Комментарии 49
>Процессор Intel Atom 2538
Закапывайте.
Закапывайте.
Аргументируйте, пожалуйста.
Можно перефразировать: «А почему у вас используется процессор Atom 2538?» И тогда по всем правилам, доказательство постулата ложится на плечи постулирующего. Могу предположить, что там усё у ней внутрях тотально железно-аппаратное, и поэтому на плечи Атома ложится только координация этих железяк между собой.
Ну тогда по всем канонам клинча в ответ услышите: «Священное право на собственные убеждения и личное мнение».
Там наличествует SDN. Он подразумевает, что в случае если правила нет на поток, то это все валит процессору, который обращается к контроллеру и тот говорит какое правило настроить фабрику. Плюс классическая схема подразумевает, что часть потока может быть отправлена на процессор общего назначения и обработана там. Это кстати ответ почему у cisco на их железяках был весьма дохлый NAT при прочих довольно хороших коммутационных характеристиках.
А я вот весьма не уверен, что Intel Atom 2538 сможет с адекватной скоростью обработать возможный поток.
А я вот весьма не уверен, что Intel Atom 2538 сможет с адекватной скоростью обработать возможный поток.
Это правильное перефразирование. :)
Atom используется потому, что это это архитектура x86, что упрощает перенос собственных дополнительных пакетов в среду сетевой ОС. Альтернативой являются процессоры на архитектурах MIPS и PowerPC.
Вы абсолютно правы, вся работа с трафиком между портами лежит исключительно на коммутирующей матрице, процессор и сетевая ОС нужны лишь для задания правил обработки пакетов матрицей.
Одиночный порт 100GbE практически полностью выедает пропускную способность PCIe x16 v3, «запихать» поток с 32 портов в процессор крайне сложно. Да и возможностей его, мягко говоря, будет несколько недостаточно.
Atom используется потому, что это это архитектура x86, что упрощает перенос собственных дополнительных пакетов в среду сетевой ОС. Альтернативой являются процессоры на архитектурах MIPS и PowerPC.
Вы абсолютно правы, вся работа с трафиком между портами лежит исключительно на коммутирующей матрице, процессор и сетевая ОС нужны лишь для задания правил обработки пакетов матрицей.
Одиночный порт 100GbE практически полностью выедает пропускную способность PCIe x16 v3, «запихать» поток с 32 портов в процессор крайне сложно. Да и возможностей его, мягко говоря, будет несколько недостаточно.
Atom используется потому, что это это архитектура x86, что упрощает перенос собственных дополнительных пакетов в среду сетевой ОС. Альтернативой являются процессоры на архитектурах MIPS и PowerPC.
В Linux это никогда проблемой особой не было. А вот стоимость при сравнимых характеристиках может решать, так-как сравнимый даже с Atom MIPS/PowerPC будет стоить несколько дороже.
Вы абсолютно правы, вся работа с трафиком между портами лежит исключительно на коммутирующей матрице, процессор и сетевая ОС нужны лишь для задания правил обработки пакетов матрицей.
Т.е. пакеты в сетевую ОС нельзя внутрь отдать от слова никак?
Одиночный порт 100GbE практически полностью выедает пропускную способность PCIe x16 v3, «запихать» поток с 32 портов в процессор крайне сложно. Да и возможностей его, мягко говоря, будет несколько недостаточно.
Более того установленный процессор 10GbE имеет риск не прожевать.
>В Linux это никогда проблемой особой не было. А вот стоимость при сравнимых характеристиках может решать, так-как сравнимый даже с Atom MIPS/PowerPC будет стоить несколько дороже.
Вопрос в стоимости адаптации.
А разница стоимости x86/MIPS/Power несущественна от слова вообще.
>Т.е. пакеты в сетевую ОС нельзя внутрь отдать от слова никак?
На скоростях потока в матрице? Да. Там вся матрица висит на шине PCIe, по которой получает управляющие команды и отдает те данные, которые обучена отдавать. Собственно, вышеупомянутый Broadview введен Boradcom'ом как раз для расширения возможностей работы с трафиком на уровне мониторинга и анализа.
>Более того установленный процессор 10GbE имеет риск не прожевать.
Смотрите чуть ниже. Если нужно именно «жевать» трафик, то для этого сейчас принято ставить специализированные программируемые NPU.
