры, вторая колонки одинаковой длины.
После того как я подготовил обучающую и тестовую выборки, встал вопрос о необходимости предобработки данных. Используя функцию range() в цикле, рассчитал диапазон значений. Оказалось, что все признаки находятся в рамках [-1,1] и значит не нужно ни нормализации, ни масштабирования. Затем проверил наличие признаков с сильно смещенным распределением. Для этого воспользовался функцией skewness() из пакета e1071:
Apply() — функция из той же категории, что и sapply(), используется, когда что-то нужно сделать по столбцам или строкам. train_data[,-1] — набор данных без зависимой переменной Activity, 2 показывает что нужно рассчитывать значение по столбцам. Этот код выводит три худшие переменные:
Чем ближе эти значения к нулю, тем меньше перекос распределения, а здесь он, прямо скажем, немаленький. На этот случай в caret есть реализация BoxCox-трансформации. Читал, что Random Forest не чувствителен к подобным вещам, поэтому решил признаки оставить как есть и заодно посмотреть, как с этим справится SVM.
Осталось выбрать критерий качества модели: точность или верность Accuracy или критерий согласия Kappa. Если кейсы по классам распределены неравномерно, нужно использовать Kappa, это та же Accuracy только с учетом вероятности случайным образом «вытащить» тот или иной класс. Сделав summary() для столбца Activity проверил распределение:
Кейсы распределены практически поровну, кроме может быть walking_down (кто-то из добровольцев видимо не очень любил спускаться по лестнице), а значит можно использовать Accuracy.
Обучил модель RF на полном наборе признаков. Для этого была использована следующая конструкция на R:
Здесь предусмотрена k-fold кросс-валидация с k=5. По умолчанию обучается три модели с разным значением mtry (кол-во признаков, которые случайным образом выбираются из всего набора и рассматриваются в качестве кандидата при каждом разветвлении дерева), а затем по точности выбирается лучшая. Количество деревьев у всех моделей одинаково ntree=100.
Для определения качества модели на тестовой выборке я взял функцию confusionMatrix(x, y) из caret, где x – вектор предсказанных значений, а y – вектор значений из тестовой выборки. Вот часть её выдачи:
Обучение на полном наборе признаков заняло около 18 минут на ноутбуке с Intel Core i5. Можно было сделать в несколько раз быстрее на OS X, задействовав при помощи пакета doMC несколько ядер процессора, но для Windows такой штуки нет, на сколько мне известно.
Caret поддерживает несколько реализаций SVM. Я выбрал svmRadial (SVM с ядром – радиальной базисной функцией), она чаще используется c caret, и является общим инструментом, когда нет каких-то специальных сведений о данных. Чтобы обучить модель с SVM, достаточно поменять значение параметра method в функции train() на svmRadial и убрать параметры do.trace и ntree. Алгоритм показал следующие результаты: Accuracy на тестовой выборке – 0.952. При этом обучение модели с пятикратной кросс-валидацией заняло чуть более 7 минут. Оставил себе заметку на память: не хвататься сразу за Random Forest.
Получить результаты встроенной оценки важности переменных в RF можно при помощи функции varImp() из пакета caret. Конструкция вида plot(varImp(model),20) отобразит относительную важность первых 20 признаков:
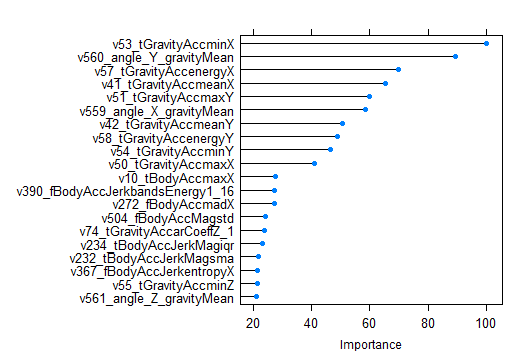
«Acc» в названии обозначает, что эта переменная получена при обработке сигнала с акселерометра, «Gyro», соответственно, с гироскопа. Если внимательно посмотреть на график, можно убедиться, что среди наиболее важных переменных нет данных с гироскопа, что лично для меня удивительно и необъяснимо. («Body» и «Gravity» это два компонента сигнала с акселерометра, t и f временной и частотный домены сигнала).
