В этой статье я попробую ответить на такие вопросы:
Ответ на первый вопрос будет самым лаконичным — «да». Услышав это выступление bobuk на YaC/M, я восхитился элегантностью подхода и задумался о том, как бы внедрить похожее решение. Я тогда работал продуктовым менеджером в компании Wargaming и как раз занимался т.н. user acquisition services – технологическими решениями для привлечения пользователей, в число которых входила и система для A/B тестирования лендингов. Так что зерна легли на благодатную почву.
К сожалению, по всяким причинам я не мог плотно заняться этим проектом в обычном рабочем режиме. Зато когда я слегка перегорел на работе и решил устроить себе длинный творческий отпуск, одержимость превратилась в желание сделать такой сервис умной ротации лендингов самостоятельно.
Концепция сервиса была довольно простой: на стадии прототипа я решил ограничиться роутером, который бы прогнозировал конверсию для каждого новоприбывшего пользователя на разных лендингах и отправлял бы его на оптимальный. Все свистелки отложил на потом, т.к. нужно было сначала отточить предсказательную технологию.
Уровень моих познаний в машинном обучении был где-то между «отсутствуют» и «скудны». Потому пришлось начинать с минимального ликбеза:
Для реализации неплохо подошел Python, т.к. с одной стороны, это язык общего назначения, с другой — его экосистема породила немало библиотек для работы с данными (в частности, мне пригодились scikit-learn, pandas, Lasagne). Для веб-обертки использовал Django — это явно неоптимальный выбор, но зато это не требовало дополнительного времени на освоение нового фреймворка. Забегая вперед, отмечу, что проблем с быстродействием Django не было, и на моей сравнительно небольшой нагрузке до 3000 RPM серверные запросы отрабатывали в течение 20-30 мс.

Что бывает, если внезапно подключить к тесту клиента с большим количеством трафика.
Workflow был таким:
Чтобы подбирать лучшие лендинги, нужно для начала подобрать подходящий классификатор. Для каждого проекта (набора лендингов одного клиента) классификаторы бы наверняка разнились, потому мне нужно было:
Несомненное преимущество было в том, что обучать классификаторы можно в бэкграунде, независимо от той части системы, которая непосредственно распределяла пользователей по лендингам. Например, в начале экспериментов пользователи распределялись в режиме a/b теста, чтобы одновременно и собрать данные для обучения модели, и не испортить существующую конверсию.
Обучение классификатора при помощи scikit-learn — достаточно простая вещь. Достаточно сперва векторизовать данные при помощи DictVectorizer из scikit-learn, разделить выборкy на обучающую и тестовую, обучить классификатор, сделать предсказания и оценить их точность.
А примерно так — трансформированные в numpy array:
Кстати, для многих методов классификации рациональнее оставлять данные в виде sparse-матрицы, а не numpy array, т.к. это снижает расход памяти.
Результат, который нужно предсказывать по этим данным, является списком из нулей (конверсии не случилось) и единиц (ура, пользователь зарегистрировался!).
Сделаем простейшую логистическую регрессию:
Оценим качество предсказаний. Выбор критерия оценки — едва ли не самая сложная часть проекта. Интуитивно кажется, что не нужно ничего придумывать и достаточно оценить долю правильных предсказаний, однако это некорректный подход. Простейший контраргумент: если у наших лендингов будет средняя конверсия 1%, то самый тупой классификатор, предсказывающий отсутствие конверсии для любого пользователя, покажет точность 99%.
Для задач бинарной классификации часто используют такие метрики как f1-score или коэффициент Мэттьюса. Но в моем случае важна не столько корректность бинарного предсказания (случится конверсия или нет), а насколько близка предсказанная вероятность. В таких случаях можно использовать ROC AUC score или log_loss; если изучить похожие задачи на Kaggle (например, конкурс Avazu или Avito), можно увидеть, что именно эти метрики зачастую и используются.