Вопрос в стоимости адаптации.
А разница стоимости x86/MIPS/Power несущественна от слова вообще.
>Т.е. пакеты в сетевую ОС нельзя внутрь отдать от слова никак?
На скоростях потока в матрице? Да. Там вся матрица висит на шине PCIe, по которой получает управляющие команды и отдает те данные, которые обучена отдавать. Собственно, вышеупомянутый Broadview введен Boradcom'ом как раз для расширения возможностей работы с трафиком на уровне мониторинга и анализа.
>Более того установленный процессор 10GbE имеет риск не прожевать.
Смотрите чуть ниже. Если нужно именно «жевать» трафик, то для этого сейчас принято ставить специализированные программируемые NPU.
Процессор весьма дохлый. И что-то внятное сделать на нем нельзя. Грубо говоря если вдруг мне потребуется что-то сделать софтом и пакеты будут уходить к нему, то он много не прожует. Та же ситуация с SDN он может в некоторых случаях не успеть. И получится ситуация «Не прожевал волк бабушку!»
А для тех кто в танке можно расчеты и сравнение расчетов и практики у текущего поколения?
А через что вы собираетесь передавать поток в три терабита в процессор?
Про производительность процессоров можно поговорить отдельно.
Про производительность процессоров можно поговорить отдельно.
Какие три терабита? Он хотя бы 10 гигабит осилит? Вот надо netflow отдавать. Кто этим будет заниматься?
32 порта х 100 GbE — это физические возможности коммутатора, которые реализованы на коммутационной матрице. Если вы собираетесь выводить поток из нее на обработку процессором — думайте, как вы их туда доставите.
Что же касается производительности x86… ну примерно так:
«Under the tests conducted by SDNCentral testing lab partners, the Brocade Vyatta 5600 vRouter platform ran on a mid-range, Intel Xeon server platform with dual 10-core Xeon processors (E5-2670v2 @ 2.50GHz). The tests measured L3 forwarding for a dual-socket CPU compute node with an aggregate system performance of 70 million packets per second and 80Gbps rates over a wide set of IP conditions – performance was comparable to many traditional hardware appliances.»
Поэтому перестаньте рассчитывать на то, что вы что-то успеете сделать х86-процессором с трафиком такого уровня.
Что же касается производительности x86… ну примерно так:
«Under the tests conducted by SDNCentral testing lab partners, the Brocade Vyatta 5600 vRouter platform ran on a mid-range, Intel Xeon server platform with dual 10-core Xeon processors (E5-2670v2 @ 2.50GHz). The tests measured L3 forwarding for a dual-socket CPU compute node with an aggregate system performance of 70 million packets per second and 80Gbps rates over a wide set of IP conditions – performance was comparable to many traditional hardware appliances.»
Поэтому перестаньте рассчитывать на то, что вы что-то успеете сделать х86-процессором с трафиком такого уровня.
Про то сколько может прожевать x86 процессор я в курсе, по этому и спрашиваю. Вопрос состоит зачем там процессор и что я им смогу сделать с трафиком. Если он там только как рулилка и возможная запускалка процессов, ну ок. Только с таким же успехом можно купить свитч без такого процессора.
Можно, конечно. Только матрица сама себе правил работы с трафиком не задаст.
Для задачи правил работы с трафиком как-то x86 процессора не надо. Можно обойтись более простым и менее мощным.
Можно поставить 2-х ядерный Атом.
Было бы желание и объём.
Было бы желание и объём.
Дамы и господа, перед нами человек, предположительно никогда не материвший коммутаторы за низкую производительность RP. Уникальный кадр, спешите, смотрите!
Серьезно, после одноядерного камня на 700мгц в sup720 многоядерные относительно современные xeon'ы в нексусах — счастье. Первый можно стабильно загрузить до 100% настройкой SNMP опросов без каких-либо экстремальных таймеров и параметров, второй даже show tech переваривает не замечая нагрузки, за пару-тройку секунд. Обе платформы хардварные, не предполагается передача трафика через те процессоры.
Мне тоже не нравится выбор Атома, но по другой причине: могли бы и чего попроизводительнее впихнуть. Исключительно для control plane — про транзитные пакеты речь не идет.