Подставлять в RF признаки, отобранные по важности, бессмысленное занятие, он их уже отобрал и использовал. А вот с SVM может получиться. Начал с 10% наиболее важных переменных и стал увеличивать на 10% каждый раз контролируя точность, найдя максимум, сократил шаг сначала до 5%, потом до 2.5% и, наконец, до одной переменной. Итог – максимум точности оказался в районе 490 признаков и составил 0.9545 что лучше значения на полном наборе признаков всего на четверть процента (дополнительная пара правильно классифицированных кейсов). Эту работу можно было бы автоматизировать, так в составе caret есть реализация RFE (Recursive feature elimination), он рекурсивно убирает и добавляет по одной переменной и контролирует точность модели. Проблем с ним две, RFE работает очень медленно (внутри у него Random Forest), для сходного по количеству признаков и кейсов набора данных, процесс бы занял около суток. Вторая проблема — точность на обучающей выборке, которую оценивает RFE, это совсем не тоже самое, что точность на тестовой.
Код, который извлекает из varImp и упорядочивает по убыванию важности имена заданного количества признаков, выглядит так:
Для очистки совести решил попробовать еще какой-нибудь метод отбора признаков. Выбрал фильтрацию признаков на основе расчета information gain ratio (в переводе встречается как информационный выигрыш или прирост информации), синоним дивергенции Кульбака-Лейблера. IGR это мера различий между распределениями вероятностей двух случайных величин.
Для расчета IGR я использовал функцию information.gain() из пакета FSelector. Для работы пакета нужна JRE. Там, кстати, есть и другие инструменты, позволяющие отбирать признаки на основе энтропии и корреляции. Значения IGR обратны «расстоянию» между распределениями и нормированы [0,1], т.е. чем ближе к единице, тем лучше. После вычисления IGR я упорядочил список переменных в порядке убывания IGR, первые 20 выглядели следующим образом:
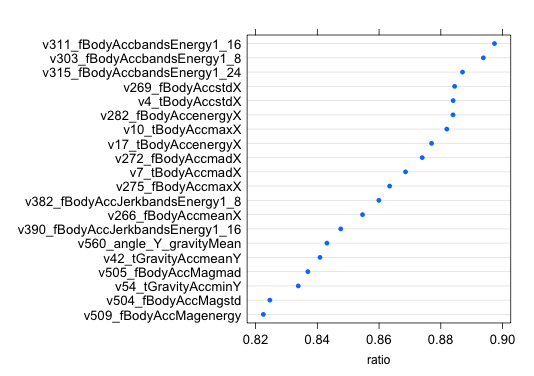
IGR дает совсем другой набор «важных» признаков, с важными совпали только пять. Гироскопа в топе снова нет, зато очень много признаков с X компонентой. Максимальное значение IGR – 0.897, минимальное – 0. Получив упорядоченный перечень признаков поступил с ним также как и с важностью. Проверял на SVM и RF, значимо увеличить точность не получилось.