Хм, качество так себе. А почему бы не попробовать перебирать гиперпараметры модели? Для этого в scikit-learn тоже есть готовый инструмент — модуль grid_search и классы GridSearchCV для полного перебора и RandomizedSearchCV для множества случайных выборов (пригодится, если количество возможных вариантов уж слишком велико).
Этот фрагмент кода, как и прочие, максимально упрощен для наглядности: например, в качестве числовых параметров для перебора в RandomizedSearchCV рекомендуется передавать распределения scipy.stats, а не списки.
В принципе, можно было бы не останавливаться на достигнутом и прикрутить к этому счастью еще и генетические алгоритмы. Но, кажется, качество предсказаний уже становится более или менее адекватным:
К сожалению, нет четкого критерия, когда модель уже хороша или еще нуждается в тюнинге. Возможности для тюнинга безграничны: можно добавить полиномиальные комбинации признаков, можно конструировать признаки на базе существующих (например, определять тематики сайта-реферера). Тем не менее, когда разного рода манипуляции уже не дают ощутимого эффекта, пора приступать к следующей стадии, иначе можно провести немало времени, улучшая классификатор еще на 0.00001%.
После того, как определены гиперпараметры, классификатор можно обучать на всей выборке и класть в кэш для быстрого доступа.
Итак, у нас есть сколько-нибудь работающие классификаторы. Пора в продакшен! Только перед этим нужно определиться, что такое хорошо, а что такое плохо — уже не с точки зрения математики и машинного обучения, а для бизнеса.
Т.к. весь проект про повышение конверсии, надо опять устроить A/B тест. Точнее, метатест:
Деплой, обсуждение запуска с тестовыми клиентами, отладка мелких багов — и можно с нетерпением ждать результата.
Лично для меня самое неприятное в процессе A/B тестов — это промежуточные результаты. Регулярно случается ситуация, что поначалу один вариант выбивается вперед, кажется, что удалось добиться хорошего результата, хотя статистической значимости еще нет. Спустя какое-то время данных становится больше, и приходит понимание, что все не так радужно.
Примерно так же было и в этот раз. «Умный» роутинг при помощи классификаторов сперва выбился вперед, а потом результаты почти сравнялись с многоруким бандитом. Обе модели выбора лендинга показали себя примерно одинаково эффективными, оставив рандом позади (неудивительно). Только один из шести экспериментов показал статистически значимое преимущество такого роутинга перед A/B тестом.
Отдельно хочу отметить, что никакой корреляции между качеством классификатора (ROC AUC / log_loss) и конверсией я не заметил, что сильно усложняло попытки как-нибудь улучшить ситуацию.
Более актуален вопрос, может ли эта технология принести ощутимую пользу, а не колебаться на грани статистической погрешности? Я не могу подтвердить или опровергнуть эту гипотезу, но выглядит так, будто такой подход с машинным обучением может оказаться полезным при работе со всей цепочкой привлечения пользователей.
Вероятно, если делать разнообразные лендинги (я тестировал систему на слишком похожих страницах), интегрировать большее количество источников данных (макросы рекламных сетей, CRM клиента и даже DMP) — технология может оказаться полезной и повысить конверсию в ситуации, когда обычные a/b тесты не дают эффекта. Сделать же серебряную пулю, чтобы любой желающий мог на ровном месте получить +N% конверсии из существующих страниц без вдумчивой работы — скорее нереально.
Некоторые классификаторы scikit-learn (в частности, основанные на деревьях решений) имеют занятный атрибут feature_importances_, показывающий вес того или иного признака для итогового предсказания. Мои тестовые классификаторы редко присваивали выбранному лендингу вес более 2% и ни разу не пробили порог в 5%. При этом такие параметры как страна, реферер и браузер могли отобрать себе 20-25%. Я склонен трактовать это так: важность хорошего лендинга несколько преувеличена, а работа с таргетингом в рекламной кампании могла быть и получше.