По поводу упомянутого выше netflow — сам семплинг обычно хардварным делают, на крайняк есть sampled netflow (один пакет из X, где X может быть >100, передается RP, этого достаточно для общего понимания профиля трафика). Процессор только упаковывает уже собранную статистику и шлет коллектору. Иногда даже эта роль переносится на линейные карты, так как задача упаковки готовой статистики в пакеты может серьезно прогрузить RP…
Серьезно, после одноядерного камня на 700мгц в sup720 многоядерные относительно современные xeon'ы в нексусах — счастье. Первый можно стабильно загрузить до 100% настройкой SNMP опросов без каких-либо экстремальных таймеров и параметров, второй даже show tech переваривает не замечая нагрузки, за пару-тройку секунд. Обе платформы хардварные, не предполагается передача трафика через те процессоры.
Мне тоже не нравится выбор Атома, но по другой причине: могли бы и чего попроизводительнее впихнуть. Исключительно для control plane — про транзитные пакеты речь не идет.
По поводу упомянутого выше netflow — сам семплинг обычно хардварным делают, на крайняк есть sampled netflow (один пакет из X, где X может быть >100, передается RP, этого достаточно для общего понимания профиля трафика). Процессор только упаковывает уже собранную статистику и шлет коллектору. Иногда даже эта роль переносится на линейные карты, так как задача упаковки готовой статистики в пакеты может серьезно прогрузить RP…
Дамы и господа, перед нами человек, предположительно никогда не материвший коммутаторы за низкую производительность
А теперь внимательно почитайте все комментарии :)
Серьезно, после одноядерного камня на 700мгц в sup720 многоядерные относительно современные xeon'ы в нексусах — счастье. Первый можно стабильно загрузить до 100% настройкой SNMP опросов без каких-либо экстремальных таймеров и параметров, второй даже show tech переваривает не замечая нагрузки, за пару-тройку секунд.
Если для этого требуется xeon то я не знаю что мне приложить к лицу, видимо кроме рук еще и ноги :)
Мне тоже не нравится выбор Атома, но по другой причине: могли бы и чего попроизводительнее впихнуть. Исключительно для control plane — про транзитные пакеты речь не идет.
Я вообще про производительность тоже писал. Тут или или. Тут или лучше уже больше или же уж можно и ARM поставить. А так получается не рыба не мясо.
Если для этого требуется xeon то я не знаю что мне приложить к лицу, видимо кроме рук еще и ноги
Так у меня рука уже давно приросла к лицу, я давно ничему не удивляюсь. Отображение конфигурации грузит ЦП до 100% секунд на 5-10? Ок, ничего особенного (в конце концов, многие железки не просто файл читают, а по большей части реверсят то, что запрограммировано в железо). Отображение конфигурации отрабатывает мгновенно? Вот это уже необычно.
или же уж можно и ARM поставить. А так получается не рыба не мясо.
Какой смысл ставить ARM? Atom похож по производительности и по энергопотреблению. Следить за кодом сразу под две разные архитектуры — затратнее.
У них там linux. Никакой разницы, а ARM кстати по энергопотреблению получше будет :)
Linux — просто ядро. Есть еще и управляющий софт, который иногда довольно низкоуровнево пишут. И еще очень часто Linux там с RT вставками.
ARM сравним с Atom'ом.
www.extremetech.com/extreme/188396-the-final-isa-showdown-is-arm-x86-or-mips-intrinsically-more-power-efficient/2
Вообще, железка будет тратить на один порт больше, чем на весь процессор в пике. Что тут сравнивать?
ARM сравним с Atom'ом.
www.extremetech.com/extreme/188396-the-final-isa-showdown-is-arm-x86-or-mips-intrinsically-more-power-efficient/2
Вообще, железка будет тратить на один порт больше, чем на весь процессор в пике. Что тут сравнивать?
Linux — просто ядро. Есть еще и управляющий софт, который иногда довольно низкоуровнево пишут. И еще очень часто Linux там с RT вставками.
Не в их случае. Управлятор же.
Вообще, железка будет тратить на один порт больше, чем на весь процессор в пике. Что тут сравнивать?
Тогда вообще не понятно зачем Atom.