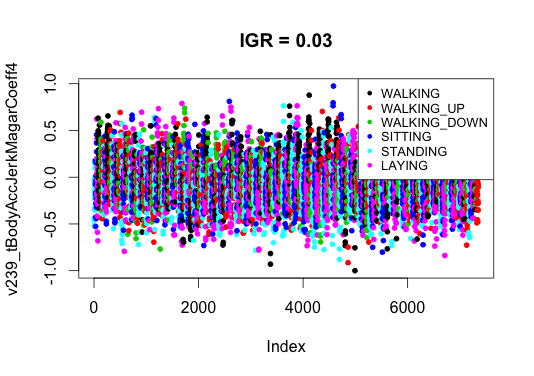
Думаю, что отбор признаков в похожих задачах работает далеко не всегда, и причин здесь как минимум две. Первая причина связана с конструированием признаков. Исследователи, которые подготовили набор данных, старались «выжить» всю информацию из сигналов с датчиков и делали это наверняка осознанно. Какие-то признаки дают больше информации, какие-то меньше (только одна переменная оказалась с IGR, равным нулю). Это хорошо видно, если построить графики значений признаков с разным уровнем IGR. Для определенности я выбрал 10-й и 551-й. Видно, что для признака с высоким IGR точки хорошо визуально разделимы, с низким IGR – напоминают цветовое месиво, но очевидно, несут какую-то порцию полезной информации.


Вторая причина связана с тем, что зависимая переменная это фактор с количеством уровней больше двух (здесь – шесть). Достигая максимума точности в одном классе, мы ухудшаем показатели в другом. Это можно показать на матрицах несоответствия для двух разных наборов признаков с одинаковой точностью:
В верхнем варианте меньше ошибок у первых двух классов, в нижнем – у третьего и пятого.
Подвожу итоги:
1. SVM «сделала» Random Forest в моей задаче, работает в два раза быстрее и дает более качественную модель.
2. Было бы правильно понимать физический смысл переменных. И, кажется, на гироскопе в некоторых устройствах можно сэкономить.
3. Важность переменных из RF можно использовать для отбора переменных с другими методами обучения.
4. Отбор признаков на основе фильтрации не всегда дает повышение качества модели, но при этом позволяет сократить количество признаков, сократив время обучения при незначительной потери в качестве (при использовании 20% важных переменных точность в SVM оказалась всего на 3% ниже максимума).
Код для этой статьи можно найти в моем репозитарии.
Несколько дополнительных ссылок:
UPD:
По совету kenoma сделал анализ главных компонент (PCA). Использовал вариант с функцией preProcess из caret:
Отсечка 0.95, получилось 102 компоненты.
Точность RF на тестовой выборке: 0.8734 (на 5% ниже точности на полном наборе)
Точность SVM: 0.9386 (на один с небольшим процента ниже). Я считаю, что этот результат весьма неплох, так что совет оказался полезным.
Данные
Данные в наборе получены от тридцати добровольцев с закрепленным на поясе Samsung Galaxy S II. Сигналы с гироскопа и акселерометра были специальным образом обработаны и преобразованы в 561 признак. Для этого использовалась многоступенчатая фильтрация, преобразование Фурье и некоторые стандартные статистические преобразования, всего 17 функций: от математического ожидания до расчета угла между векторами. Подробности обработки я упускаю, их можно найти в репозитории. Обучающая выборка содержит 7352 кейса, тестовая – 2947. Обе выборки размечены метками, соответствующими шести активностям: walking, walking_up, walking_down, sitting, standing и laying.
В качестве базового алгоритма для экспериментов я выбрал Random Forest. Выбор был основан на том, что у RF есть встроенный механизм оценки важности переменных, который я хотел испытать, так как перспектива самостоятельно выбирать признаки из 561 переменной меня несколько пугала. Также я решил попробовать машину опорных векторов (SVM). Знаю, что это классика, но ранее мне её использовать не приходилось, было интересно сравнить качество моделей для обоих алгоритмов.
Скачав и распаковав архив с данными, я понял что с ними придется повозиться. Все части набора, имена признаков, метки активностей были в разных файлах. Для загрузки файлов в среду R использовал функцию read.table(). Пришлось запретить автоматическое преобразование строк в факторные переменные, так как оказалось, что есть дубли имен переменных. Кроме того, имена содержали некорректные символы. Эту проблему решил следующей конструкцией с функцией sapply(), которая в R часто заменяет стандартный цикл for:
editNames <- function(x) {
y <- var_names[x,2]
y <- sub("BodyBody", "Body", y)
y <- gsub("-", "", y)
y <- gsub(",", "_", y)
y <- paste0("v",var_names[x,1], "_",y)
return(y)
}
new_names <- sapply(1:nrow(var_names), editNames)
Склеил все части наборов при помощи функций rbind() и cbind(). Первая соединяет строки одинаковой структуры, вторая колонки одинаковой длины.