Тем не менее, если среди читателей есть желающие попробовать мою разработку на своем проекте, пишите, буду рад провести еще несколько совместных экспериментов. Для теста понадобится несколько вариантов транзакционных страниц и достаточное количество пользователей (от 10 тыс.).
Я планирую на этом закончить свой творческий отпуск и вернуться к обычной работе, потому хотел бы узнать мнение сообщества о востребованности такого проекта, чтобы дойти до логического завершения.
- может ли один доклад умного человека сделать другого человека одержимым?
- как окунуться в машинное обучение (почти) с нуля?
- почему не стоит недооценивать многоруких бандитов?
- существует ли серебряная пуля для a/b тестов?
Ответ на первый вопрос будет самым лаконичным — «да». Услышав это выступление bobuk на YaC/M, я восхитился элегантностью подхода и задумался о том, как бы внедрить похожее решение. Я тогда работал продуктовым менеджером в компании Wargaming и как раз занимался т.н. user acquisition services – технологическими решениями для привлечения пользователей, в число которых входила и система для A/B тестирования лендингов. Так что зерна легли на благодатную почву.
К сожалению, по всяким причинам я не мог плотно заняться этим проектом в обычном рабочем режиме. Зато когда я слегка перегорел на работе и решил устроить себе длинный творческий отпуск, одержимость превратилась в желание сделать такой сервис умной ротации лендингов самостоятельно.
О чем вообще речь?
Концепция сервиса была довольно простой: на стадии прототипа я решил ограничиться роутером, который бы прогнозировал конверсию для каждого новоприбывшего пользователя на разных лендингах и отправлял бы его на оптимальный. Все свистелки отложил на потом, т.к. нужно было сначала отточить предсказательную технологию.

Уровень моих познаний в машинном обучении был где-то между «отсутствуют» и «скудны». Потому пришлось начинать с минимального ликбеза:
- «Программируем коллективный разум»;
- Mastering Machine Learning With scikit-learn;
- scikit-learn Cookbook;
- классический курс на Coursera от Andrew Ng;
- документация по scikit-learn (едва ли не самый ценный источник информации);
Для реализации неплохо подошел Python, т.к. с одной стороны, это язык общего назначения, с другой — его экосистема породила немало библиотек для работы с данными (в частности, мне пригодились scikit-learn, pandas, Lasagne). Для веб-обертки использовал Django — это явно неоптимальный выбор, но зато это не требовало дополнительного времени на освоение нового фреймворка. Забегая вперед, отмечу, что проблем с быстродействием Django не было, и на моей сравнительно небольшой нагрузке до 3000 RPM серверные запросы отрабатывали в течение 20-30 мс.

Что бывает, если внезапно подключить к тесту клиента с большим количеством трафика.
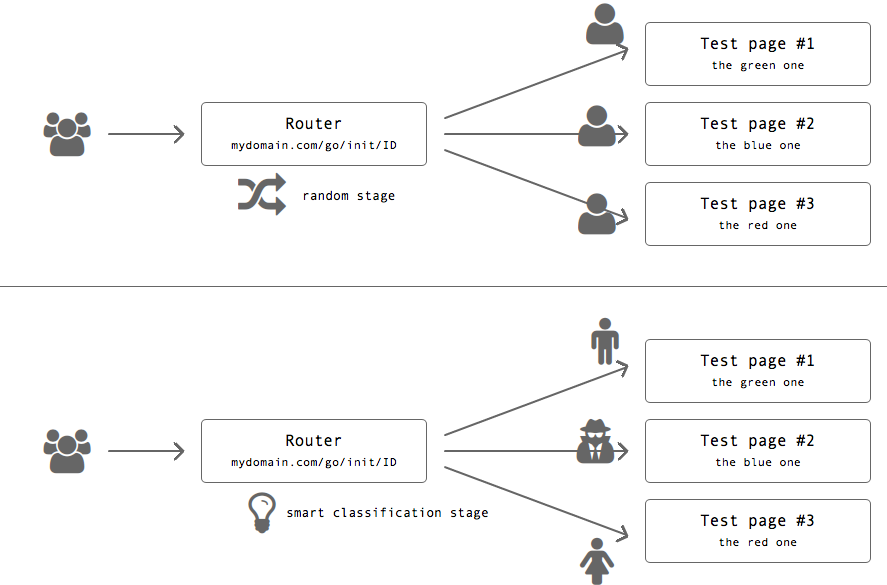
Workflow был таким:
- пользователь приходит на роутер;
- сервис собирает максимальное количество информации о нем (так как на этапе прототипа было бы глупо интегрироваться с поставщиками информации вроде DMP, я начинал с технических данных — HTTP-заголовки, геолокация, разрешение экрана и т.п.);
- классификатор предсказывает конверсию на возможных вариантах лендингов;
- роутер отдает 302 Redirect на потенциально лучший лендинг.