Не в их случае. Управлятор же
И чо? Если управлятор излишне задумывается о чем-то постороннем, то рвутся соседства и теряется трафик.
Тогда вообще не понятно зачем Atom.
Так ведь потому что стоит копейки.
И чо? Если управлятор излишне задумывается о чем-то постороннем, то рвутся соседства и теряется трафик.
Ну давайте вместо того чтобы нормально писать код просто ставить жирный процессор. Это же проще :]
Ну давайте вместо того чтобы нормально писать код просто ставить жирный процессор. Это же проще :]
ARM не будет лучше по потреблению, а единый репозиторий софта гораздо удобней.
Единый репозиторий с чем?
Оркестровка OpenStack, NFV продукты, автоматизация (Chef и т.д.), агенты sFlow.
Мало ли чего ещё захочется поставить.
У Гугла используется единый образ на все случаи жизни — он разворачивается на железке, по конфигурации понимает, где оказался, и устанавливает нужную роль.
Всё автоматом, без участия человека.
Будут у нас х86 серверы и PPC коммутаторы — так уже не сделать.
Мало ли чего ещё захочется поставить.
У Гугла используется единый образ на все случаи жизни — он разворачивается на железке, по конфигурации понимает, где оказался, и устанавливает нужную роль.
Всё автоматом, без участия человека.
Будут у нас х86 серверы и PPC коммутаторы — так уже не сделать.
Нет никакой разницы ровно до того момента, пока не возникнет необходимость поставить там что-нибудь свое, например какое-нибудь свое приложение на Java и нативные JNI-либы прицепом.
Главный плюс Atom'a именно в том, что это дешевый и слабый, но тем не менее x86 процессор. И разработчикам не нужно думать, как там кросс-компилить софт и как потом все это дело отлаживать.
Главный плюс Atom'a именно в том, что это дешевый и слабый, но тем не менее x86 процессор. И разработчикам не нужно думать, как там кросс-компилить софт и как потом все это дело отлаживать.
К вопросу о совместимости софта под ARMы — из нескольких протестированных моделей (среди которых Marvell и еще одна серверная модель) ни на одной линуксовый AIO не работает так, как работает на x86 (включая Atom). Тесты, которые на Atom'е съедают 10-15% CPU, все без исключения ARMы уводят в глубокий iowait в 60-80%.
Это в принципе все что нужно знать о зрелости армовой экосистемы.
Это в принципе все что нужно знать о зрелости армовой экосистемы.
Netmap наше все в данном случае.
Не знаю, общая эрудиция говорит, что в любых процессорах шина не настолько широка, чтоб все пропустить; потому и спрашиваю про сравнение с текущим поколением.
Коммутатор делится на control plane (управляющая часть) и data plane (коммутирующая часть).
Наиболее удобная аналогия — коммутирующая часть выступает для управляющей устройством на PCIe шине, как GPU либо Xeon Phi.
Связь между ними — хорошо, если PCIe 2.0 x2 и гигабит, вопрос направления каких-либо потоков вообще не стоит.
Нужна управлялка только для программирования матрицы правилами + внешнего софта для оркестровки/автоматизации процесса.
Как появились коммутаторы 10G на Freescale P2020, так и в 100G можно поставить его же.
Атомы пришли в коммутаторы позже, но и они не меняются.
Наиболее удобная аналогия — коммутирующая часть выступает для управляющей устройством на PCIe шине, как GPU либо Xeon Phi.
Связь между ними — хорошо, если PCIe 2.0 x2 и гигабит, вопрос направления каких-либо потоков вообще не стоит.
Нужна управлялка только для программирования матрицы правилами + внешнего софта для оркестровки/автоматизации процесса.
Как появились коммутаторы 10G на Freescale P2020, так и в 100G можно поставить его же.
Атомы пришли в коммутаторы позже, но и они не меняются.
Ну, немного о цифрах — у 100GE с обычным 1536b пакетами скорость классификации близка к 10Mpps — далеко не все современные фреймворки способны переваривать такой рейт на чем-то, кроме топовых процессоров. Если вас вдруг начнут атаковать и пакет рейт вырастет на порядок — x86 просто не будет способен это переварить, по нескольким причинам:
а) нельзя масштабироваться на соседние NUMA-ноды, то есть сокеты, слишком большие потери даже при bulk queuing пакетов для пересылки между процессором и очередями карт, сюда же записываем проблему с работой DCA, который хорошо вывозит работу с картой на сравнительно небольших объемах трафика,
б) классификация пакетов не может съедать ниже определенного числа тактов на пакет, равного примерно полусотне.