После того как я подготовил обучающую и тестовую выборки, встал вопрос о необходимости предобработки данных. Используя функцию range() в цикле, рассчитал диапазон значений. Оказалось, что все признаки находятся в рамках [-1,1] и значит не нужно ни нормализации, ни масштабирования. Затем проверил наличие признаков с сильно смещенным распределением. Для этого воспользовался функцией skewness() из пакета e1071:
SkewValues <- apply(train_data[,-1], 2, skewness)
head(SkewValues[order(abs(SkewValues),decreasing = TRUE)],3)
Apply() — функция из той же категории, что и sapply(), используется, когда что-то нужно сделать по столбцам или строкам. train_data[,-1] — набор данных без зависимой переменной Activity, 2 показывает что нужно рассчитывать значение по столбцам. Этот код выводит три худшие переменные:
v389_fBodyAccJerkbandsEnergy57_64 v479_fBodyGyrobandsEnergy33_40 v60_tGravityAcciqrX 14.70005 12.33718 12.18477
Чем ближе эти значения к нулю, тем меньше перекос распределения, а здесь он, прямо скажем, немаленький. На этот случай в caret есть реализация BoxCox-трансформации. Читал, что Random Forest не чувствителен к подобным вещам, поэтому решил признаки оставить как есть и заодно посмотреть, как с этим справится SVM.
Осталось выбрать критерий качества модели: точность или верность Accuracy или критерий согласия Kappa. Если кейсы по классам распределены неравномерно, нужно использовать Kappa, это та же Accuracy только с учетом вероятности случайным образом «вытащить» тот или иной класс. Сделав summary() для столбца Activity проверил распределение:
WALKING WALKING_UP WALKING_DOWN SITTING STANDING LAYING
1226 1073 986 1286 1374 1407
Кейсы распределены практически поровну, кроме может быть walking_down (кто-то из добровольцев видимо не очень любил спускаться по лестнице), а значит можно использовать Accuracy.
Обучение
Обучил модель RF на полном наборе признаков. Для этого была использована следующая конструкция на R:
fitControl <- trainControl(method="cv", number=5)
set.seed(123)
forest_full <- train(Activity~., data=train_data,
method="rf", do.trace=10, ntree=100,
trControl = fitControl)
Здесь предусмотрена k-fold кросс-валидация с k=5. По умолчанию обучается три модели с разным значением mtry (кол-во признаков, которые случайным образом выбираются из всего набора и рассматриваются в качестве кандидата при каждом разветвлении дерева), а затем по точности выбирается лучшая. Количество деревьев у всех моделей одинаково ntree=100.
Для определения качества модели на тестовой выборке я взял функцию confusionMatrix(x, y) из caret, где x – вектор предсказанных значений, а y – вектор значений из тестовой выборки. Вот часть её выдачи:
Reference
Prediction WALKING WALKING_UP WALKING_DOWN SITTING STANDING LAYING
WALKING 482 38 17 0 0 0
WALKING_UP 7 426 37 0 0 0
WALKING_DOWN 7 7 366 0 0 0
SITTING 0 0 0 433 51 0
STANDING 0 0 0 58 481 0
LAYING 0 0 0 0 0 537
Overall Statistics
Accuracy : 0.9247
95% CI : (0.9145, 0.9339)
Обучение на полном наборе признаков заняло около 18 минут на ноутбуке с Intel Core i5. Можно было сделать в несколько раз быстрее на OS X, задействовав при помощи пакета doMC несколько ядер процессора, но для Windows такой штуки нет, на сколько мне известно.