Классифицируя классификаторы
Чтобы подбирать лучшие лендинги, нужно для начала подобрать подходящий классификатор. Для каждого проекта (набора лендингов одного клиента) классификаторы бы наверняка разнились, потому мне нужно было:
- обучать некоторое количество классификаторов на исторических данных, подбирая гиперпараметры;
- выбирать оптимальный классификатор на текущий момент;
- периодически повторять эту операцию.
Несомненное преимущество было в том, что обучать классификаторы можно в бэкграунде, независимо от той части системы, которая непосредственно распределяла пользователей по лендингам. Например, в начале экспериментов пользователи распределялись в режиме a/b теста, чтобы одновременно и собрать данные для обучения модели, и не испортить существующую конверсию.
Обучение классификатора при помощи scikit-learn — достаточно простая вещь. Достаточно сперва векторизовать данные при помощи DictVectorizer из scikit-learn, разделить выборкy на обучающую и тестовую, обучить классификатор, сделать предсказания и оценить их точность.
Так выглядят исходные данные:
(часть пар ключ-значение удалена)
[{'1_lang': 'pl-PL',
'browser_full': 'IE8',
'country': 'Poland',
'day': '5',
'hour': '9',
'is_bot': False,
'is_mobile': False,
'is_pc': True,
'is_tablet': False,
'is_touch_capable': False,
'month': '6',
'os': 'Windows 7',
'timezone': '+0200',
'utm_campaign': '11766_',
'utm_medium': ‘543',
'used_landing' : '1'
},
{'1_lang': 'en-US',
'REFERER_HOST': 'somedomain.com',
'browser': 'Firefox',
'browser_full': 'Firefox38',
'city': 'Raleigh',
'country': 'United States',
'day': '5',
'hour': '3',
'is_bot': False,
'is_mobile': False,
'is_pc': True,
'is_tablet': False,
'is_touch_capable': False,
'month': '6',
'os': 'Windows 8.1',
'timezone': '-0400',
'utm_campaign': 'pff_r.search.yahoo.com',
'utm_medium': '1822',
'used_landing’ : '2'
},
...,
{'1_lang': 'ru-RU',
'HTTP_REFERER': 'somedomain.ru',
'browser': 'IE',
'browser_full': 'IE11',
'screen': '1280x960x24',
'country': 'Ukraine',
'day': '5',
'hour': '7',
'is_bot': False,
'is_mobile': False,
'is_pc': True,
'is_tablet': False,
'is_touch_capable': False,
'month': '6',
'os': 'Windows 7',
'timezone': 'N/A',
'utm_campaign': '62099',
'utm_medium': '1077',
'used_landing' : '1'
}]
(часть пар ключ-значение удалена)
А примерно так — трансформированные в numpy array:
[[ 0. 0. 0. ..., 0. 0. 1.]