Иными словами, хотите крутой и производительный SDN — распределяйте обработку пакетов по коробкам, а там уже не имеет значения, атом ли это или топовый зеон. В сабжевом устройстве единственная задача управляющей платы — запускать линукс с программирующей сущностью, обычно это сцепленный с API матрицы виртуальный свич.
а) нельзя масштабироваться на соседние NUMA-ноды, то есть сокеты, слишком большие потери даже при bulk queuing пакетов для пересылки между процессором и очередями карт, сюда же записываем проблему с работой DCA, который хорошо вывозит работу с картой на сравнительно небольших объемах трафика,
б) классификация пакетов не может съедать ниже определенного числа тактов на пакет, равного примерно полусотне.
Иными словами, хотите крутой и производительный SDN — распределяйте обработку пакетов по коробкам, а там уже не имеет значения, атом ли это или топовый зеон. В сабжевом устройстве единственная задача управляющей платы — запускать линукс с программирующей сущностью, обычно это сцепленный с API матрицы виртуальный свич.
100GE с обычным 1536b пакетами скорость классификации близка к 10Mpps — далеко не все современные фреймворки способны переваривать такой рейт на чем-то, кроме топовых процессоров.
Про то и речь.
Иными словами, хотите крутой и производительный SDN — распределяйте обработку пакетов по коробкам, а там уже не имеет значения, атом ли это или топовый зеон.
Иными словами, а зачем тогда тут Atom? :)
В сабжевом устройстве единственная задача управляющей платы — запускать линукс с программирующей сущностью, обычно это сцепленный с API матрицы виртуальный свич.
С моей точки зрения ставить туда тогда 4 ядерный Atom с 8 гигабайтами памяти под такую задачу несколько избыточно. Не проще ARM туда воткнуть или MIPS?
>С моей точки зрения ставить туда тогда 4 ядерный Atom с 8 гигабайтами памяти под такую задачу несколько избыточно.
Пакеты мониторинга, управления и оркестрации нынче становятся весьма требовательными. Проще сразу заложить некоторый запас, чем сэкономить копейки на железе, а потом страдать, не влезая в пожелания заказчика.
Собственно, архитектуру процессора можно подобрать под конкретного заказчика, если он уже имеет широкомасштабную развернутую структуру. Оно же все реализуется на дочерних платах, как завещает OCP, и пророк его Facebook.
Пакеты мониторинга, управления и оркестрации нынче становятся весьма требовательными. Проще сразу заложить некоторый запас, чем сэкономить копейки на железе, а потом страдать, не влезая в пожелания заказчика.
Собственно, архитектуру процессора можно подобрать под конкретного заказчика, если он уже имеет широкомасштабную развернутую структуру. Оно же все реализуется на дочерних платах, как завещает OCP, и пророк его Facebook.
Пакеты мониторинга, управления и оркестрации нынче становятся весьма требовательными. Проще сразу заложить некоторый запас, чем сэкономить копейки на железе, а потом страдать, не влезая в пожелания заказчика.
Настолько? Не ну если на ruby писать то конечно и такого процессора будет мало.
Оно же все реализуется на дочерних платах, как завещает OCP, и пророк его Facebook.
Atom вынули, MIPS, ARM поставили?
>Настолько? Не ну если на ruby писать то конечно и такого процессора будет мало.
Нет границ у таланта индусокодеров!
>Atom вынули, MIPS, ARM поставили?
Практически.