Caret поддерживает несколько реализаций SVM. Я выбрал svmRadial (SVM с ядром – радиальной базисной функцией), она чаще используется c caret, и является общим инструментом, когда нет каких-то специальных сведений о данных. Чтобы обучить модель с SVM, достаточно поменять значение параметра method в функции train() на svmRadial и убрать параметры do.trace и ntree. Алгоритм показал следующие результаты: Accuracy на тестовой выборке – 0.952. При этом обучение модели с пятикратной кросс-валидацией заняло чуть более 7 минут. Оставил себе заметку на память: не хвататься сразу за Random Forest.
Важность переменных
Получить результаты встроенной оценки важности переменных в RF можно при помощи функции varImp() из пакета caret. Конструкция вида plot(varImp(model),20) отобразит относительную важность первых 20 признаков:

«Acc» в названии обозначает, что эта переменная получена при обработке сигнала с акселерометра, «Gyro», соответственно, с гироскопа. Если внимательно посмотреть на график, можно убедиться, что среди наиболее важных переменных нет данных с гироскопа, что лично для меня удивительно и необъяснимо. («Body» и «Gravity» это два компонента сигнала с акселерометра, t и f временной и частотный домены сигнала).
Подставлять в RF признаки, отобранные по важности, бессмысленное занятие, он их уже отобрал и использовал. А вот с SVM может получиться. Начал с 10% наиболее важных переменных и стал увеличивать на 10% каждый раз контролируя точность, найдя максимум, сократил шаг сначала до 5%, потом до 2.5% и, наконец, до одной переменной. Итог – максимум точности оказался в районе 490 признаков и составил 0.9545 что лучше значения на полном наборе признаков всего на четверть процента (дополнительная пара правильно классифицированных кейсов). Эту работу можно было бы автоматизировать, так в составе caret есть реализация RFE (Recursive feature elimination), он рекурсивно убирает и добавляет по одной переменной и контролирует точность модели. Проблем с ним две, RFE работает очень медленно (внутри у него Random Forest), для сходного по количеству признаков и кейсов набора данных, процесс бы занял около суток. Вторая проблема — точность на обучающей выборке, которую оценивает RFE, это совсем не тоже самое, что точность на тестовой.
Код, который извлекает из varImp и упорядочивает по убыванию важности имена заданного количества признаков, выглядит так:
imp <- varImp(model)[[1]]
vars <- rownames(imp)[order(imp$Overall, decreasing=TRUE)][1:56]
Фильтрация признаков
Для очистки совести решил попробовать еще какой-нибудь метод отбора признаков. Выбрал фильтрацию признаков на основе расчета information gain ratio (в переводе встречается как информационный выигрыш или прирост информации), синоним дивергенции Кульбака-Лейблера. IGR это мера различий между распределениями вероятностей двух случайных величин.
Для расчета IGR я использовал функцию information.gain() из пакета FSelector. Для работы пакета нужна JRE. Там, кстати, есть и другие инструменты, позволяющие отбирать признаки на основе энтропии и корреляции. Значения IGR обратны «расстоянию» между распределениями и нормированы [0,1], т.е. чем ближе к единице, тем лучше. После вычисления IGR я упорядочил список переменных в порядке убывания IGR, первые 20 выглядели следующим образом:
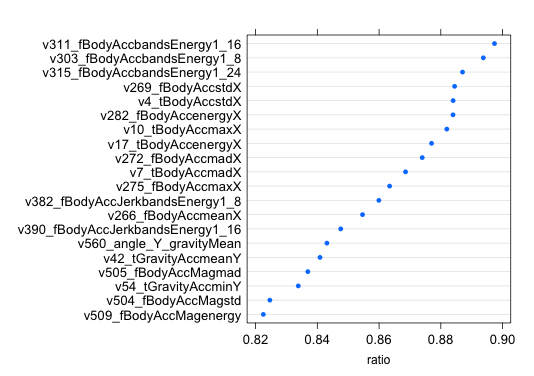
IGR дает совсем другой набор «важных» признаков, с важными совпали только пять. Гироскопа в топе снова нет, зато очень много признаков с X компонентой. Максимальное значение IGR – 0.897, минимальное – 0. Получив упорядоченный перечень признаков поступил с ним также как и с важностью. Проверял на SVM и RF, значимо увеличить точность не получилось.