[ 0. 0. 0. ..., 0. 0. 1.]
[ 0. 0. 0. ..., 0. 1. 0.]
...,
[ 0. 0. 0. ..., 0. 1. 0.]
[ 0. 0. 0. ..., 0. 0. 1.]
[ 0. 0. 0. ..., 0. 0. 1.]] Кстати, для многих методов классификации рациональнее оставлять данные в виде sparse-матрицы, а не numpy array, т.к. это снижает расход памяти.
Результат, который нужно предсказывать по этим данным, является списком из нулей (конверсии не случилось) и единиц (ура, пользователь зарегистрировался!).
from sklearn.feature_extraction import DictVectorizer
from sklearn.cross_validation import train_test_split
import json
clicks = Click.objects.filter(project=42)
# deserializing data stored as json
X = DictVectorizer().fit_transform([json.loads(x.data) for x in clicks])
Y = [1 if click.conversion_time else 0 for click in clicks]
# getting train and test subsets for model fitting and scoring
X1, X2, Y1, Y2 = train_test_split(X, Y, test_size=0.3)
Сделаем простейшую логистическую регрессию:
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(class_weight='auto')
clf.fit(X1, Y1)
predicted = clf.predict(X2)
Оценим качество предсказаний. Выбор критерия оценки — едва ли не самая сложная часть проекта. Интуитивно кажется, что не нужно ничего придумывать и достаточно оценить долю правильных предсказаний, однако это некорректный подход. Простейший контраргумент: если у наших лендингов будет средняя конверсия 1%, то самый тупой классификатор, предсказывающий отсутствие конверсии для любого пользователя, покажет точность 99%.
Для задач бинарной классификации часто используют такие метрики как f1-score или коэффициент Мэттьюса. Но в моем случае важна не столько корректность бинарного предсказания (случится конверсия или нет), а насколько близка предсказанная вероятность. В таких случаях можно использовать ROC AUC score или log_loss; если изучить похожие задачи на Kaggle (например, конкурс Avazu или Avito), можно увидеть, что именно эти метрики зачастую и используются.
In [21]: roc_auc_score(Y2, clf.predict(X2))
Out[21]: 0.76443388650963591
Хм, качество так себе. А почему бы не попробовать перебирать гиперпараметры модели? Для этого в scikit-learn тоже есть готовый инструмент — модуль grid_search и классы GridSearchCV для полного перебора и RandomizedSearchCV для множества случайных выборов (пригодится, если количество возможных вариантов уж слишком велико).
from sklearn.metrics import roc_auc_score, make_scorer
from sklearn.grid_search import RandomizedSearchCV
clfs = ((DecisionTreeClassifier(), {'max_features': ['auto', 'sqrt', 'log2', None],
'max_depth': range(3, 15),
'criterion': ['gini', 'entropy'],
'splitter': ['best', 'random'],
'min_samples_leaf': range(1, 10),
'class_weight': ['auto'],
'min_samples_split': range(1, 10),
}),
(LogisticRegression(), {'penalty': ['l1', 'l2'],
'C': [x / 10.0 for x in range(1, 50)],
'fit_intercept': [True, False],
'class_weight': ['auto'],
}),
(SGDClassifier(), {'loss': ['modified_huber', 'log'],
'alpha': [1.0 / 10 ** x for x in range(1, 6)],
'penalty': ['l2', 'l1', 'elasticnet'],
'n_iter': range(4, 12),
'learning_rate': ['constant', 'optimal', 'invscaling'],
'class_weight': ['auto'],
'eta0': [0.01],
}))
for clf, param in clfs:
logger.debug('Parameters search started for {0}'.format(clf.__class__.__name__))
grid = RandomizedSearchCV(estimator=clf,
param_distributions=param,
scoring=make_scorer(roc_auc_score),
n_iter=200,
n_jobs=2,
iid=True,
refit=True,
cv=2,
verbose=0,
pre_dispatch='2*n_jobs',
error_score=0)
grid.fit(X, Y)
logger.info('Best estimator is {} with score {} using params {}'.format(clf.__class__.__name__, grid.best_score_, grid.best_params_))
Этот фрагмент кода, как и прочие, максимально упрощен для наглядности: например, в качестве числовых параметров для перебора в RandomizedSearchCV рекомендуется передавать распределения scipy.stats, а не списки.