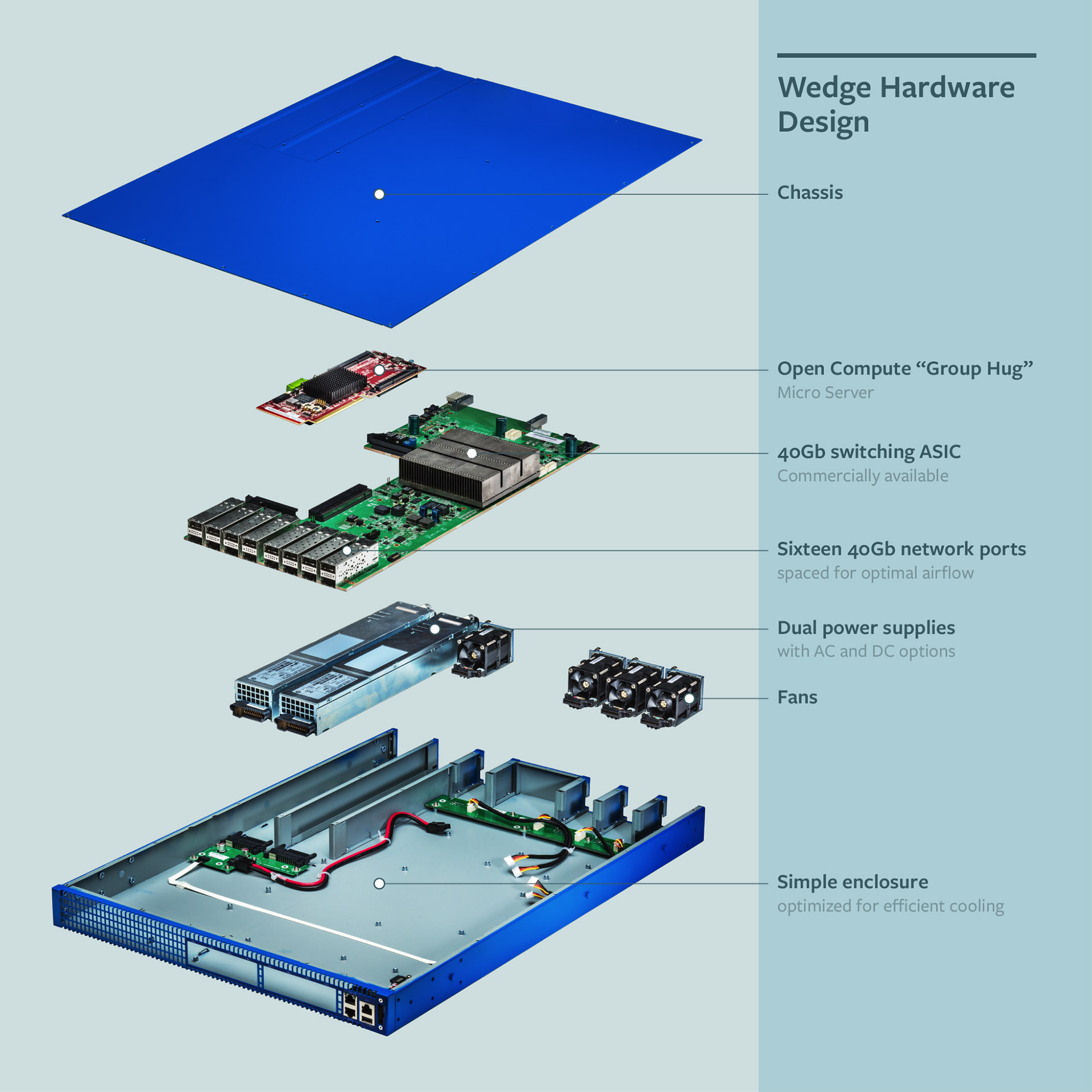
Плата с красным тексталитом — «серверная» часть: впаянный процессор, RAM, флеш.
hsto.org/getpro/habr/post_images/404/0b9/1c0/4040b91c057566d811980065feb4dcd0.jpg
Нет границ у таланта индусокодеров!
>Atom вынули, MIPS, ARM поставили?
Практически.
Плата с красным тексталитом — «серверная» часть: впаянный процессор, RAM, флеш.
hsto.org/getpro/habr/post_images/404/0b9/1c0/4040b91c057566d811980065feb4dcd0.jpg
{kind=link}
Что касается готовности нового стандарта к массовому производству и внедрению, то здесь, на наш взгляд, все обстоит достаточно неплохо. Уже сейчас существует реализованный в железе, текстолите и кремнии полный спектр необходимого оборудования
Можно пример готовых к стандарту маршрутизаторов и брасов?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Эволюция сетей — новый стандарт 25/50/100 GbE