Думаю, что отбор признаков в похожих задачах работает далеко не всегда, и причин здесь как минимум две. Первая причина связана с конструированием признаков. Исследователи, которые подготовили набор данных, старались «выжить» всю информацию из сигналов с датчиков и делали это наверняка осознанно. Какие-то признаки дают больше информации, какие-то меньше (только одна переменная оказалась с IGR, равным нулю). Это хорошо видно, если построить графики значений признаков с разным уровнем IGR. Для определенности я выбрал 10-й и 551-й. Видно, что для признака с высоким IGR точки хорошо визуально разделимы, с низким IGR – напоминают цветовое месиво, но очевидно, несут какую-то порцию полезной информации.

Вторая причина связана с тем, что зависимая переменная это фактор с количеством уровней больше двух (здесь – шесть). Достигая максимума точности в одном классе, мы ухудшаем показатели в другом. Это можно показать на матрицах несоответствия для двух разных наборов признаков с одинаковой точностью:
Accuracy: 0.9243, 561 variables
Reference
Prediction WALKING WALKING_UP WALKING_DOWN SITTING STANDING LAYING
WALKING 483 36 20 0 0 0
WALKING_UP 1 428 44 0 0 0
WALKING_DOWN 12 7 356 0 0 0
SITTING 0 0 0 433 45 0
STANDING 0 0 0 58 487 0
LAYING 0 0 0 0 0 537
Accuracy: 0.9243, 526 variables
Reference
Prediction WALKING WALKING_UP WALKING_DOWN SITTING STANDING LAYING
WALKING 482 40 16 0 0 0
WALKING_UP 8 425 41 0 0 0
WALKING_DOWN 6 6 363 0 0 0
SITTING 0 0 0 429 44 0
STANDING 0 0 0 62 488 0
LAYING 0 0 0 0 0 537
В верхнем варианте меньше ошибок у первых двух классов, в нижнем – у третьего и пятого.
Подвожу итоги:
1. SVM «сделала» Random Forest в моей задаче, работает в два раза быстрее и дает более качественную модель.
2. Было бы правильно понимать физический смысл переменных. И, кажется, на гироскопе в некоторых устройствах можно сэкономить.
3. Важность переменных из RF можно использовать для отбора переменных с другими методами обучения.
4. Отбор признаков на основе фильтрации не всегда дает повышение качества модели, но при этом позволяет сократить количество признаков, сократив время обучения при незначительной потери в качестве (при использовании 20% важных переменных точность в SVM оказалась всего на 3% ниже максимума).
Код для этой статьи можно найти в моем репозитарии.
Несколько дополнительных ссылок:
- Feature Selection with the Caret R Package
- Random Forests, Leo Breiman and Adele Cutler
UPD:
По совету kenoma сделал анализ главных компонент (PCA). Использовал вариант с функцией preProcess из caret:
pca_mod <- preProcess(train_data[,-1],
method="pca",
thresh = 0.95)
pca_train_data <- predict(pca_mod, newdata=train_data[,-1])
dim(pca_train_data)
# [1] 7352 102
pca_train_data$Activity <- train_data$Activity
pca_test_data <- predict(pca_mod, newdata=test_data[,-1])
pca_test_data$Activity <- test_data$Activity
Отсечка 0.95, получилось 102 компоненты.
Точность RF на тестовой выборке: 0.8734 (на 5% ниже точности на полном наборе)
Точность SVM: 0.9386 (на один с небольшим процента ниже). Я считаю, что этот результат весьма неплох, так что совет оказался полезным.