В принципе, можно было бы не останавливаться на достигнутом и прикрутить к этому счастью еще и генетические алгоритмы. Но, кажется, качество предсказаний уже становится более или менее адекватным:
In [27]: roc_auc_score(Y2, clf.predict(X2))
Out[27]: 0.95225886338947252
К сожалению, нет четкого критерия, когда модель уже хороша или еще нуждается в тюнинге. Возможности для тюнинга безграничны: можно добавить полиномиальные комбинации признаков, можно конструировать признаки на базе существующих (например, определять тематики сайта-реферера). Тем не менее, когда разного рода манипуляции уже не дают ощутимого эффекта, пора приступать к следующей стадии, иначе можно провести немало времени, улучшая классификатор еще на 0.00001%.
После того, как определены гиперпараметры, классификатор можно обучать на всей выборке и класть в кэш для быстрого доступа.
Из песочницы в продакшен
Итак, у нас есть сколько-нибудь работающие классификаторы. Пора в продакшен! Только перед этим нужно определиться, что такое хорошо, а что такое плохо — уже не с точки зрения математики и машинного обучения, а для бизнеса.
Т.к. весь проект про повышение конверсии, надо опять устроить A/B тест. Точнее, метатест:
- часть трафика будет распределяться между лендингами случайным образом;
- для части будет работать A/B тест по простейшей модели многорукого бандита;
- и, наконец, оставшийся трафик будет распределяться при помощи классификаторов.
Деплой, обсуждение запуска с тестовыми клиентами, отладка мелких багов — и можно с нетерпением ждать результата.
Лично для меня самое неприятное в процессе A/B тестов — это промежуточные результаты. Регулярно случается ситуация, что поначалу один вариант выбивается вперед, кажется, что удалось добиться хорошего результата, хотя статистической значимости еще нет. Спустя какое-то время данных становится больше, и приходит понимание, что все не так радужно.
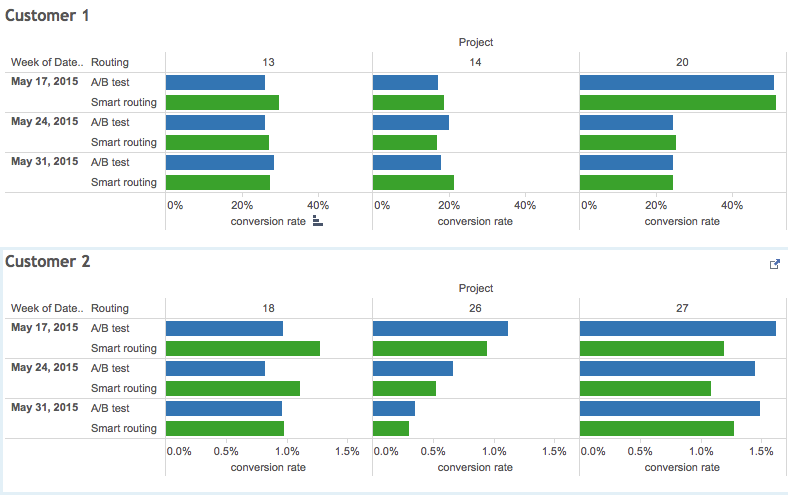
Примерно так же было и в этот раз. «Умный» роутинг при помощи классификаторов сперва выбился вперед, а потом результаты почти сравнялись с многоруким бандитом. Обе модели выбора лендинга показали себя примерно одинаково эффективными, оставив рандом позади (неудивительно). Только один из шести экспериментов показал статистически значимое преимущество такого роутинга перед A/B тестом.
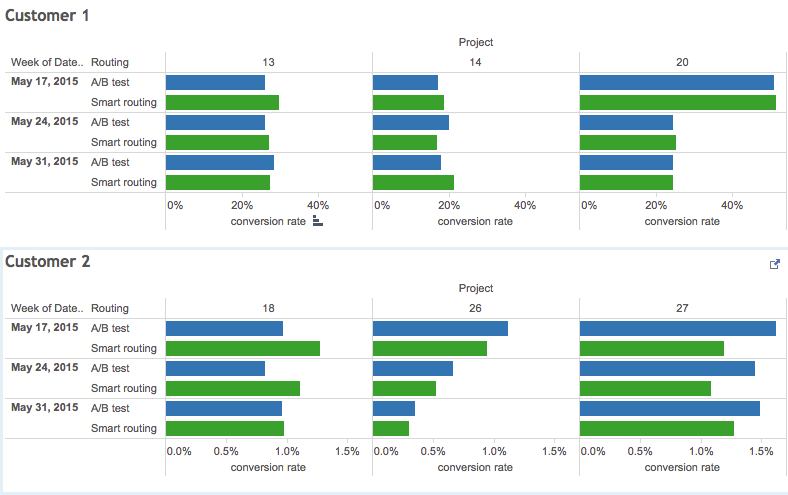
Отдельно хочу отметить, что никакой корреляции между качеством классификатора (ROC AUC / log_loss) и конверсией я не заметил, что сильно усложняло попытки как-нибудь улучшить ситуацию.
Есть ли жизнь на Марсе?
Более актуален вопрос, может ли эта технология принести ощутимую пользу, а не колебаться на грани статистической погрешности? Я не могу подтвердить или опровергнуть эту гипотезу, но выглядит так, будто такой подход с машинным обучением может оказаться полезным при работе со всей цепочкой привлечения пользователей.
Вероятно, если делать разнообразные лендинги (я тестировал систему на слишком похожих страницах), интегрировать большее количество источников данных (макросы рекламных сетей, CRM клиента и даже DMP) — технология может оказаться полезной и повысить конверсию в ситуации, когда обычные a/b тесты не дают эффекта. Сделать же серебряную пулю, чтобы любой желающий мог на ровном месте получить +N% конверсии из существующих страниц без вдумчивой работы — скорее нереально.
Некоторые классификаторы scikit-learn (в частности, основанные на деревьях решений) имеют занятный атрибут feature_importances_, показывающий вес того или иного признака для итогового предсказания. Мои тестовые классификаторы редко присваивали выбранному лендингу вес более 2% и ни разу не пробили порог в 5%. При этом такие параметры как страна, реферер и браузер могли отобрать себе 20-25%. Я склонен трактовать это так: важность хорошего лендинга несколько преувеличена, а работа с таргетингом в рекламной кампании могла быть и получше.
Тем не менее, если среди читателей есть желающие попробовать мою разработку на своем проекте, пишите, буду рад провести еще несколько совместных экспериментов. Для теста понадобится несколько вариантов транзакционных страниц и достаточное количество пользователей (от 10 тыс.).
Я планирую на этом закончить свой творческий отпуск и вернуться к обычной работе, потому хотел бы узнать мнение сообщества о востребованности такого проекта, чтобы дойти до логического завершения.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Вам бы пригодился такой сервис?
13.81%
Это интересно, готов пользоваться за небольшие деньги
25
53.04%
Это интересно, хочется, чтобы проект ушел в open source
96
8.29%
Для меня это бесполезно / неинтересно
15
24.86%
Если понадобится, я сам легко сделаю такой велосипед
45
Проголосовал 181 пользователь.
Воздержались 69 пользователей.










